CCF-ADL 87期回顾:韩家炜等13 位大牛全方位解析社交网络和数据挖掘
AI 科技评论按:2017 年 12 月 22-24 日,由中国计算机学会(CCF)主办的第 87 期 CCF 学科前沿讲习班(CCF Advanced Disciplines Lectures,简称 ADL)在北京中国科学院计算技术研究所成功举办,雷锋网作为独家合作媒体,进行了全程报道。
本次讲习班的主题为《社交网络与数据挖掘》。社交网络和数据挖掘是计算机学科相关研究中的热点,具体研究涵盖理论、关键技术以及互联网核心应用等各个应用。
本次讲习班邀请到了一系列的学界大牛,包括:
韩家炜——UIUC 教授,ACM/IEEE Fellow
Philip S Yu——伊利诺伊大学芝加哥分校特聘教授,清华大学数据科学院院长,ACM/IEEE Fellow
Wei Wang——UCLA 教授,KDD 2016 Service Award
胡祥恩——孟菲斯大学教授,华中师范大学教授、心理学院院长
James A. Evans——芝加哥大学社会学系教授
唐杰——清华大学副教授
沈华伟——中科院计算所研究员
石川——北京邮电大学教授
宋国杰——北京大学副教授
崔鹏——清华大学副教授
刘知远——清华大学助理教授
赵鑫——中国人民大学副教授
杨洋——浙江大学助理教授
三天的时间里,在社交网络和数据挖掘领域覆盖的范围内,13位老师分别讲述了一个或几个不同的研究方向,可谓场场干货。尤其是韩家炜教授和Philip教授两位学界大牛,从他们的报告可以看出,虽然他们讲的概念不同,用的方法不同,但是他们做的方向基本一致,两位学界巨擘的研究或许也代表了数据挖掘领域当前的一个方向。
下面我们来回顾一下本次讲习班的主要内容(按分享时间顺序总结,排名不分先后)。
Philip S Yu:Broad Learning via Fusion of Social Network Information

Philip 教授作为数据挖掘领域的顶级人物,在报告中详细阐述了他多年来所倡导的一种概念——Broad Learning(广度学习)。

他认为在大数据的时代,我们不仅需要深度学习,更需要广度学习。大数据并不是每个数据都很大或者都很复杂,除了大数据外还有很多数据集可以利用。在大数据时代各种各样的数据都是可以利用的,为了更好地利用这些数据,我们需要定义和获取相关的有用数据,然后设计一种模型将异质数据源融合成起来,再从这些数据源中挖掘信息。
广度学习与深度学习的区别在于,深度学习的「深」来源于模型层数,广度学习的「广」来源于数据以及模型的多样。
根据对 Broad Learning 的考虑,Philip 认为广度学习大致分为三类:
1.对同一个实体上的不同类型信息进行处理,这包括 multi-view,multi-model、multi-source Learning;
2.对不同但相似的实体上的信息的处理,这包括 transfer learning;
3.对通过复杂网络关系相关的不同类型实体的信息进行处理,这包括异质信息网络(Heterogeneous Information Network,HIN)融合。
Philip 教授认为 Broad Learning 的关键任务有两点:1、信息融合;2、知识发现。而其挑战则是,怎么融合以及怎么挖掘知识?因为现在信息融合的方法会随着不同的数据而变,此外在特定的知识发现任务中并不是所有的数据都是有用的。
随后 Philip 教授通过三个例子来详细阐述 Broad Learning 的概念,分别为:POI 预测;跨社交网络平台的知识融合;地点预测。
AI科技评论随后将整理Philip完整报告,敬请期待!
