沈春华:如何窥一斑而知全豹--Dense Per Pixel Prediction | VALSE2017之九
点击上方“深度学习大讲堂”可订阅哦!
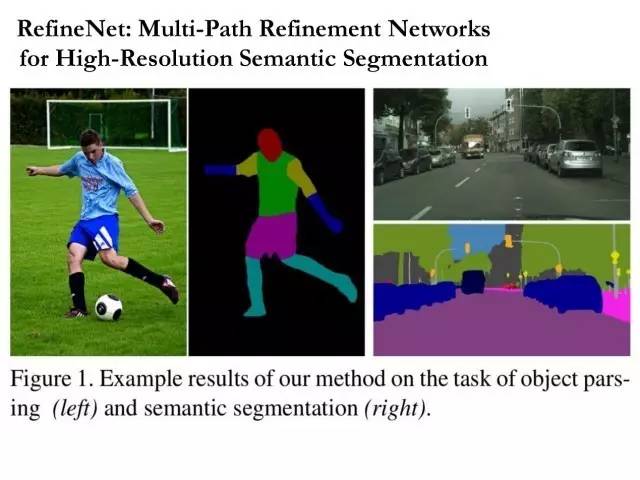
编者按:古语有云,窥一斑而知全豹,讲的就是从局部到整体的知识累进过程,在CV领域,Dense Pixel Prediction就是一个从图像像素的理解出发,建立对图像内容理解的基础性方法。在本文中,来自澳大利亚阿德莱德大学的沈春华教授将会讲述,如何使用深度结构化学习的方法来实现Dense Per Pixel Prediction,该方法在单目图像深度估计、语义分割、以及low-level图像处理领域均有很好的应用。大讲堂在文末特别提供文中提到所有文章的下载连接及沈教授组内开源代码的下载链接。

在这个报告中,将会介绍我们最近使用深度结构化方法也就是结合深度学习和图模型(如CRF)做Dense per-pixel prediction的一些工作:
1. 怎样提升单目图像深度估计的效果;
2. 利用深度结构化学习结合上下文信息进行语义分割;
3. 在卷积神经网络中,重复的下采样操作,池化或者步长大于一的卷积都会导致特征图的分辨率下降。我们提出RefineNet通过residual connections使得较深层的网络也可以利用浅层网络的特征。

Dense pixel prediction问题:通俗理解就是对每个像素预测它的标签。这个问题主要有两个应用:
1. 深度图像估计,从单幅图像中把图像的深度信息估计出来。
2. 像素标定。 这里还会展示一些low level processing的结果, 相当于per pixel prediction。

图像理解
在过去几十年中,传统视觉领域研究的最多的就是给出一张图片,预测与输入图像相关的一个或者几个标签,我们可以把这样的问题归成是稀疏的。然后,随着研究的发展,问题越来越复杂。在深度学习出现之前,我们用条件随机场也对这个问题做了很多年。基本上是用结构化学习的思路,希望给出一张图片可以预测一个跟这个图片相关的标签。

这是深度学习从2012年开始到现在的发展。从ImageNet上的一些结果,可以看得出来这些年深度学习发展的速度非常快。
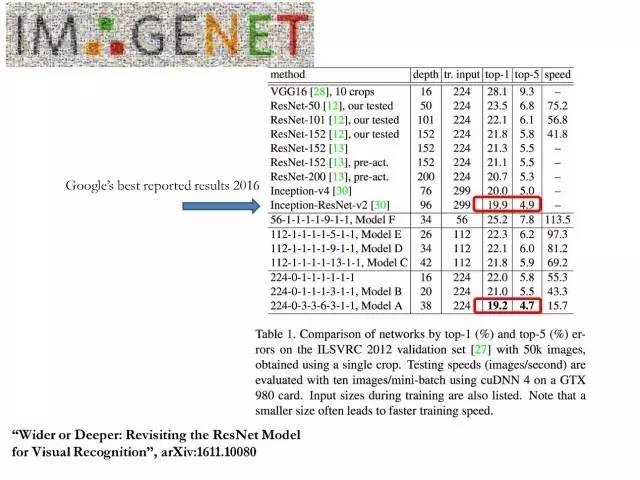
在介绍像素标记和dense per pixel prediction之前,先看一个结果,这是去年年底我们组里做的一个工作。如果大家做分类,像素标记等相关的问题可以尝试一下我们训练的一个38层的ResNet模型,在分类任务和像素标记问题上,都得到了超过152层ResNet模型的结果,代码和训练好的模型都放在github(https://github.com/itijyou/ademxapp)上。

