多任务深度学习框架在 ADAS 中的应用 | 分享总结

在 8 月 10 日AI 研习社邀请了北京交通大学电子信息工程学院袁雪副教授给我们讲解了在高级辅助驾驶系统(ADAS)中的多任务深度学习框架的应用。
ADAS 系统包括车辆检测、行人检测、交通标志识别、车道线检测等多种任务,同时,由于无人驾驶等应用场景的要求,车载视觉系统还应具备相应速度快、精度高、任务多等要求。对于传统的图像检测与识别框架而言,短时间内同时完成多类的图像分析任务是难以实现的。
袁雪副教授的项目组提出使用一个深度神经网络模型实现交通场景中多任务处理的方法。其中交通场景的分析主要包括以下三个方面:大目标检测(车辆、行人和非机动车),小目标分类(交通标志和红绿灯)以及可行驶区域(道路和车道线)的分割。
这三类任务可以通过一个深度神经网络的前向传播完成,这不仅可以提高系统的检测速度,减少计算参数,而且可以通过增加主干网络的层数的方式提高检测和分割精度。
观看完整视频需要大约 54 分钟。
一、任务分析
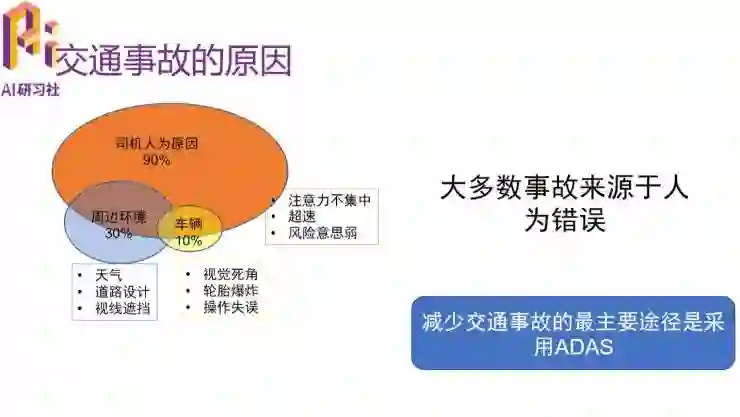
WHO 在 2009 年统计的一个数据显示,在全世界范围内每年由交通事故死亡的人数有 123 万人。但是我们知道,在朝鲜战争中,整个战争死亡的人数也差不多一百多万。也就是说,每年死于交通事故的人数差不多等于一次非常惨烈的战争的死亡人数了。根据 WHO 统计,在全世界范围内每年由交通事故造成的死亡人数有 123 万之多;而发生交通事故 90% 是由司机人为原因造成的,比如注意力不集中、超速、安全意识弱等等。所以目前减少交通事故的最主要途径通过采用高级辅助驾驶系统(ADAS)就是减少认为错误。

对于 ADAS 系统,基本上包括这些功能:夜视辅助、车道保持、司机提醒、防撞提醒、车道变换辅助、停车辅助、碰撞疏解、死角障碍物检测、交通标志识别、车道线偏移提醒、司机状态监测、远光灯辅助等。这些功能是 ADAS 所必备的。