唐杰:Social Network Mining

唐杰在讲座中首先分析了什么是社交网络,以及社交网络的发展历史;随后他讲解了如何做社交网络和数据挖掘的研究、模型及应用。
唐杰认为社交网络就是由一组个人(节点)组成的图形,并由一个或多个相互依赖(「边」)联系起来。这是一个通过收集和分析大规模数据来揭示个人或社会行为模式的领域。
唐杰认为若想理解社交网络是什么,就需要理解整个 internet 的发展。Internet 的发展主要有三个阶段。在信息时代 1.0 时,网络就是由一系列页面(文档)和页面上的链接构成的一个结构。第一个时代一方面越来越多的传统行业不断地加入,于是产生了大数据;同时还伴随着产生了云计算。在信息时代 2.0,用户加入了网络当中,「今日头条」就是这方面典型的应用。在信息时代 3.0,用户开始在网络上了,用户之间形成了交互,这就形成了信息空间和用户空间,通过两个空间信息的融合将产生智能。
有了数据,怎么去发现并充分利用大数据的价值,则需要新型数据挖掘和分析方法,以能够从非结构化数据中获得知识和洞察力。
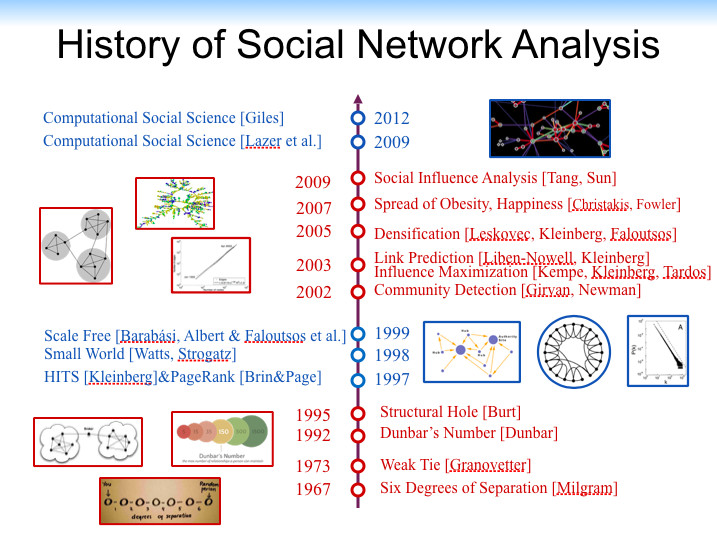
关于社交网络研究的历史,唐杰从 1967 年 Milgram 提出的六度空间讲起,并介绍了 Weak Tie(1973)、邓巴数(1992)、结构洞(1995)、HITS(1997)、小世界(1998)、Scale Free(1999)、Community Detection(2002)、Link Prediction(2005)、Spread of Obesity(2007)、Social Influence Analysis(2009)等。
随后唐杰以如何将 AI(「小木」)应用到慕课以及如何通过手机发红包的数据研究社会现象两个具体案例,讲述了如何做社交网络的问题研究。
在社交网络研究的计算模型方面,唐杰以「Unifying Network Embedding」为主题,介绍了 DeepWalk, LINE, PTE, and node2vec 以及 NetMF 等方法。
最后唐杰以他近期所做的研究 AMiner 为例详细讲述社交网络的研究如何应用到实际问题当中。他还介绍了一些有意思的应用,包括预测红包流向、学堂在线伴读机器人「小木」。
宋国杰:社交网络影响最大化
宋国杰首先介绍了社交网络最大化的基本背景知识,然后对「影响最大化」做出了定义,并举出两个有代表性的算法研究和两个他们做的一些工作。最后总结了一些该领域的未来方向。
所谓扩散就是某个事物在社会系统的成员中通过某种渠道随着时间而不断有更多的人受到影响,用病毒的传播可以更好地理解这个概念,例如 SARS 的爆发、电脑蠕虫等。而在做社交网络的人眼中,类似地就是去研究信息如何在社交网络平台中进行传播,以及如何才能做到传播影响力的最大化(以便做广告等)。
影响最大化一般可以分成几个的模型,例如离散时间模型、连续时间模型、竞争扩散模型或者其他诸如流行病传播模型、投票模型等。其中在离散时间模型大类中 Threshold Model 和 Cascade Mode 两个模型最为基本。
当给定一个模型是,最优化的问题有例如:
1.该如何选择一系列用户,给他们一些打折券,最后能使更多的用户受到影响?
