客服机器人中的深度语义技术与应用探索(附视频+PPT)| 硬创公开课
雷锋网「新智造」按:几年之间,苹果、微软、Google、百度、阿里等巨头都推出了以聊天为形式的机器人,应用在情感陪护、虚拟助理、客服、售后等场景中,同时也有诸多初创公司、投资机构杀入这一行业。但在实际使用中,用户经常发现,机器人并没有想象中那么智能,它能识别文字和语音,但却“不懂你”。这其中的关键便涉及到自然语言处理中的”深度语义技术“。
针对这个问题,本期雷锋网硬创公开课邀请到小i机器人创新中心的研究院陈培华为大家具体讲解,在客服机器人领域的深度语义技术和应用探索。
嘉宾介绍:

陈培华,毕业于上海交通大学,工学博士,目前主要负责基于机器学习、深度学习的自然语言处理技术及其应用,参与“小i中文语义开放平台”以及贵阳人工智能大数据云服务平台建设,已申请相关发明专利2项。
公开课完整视频:
以下内容整理自陈培华在雷锋网硬创公开课的分享,文中略有删减,完整内容可观看上方视频。关注雷锋网旗下公众号「新智造」,回复「PPT」可获取嘉宾完整PPT。
语义技术在人工智能中的应用
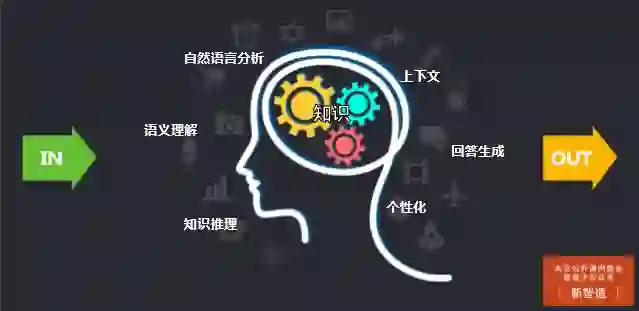
这个图片展示的是一个典型的人工智能对话引擎,输入的是用户的问题,引擎内部通过长期积累的知识,首先经过自然语言分析,在通过语义理解、上下文分析进行知识推理,从而生成个性化的答案,输出给用户。

这里展示的就是对话引擎中的知识库和语义库。在客服机器人的知识库中,分为专业知识库和语言知识库,下面的部分是语义库中的三个模块,包括词类识别、语义表达和语言模型。我们在发展的过程中,积累了一个庞大的语言知识库,比如在“余额查询”这个查询中,就有250种表达方式。
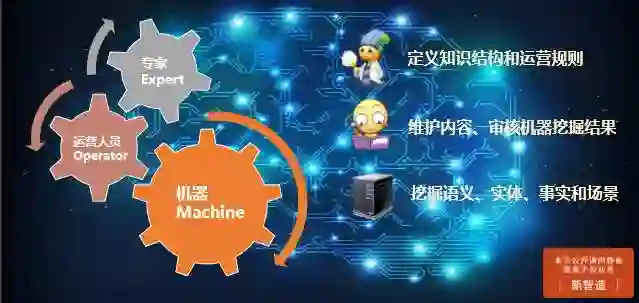
此外,在上述基础上,小i搭建了一些辅助系统,比如上图的人机协作学习体系。首先通过大数据平台,挖掘知识中的语义、实体、事实和场景信息;其次通过运营人员维护内容、审核机器挖掘的结果;最后由特定领域专家定义知识结构和运营规则。通过辅助系统,就能让对话引擎在服务中提升自身的能力。
深度语义技术平台
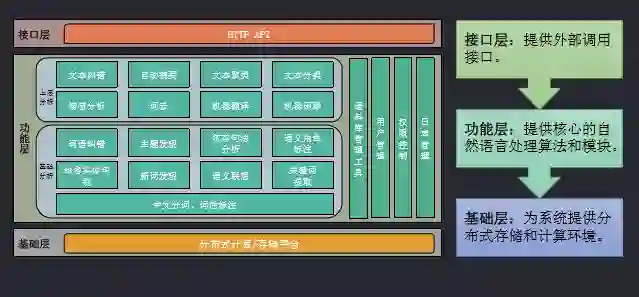
上图显示的是小i中文语义开放平台,分为三层:
基础层:为系统提供分布式储存和计算环境
功能层:提供核心的自然语言处理算法和模块
接口层:提供外部调用接
下面主要介绍功能层所包含的模块:
中文分词与词性标注
中文分词是中文自然语言处理的一个基础环节,分词的结果可以被广泛的应用于文本处理、信息提取、搜索引擎、机器翻译等方面。通过采用基于统计+规则的方法对标注语料进行训练学习,将所得到的模型应用于中文分词和词性标注中,能够支持歧义切分处理、中文词性自动标注、未登录词识别、多编码支持能力以及丰富的知识词典。
命名实体的识别
命名实体识别指的是识别文本中具有特定意义的实体,主要包括人名、地名、机构名等专有名词。命名实体识别是信息抽取技术中的重要组成部分,可以应用在自动问答、机器翻译、信息检索等自然语言处理领域,有助于提高相关的性能。
语义联想
语义联系用于对词语进行同义词查询检索,通过全网数据挖掘出海量同义词,并持续对数据、模型等进行迭代更新,保证同义词的效果始终与时俱进。
词语纠错
日常生活中,用户在使用搜索引擎、智能问答时,可能会出现输入错误的情况,比如说同音别字、近音别字、形近别字、拼音等,这样搜索引擎和智能问答可能就无法正确识别,导致用户无法获取需要的信息。
自动摘要和关键词提取
