基于模型的强化学习论文合集
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
作者
来源:
最近组里在讨论接下来在强化学习这块的研究方向,在讨论之前,我们把强化学习各个子方向的论文都粗略过了一下,涉及到model-free/model-based/multi-agent/deep exploration/meta-learning/imitation learning/application/distributed training等方向。我想着当时查找阅读相关文章花费了不少精力,决定开个专栏把我看的论文给整理一遍,主要是为了让别的同学少走点弯路,也方便自己回顾。
本文讨论到的相关论文连接放在了 github 上,后续会一直更新。
github 链接:
https://github.com/PaddlePaddle/PARL/blob/develop/papers/archive.md#model-based-rl

[背景]阻碍强化学习落地的致命缺点
强化学习近些年在控制领域取得了相当大的突破,比如超越人类玩家平均水平的DQN算法,以及碾压所有人类选手的Alpha Go等。尽管如此,强化学习仍然有着一个巨大的问题:需要大量的环境交互数据来迭代算法。这也是为什么近些年我们看到强化学习在仿真环境中做了更令人震撼的事情,但是在现实问题并没有这么大的突破。在现实问题上获取交互数据的成本是远比模拟环境高的:我们通过几行代码可以在Mujoco环境上跑一千万的交互数据,但是在真实场景中,收集一千万数据的成本是难以想象的。
这点我相信接触过硬件的同学都会深有感触。之前我们把强化学习落地到无人机控制过程中,第一步就是通过手工控制无人机整整收集了两周的数据,耗费了上百块电池,后面的算法训练更是迭代了一个月,更别提中途还有各种炸机导致维修停工的插曲。
[定义]基于模型的强化学习
在众多尝试解决RL中的数据依赖的研究方法中,Model-based RL是最有希望的方向之一。Model-based RL相对于Model-free RL的最主要区别是引入了对环境的建模。这里提到的建模是指我们通过监督训练来训练一个环境模型,其数据是算法和环境的实际交互数据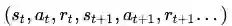

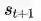
[论文]Model-based RL 论文整理
看了大半个月论文。model-based RL这个方向的工作可以根据environment model的用法分为三类:
作为新的数据源:environment model 和 agent 交互产生数据,作为额外的训练数据源来补充算法的训练。
增加决策的context信息:在进行Q值或者V值预估时,environment model 和agent做交互,交互过程中的信息作为context提供给agent来帮助其决策。
增加Q值预估的质量:在进行Q值预估时候,会通过environment model 来展开一定步数,然后结合model-free的Q值预估来给出一个更高准确的Q值预估。
其中3和2有点类似,但是2一般和planning结合,3的话则更多用于off-policy的RL算法中,具体可以看后文的详细分析。
Model-Ensemble Trust-Region Policy Optimization
ICLR2018.paper
paper 链接:https://arxiv.org/abs/1802.10592
Thanard Kurutach, Ignasi Clavera, Yan Duan, Aviv Tamar, Pieter Abbeel
简述:这是属于类别【1】的文章。文章指出了目前model-based RL这类算法存在的矛盾点:环境模型是通过监督训练得到的,监督训练是数据越多则模型预测效果越好。但是,agent是通过探索未知的状态空间来获得更好的policy的,在探索未知的状态空间时候,这部分状态空间的对应数据很少,环境模型在这些新的状态空间中预测效果很差。针对这个问题,作者在原先的TRPO算法上增加了一个迭代的限制,用来限制policy在更新的过程中朝着环境模型不熟悉的地方迭代。