2.该选择那些人群去接种疫苗,能够最小化传染?
3.如果有一些传感器,该如何放置它们以能加速检测到传染病?
在研究的算法部分,宋国杰详细介绍了 Lazy Evaluation 算法和 MIA Heuristic 算法。
随后宋国杰介绍了他们做的四项工作,分别为:
1.如何降低影响力计算所消耗的成本;
2.如何加速收敛过程;
3.当不同信息传播时会发生什么?
4.当动态社会网络中我们会遇到什么。
最后宋国杰说,在实际企业应用中并不一定会需要效率更高的算法,而是倾向于使用比较成熟、稳定的算法。因此如何在具体的场景中找到好的应用点,是驱动这个方面进一步的研究的关键之处。
赵鑫:面向社交媒体平台的商业知识挖掘

赵鑫主要从应用的视角来看社交媒体平台的研究。他首先讲解了社交媒体的研究动机,随后分别介绍了用户意图分析、用户画像构建、用户需求推荐三个研究内容,最后赵鑫给出了相关研究的一些展望。
社交大数据无处不在,且与用户息息相关(社交身份与真实身份绑定);用户不断产生的社交大数据蕴含了丰富的商业价值,如何挖掘这些数据背后的知识则极为重要。传统的电商推荐系统往往只能在自己的站内进行推荐服务,一旦离开了自己的平台,它们的推荐服务就无能为力了。但用户可能会在自己其他的一些社交平台中暴露个人的购买需求,例如在微博上发一条「要换手机了,求推荐」,如果能够挖掘出这样的信息,利用社交状态信息实时地发现用户购买意图则将解决传统电商这方面的不足。
用户购买意图识别根据领域有食物、出行、教育等。它不适用于有监督学习,最多只能做半监督学习。在用户意图分类中,可以构建整体模型的正则化框架,包括文本-关键词正则化、文本-文本正则化、关键词-关键词正则化以及原始估计。
在用户画像中,传统的应用系统可能会遇到新用户的可用信息太少等问题;在这方面如果能够利用社交媒体平台上的信息,则能够很好地解决这些问题。
前两步(意图识别和用户画像)的工作是为了第三步——用户需求推荐。基于受众的产品推荐需要考虑两个维度:性别和年龄,同时产品在受众上也有一定的分布、受众还有一定的图分布。
赵鑫认为他应当围绕数据建立应用问题,通过数据+弱知识+模型得到强知识。此外他认为随着网络实名制的进行,社交身份的形成与刻画也是一个非常重要的研究方向。
James A. Evans:Team Structure and Scientific Advance

James 作为一个社会学家,在报告中分享了他们关于团队合作(众包和大团队协作)的研究。
他首先举了一个例子,在 2010 年贝克教授和他的团地要重新设计酶催化 Diel-Alder 反应,但是效果不佳。他们就开发了一个名叫 Foldit!的蛋白质游戏,不久研究人员就收回了近 20 万个设计方案,酶的活性提高了 18 倍之多。这种众包的现象也能复制到计算机领域呢,例如训练无监督(有监督)机器学习算法或者更复杂的并行任务?