关键词提取的主要功能是,从文本中提炼关键词,形成主题分析,方便用户快速了解文章主题。自动文摘技术可以分为摘要、摘录两类,摘要是基于对文本的理解,使用简短的自然语言,对文中的主要内容进行描述;摘录的方法则是,从原始文档中抽取重要的句子,再连接到一起。
依存句法分析
该模块主要分析句子的构成方法,描述句子中的语法功能。
文本聚类
针对用户出现的多文本、无需组织的情况,需要进行聚类分析。聚类分析是按照一定的规律和要求对文本进行簇划分的过程,是一种无监督分类,没有预定义的先验知识。聚类的算法有很多种,应用最多的是K-means算法。
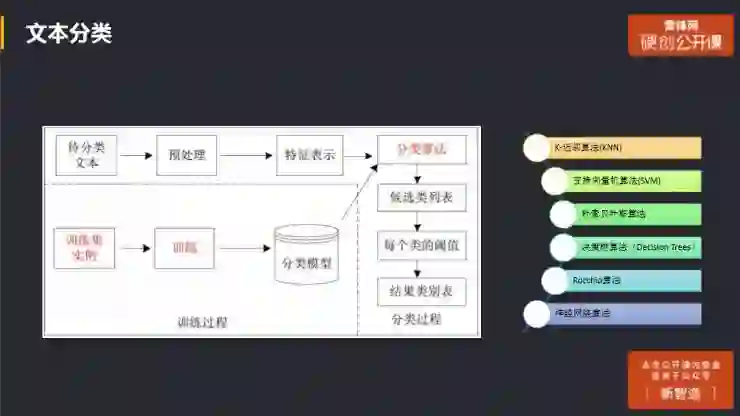
文本分类
如有现有较多带标注的文本语料的话,就可以利用文本分类来训练分类模型,按照预先定义的主题类别进行分类。
情感分析
文本情感分析又称为意见挖掘,是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。在本质上,情感分析也是一种分类问题,不过它针对的是短文本。情感分析的任务主要有:正负面评价、按分数打分、分析目标和来源的情感类型。主要应用于影评、产品评价、用户情感等方面。
此外还有词云及基于多层RNN神经网络实现的机器闲聊等模块。
深度语义技术的应用探索
以小i为例,基于深度语义技术,能够应用在客服机器人、智能知识库、智能IVR、实体机器人、企业内部智能应用等方面,同时可将客服机器人部署在Web、WeChat、SMS、QQ、App等平台。
Q&A环节
新智造:聊天机器人目前主要有哪几类?各细分类别中,代表性的应用都有哪些?
陈培华:从大的分类而言,主要有两类,一类是面向垂直领域的客服机器人,另一类是通用类机器人,比如小冰、小娜、Siri等聊天机器人。
新智造:目前的客服机器人,主要是被动的接受用户需求,有没有主动去推荐的?
陈培华:准确来说目前客服机器人确实是被动接受用户需求,再做出回应。分享中提到的意图推荐模块,就能够根据用户信息进行推荐。这个问题在业界也是众说纷纭,比如机器人什么时候推荐,推荐哪些信息,很难自动去完成。
新智造:聊天机器人技术的关键困难在哪儿?
陈培华:在客服机器人方面,关键困难在于如何获取知识,以及理解用户问题,需要利用自然语言处理方法,来对用户的问题进行理解,识别他的意图。还有一个难点在于答案的生成,很多用户的提问中包含多个知识点,如何就此回答比较困难。在通用聊天机器人方面,关键困难在于常识性的知识,我们很难从网上的一些数据获取到。
新智造:人工智能最容易落地的是不是语音类的应用?
陈培华:就人机交互的发展历程来看,目前确实是最容易落地的应用。但是随着技术的发展,后面可能会有更多复合的人机交互的应用落地,比如语音、图像处理相结合的技术。
新智造:距离一个真的懂得人类的聊天机器人还需要多久?
陈培华:我觉得它面临很多问题,它必须自主学习、自我进化,现在学界和工业界都在往这个方向努力,比如提出了对抗网络、迁移学习等。至于实现需要多久,我很难给出答案,拭目以待。
新智造:深度语义技术需要多长的时间才能成熟?距离产业又有多远呢?
陈培华:我们不断去研究深度语义技术,将技术落地,进行产业化应用。深度语义技术,可以从各个方面去研究,应用下去。距离产业不算远,而且它其中包含了很多技术模块,我们的思路是各点击破。
新智造:刚刚毕业想学人工智能,觉得语义理解这个很有前途,不知道有什么好的建议么?
陈培华:我觉得刚刚毕业,最好不要做人云亦云的事情,要有自己的判断。如果确实对语义理解感兴趣,可以找一个相关行业,沉下心去做研究和探索。当然,我们的目标,还是通过研究和探索,并能够应用,来提升人类的生活水平。