Per pixel prediction这个问题本身其实非常容易理解,也就是给出一张图片,我们希望有一个算法对每一个像素都估计一个标签。
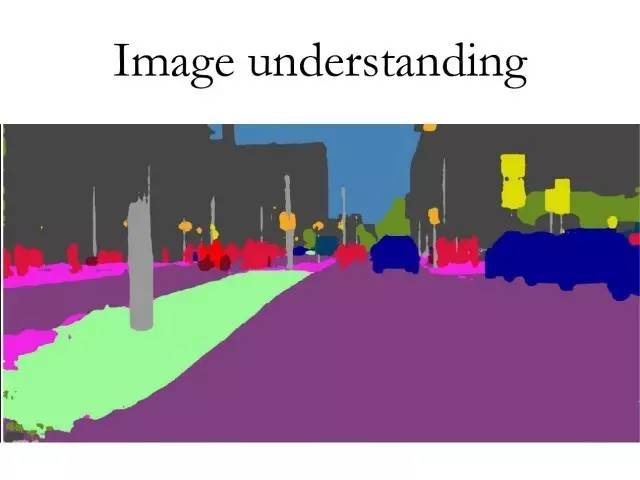
这幅图像是我们的算法在研究自动驾驶的数据集—Cityscapes上的结果。上一张为输入,这一张图像是算法输出的结果,图中一共包含19类。
深度估计

如何从单目单帧图片做深度估计(一)
第一个应用为单目图像深度估计。由于深度估计与工业界的一些应用结合紧密,比如自动驾驶技术,因而这一应用是非常有意义的。

如何从单目单帧图片做深度估计(二)
通俗的理解就是给出一张输入图片(左边第一列),我们希望有一个算法可以从这张图片中直接把深度信息估计出来,也就是将拍摄这张图片时的场景中每个像素与相机的距离估计出来。
做计算机视觉领域的应该都知道,这个问题最经典的解决思路是做立体视觉,也就是给定一对立体的图片,然后用多视图几何的算法去寻找左右两图的相关性,然后结合相机的参数把深度估计出来。
而我们想做的是,在没有一对图片而是只有单目单帧图片的情况下,甚至在没有视频只有图像的情况下,对左侧的输入图像做深度的估计。
上图实验结果中,中间一栏为真实图像是用激光扫描得到的。右边一栏是我们算法的输出,不同的颜色表征不同的距离。

