基于文本生成知识图谱的研究很常见,但是基于语音生成知识图谱,这算是第一家。
![]()
在这个信息飞速发展的时代,数据呈爆炸式增长。而互联网信息的多元性、异构性、结构松散等特点,给人们有效获取信息和知识带来了挑战。
知识图谱(Knowledge Graph) 凭借强大的语义处理能力,为互联网时代的知识化组织和智能应用奠定了基础,并被广泛应用于智能搜索、知识问答、舆情分析等领域。
然而在现有的技术中,大部分研究集中在从文本转化到图谱的过程,却忽略了从语音实时转换到图谱的研究。
本文将介绍一篇关于从语音到图谱构建的论文,可以说是该领域的首个相关研究。这篇来自明略科学院知识工程实验室的论文已被人工智能国际顶会 IJCAI 2020 Demonstrations Track 接收。
![]()
论文链接:https://www.ijcai.org/Proceedings/2020/0777.pdf
近年来语音接口受到极大欢迎。以智能音箱为例,截至 2019 年,估计有 35%的美国家庭至少配备了一个智能音箱。目前尽管存在成熟的语音识别工具包和商业语音转录系统,但面对长篇大论的交谈中,人们仍难以集中精力抓取其中的关键所在。而知识图谱可以追溯到早期的专家系统研究和语义网络,它提供了一种方法,这种方法可以可视化演讲者的关键思想。
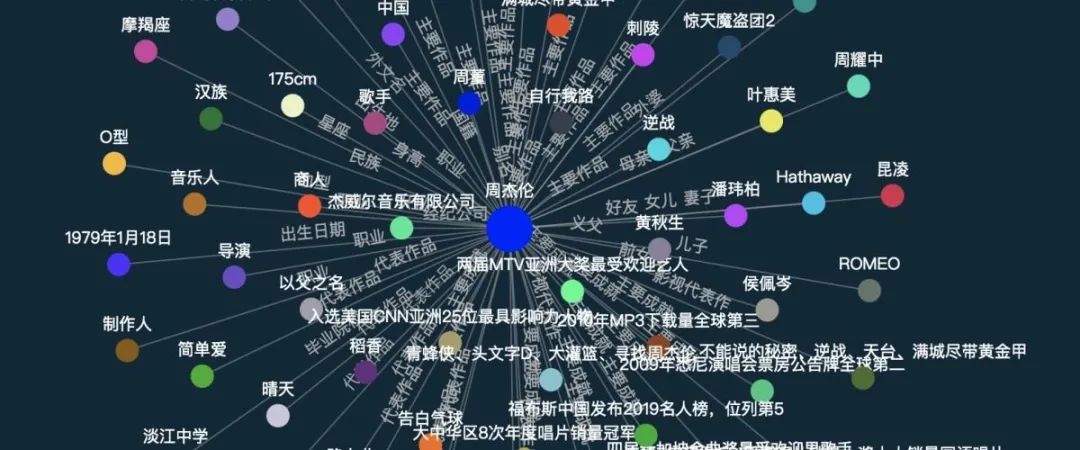
对于知识图谱的概念有不同的定义。这篇论文遵循此定义:「知识图谱作为一种数据表示工具,是对实体、属性、概念以及它们之间的关系进行建模」。为了从语音中构造知识图谱,有两个关键组件是必须的「实体 - 关系 - 实体」三元组和「实体 - 属性」对,如图 1 所示。
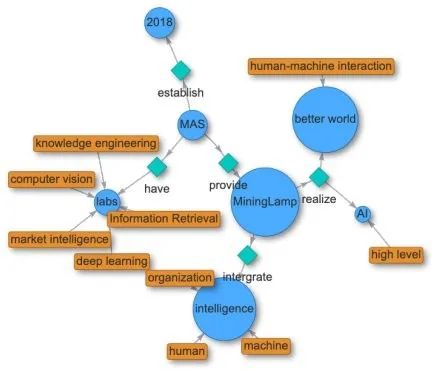
在此论文中,来自明略科技的研究者们提出了 HAO 图谱,它基于 HAO 智能,而 HAO 智能整合了人类智能(HI),人工智能(AI)和组织智能(OI),实现了中文文本和语音知识图谱的实时生成和可视化,填补了本领域的空白。
![]()
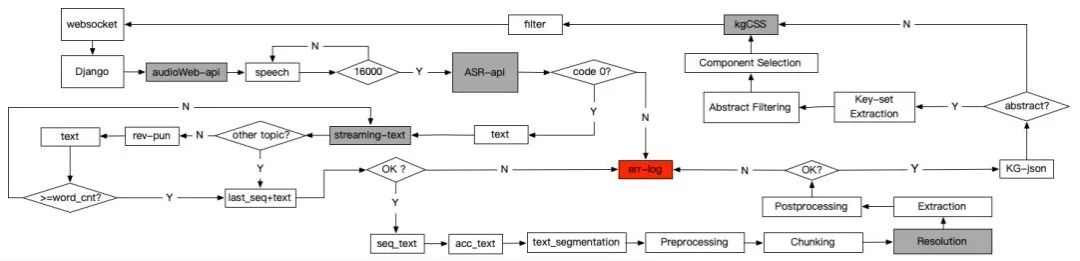
HAO 图谱系统到底是怎样实现的?我们来看看它的技术架构。
![]()
Monitor
:语音是根据 WebSocket 协议从前端 HTML 页面传输的。该模块通过端口实时监控前端页面发送的二进制语音流信号数据,并将数据保存在缓冲池中。当缓冲池数据大于 16000 字节时,缓冲池中的二进制语音流数据传输到后续的「语音转文本」模块中。
ASR 模块
:该模块将接收到的二进制语音流数据转换为无标点的文本,并以多线程的方式将其发送到前端,得到「语音转文本」显示结果。缓冲池中的无标点文本则根据上下文信息进行校对和更正,修正后的结果被传递给后续的「文本标点」模块。
标点模块
:该模块通过在中国日报语料库上基于 BERT 训练的模型,将接收到的无标点文本数据转换为带有标点符号的文本数据,并将转换结果保存在文本缓冲池中。此缓冲池用于缓存已加标点的文本,这是因为只有在识别出完整的句子后,该句子才会被发送到后续的「知识图谱构建」服务中,因此该模块会将完整的句子发送到知识图谱构建阶段,最后一部分没有标点符号的文本被缓存。如果带标点的文本都是完整的句子,并且句号在文本的末尾,则缓冲池被清空。
将语音转换成文本后,现在进入知识图谱构建阶段。该论文介绍了基于文本构建知识图谱所需的 5 个关键步骤:
预处理
