![]()
在处理非结构化数据的问题上,人工智能和深度学习方法一直都表现出众且广为人知,无论是在自然语言处理、知识库自动构建,还是图像视频的识别和生成应用中,都有很多成熟案例。
然而对于结构化数据的研究,似乎已经被人工智能和深度学习忘之脑后。
结构化数据普遍存在于各类商业应用软件和系统中,例如产品数据存储、交易日志、ERP和CRM系统中都存在大量结构化数据
,这些结构化数据仍应用着陈旧的数据技术处理,如基于规则的系统,决策树等。这样的方法需要人工进行特征提取,操作繁琐且需要耗费大量人力进行数据标签。
虽然人工智能的最新发展已经从非结构化数据中挖掘出了巨大价值,但对结构化数据而言,其研究和应用也是不可忽视的,因为结构化数据对于驱动企业的业务发展、营收、数据安全以及数据治理方面都有着重大意义。
不同于非结构化数据,结构化数据的AI研究一直存在着一个巨大的挑战,那就是其对于数据质量的高度敏感性。
对于非结构化数据而言,人们或许可以接受分辨率不高的视频,略带瑕疵的图像识别。但对于拥有大量结构化数据的大型企业来说,其核心业务数据是不容许有丝毫差错的。比如对于制药公司来说,药品的剂量、价格和数量即使出现细微的数据错误,都有可能带来巨大的灾难。
研究这些核心业务数据(结构化数据)在人工智能上的应用,是具有极大价值的,但受限于数据质量的高要求,大型企业在这类研究上举步维艰。尽管人工智能在结构化数据上的应用研究已经有数十年的时间,但目前仍进展甚微。
数据背后的业务复杂性,基于特定规则和逻辑的系统复杂性,需要人工介入的数据清洗和准备工作的高成本,都阻碍着这一研究的发展。要在结构化数据AI应用上有所成果,首先需要解决人工数据清洗和准备的问题,找到极少或者没有人为干预的自动化方法,才能使得这一应用可落地可拓展。
这也是为什么机器学习方法能适用于结构化数据准备和清洗的原因,最终的解决方案需要能够提取企业数据特征并且理解毫不相干的数据上下文,能够从大量数据集中训练出模型,预测数据质量,甚至能提出数据质量的修复建议。
将这样的模型应用于数据准备和清洗中,可以解决结构化数据长期以来存在的问题 —— 需要大量人工介入的数据准备和清洗工作。这样的解决方案有以下的要求:
-
可以将业务规则在内的所有信号和上下文,函数依赖和键等约束条件以及数据的统计属性进行组合。
-
能够避免构建大量的规则,同时可以兼容极端情况。在许多情况下,结构化数据中的规则管理比清洗噪音数据更具挑战性,成本更高。
-
最终,模型所提供的预测应用于标准的数据质量测试中,能够传达一种 “信心”:模型的预测能够解决大多数情况,而人工,只需要专注去处理特殊的案例。
虽然结构化数据在AI应用的研究中困难重重,研究者们还是找到了一些方法并有所进展。处理结构化数据并不仅仅依赖于数据本身的特征(稀疏,异构,丰富的语义和领域知识),数据表集合 (列名,字段类型,域和各种完整性约束等)可以解码各数据块之间的语义和可能存在的交互的重要信息。
举个例子,两个不同的城市不可能都对应相同的邮政编码,一个项目的总预算不可能超过其计划的开支。这都是可以明确提供的条件约束,这些条件约束增强了机器学习模型在结构化数据处理上的能力,而不仅仅是做统计分析。
处理结构化数据的其中一大挑战在于,结构化数据可能是异构的,同时组合了不同类型的数据结构,例如文本数据、定类数据、数字甚至图像数据。其次,数据表有可能非常稀疏。想象一个100列的表格,每列都有10到1000个可能值(例如制造商的类型,大小,价格等),行则有几百万行。由于只有一小部分列值的组合有意义,可以想象,这个表格可能的组合空间有多么“空”。
如果没有任何结构、领域知识和条件约束,就很难了解数据如何生成及其准确性。因此,在构建结构化数据准备和清洗的解决方案过程中,可总结出存在的三个主要挑战:
-
如何将背景知识转化为模型输入,以解决数据稀疏性和异构性带来的挑战?在预测某个列中的值时,我们如何在机器学习模型中传递关键约束、函数依赖关系、否定约束和其他复杂的完整性逻辑作为模型输入?
