提供基于transformer的pipeline、准确率达SOTA,spaCy 3.0正式版发布
机器之心报道
spaCy 3.0 正式版来了。

具有新的基于 transformer 的 pipeline,这使得 spaCy 的准确率达到了当前的 SOTA 水平;
提供了新的 workflow 系统,帮助用户将原型变为产品;
pipeline 配置更加简单,训练 pipeline 也更加轻松;
与 NLP 生态系统的其他部分有许多新的和改进的集成。
pip install -U spacy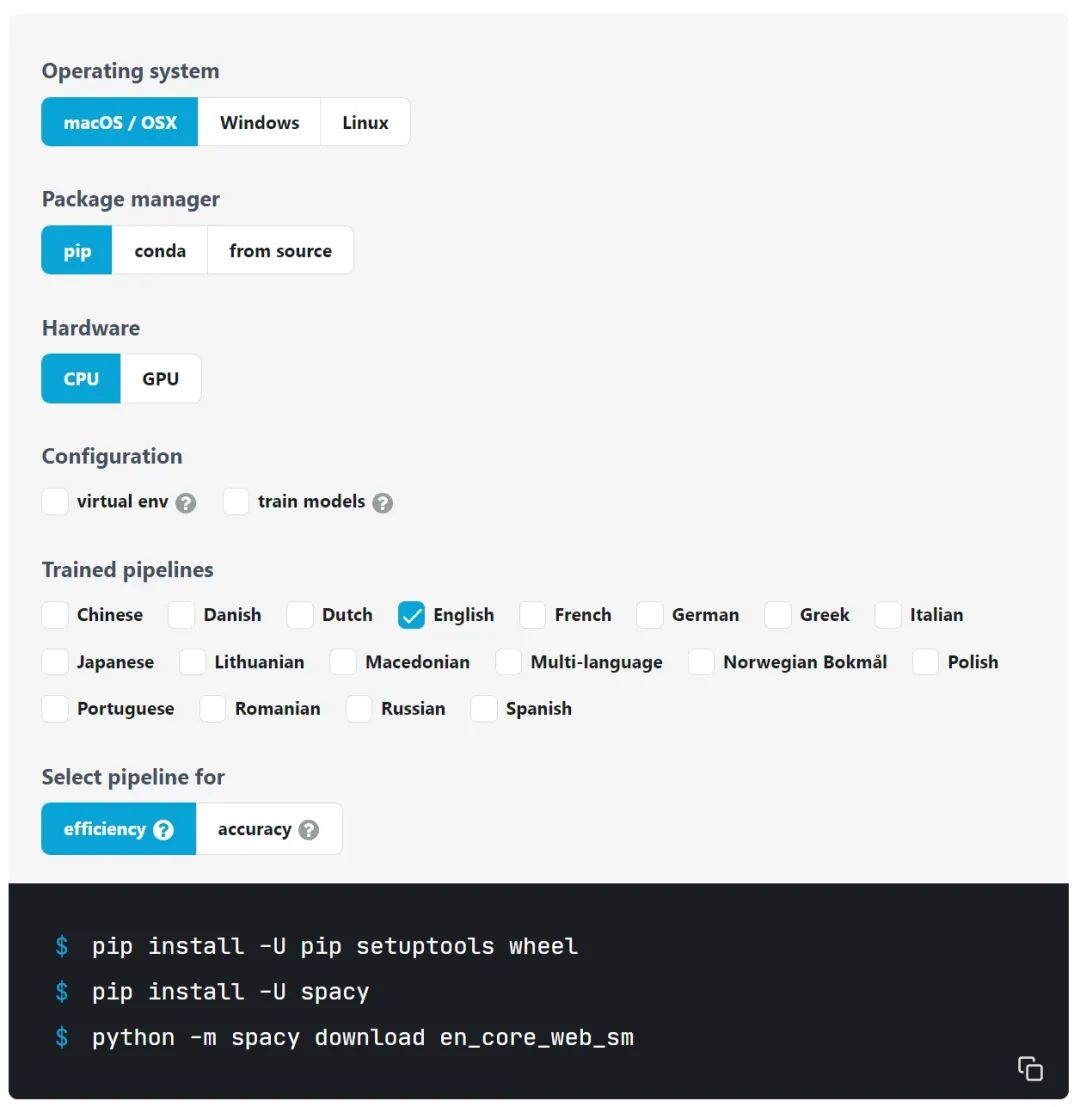
基于 Transformer 的 pipeline,支持多任务学习;
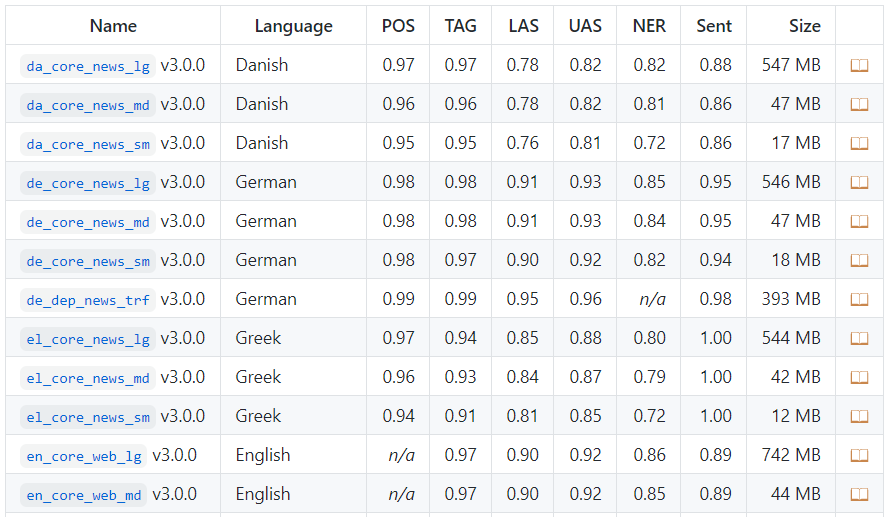
针对 18 + 种语言再训练的模型集合以及 58 个训练的 pipeline(包括 5 个基于 transformer 的pipeline);
针对所有支持语言再训练的 pipeline,以及用于马其顿语和俄语的新的核心 pipeline;
新的训练工作流和配置系统;
使用 PyTorch、TensorFlow 和 MXNet 等任何机器学习框架实现自定义模型;
管理从预处理到模型部署等端到端多步骤工作流的 spaCy 项目;
集成数据版本控制(Data Version Control, DVC)、Streamlit、Weights & Biases、Ray 等;
利用 Ray 的并行训练和分布式计算;
新的内置pipeline组件:SentenceRecognizer、Morphologizer、Lemmatizer、AttributeRuler 和 Transformer;
针对自定义组件的全新改进版 pipeline 组件 API 和装饰器;
从用户训练配置的其他 pipeline 中获取经过训练的组件;
为所有经过训练的 pipeline 包提供预建和更高效的二进制 wheel;
使用 Semgrex 运算符在依赖解析(dependency parse)中提供用于匹配模式的 DependencyMatcher;
在 Matcher 中支持贪婪模式(greedy pattern);
新的数据结构 SpanGroup,可以通过 Doc.spans 有效地存储可能重叠的 span 的集合;
用于自定义注册函数的类型提示和基于类型的数据验证;
各种新方法、属性和命令。
报告内容涵盖人工智能顶会趋势分析、整体技术趋势发展结论、六大细分领域(自然语言处理、计算机视觉、机器人与自动化技术、机器学习、智能基础设施、数据智能技术、前沿智能技术)技术发展趋势数据与问卷结论详解,最后附有六大技术领域5年突破事件、Synced Indicator 完整数据。
识别下方二维码,立即购买报告。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com