James 的团队研究了 1954 年到 2014 年间 5000 万多份论文、专利和软件产品,以此从中分析团队合作特点。他们发现小的团队在定性工作中表现更佳,大的团队则在定量工作上更具优势。
Wei Wang:Modeling Dynamic Networks
王伟教授在报告中主要介绍了他们实验组 ScAi 在动态网络中的研究。
很多数据是以网络的形式存在的,例如社交网络、互联网、蛋白质交互网络、道路网络、引用率网络等。
考虑到网络的动态性,王伟介绍了将网络结构描述成时间的一个函数的方法:时间因式分解网络模型。也即将矩阵因式分解为两个时间依赖的矩阵。方法很简单,但却很有效,因为当计算的时候不用每次都从头重新计算。这种方法的应用不分有向图还是无向图。在 Link Prediction 问题可以看出这种方法的优势。对于 Anomaly 的检测,则可以直接通过相邻时间边的差异来计算。
除了时间的一致性,还有空间一致性的考虑。通过考虑邻近边之间的相互影响,把空间的因素也考虑进动态网络当中。
通过考虑时间和空间的动态性,则能够更好地预测网络的发展。随后王伟教授讲述了具有时空一致性的边预测(LIST)以及动态属性网络(DANE)和使用动态网络 embedding 的异常检测(NetWalk)。
胡祥恩:语义表示和分析(SRA)以及潜在的应用

胡祥恩教授主要从认知心理学的角度来考虑语义表示和分析(SRA),并介绍了相关的一些应用。
胡祥恩认为数据和信息不能划等号。从心理学的角度考虑的重点不是大的数据,而是人的行为。
胡祥恩介绍了他们在智能导学 AutoTutor 方面的研究。所谓智能导学就是用认知心理学中学习和记忆的原理来设计计算机的系统,使计算机的系统能跟人进行互动。胡祥恩的研究与其他研究团队的智能导学研究主要的区别在于,更强调自然语言的交互。他在报告中详细介绍了智能导学的框架及应用。
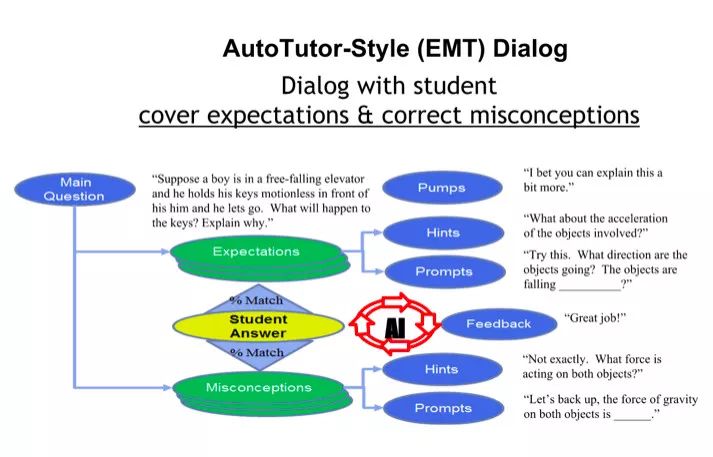
自然语言的交互首先就需要创建语义空间,这包括首先构建语料库,其次将语料库编码进语义空间,最后才是应用。针对一个给定的应用(尤其是教育领域),胡祥恩认为我们应当选着最好的语料库、用最好的编码方法,用在最恰当的应用上,否则就是对孩子生命的不负责任。
随后他就 AutoTutor 中如何进行选择语料库、编码和应用做出了详细讲解。
石川:异质信息网络建模与分析

石川首先回顾了社交网络的三个发展阶段:2000 年以前的对象特征挖掘、2000 年之后基于交互式网络出现的链接关系挖掘,以及随后出现的对象之间有多种复杂关系的异质信息网络挖掘。
随后他介绍了异质信息网络的基本概念,并对比了异质信息网络与同质信息网络、多重关系网络、复杂网络之间的异同。他认为挖掘异质信息网络的优点在于异质信息网络无处不在,包含了大量丰富的语义和综合信息;但同时也面临着许多挑战,例如结构复杂以及语义难挖掘等。
随后石川通过几个具体的实例来介绍如何进行异质网络数据挖掘,分别为相似性度量(HeteSim)、推荐(SemRec)和恶意软件检测(HinDriod)。其中最后一个为今年 KDD 的最佳应用论文。