-
在训练数据有限且存在脏数据,甚至有时都没有训练数据的情况下如何学习模型呢?以识别结构化数据错误的模型为例,该模型查找各种数据错误,包括错别字、缺失值、错误值、矛盾事实、数据错位等问题。使用非常有限的可用错误样本和可用数据中存在的这些错误来训练这样的模型,就是需要克服的挑战。
-
模型如何拓展到大规模应用?如何能支撑上百万个的随机变量?如果把实验条件下训练出来的模型,直接应用到复杂商业环境中的结构化数据,毫无疑问,结果肯定是失败的。
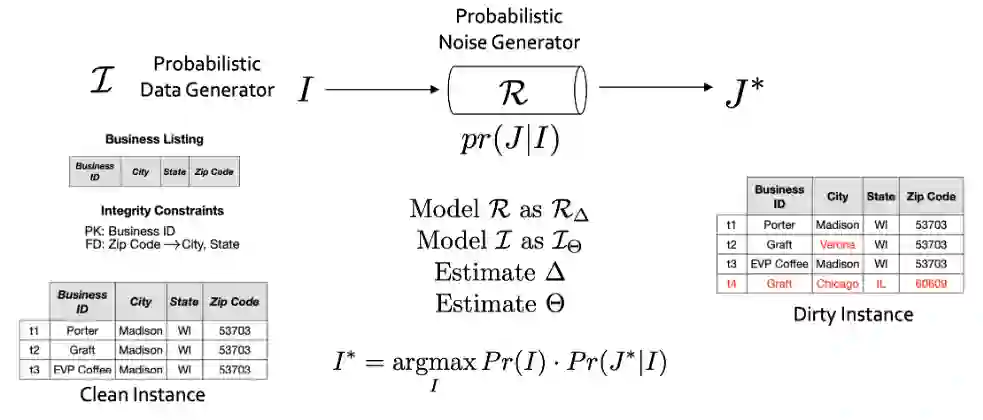
对此,滑铁卢大学教授 Ihab Ilyas开发了一个用于结构化数据的AI平台——inductiv,训练模型理解数据的生成和“污染”过程。inductiv可用于结构化数据的准备和清洗,例如错误检测、预测缺失值、错误校正、空值补齐、数据融合等。Inductiv归属于学术开源项目HoloClean(www.holoclean.io),该项目是 Ihab Ilyas 团队在2017年与滑铁卢大学、威斯康星大学麦迪逊分校和斯坦福大学合作启动的。
HoloClean采用经典的噪声通道模型来学习数据的生成和“污染”过程。完整的研究论文:https://cs.uwaterloo.ca/~ilyas/papers/DeSaICDT2019.pdf。
HoloClean利用所有已知的领域知识(例如规则)、数据中的统计信息以及其他可信任来源作为属性,来构建复杂的数据生成和错误检测模型,此模型可用于发现错误并能够提供修复建议,给出最有可能的替换值。
图 1: “干净”的数据是按照一定的生成过程生成的。作者也观察到了脏数据的生成过程 。通过建模和参数化,我们将数据清理转变为了一个推断问题。
虽然这样的模型已经帮助我们将数据清理和数据错误检测问题转变为机器学习中的推理问题,但要训练出表达力足够强,能够将应用规模化的模型,还是极有难度的。
针对上文提到的挑战,如何使用很少的样本数据进行训练的问题, Ihab Ilyas 在论文中提出了解决方案。
-
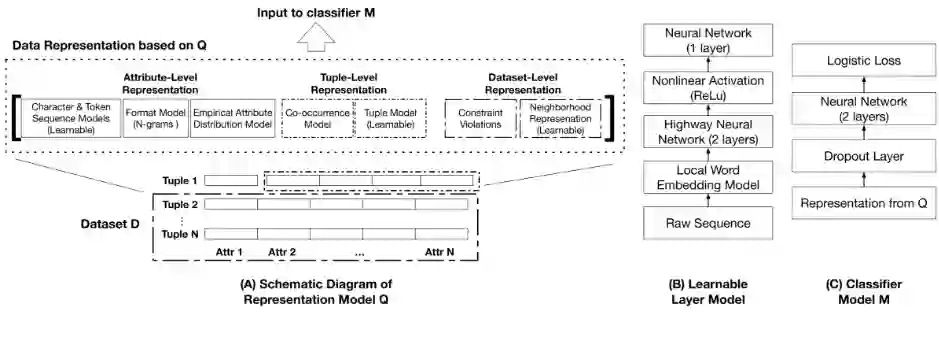
模型。数据错误的异构性和异构性带来的其他影响,导致很难找到适合的统计特征和完整性约束作为属性,来帮助区分错误值和正确值。这些属性对应着数据库的属性级、元组级和数据集级的特征,而这些特征都是用来表示数据分布的。图2中描述的模型学习了一个表示层,该层通过捕获这些多级特征,来学习应用于错误检测的二分类器。
-
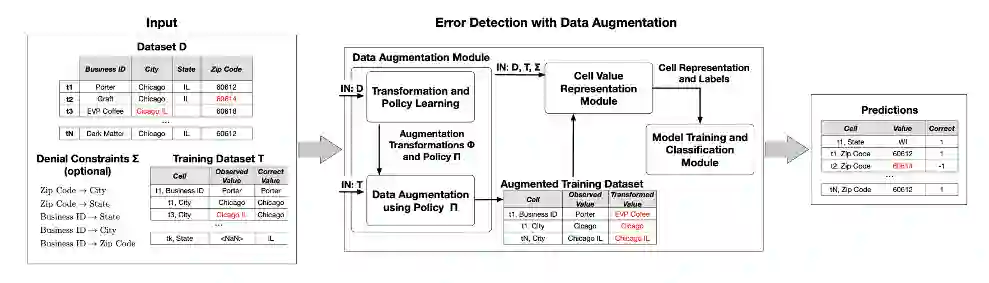