:这一步骤包括了去除提取文本中的特殊字符,利用基于 BERT 的序列标注模型进行中文分词和词性分析,通过基于中心语驱动的短语结构语法的神经网络模型进行依存句法分析。这些模型均在 Penn Chinese Treebank 数据集上训练得到。
分块(Chunking)
:根据预处理阶段词性标注和依存关系的结果,按照规则对名词词性(如专有名词 NR 和其他名词 NN 等)进行分组组合。规则包括但不限于两个连续的专有名词(组)、专有名词后接其他名词、专有名词用标点符号或连词隔开。值得一提的是,该合并过程是递归执行的。例如,「人工智能,大数据,及物联网技术」这个短语中包含了三个专有名词、一个标点符号和一个连词。在分块步骤中,这些词被递归地合并为「人工智能,大数据及物联网技术」,并产生最终的分块结果。
指代消解
:该模块基于分块得到的结果,将文本中待分析的代词替换为指代消解模型的结果(即将代词替换为所指的名词)。
信息提取
:在进行信息提取时,利用预处理步骤中解析的依存关系,将每个动词短语作为候选三元组的谓词,并将其作为根节点遍历与其相关的名词短语。然后使用基于规则的方法提取三元组。对于三元组的主客体,抽取规则包括但不限于:关系的主体(nsubj)作为三元组主语,关系的主体(dobj)作为三元组宾语。
后处理
:最后,将上一步骤中获得的三元组进行后处理操作,如删除停用词,将所有三元组集成起来并输出。
为了实现生动的可视化,该研究设计了一个基于图数据库数据和上游模块返回结果来检测主题变化的模块。如果当前内容与之前的内容属于同一主题,则图数据库中与该主题相关的所有实体关系都将发送到前端进行显示。如果当前内容和前面的内容不属于同一主题,则只有当前内容的图结果显示在首页上。
在基于语音生成知识图谱的过程中,语速快导致节点和边的数量急剧增加。因此,从完整语音中生成可视化的知识图谱变得非常复杂,这种情况甚至比原始文本更难理解。为了解决上述问题,该研究通过以下三个步骤对知识图谱进行抽象化处理:
关键集提取
:首先,对于数据集 NLPCC 2017 corpus 中的所有文档集合,通过选择 TF-IDF 最高的词语,基于完全的语音转录文本获得一组关键词。另外,将中心度较高的节点选入关键节点集中。
抽象过滤
:其次,应用规则从语音系统中获取抽象化的知识图谱。使用关键词和关键节点集合之间的交集对「实体关系三元组」和「实体属性对」进行过滤。
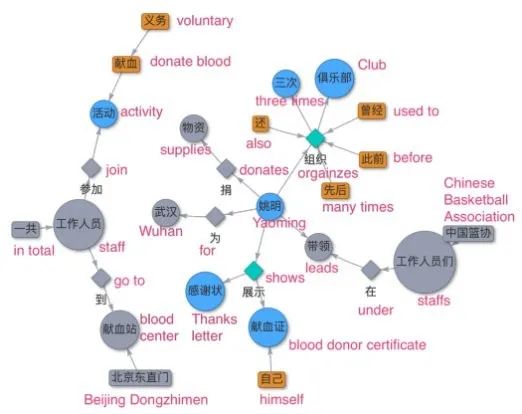
组件选择
:最后,从知识图谱中选出最大连通分量。这一步很关键,因为小分量通常没有明确的含义,如下图 3 左上角所示。
![]()
图 3:在执行「组件选择」步骤之前,基于长语音构建的知识图谱及其抽象(彩色部分)。
最后,作为首个基于语音实时生成知识图谱的系统,HAO 图谱的效果如何呢?明略科技进行了满意度调查。
在今年 1 月举办的 2000 人左右的会议上,该系 统实时地从两小时的谈话中提取知识图谱。满意度调查显示,61.54% 的受访者认为 HAO 图谱有助于更清楚地了解谈话内容,41.76% 的受访者认为该系统可以缓解认知疲劳。超过 65% 的受访者对该系统是否加强了沟通方面给予了 5/5 星级的评价。
Amazon SageMaker 是一项完全托管的服务,可以帮助开发人员和数据科学家快速构建、训练和部署机器学习 模型。SageMaker完全消除了机器学习过程中每个步骤的繁重工作,让开发高质量模型变得更加轻松。
现在,企业开发者可以免费领取1000元服务抵扣券,轻松上手Amazon SageMaker,快速体验5个人工智能应用实例。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com