如何从单目单帧图片做深度估计(三)
直接从单幅图像中估计出深度信息本身是一个非常有用的,当然也是非常困难的问题。这里给出了一些可能的应用场景和挑战。
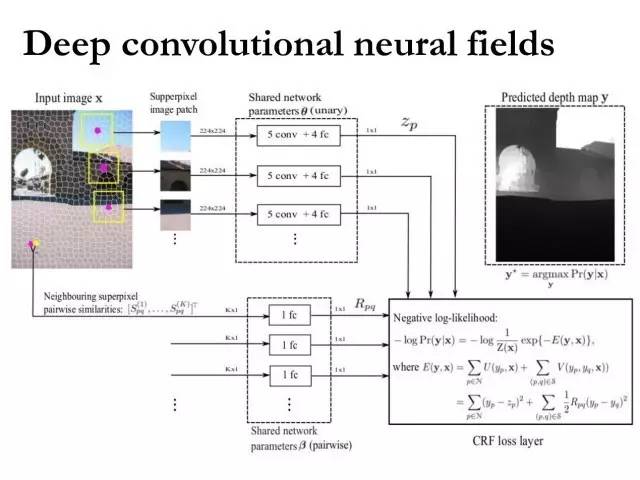
Deep Convolutional Neural Fields
这是我们2015年CVPR的算法的基本框架。既然要做像素级的预测,肯定是要考虑像素和像素之间的依赖关系,传统算法的角度来看就是条件随机场(CRF)或者马尔科夫随机场,也即在每个像素上面建立一个图模型,然后用节点和节点之间的边缘连接来模拟像素和像素之间的依赖关系,所以这是一个经典的CRF Markov问题。
现在有了深度学习这样的方法,也有了大数据,我们就可以利用卷积神经网络把预测函数学的更好,这个预测函数如果是standard CRF的话,那么只有两项:unary term和pairwise term的。这里的unary term是一个CRF,然后pairwise term又是一个CRF,我们可以用经典的最大似然估计来估计所有的参数。这些参数就包含在了unary term和pairwise term这两个网络里,然后就可以求其梯度,使用SGD算法对网络进行优化求解。
这里会涉及到CRF 的推理问题,其实在求梯度的时候,每一次的计算都需要去做一次推断。在该问题上,我们的算法对其进行了简化,假设噪声是高斯模型,并且变量是连续的,在这种情况下,其实最大似然估计是有个闭式解。所以梯度是比较容易求解出来的。
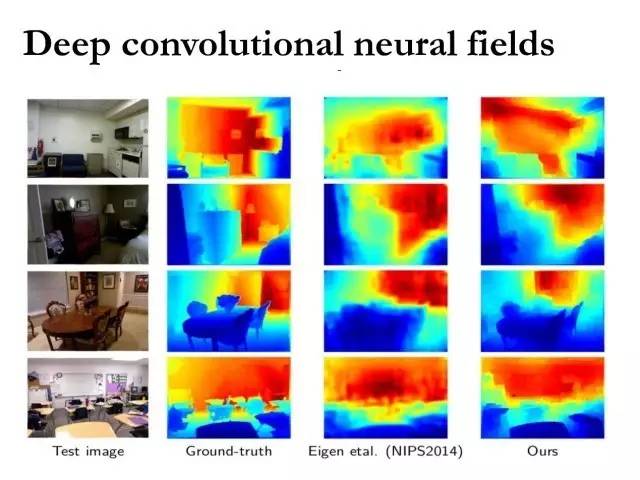
Deep Convolutional Neural Fields
这里是一些实验结果,针对室内一些场景的深度估计。
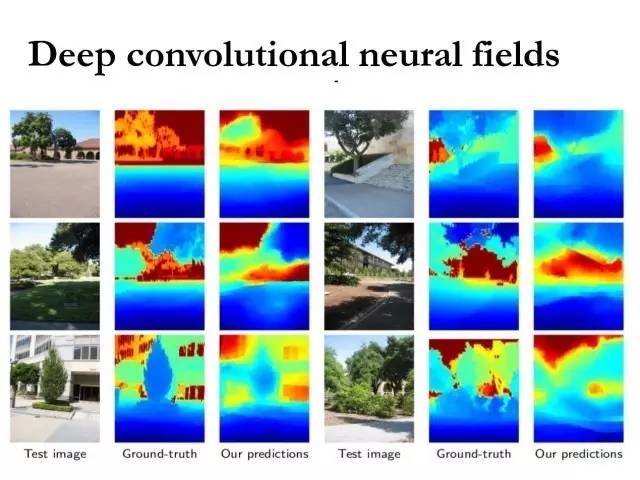
Deep Convolutional Neural Fields
这个展示了室外一些场景的深度估计结果。

鉴于现有深度估计的数据集规模太小,我们最近为深度估计问题做了一个数据集(RDIS)。去年NIPS上有一篇论文“depth in the wild”。他们用人工标注了一个大概有几十万数据的一个大数据集,但是那个数据集最大的问题是:每一张图片只标记了两个像素。只标出了一对像素深度之间的关系,所以我们做了一个更大的数据集,每一张图片也不只标了一对像素,而是几千对像素。
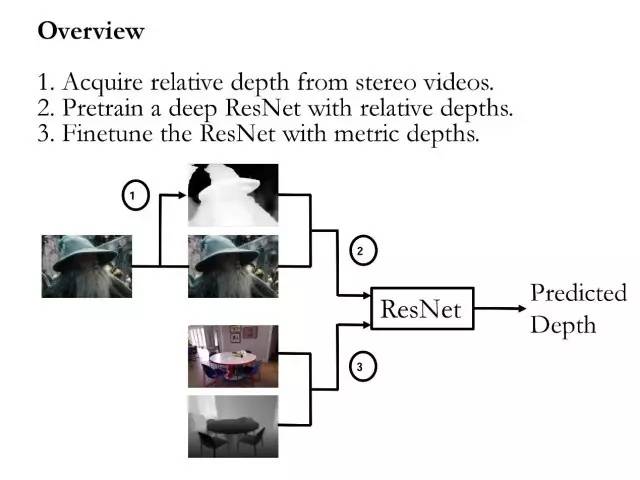
因为这个数据集标注的是相对深度,那么我们就可以简单把损失函数换成相对损失函数,可以用来学习相对的深度关系。