为了实现这些功能,一般其传感器需要包括视觉传感器、超声波传感器、GPS&Map 传感器、Lidar 传感器、Radar 传感器,还有一些别的通信设备。但是我们在市面上看到的大多数传感器其功能其实是比较少的,例如 mobile I,它只有车道保持、交通标志识别、前车监测和距离监测的功能,但并不全面。从厂家或者用户的角度来说,自然我们希望能用最便宜的传感器来完成更多 ADAS 的功能。最便宜的传感器基本上就是视觉传感器。所以我们设计方案时就想,能不能通过算法将视觉传感器实现更多 ADAS 系统的功能呢?这就是我们整个研发的初衷。
此外,我们还需要考虑 ADAS 的一些特点。ADAS 系统(包括无人驾驶)是在一个嵌入式平台下进行的,也就是说它的计算资源很少。那么我们也必须考虑如何在这样一个计算资源非常少的基础上,保证 ADAS 系统能够快速且高精度地响应,同时还能保证多任务的需求。这是我们第二个要考虑的问题。
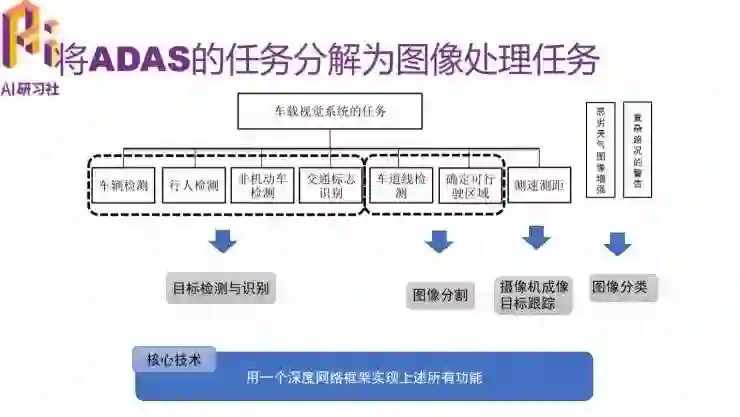
为了解决以上两个问题,我们首先把 ADAS 的任务分解一下。如图所示,我们将 ADAS 的任务分解成目标检测与识别、图像分割、摄像机成像目标跟踪、图像分割。我们过去一年多的研发工作其实就是,用一个深度学习框架来同时实现上述这四个的功能。
对于一个前向传播的网络,其计算量和计算时间主要取决于它的参数数量,而 80% 的参数都来自全链接层,所以我们的第一个想法就是去掉全链接层。其次,网络越深,它的参数就会越多所以如果我们把目标检测与识别、图像分割、摄像机成像目标跟踪、图像分割做成四个网络的话,就会有 X4 倍的参数。
所以针对这两个考量,我们用一个主干的网络来做前面的运算,然后在后面再根据具体的任务分成多个小的分支加到主干网络上。这样多个图像处理的任务就可以通过一个主干网络的前向传播来完成了,其参数大大减少,计算速度也变的更快。同时我们也能实现多个任务同时进行的需求。另外,在最后我们还可以将多个结果进行融合,驾到训练过程的调整中,这样就可以提高我们结果的可信性。
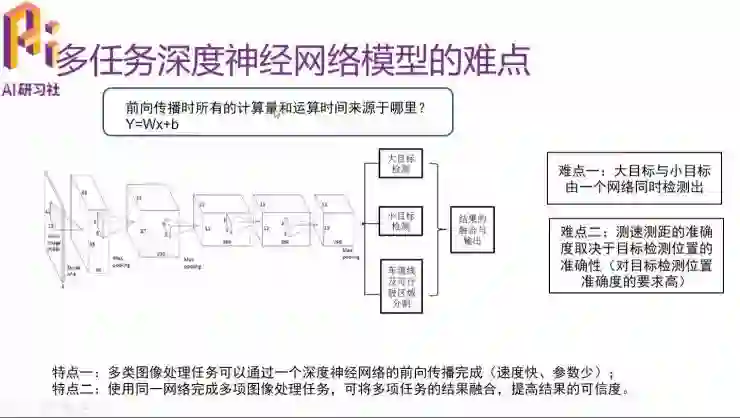