数据不平衡。数据错误的种类非常多,但通常样本数据中出现的错误数据是很少的,因此机器学习算法在面对不平衡的数据集时,训练出来的结果通常不太乐观。因此,不常见的数据错误,其特征经常被识别为噪音,因此被忽略。与常见数据错误相比,不常见的数据错误其识别的错误率很高。如图3,我们提出了应用“数据扩增强”方法,按照学习到的错误生成策略来制造许多“伪”错误,使用少量的真实数据错误来学习策略参数。当样本的错误数据有限时,这一方法可以用于增加错误数据在样本数据中的分布。
图3:使用生成错误示例的策略来解决训练数据类别不均衡的问题
3、inductiv 引擎:现代 AI在结构化数据中的应用
诸如数据准备、数据清洗、错误检测和缺失值填补之类的数据问题,都可以应用一个统一的、可规模化的推理引擎进行建模。这样的引擎要求能够对“结构化”数据的生成以及错误的产生进行建模。更重要的是,结合上文提到的各种挑战,这一模型还需要纳入一些现代机器学习原理:
-
-
目标列/值建模所需要的各种上下文的表示,例如学习异构数据的嵌入空间
-
自我监督学习,尽可能利用所有数据。比如使用其他值来重建某些观察到的数据值
-
-
进行一些系统级别的优化,例如学习数据分区和本地索引,以完善模型的可拓展性,提高模型适应多种数据分布的能力。
Inductiv将之前提到的所有研究,融合于一个统一的AI内核中,它可以支持多种数据准备和清洗的应用。
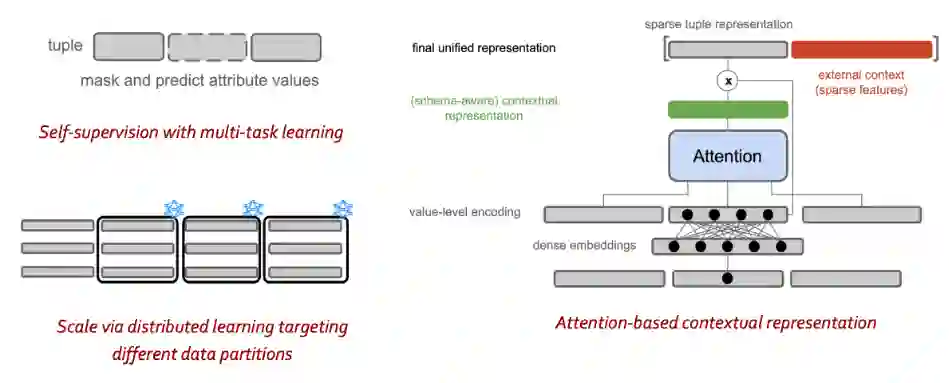
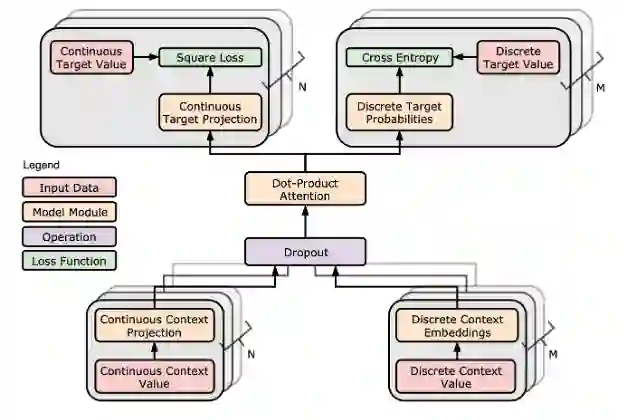
图 4 描绘了前文提到的多种方法的核心组成部分,以处理不同的数据类型(例如量化数据的回归分析,定类数据的分类)。这些方法包括了基于注意力的上下文表示机制、分布式学习、数据切片以及多任务学习的自我监督。
在MLSys 2020论文中,作者提出了一种基于注意力的学习架构,用于混合类型结构化数据的缺失值填补(图5)。
图4:Inductiv 统一推理引擎的核心组成部分
图5:基于注意力的上下文表示和多任务学习的示例架构
如今的商业化数据中,绝大部分重要数据都是结构化的,然而由于对数据质量的高要求,使得很多有价值的研究都望而却步。
通过采用机器学习的方法,我们可以将结构化数据的数据准备和清洗问题都视为一个统一的预测任务,不过这种方式存在着规模化,异构性,稀疏性以及复杂语义和专业领域知识的挑战。
而Inductiv引擎作为首个用于结构化数据处理的可扩展AI平台,则成功解决了这些挑战!
via https://towardsdatascience.com/ai-should-not-leave-structured-data-behind-33474f9cd07a