最后石川总结了异质信息网络研究的现状和未来研究的方向。他认为异质信息网络仍然是一个年轻的、有前途的研究领域。对于大数据的 5V(Volume、Velocity、Variety、Veracity 和 Value),异质信息网络对其中的多样性(Variety)将有很大的促进。其挑战在于如何解决更复杂的问题(例如知识图谱)、如何变得更加强大以及如何处理更大的数据。当然异质信息网络处理中也有很多机会,包括解释、表示和分析。石川整理了异质信息网络领域较为重要的论文资料,详细信息可以访问石川的个人主页(http://www.shichuan.org/)。
崔鹏:网络嵌入:在向量空间中启用网络分析和推理

崔鹏在报告中主要介绍了他们围绕网络嵌入的一些工作。崔鹏介绍说,现在大数据的体量和计算机的计算能力都在程指数增长,如果按照这种趋势发展,那么对大数据的研究将不成问题。
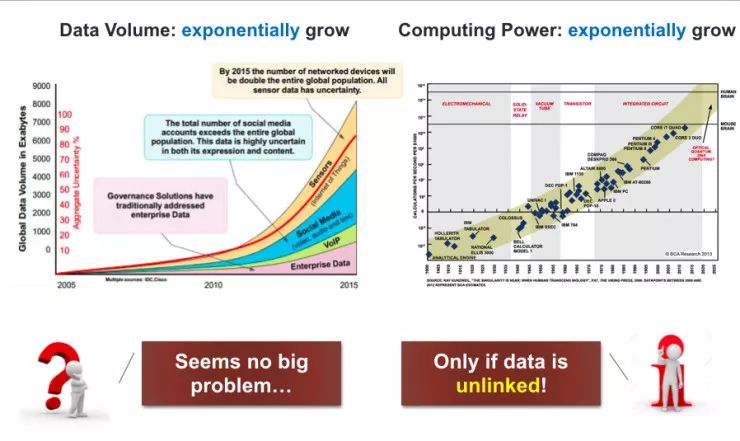
但是现实的数据之间是存在关联的,这就导致数据的增长不仅仅是指数,而是指数的指数。
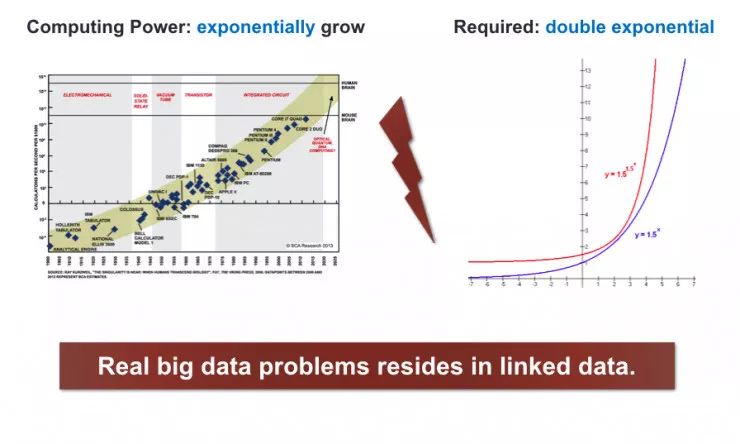
对于这种大规模的网络数据,他认为由于 link 的存在,就会造成由迭代和组合造成的复杂性、由耦合带来的可平行性以及由节点间的从属关系带来的机器学习应用的一些问题。
崔鹏随后介绍了将网络嵌入到一个向量空间,那么关于 node importance、community detection、Network distance、link Prediction 等等问题都可以转化为向量空间中的问题。如何将网络嵌入到向量空间呢?崔鹏认为有两个目标:1、能否从向量空间重构原网络;2、向量空间是否支持网络表示。
介绍完这些背景知识后,崔鹏介绍了他们最近的两项工作。其一为从更复杂结构角度考虑的 Hyper-network Embedding,其二为从更多挑战性的特性角度考虑的 Dynamic Network Embedding。
崔鹏认为现实应用中网络数据还远没有被挖掘,主要面临着复杂性和可扩展性的瓶颈。对这一问题最本质的解决就是网络表示学习,而网络嵌入则被证明是一个有前景的方法,但仍然还有很长的路要走。
沈华伟:在线社交媒体中的信息传播预测

沈华伟主要从信息传播预测的角度来讲述,报告内容主要分为两个部分。
沈华伟首先分享了影响力最大化的研究。所谓影响力最大化,就是给定一个社会网络找到一个尺寸固定的子节点集合,最大限度地扩大影响力。对于这项研究有两个主要问题:如何确定人际影响节点间的传播概率?如何设计高效、准确的影响力最大化算法?现存的算法有 Greedy 算法、Heuristic 算法等,但是它们面临着可扩展性-准确性的困境。沈华伟他们的解决方法就是在蒙特卡洛模拟中重用相同的集合,并提出了 StaticGreedy 算法。
随后沈华伟介绍了传播预测。对于传播预测现存的方法有两大类:feature-based methods 和 temporal analysis。但是这些方法忽视了人群动态是一个反映集体参与的过程。于是他们提出一种 process-based 方法。他认为群体动态是一个 arrival process 能够捕获一个信息如何积累关注,基于特征的方法将会被合并到特征学习方法中。