数据集是用了很多三维的电影。用立体匹配的算法做了一系列预处理得到的,生成相对深度的具体步骤如下:
1. 使用绝对差(AD)匹配损失,用半全局匹配思想来生成初始视差图。
2. 后处理视差图:纠正对象的模糊或者丢失的边界信息,平滑处理对象和背景之间的差异,这是由经验丰富的电影制作公司的员工完成的。
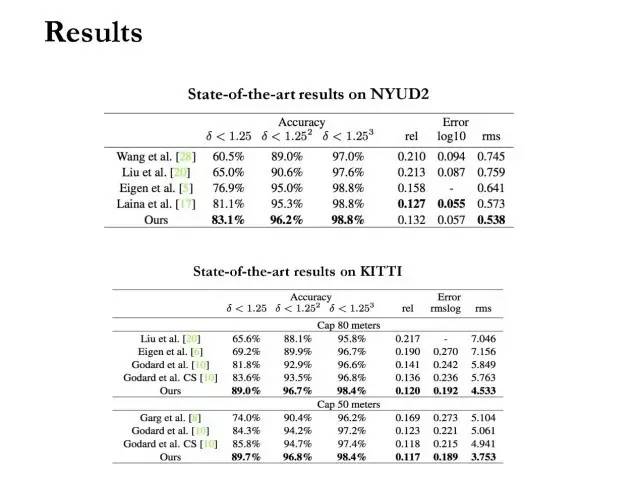
这里是该算法一些数值的结果。

这里是是一个3D视频,左图是算法自己生成的(此处应有三维的效果)。
下面是一个根据估计的深度做手机照片处理的一个例子(Images are from Dean's recent slides)
Pixel labeling
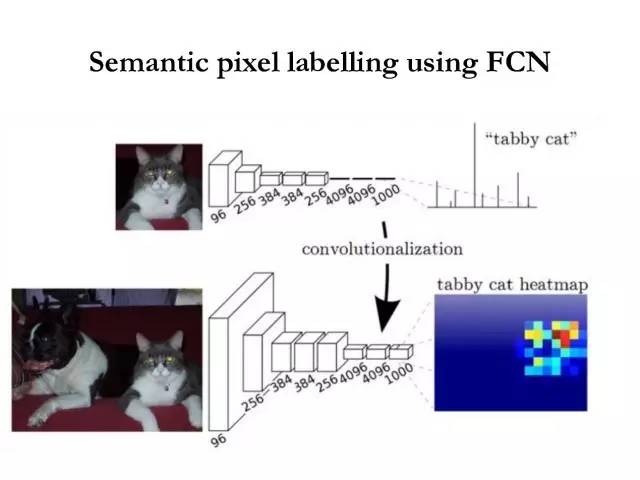
用全卷积网络做像素标记
在过去一年到两年的时间里,我们更关注的是像素标记。像素标记现在最经典的框架就是全卷积神经网络,当然全卷积神经网络可以用在各种各样的问题上面,不仅仅是像素标记,也用在目标检测等等。这样的好处就是卷积只做一次比较节省时间。