但是在这个过程中我们也碰到一些难点。第一个难点就是我们在同一个网络中需要将较大的目标(例如车辆)和较小的目标(例如交通标志)同时检测出来。第二个难点是,测速测距时我们需要的目标的位置是非常精确的,目前这个问题我们还没有解决。
二、模型结构
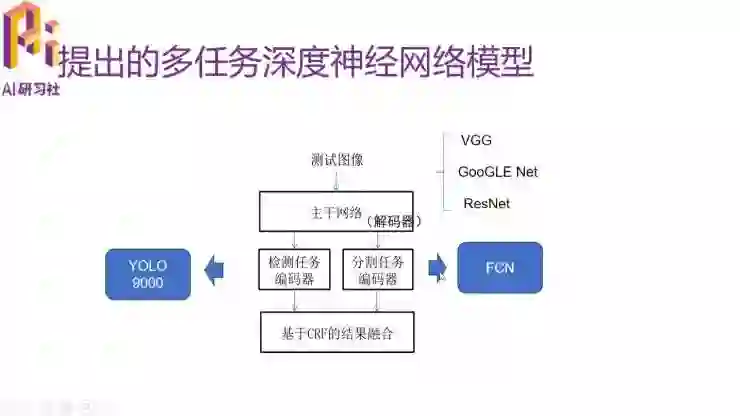
这个是我们设计的网络的一个基本结构。它分为几个部分:主干网络(我们称为解码器)、多个分支(我们称为编码器)和基于 CRF 的结果融合。现在这个网络我们只设计了两个编码器,一个是检测任务编码器,还有一个是分割任务编码器,以后我们还可以增加其他的编码器。结果融合,主要是想用它来影响主干网络的一些权重选择。主干网络,我们选择了一些比较有人气的算法,例如 VGG 16、GoogleNet、ResNet 等。分割任务编码器我们用了 FCN 编码器,检测任务编码器我们用了 YOLO9000 编码器。
1、主干网络
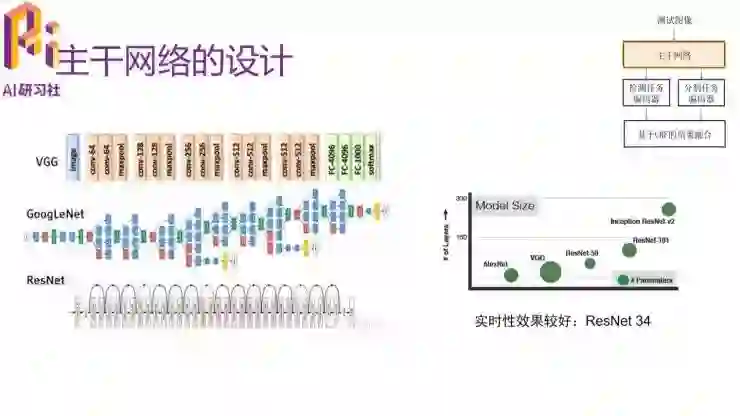
下面我们来详细看一下这个网络各个部分。首先我们来看主干网络。主干网络我们使用了 VGG、GoogleNet 或者 ResNet。这几个是可选择的。从右侧的这张图(纵轴是网络深度,圈的大小表示模型的大小)我们可以看到 ResNet 在深度和大小上都比较好,我们选择使用 ResNet 可以有比较好的实时性。
2、FCN 语义分割解码器
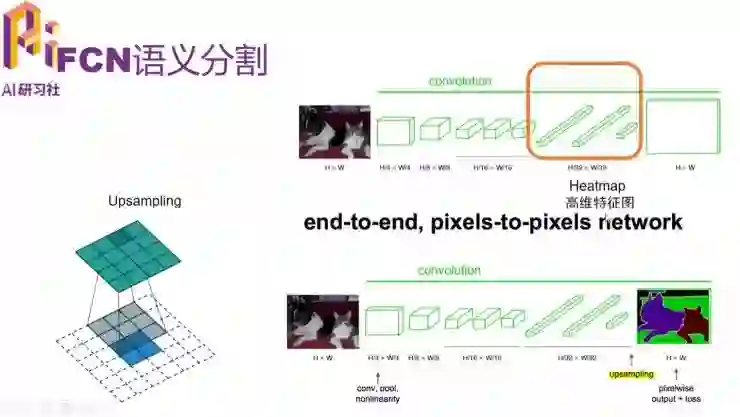
然后我们看一下 FCN 语义分割解码器。在神经网络中,一张图片经过主干网络后,再对其提取高维特征图。其实这个过程就是用 pooling 的方法给它降维。结果到了输出高维特征图时,它只有原图像的 1/32 大小了。随后我们采用上采样把它升维成原图像大小。上采样的过程就如左侧所示,这个示例中我们将 2*2 的图像上采样成 4*4 的图像。
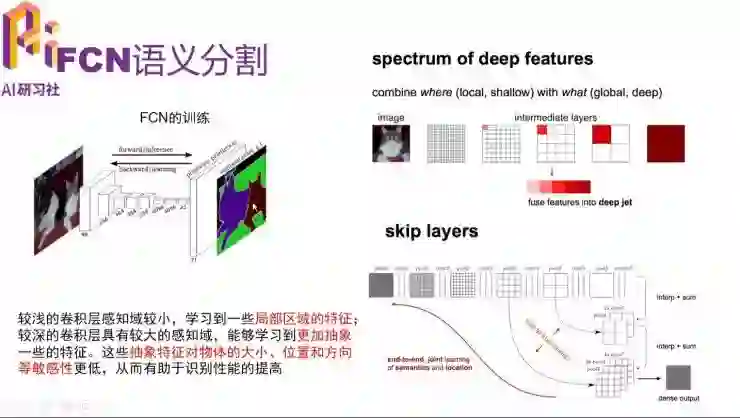
