学界 | 如何得到稳定可靠的强化学习算法?微软两篇顶会论文带来安全的平滑演进

取长补短,相得益彰
AI 科技评论按:强化学习最常见的应用是学习如何做出一系列决策,比如,如何一步步攀登上三千英尺高的岩壁。有机会用到强化学习并做出高水准结果的领域包括机器人(以及无人机)控制、对话系统(个人助理、自动化呼叫中心)、游戏产业(智能 NPC、游戏 AI)、药物研发(分子构型测试、剪裁管理)、复杂系统控制(资源分配、过程优化)等等。

强化学习的学术研究目前已经取得了不少令人欣喜的研究成果,比如斯坦福大学的强化学习研究团队就搞定了用强化学习控制一个简化过的直升机模型(https://link.springer.com/chapter/10.1007/11552246_35),甚至还学会了新的杂耍动作;Orange Labs 部署了世界首个用强化学习优化的商业化对话系统(https://aclweb.org/anthology/papers/W/W10/W10-4332/);DeepMind 开发出了深度强化学习算法 DQN(https://www.nature.com/articles/nature14236/),正是凭借着这个算法,他们训练出了只依靠视觉输入就可以在 Atari 游戏中达到人类水平的智能体,以及创造了只靠自我对弈就可以在围棋中达到超过人类顶尖水平的人工智能。
虽然强化学习领域已经有了这么多成果,但是用强化学习解决真实世界中的问题仍然是困难重重的。原因有许多种,包括:深度强化学习的样本效率很糟糕,训练算法需要用到上亿级的样本,但这种数量的样本是难以在真实世界获得的;算法的决策有可能是有危害的,所以只能在不会伤害生命、不会破坏设施的环境中训练,也无法在有较高安全性要求的环境中使用;强化学习算法的公平性无法保证;而且,算法的可靠性、可重复性也不理想。
这篇博客讨论的就是强化学习中的可靠性问题。上面列出的强化学习的成果只能代表它在「稳定、可靠」的时候的表现,然而深度强化学习解决真实世界问题时经常「不稳定、不可靠」。甚至于,在训练算法时使用两个不同的随机种子都会因为训练过程中的随机性而得到两种截然不同的结果。微软的研究人员们探究了两种缓解这个问题的方法。AI 科技评论根据博客介绍如下。
· 算法选择法 ·
第一种方法是微软蒙特利尔研究院在 ICLR 2018 论文《Reinforcement Learning Algorithm Selection》中提出的。它的思路很简单,如果某个算法不可靠,就训练多个算法,选取其中表现最好的那个。算法选择过程如下图所示。在每轮训练的开头,算法选择器会从算法库中选择一个算法,这个算法输出的策略会在这轮训练的后续部分中用到。下面来到绿色部分,用标准的强化学习循环一直执行到这轮训练结束。训练过程中生成的运动轨迹会被记录下来,然后重新喂给算法们,在之后更多的训练中用到。不同算法的表现会提交给算法选择器,它会在之后的更多训练中选择最适合的算法。
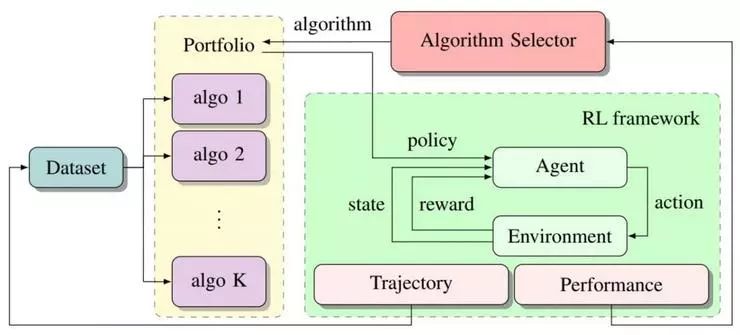
算法选择法示意图