在报告的最后,沈华伟做出了两个预测:
1.在未来会由 feature-engineering 变到 feature-learning;
2.明年社会网络将会成为突破的一年。
刘知远:语言表示学习与计算社会科学

刘知远的基本观点是:计算社会科学研究比的是「想法」。他认为语言是研究人类社会的重要角度,他举了很多有意思的例子。例如哈佛大学研究团队利用 google books 并扫描识别的 1800 年到 2000 年之间的 500 万种出版物,通过不同关键词使用频度随时间的变化,分析人类文化演进特点(https://books.google.com/ngrams);斯坦福大学 Leskovec 团队收集 9 千万篇新闻文章,利用引号抽取流行语句作为模因,通过跟踪模因使用频率变化能够及时有效地把握美国政治、经济和文化生活(http://www.memetracker.org/)。此外还有研究在线社区中语言使用变迁模式、利用名人出生死亡信息来研究文化中心变迁、研制微博关键词应用。
刘知远认为以上这些都是「前表示学习时代」——基于符号的表示,这些研究中都是把没个词表示为 one-hot 的模型。这种表示模型不能表示不同词之间的关系。随后他介绍了分布式表示学习,在这种表示中对象均被表示为稠密、实值、低维向量;向量之间的距离则能够表示不同词之间的关系。
基于这种表示,word2vec 的学习模型开始发展。这种学习模型在词汇相似度计算上有非常好的效果,同时还能习得词汇间隐含关系、发现词汇语义层级、建立跨语言词汇表示、建立视觉-文本联合表示、检测词汇语义变迁。
随后刘知远介绍了一份发表在《nature》上的来自认知科学的研究成果,即语言分布式表示在大脑中的体现,利用分布式表示绘制了词汇的大脑地图。研究发现不同的词对脑区的激活并不是局限在某一个脑区,而是分布在大脑各个部分;意义相关的词汇所激活的大脑区域相似。
最后刘知远还详细讲述了计算社会科学的研究,包括融合 HowNet 的词义表示、知识图谱等。他认为分布式表示提供了比符号表示更加强大的计算能力,具有更强更深的洞察能力,但关键也看如何能创造性地用起来。
杨洋:社交网络中的群体用户行为分析与表示学习
杨洋的报告内容主要有两个主题内容,其一为群体用户的行为分析,其二是面向网络的表示学习。
针对群体用户的行为分析,杨洋介绍了三个具体的研究案例。案例一从社会学角度出发,研究移民者的都市梦——感知移民群体的行为模式,并给出城市规划导向性的建议。在这个案例中,杨洋通过使用上海全网通话的 5400 万用户的 7 亿条元数据(无通话内容,只有拨打和接听数据)研究了不同群体(本地人、老移民者、新移民者)的行为模式差异。他们发现新移民者融入新环境有三种模式:朝向本地人靠拢,朝向老移民者靠拢和移民失败。他们发现移民者抵达都市后的前两周的行为模式决定了他最终是否能够移民成功。