上采样的结果就是解码器预测出来的,我们将它与标注好的图像进行比较运算,算出 loss,然后对权重进行修改。在上采样中一个问题就是,比较小的物体是计算不出来的。我们知道一些较浅的卷积层感知阈比较小,它会包含更多比较局部的信息;而较深的卷积层具有较大的感知阈,它能够学习到更加抽象的信息。于是 FCN 就通过将 pool3、pool4 和 pool5 的信息叠加在一起进行上采样,这样就可以做到同时上采样多个尺度的信息了。
3、目标检测 / 识别解码器 YOLO
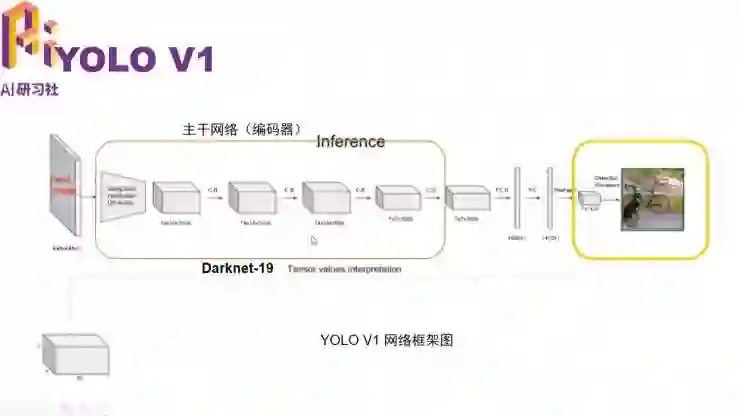
其次我们再来介绍一下用于目标检测/识别的解码器 YOLO。我们使用的是 YOLO V2 的解码器,但这里我们先介绍一下 YOLO V1。这是 YOLO V1 的主框架,它的主干网络是 Darknet19,我们不用管它。我们重点关注编码器的过程。主干网络输出的特征图,这种特征图会用 1*1 的卷积核给正规化成 7*7*30 的特征图。那么这个 30 是什么呢?
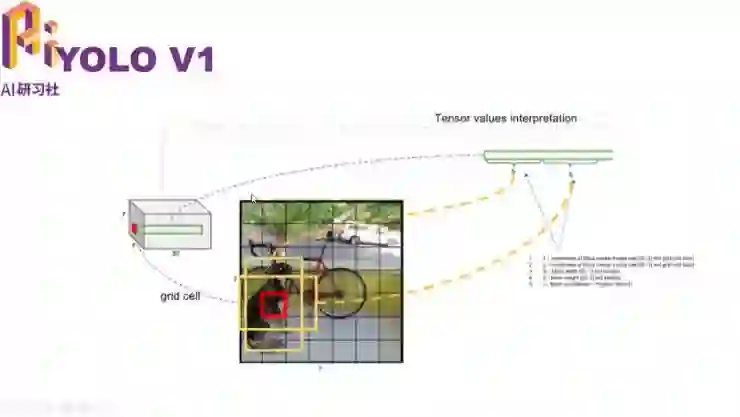
在这样一个 7*7 的矩形框中,每一个方形框用一个点来表示。然后我们分别用 5 维表示包含这个方形框的一个矩形框,其中 4 维表示 x、y、z、w,另外一维为 confidence。
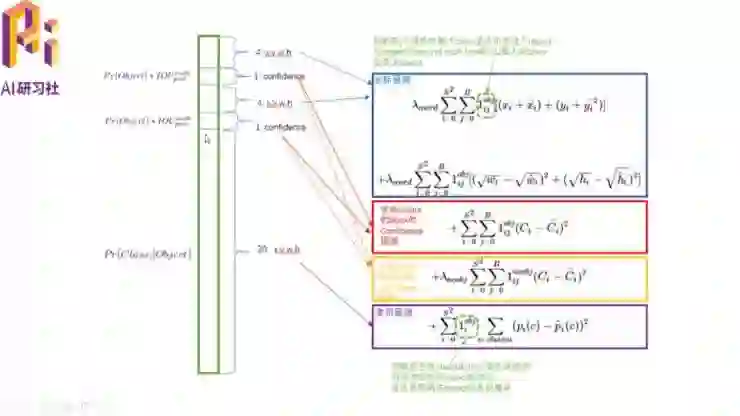
在 YOLO V1 中 30 维的前 10 个为两个这样的矩形框。它们的(x,y,z,w)分别表示了坐标预测,而另外一维为 confidence 预测。另外的 20 维为类别预测(也就是说在模型中有 20 种可能出现的例如汽车、行人之类的模型 )。
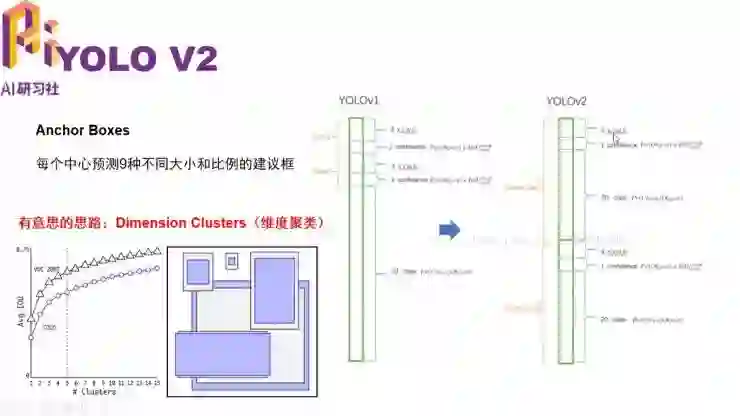
YOLO V2 与 V1 最大的不同就是采用了 Anchor boxes。所谓 Anchor boxes 就是每个中心预测(例如 9 种)不同大小和比例的建议框,每一个建议框对应一个 4 维的坐标预测、1 维 confidence 预测和 20 维的类别预测。它提出一个非常有意思的思想就是维度聚类,也即现在训练集里通过聚类的方式算出 Anchor boxes 的大小。这样,例如它从 9 个 boxes 选出 5 个 boxes。于是对于 VOC 数据集,总共就 5*(4+1+20)=125 个输出维度。