微软的研究人员们在谈判对话博弈场景中进行了实验。测试使用的算法选择系统 ESBAS 中含有两个算法,每个算法单独的表现如下图,一个很稳定(蓝线),另一个最初很差,会逐渐学习并改善(红线)。ESBAS 的表现是绿色的线,它在每一时刻的表现都更接近更好的那个算法。
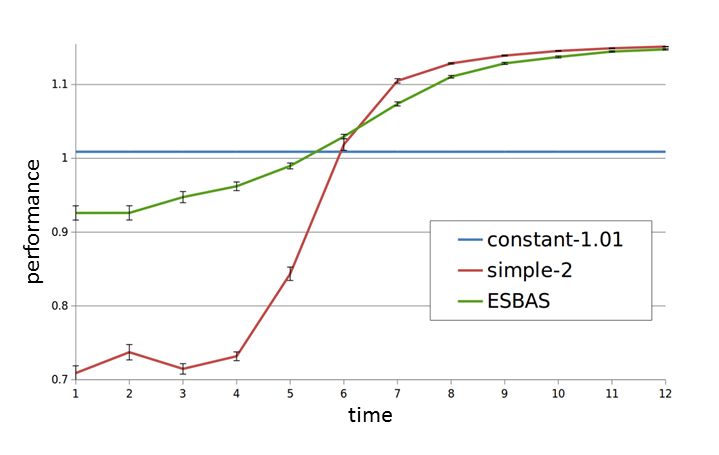
算法选择法初步实验结果
另一个以 Atari 游戏为环境的测试中,算法选择系统也结合了多个不同的 DQN 网络的能力,最终表现比每个单独的算法都要好。
最初微软的研究人员们只是提出算法选择系统可以提升强化学习算法的可靠性,但其实它的价值不止如此。首先,这个系统中存在交错学习,在每一时间步上都更倾向于选择能产生最好的策略的算法;其次,一些难以直接表达为反馈的目标函数也可以在这个系统中实现(比如它可以强制保证达到某些安全限制);而且,研究人员们观察到不同算法策略的综合体在环境中获得了更加丰富多样的经验(也就意味着获得了更多的信息);最后,正如上面那个例子展示的,算法选择系统可以在基准策略和需要时间学习的策略之间平滑地转换。
· 可靠策略改进 ·
微软的研究人员们还进行了另一个尝试,这篇论文《Safe Policy Improvement with Baseline Bootstrapping》发表在了 ICML 2019 上。他们研究的是一个真实世界应用中时常会遇到的具体场景:批量强化学习。相比于典型强化学习的在环境中一边互动一边学习,批量强化学习中智能体并不与环境直接互动,只有一个固定的基准线智能体采集数据,然后用采集到的数据训练算法产生新的策略。这种批量学习的情境是真实世界场景中时长遇到的,对话系统、电子游戏之类的部署在个人设备上的系统很难频繁更新,更没法实时更新,所以需要先大规模采集数据再训练新的算法;药物分子测试中也有类似的状况,如果像传统强化学习那样并行运行许多个轨迹需要花很多年,所以更适合用批量强化学习的方法。
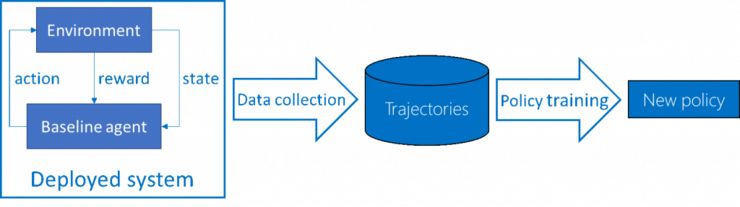
批量强化学习流程
传统强化学习在基准算法基础上的提升不是稳定可靠的。那么在批量强化学习中,能够可靠地改进策略就非常关键,因为如果得出了一个不好的策略,它的负面影响会遗留在许多轨迹中。微软的研究人员们的目标是,相比于基准算法的表现,可靠策略改进应当总是能够保证有一定提升。
要保证总有提升,就要从表现最糟糕的状况入手。研究人员们考虑了条件风险价值(1%-CVaR),这其实是一个简单的概念,是指最糟糕的运行结果的平均值;每次运行的过程如上图所示,包含数据收集和策略训练。1%-CVaR 就是指所有运行结果中最糟糕的那 1% 的平均值。
这里值得先回顾一下为什么经典的强化学习无法达到好的表现。由于它唯一的信息来源就是这个数据集,经典强化学习在使用数据集的过程中就会隐式或者显式地把数据集作为真实环境的体现。但是,毕竟真实环境具有一定的随机性,或者模型的逼近能力也有限,当模型获得的数据受限于数据集的时候,对真实环境的重现程度也是不确定的。那么,只能接触到数据集的学习算法也就会产生盲点,以及对数据集过于依赖。所以,经典强化学习在这种情况下经常会训练出在真实环境中表现非常糟糕的智能体。