这幅图像是Cityscapes——自动驾驶相关的数据集上做的一个像素标记的结果。
像素标记:如何结合深度学习与可连续的CRF
刚才谈到的深度估计基本上就是将深度学习和可连续的CRF结合起来,最大的优点就是既可以利用深度学习把非常有效的特征学习出来,同时在做预测的时候也考虑了像素和像素之间的依赖关系。那么很显然在做像素标记问题的时候,也可以把两个技术结合在一起使用。
几个相关工作:
1. 我们的一篇CVPR2016就做了这样一个工作,其中跟深度估计最大的区别就是做像素标记的时候,需要估计的变量是离散的,因为不是连续的,所以做CRF inference的时候,会比较复杂,不可能有闭式解,在离散的情况下,每一次进行梯度计算都需要做一次CRF inference。从计算量的角度来讲是不能忍受的。去年我们有一个CVPR的论文,就是把piecewise近似训练CRF技术跟深度学习结合起来。这样就避免了每一次算梯度需要做CRF inference。这个算法的优点就是:unary term和 pairwise term是可以分开进行训练的。
2. 我们NIPS2015的一个工作,使用深度学习去学习CRF inference里面基于messages passing里面的信息。同样的问题,也是为了考虑在high level上怎样把深度学习跟CRF结合起来。或者把深度学习跟结构化学习结合起来。后来我们发现这样去做能够带来准确率的提升,但同时计算量也增大了,不单单是训练的时候,其实对于很多应用来说,更关注的是测试的时候的推断的时间,要用CRF算法的时候,做推断肯定会用到CRF的推断,这个就成了额外的一个开销;所以从实际应用这个角度考虑:如果需要加快计算速度,也许把CRF直接跟深度学习结合起来,并不一定是一个好的思路。用CRF的目的就是希望模型能够考虑像素和像素之间的关系。
3. 今年CVPR我们组的一个工作,希望可以对卷积神经网络不同级别的特征:从低级到中级、高级进行重用。我们的模型希望将这些特征里面的信息融合在一起用来帮助做预测。使用这样的模型,也许不借助CRF也能得到一个比较好的结果,这是我们的基本想法:兼顾计算量和准确率。
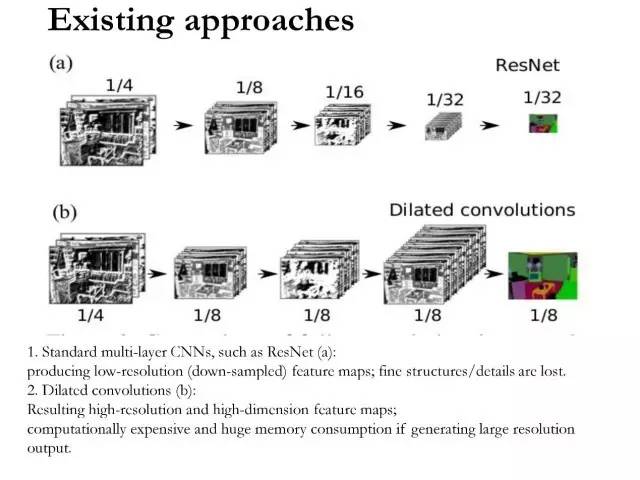
这里是用全卷积神经网络做像素标记的最经典的两个例子:
a) 第一种用ResNet,当然VGG也是一样,如果用步长大于1的卷积或者做一次池化的话,网络中的特征图的分辨率会被降采样,最后一般会得到一个原输入图片的1/16或者1/32的低分辨率的输出。
b) 第二种情况可以加入convolution with dilation,所谓dilation就是卷积核是有“空洞”(hole)的,在这种情况下,可以不做特征的下采样,同时又能兼顾这个网络的感受野,因为对很多高级的问题来说感受野的大小是非常重要的,但是会带来的一个问题是计算量比较大。
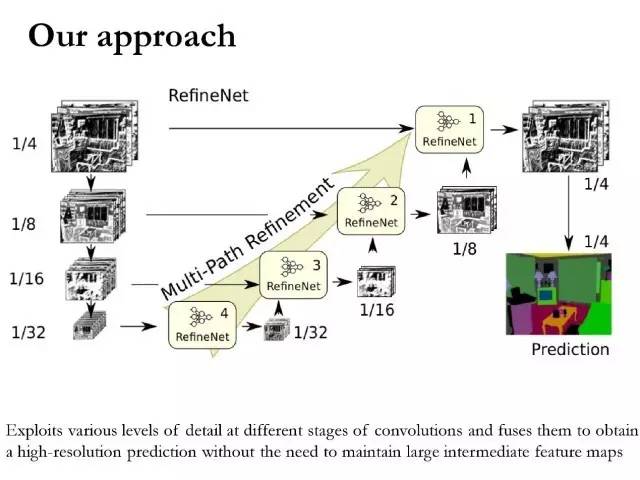
我们提出的一个方法,思路也很简单:
尽可能将FCN前面层的这些特征也利用起来,去预测最后的输出。然后将这些组合起来一起使用,所以这里修改出来的是这样一个框架。因为这个网络会做几次下采样,网络中间很多层的特征图都会不一样,怎样把这些不同的分辨率的特征图利用起来去进行预测非常关键。
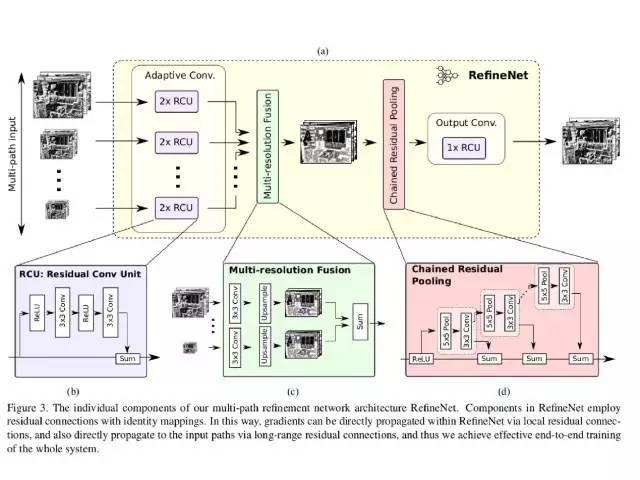
这个是上采样的网络,当然这个模型的设计也不是唯一的。这里是针对ResNet进行设计的上采样的网络。

