【ICLR2021】一种基于距离度量学习及行为正则化的完全离线的元强化学习方法

作为一种新颖的范式,可以让智能体以完全不与环境交互的方式快速适应新的未知任务,极大地提升了强化学习算法在真实世界中的应用范围和价值。围绕这一问题目前的相关研究还较少,并且有两个主要的技术难点。其一,离线强化学习中通常会因为训练数据与所学习策略的状态-动作对的分布偏移而产生较大误差,甚至导致价值函数的发散。其二,元强化学习要求在学习控制策略的同时能高效且鲁棒地进行任务推断(task inference)。
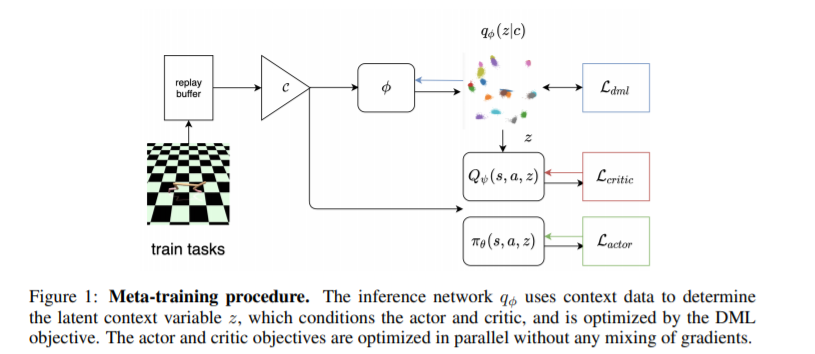
在本文中,我们将针对离线策略学习的行为正则化(behavior regularization)方法,与一个用于任务推断的确定性的任务信息编码器进行结合来解决上述的两大难点。我们在有界的任务信息嵌入空间中引入了一个全新的负指数距离度量,并且将其与控制策略的贝尔曼方程的梯度解耦进行学习。我们分析验证了在该设定下,采用一些简单的算法设计即可带来相比经典元强化学习及度量学习的效果的明显提升。据我们所知,本方法是第一个端到端、无模型的离线元强化学习算法,计算效率高并且在多个元强化学习实验环境上表现出优于以往方法的性能。
本方法赋予强化学习算法进行离线学习及高效迁移的能力,离线意味着不需要在真实环境中进行探索、交互,高效迁移意味着算法的鲁棒性及数据利用效率更高。我们的方法实现了同时具备上述两种能力的端到端的算法训练框架,可以极大扩展强化学习算法的实际应用范围:例如推动其在诸如医疗、农业、自动驾驶等数据稀缺或极度重视安全性的相关领域的实际应用,包括构建定制化的患者治疗方案、针对特定气候/作物品种的温室种植策略等。
https://www.zhuanzhi.ai/paper/af16ee8631cae148425f27ba32b6f673
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“DMLBR” 可以获取《【ICLR2021】一种基于距离度量学习及行为正则化的完全离线的元强化学习方法》专知下载链接索引