随后他讲述了他在做的一个电信领域的案例——通过用户通话记录来判断一个用户是否是电话诈骗分子并挖掘诈骗分子的诈骗策略。数据集与上面的案例相同,但构建了一个有向图。他们发现诈骗分子在打出电话的频率比普通用户要高 200 倍之多、诈骗分子打出电话对象之间的关系极弱。在时间分布上发现诈骗分子打电话的时间分布与上班族类似。
案例三是金融学领域的——根据用户通话模式来判断借贷是否会逾期还款的金融风控,即给定一名没有任何借款记录的新客户通过他的通话记录来判断他是否会逾期还款。
在总结社交网络群体用户行为分析的研究时,杨洋说很多情况下我们并不需要相关的专业知识,但需要了解用户的行为。他举例说为了研究王者荣耀用户的行为,他和他的学生打了一个月的王者荣耀。
随后杨洋介绍了他们组两篇 AAAI 2018 收录文章的内容。其一为 Dynamic Network Embedding by Modeling Triadic Closure Process,介绍了爱你想动态网络的表示学习;其二为 Representation Learning for Scale-free networks,介绍了面向无尺度网络的表示学习。
韩家炜:大规模语料库的多维分析

韩家炜在报告中分享了他们在将大数据变成 Actionable Knowledge 的一些研究。首先他介绍了如何去做。

在现在的大数据中有 80% 的数据都是以无结构的文本、图片、社交关系等表示。韩家炜介绍说他们的研究组有三个 keywords,分别为:结构化(structuring)、网络化(Networking)和挖掘(Mining)。因此他们的工作有三步曲,首先是怎么从文本数据中挖掘出隐含的结构;其次是将文本转化为网络和 TextCube;最后是从网络和 TextCube 中挖掘出 Actionable Knowledge 。
在挖掘数据之前,先将数据转化为网络和 TextCube,韩家炜认为这样处理更 powerful,他举了一个论文 Co-Authors 预测的例子说明这个问题。
随后韩家炜介绍了近期的几项从无结构文本中挖掘结构的工作。首先他介绍了短语挖掘的工作,即把原始的语料库翻译成高质量的短语和分段的语料库。其次是让短语有意义,他介绍了实体/关系的解析工作。随后,他介绍了 MetaPAD 工作,即元模式驱动的来自大量文本语料库的属性发现。最后他还介绍了多方面分类挖掘(Multifaceted Taxonomy Mining)。
做以上这些研究的目的是用来建立一个多维的 TextCube。韩家炜介绍了如何将文件正确地放入一个 Cube Cell,并用大量数据和少量 labels来构建 TextCubes。韩家炜认为要想把 Big Data 变成 Big Knowledge,很重要的一条就是要有结构;现在这种结构有两种,其一是异质网络,其二是 TextCube;用这两种结构去挖掘出知识是很 powerful 的;现在如何将异质网络和 TextCube 结合起来,还没有解决。
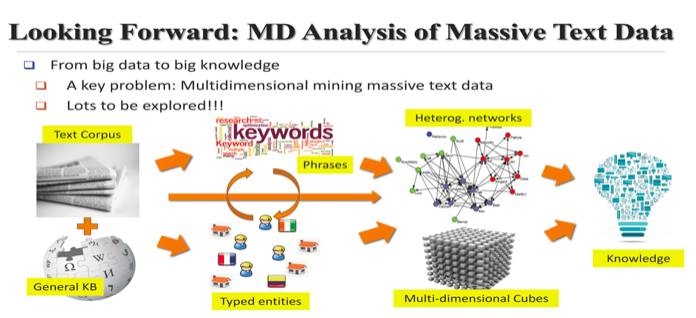
从无结构数据到知识是一条很长的路,韩家炜说近二十年所做的工作正是沿着这条路走的;现在这条路还只是一条小路,期望最终能成为一条康庄大道。
AI科技评论随后将整理 韩家炜 完整报告,敬请期待!