这一模型具备如下优势:
1. 利用高分辨率输出的多层次抽象特征
RefineNet以递归方式用细粒度的低级特征提炼低分辨率的(粗糙的)语义特征,这用来生成高分辨率的语义特征图。我们的模型是灵活的,因为它可以级联并且以多种方式修改。
2. 通过短距离和长距离连接实现有效的梯度传播
我们级联的RefineNets可以做到有效的端到端训练,这对于预测效果来说是至关重要的。RefineNets中的所有组成部分采用基于个体图的残差连接,这样的梯度可以直接通过短程和长程的残差连接来进行传播,这可以做到高效率和高效果的端到端训练。
3. 链式残差池化
我们提出了一个名为“链式残差池化”的新的网络成分,它可以在大图像区域获取背景语义信息,通过多种尺寸的窗口有效池化特征,并且通过残差连接和权重的学习将这些特征融合在一起。
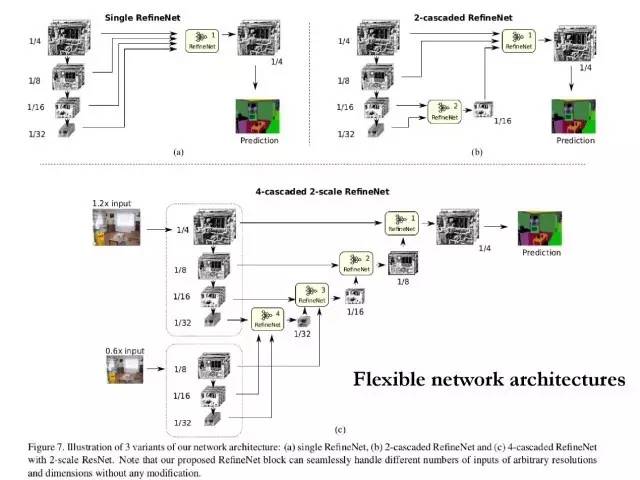
这个框架的优点是:网络的设计是比较灵活的,可以根据自己的需求用不同的组合进行设计,可以设计出不同的网络结构,从而得到不同的结果。

这里是在不同数据集上得到的结果,代码已在github上开源: https://github.com/guosheng/refinenet
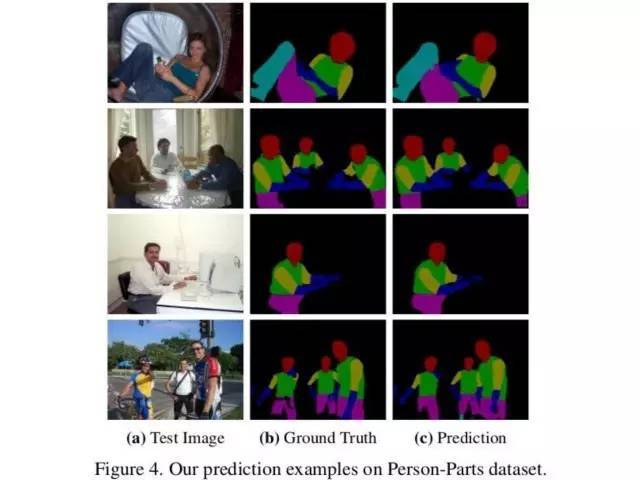
下面有一些结果,这个做的是部位分割。然后还有一些数值结果。
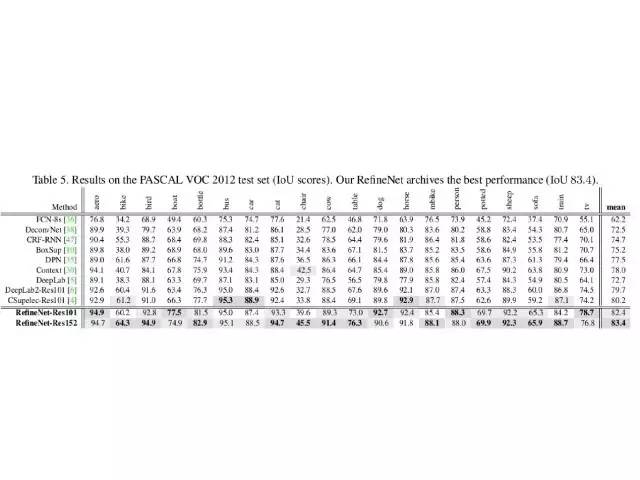