实际上这还不是最糟糕的情况,强化学习会搜索并尝试找到能优化目标函数的行为方式,在以往的研究中已经多次观察到强化学习会利用环境中的小问题走捷径,这就不是我们希望看到的了。在批量强化学习中这个问题会更糟糕一些,因为有些「捷径」在真实环境中可能不存在,仅仅是因为收集的数据集中存在盲点,所以显得仿佛存在捷径。这个任务越复杂,各种盲点就会越多。所以,确保模型能够谨慎地处理盲点也很重要。
微软为这个难题提出的解决方案是 Safe Policy Improvement with Baseline Bootstrapping,SPIBB,带有基准 bootstrap 的安全策略改进。SPIBB 想办法把这条常识性的规则作用在了策略更新过程中:如果你不知道你在做什么,那么就不要这么做。具体来说,只有在有足够数据可以作证一个策略更新是有好处的时候,才会执行这项更新;否则就只是重复基准策略在数据收集过程中所做的。SPIBB 的思路也已经用在了因子化的 MDP 中(比如 AAAI 2019 论文 http://www.st.ewi.tudelft.nl/mtjspaan/pub/Simao19aaai.pdf ) 。
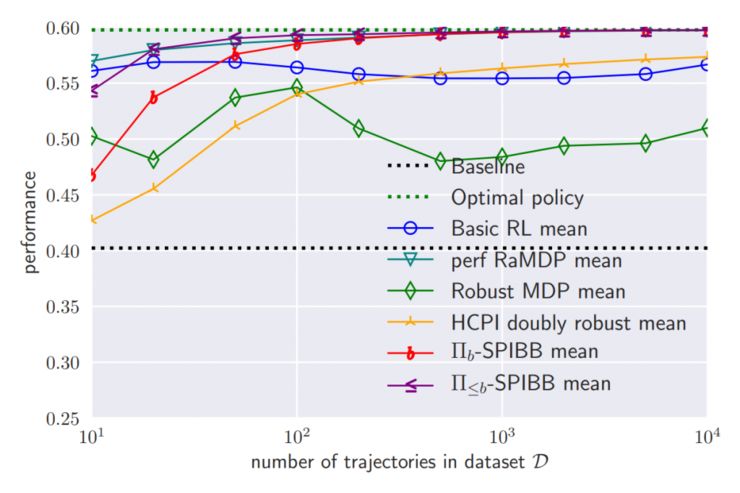
算法平均表现
微软的研究人员们在一个随机生成的网格世界环境中进行了测试,这个环境中仅包含 25 个状态和 4 种动作。根据数据集大小不同,研究人员们把 SPIBB 和以往文献中的数种算法进行了对比,平均表现如上图。总的来说,所有算法都得到了比基准线算法更好的表现,SPIBB 算法的两个变体则获得了最好的表现;相比之下,经典强化学习的表现甚至没有随着数据增加而一直变得更好。唯一一个表现和 SPIBB 近似的算法是 RaMDP(http://papers.nips.cc/paper/6294-safe-policy-improvement-by-minimizing-robust-baseline-regret),但它的问题在于需要非常仔细地调节一个超参数,而且它不如 SPIBB 可靠。
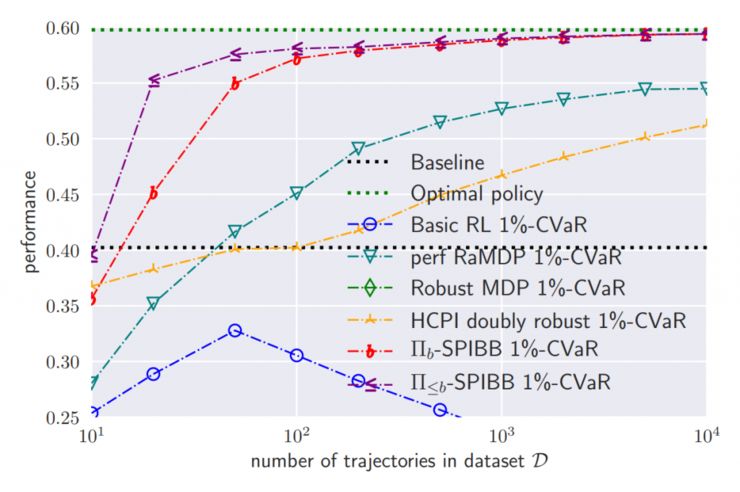
最糟糕的 1% 情况中的表现
这张图是算法可靠性的测试结果,即 1%-CVaR 最糟糕的 1% 情况中的表现。可以看到,经典强化学习是不可靠的,表现显著低于基准算法;SPIBB 的可靠性遥遥领先;RaMDP 在数据较少时稳定性表现不佳。研究人员们在其它的随机环境、随机基准算法条件下的实验也得到了类似的结果。在论文中,作者们也对 SPIBB 在有限 MDP 中的可靠性进行了严格的证明。
两篇论文地址:
《Reinforcement Learning Algorithm Selection》,ICLR 2018,https://arxiv.org/abs/1701.08810
《Safe Policy Improvement with Baseline Bootstrapping》,ICML 2019,https://arxiv.org/abs/1712.06924
via microsoft.com/en-us/research/blog/,AI 科技评论编译