Panel
除了这些精彩的报告外,ADL 还组织了一场精彩异常的 Panel 环节。Panel 上有韩家炜、刘知远、石川、沈华伟、杨洋以及从现场选出的一位学员。

下面AI 科技评论整理出 Panel 环节的部分精彩问答。
提问:社交网络研究的挑战是什么?
刘知远认为社交网络研究的挑战有两个层面,第一是:知识是一个重要的切入角度;第二,从技术上 Embedding 和 Deep Learning 会成为重要的技术手段。
韩家炜认为从无结构数据中提取出有结构数据,从结构数据中提取出网络和 TextCube,以及从后两者中提取出知识极为重要。要想自动化,很重要的一条就是从大量数据中挖掘出结构来。
沈华伟提出一种比较新颖的观点,我们总是把网络化数据 Embedding 到一个空间中,那么是否可以反其道而行之呢?也即是把算子迁移到网络上,还是把网络数据迁移到算子上。
杨洋认为无论是 Embedding 还是社会计算学,做的算法都缺少可解释性。
提问:如何和其他领域的学者的领域知识进行融合?
沈华伟认为和其他领域的学者合作主要就三件事情:
1.看他们关心什么,我们能否帮上忙;
2.看他们研究的套路是什么,我们能否借鉴;
3.做完上面两步,你就会发现其实大家做的都一样,只是看问题的角度不同、语言不同。
所以其实一点都不难,关键是你抱着什么目的去做这个事。
提问:领域知识在当前深度学习发展如此火热下怎么应用?
韩家炜认为深度学习仍在发展。现在深度学习仍然需要大量 label data。所以如果能将领域知识和深度学习结合起来可能会让学习更有效。此外,现在很多学者在提倡怎么去做小样本数据的深度学习,所以当前一个很重要的矛盾就是 Big Data 和 Little Data 之间的矛盾。因此不是领域知识没用,而是 Deep Learning 现在还没有走到能够有效应用领域知识这一步。
AI 科技评论总结:本期 ADL 讲习班由唐杰和刘知远等老师组织,邀请了国内外一众大牛学者,包括数据挖掘领域顶尖学者韩家炜和Philip S Yu等教授,以及诸如胡祥恩、James A. Evans 等心理学和社会学的知名学者。三天的时间里,13位学者分别从各个角度对社交网络和数据挖掘进行了详细的、全方位的解读。
从学员的角度来看,可以发现不仅仅是计算机学科的人对社交网络和数据挖掘感兴趣,一些心理学、管理学等专业的学生也前来听讲,甚至还包括许多高校老师、企业技术人员以及国家安全部门的一些人员。
有这么多的人对这一领域抱有浓厚的兴趣,或许如沈华伟老师所预测的,明年社交网络可能会是突破的一年。
————— 给爱学习的你 —————
本次课程早早就报满,受场地限制并未提供更多名额,而且 CCF 还推出更多 ADL课程。为了让更多人工智能爱好者、业界从业者、科研研究者们都能看到 CCF ADL 课程,人工智能培训平台 AI慕课学院获 CCF 独家线上视频版权,点击阅读原文或扫描下面👇二维码即可完整再现各路专家现场授课、交流的场景。

————— 新人福利 —————
关注AI 科技评论,回复 1 获取
【数百 G 神经网络 / AI / 大数据资源,教程,论文】
————— AI 科技评论招人了 —————
AI 科技评论期待你的加入,和我们一起见证未来!
现诚招学术编辑、学术兼职、学术外翻
详情请点击招聘启事
————————————————————