这个是在VOC数据集上面的一些结果。
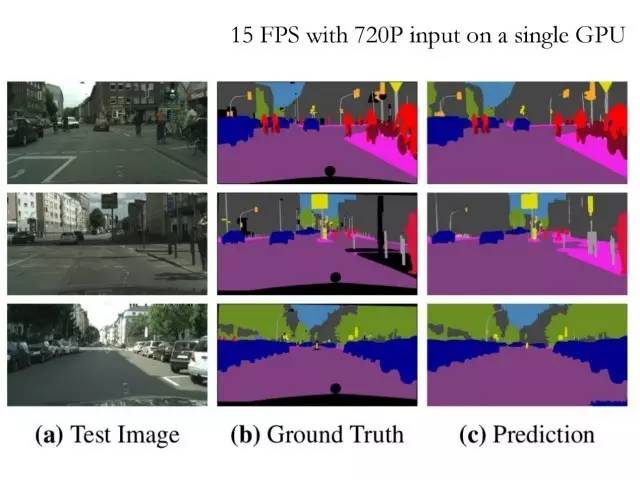
这个是在Cityscapes上的结果。我们现在的算法,可以在720P这样的输入上,用一块Titan X基本做到实时,这是优化之后的速度(现在已经能够做到近50 fps)。

这里是视频的截图。这个是在Cityscapes数据集上的结果,上面是输入,下面是像素标记的输出这里是把每个像素都标成19类。

对于自动驾驶来说,目前我们的算法的分割结果和速度,已经接近实用。当然这里还有很多其他的问题可以做。比如说可以做实例分割。

从输出可以看出,模型最后的输出的分辨率是原图的四分之一。相对来说还是比较高分辨率的。所以像电线杆,这些比较小的目标也能够标出来。
Low-level image processing
Low level的图像处理本质是也是对每个像素进行预测。所以这些问题都有很多相似性,借助自动编码器的结构,并引入跨层连接使得可以直接将信息在编码器和解码器之间的层中进行直接传播。同时在这样的任务中关键的是保证每层特征分辨率的不变性的基础上设计网络层的参数。基于这样的思路设计的模型在图像去噪,修复,超分辨率等任务中可以取得很好的效果。
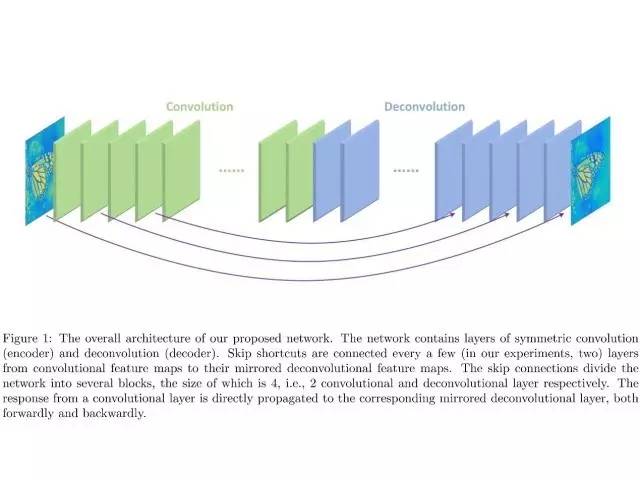
这个是我们去年做的NIPS的一个工作,用深度学习的方法做低级的图像处理。这个本质上也是一个per pixel prediction的问题,比如降噪,就是给出一张有噪声的图片,然后网络模型的输出就是对于每一个像素点,将其相应的清晰像素点估计出来。
我们提出了一个很简单的模型,前面一部分是编码器,后面一部分是解码器,然后为了更好的进行训练,在编码器和解码器之间加了一些连接捷径。一个直观的解释就是:可以把信息从前面层直接传递到后面的解码器层。这样也就更容易学到关于这个问题的一些特征。
我们之前没有做过任何低级图像处理的问题,在做这个问题的时候就发现它跟高级的一些任务是有很大的不同的,我们发现这里设计的网络,如果加入降采样,也就是卷积的步长大于1或者加池化会带来性能的下降,所以在这个网络里,所有的特征图的分辨率都是一样的:步长是1,做填充。