YOLO V2 Anchor boxes 的选择以及维度聚类的思想对于我们车载摄像的问题是更有效的,因为我们摄像机的位置是相对固定的,所以我们可以算出每一个目标的大小都是相对比较固定的。
我们在 YOLO V2 的基础上也做了一些改动。首先是我们做了一些细粒度特征,来检测小目标。其次我们还在浅层特征中进一步地做坐标预测,然后加到我们的整个预测当中,这样可以提高小目标的预测。
4、一些思考

在这个研究的过程中,我们做了一些思考。
首先,在计算机视觉领域里,低中层视觉问题更关注原始视觉信号,与语义信息的联系相对松散,同时也是许多高层视觉问题的预处理步骤。本届 CVPR 有关低中层视觉问题的论文有很多,涵盖去模糊、超分辨率、物体分割、色彩恒定性(color constancy)。
其次,在最后的层中抽象的特征对分类很有帮助,可以很好地判断出一幅图像中包含什么类别的物体,但是因为丢失了一些物体的细节,不能很好地给出物体的具体轮廓,指出每个像素具体属于哪个物体。
我们该如何将浅层特征和深层特征结合起来呢?这其实还需要进一步的研究。
三、数据库建立

在数据库这方面,我们发现国内的路况与国外路况很不一样,且中国的车的种类也多种多样。所以我们开发了一种半自动标注软件,也就是我们可以通过算法自动完成车辆标注,同时我们还可以手动修正误差较大的标注。目前我们已经标注了 5 万张矩形标注数据集。我们力争在年底能够开放数据集,另一方面我们也能协助企业建立数据库。

另外在数据库建立方面,我们还要拓展一下数据库类型。例如通过原来白天的图片,我们可以生成黑夜的图片,增加到我们的训练样本中去。
四、结果显示




新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
我们应当如何理解视频中的人类行为?
▼▼▼