这是网络模型的一些细节。这个模型是非常通用的,可以处理很多low-level图像处理的问题,例如:图像去噪、超分辨率、图像去模糊、图像增强、图像修复。
下面分别介绍一下模型在这些任务中的应用结果:
一、图像去噪

这里是去噪的一个结果,左边是有噪声的图像,右边是网络的输出。

这幅图像也是去噪的结果。
二、超分辨率

左边是双线性插值的结果,右边是网络的输出。从结果来看这个模型的确可以保留更多的细节信息。

这幅图像是超分辨率另外的结果。
三、图像去模糊
这个模型也可以做一些简单的去模糊,对于很复杂的模糊,使用这个模型去处理效果不是非常好。但是对于散焦或者焦点失调这样的一些模糊问题还是能得到一个非常好的结果的。



四、图像增强
这个模型也可以用来从压缩的图像,比如JPEG格式的图片里,将一些噪声去除掉。

比如可以去这样一些马赛克噪声,左边的是将JPEG的压缩比设置为50%时的图像,得到这种马赛克噪声图像,右边是网络的输出。

这是另外的输出结果。

这也是增强JPEG图像的一个结果。
五、图像修复

最后一个应用的例子是做图像修复。就是给出一张像这样受到损坏的图片,这个模型也可以把原始图片恢复出来。

通过上面的实验结果,可以看得出来这个框架是非常通用的。可以应用在很多任务上,如图像降噪、超分辨率、图像去模糊、图像增强、图像修复等等。
文中提到所有文章的下载链接为: http://pan.baidu.com/s/1jINvZme
开源代码链接为:
https://github.com/guosheng/refinenet
https://github.com/itijyou/ademxapp
致谢:

本文主编袁基睿,诚挚感谢志愿者王超、范琦、李珊如对本文进行了细致的整理工作。

该文章属于“深度学习大讲堂”原创,如需要转载,请联系 astaryst。
作者简介:

沈春华博士, 现任澳大利亚阿德莱德大学计算机科学学院教授(Full Professor)。 2011之前在澳大利亚国家信息通讯技术研究院堪培拉实验室,Richard Hartley领导的计算机视觉组工作近6年。他曾在南京大学(本科及硕士),澳大利亚国立大学(硕士)学习,并在阿德莱德大学获得计算机视觉方向的博士学位。 2012年被澳大利亚研究理事会(Australian Research Council)授予Future Fellowship。目前主要从事统计机器学习以及计算机视觉领域的研究工作。
VALSE是视觉与学习青年学者研讨会的缩写,该研讨会致力于为计算机视觉、图像处理、模式识别与机器学习研究领域内的中国青年学者提供一个深层次学术交流的舞台。2017年4月底,VALSE2017在厦门圆满落幕,近期大讲堂将连续推出VALSE2017特刊。VALSE公众号为:VALSE,欢迎关注。

往期精彩回顾



欢迎关注我们!
深度学习大讲堂是由中科视拓运营的高质量原创内容平台,邀请学术界、工业界一线专家撰稿,致力于推送人工智能与深度学习最新技术、产品和活动信息!
中科视拓(SeetaTech)将秉持“开源开放共发展”的合作思路,为企业客户提供人脸识别、计算机视觉与机器学习领域“企业研究院式”的技术、人才和知识服务,帮助企业在人工智能时代获得可自主迭代和自我学习的人工智能研发和创新能力。
中科视拓目前正在招聘: 人脸识别算法研究员,深度学习算法工程师,GPU研发工程师, C++研发工程师,Python研发工程师,嵌入式视觉研发工程师,运营经理。有兴趣可以发邮件至:hr@seetatech.com,想了解更多可以访问,www.seetatech.com


中科视拓

深度学习大讲堂
点击阅读原文打开中科视拓官方网站