Uncertainty-driven Imagination for Continuous Deep Reinforcement Learning
CoRL2017.paper
paper 链接:
http://proceedings.mlr.press/v78/kalweit17a/kalweit17a.pdf
Gabriel Kalweit, Joschka Boedecker
简述:这是属于类别【1】的文章。作者认为虽然可以通过环境模型能提供额外的数据,但是一个预估准确率低的环境模型提供低质量的数据会影响最终算法的效果。为了解决这个问题,文章把传统DDPG里面用到的Experience Replay Buffer 分成了两类:traditional replay buffer 以及imaginary replay buffer,然后在每次训练前,通过一个动态的概率
来决定从哪个buffer里面取出一个batch来做训练。这个概率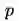
ICML2016.paper
paper 链接:https://arxiv.org/abs/1603.00748
Shixiang Gu, Timothy Lillicrap, Ilya Sutskever, Sergey Levine
简述:这是属于类别【1】的文章。这篇文章也提出了解决环境模型预估不准的方案。作者认为传统的神经网络模型虽然表达能力很好,但是需要的训练数据量也比较大,并不适合用来建模环境。作者在文章中采用了一个基于时间序列的线性模型来建模环境。当然,作者还有另一个贡献:把DQN扩展到连续空间上,但这个不是本篇文章讨论的范围,有兴趣的读者可以细读这篇文章。
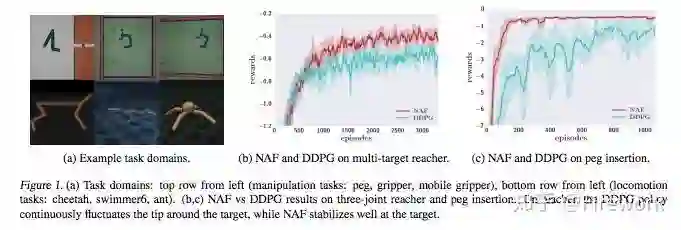
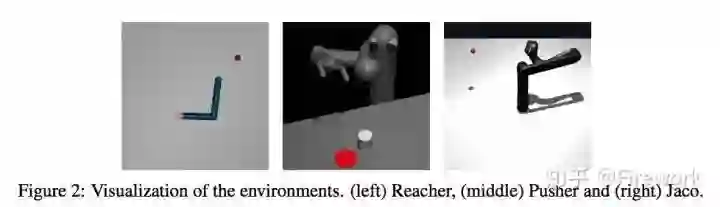
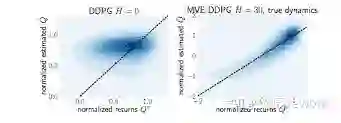
Model-Based Value Estimation for Efficient Model-Free Reinforcement Learning(MVE)
ICML2018.paper
paper 链接:https://arxiv.org/abs/1803.00101
Vladimir Feinberg, Alvin Wan, Ion Stoica, Michael I. Jordan, Joseph E. Gonzalez, Sergey Levine
简述:这是属于类别【3】的文章。作者通过一种很巧妙的方式把环境模型引入到Model-free RL算法中。传统方法对于Q值的预估(比如DDPG/DQN)是通过bootstrapped的方式来更新参数的,在这篇文章中,作者把环境模型先展开一定步数之后再进行Q值预估。也就是说,在传统的更新方式中,target Q值是下一步Q值的预估,而在这里,target Q值是先通过环境模型进行模拟一段路径之后,再进行Q值预估。这样Q值的预估就融合了基于环境模型的短期预估以及基于target_Q网络的长期预估。
Value Prediction Network
NIPS2017.paper
paper 链接:https://arxiv.org/abs/1707.03497
Vladimir Feinberg, Alvin Wan, Ion Stoica, Michael I. Jordan, Joseph E. Gonzalez, Sergey Levine
简述:这是属于类别【2】的文章。传统环境模型是显式地预测下一个状态 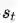
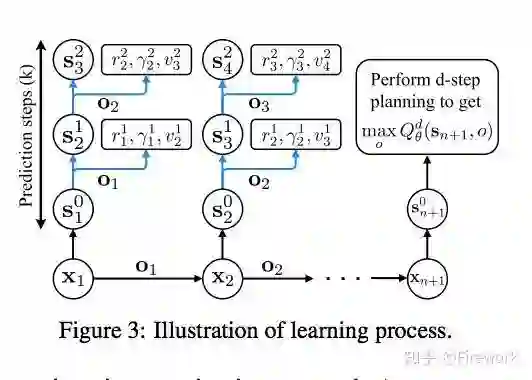
Imagination-Augmented Agents for Deep Reinforcement Learning
NIPS2017.paper
paper 链接:https://arxiv.org/abs/1707.06203
Théophane Weber, Sébastien Racanière, David P. Reichert, Lars Buesing, Arthur Guez, Danilo Jimenez Rezende, Adria Puigdomènech Badia, Oriol Vinyals, Nicolas Heess, Yujia Li, Razvan Pascanu, Peter Battaglia, Demis Hassabis, David Silver, Daan Wierstra
简述:这是属于类别【2】的文章。Deepmind在这篇文章中提出双层enconder的方式来把环境模型合入到原先的算法中。先通过agent和环境模型交互产生多条路径,每条路径通过encoder得到表征这个路径的向量,然后把多个路径向量再encoder一遍,得到表征多条路径的context。这个context用来帮助模型预估Q值,或者帮助policy做决策。
Sample-Efficient Reinforcement Learning with Stochastic Ensemble Value Expansion
NIPS2018.paper
paper 链接:https://arxiv.org/abs/1807.01675
Jacob Buckman, Danijar Hafner, George Tucker, Eugene Brevdo, Honglak Lee
简述:这是属于类别【3】的文章。这是基于前面的提到的MVE做的改进工作,整体效果相当惊艳,在mujoco的效果上达到了model-based off-policy的SOTA效果。作者指出MVE算法特别依赖于调整展开的步数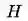
最后给出一个大概的整理。受限于知乎的版面显示,图片显示有点模糊,可以点开图片看更高清的。

-End-
*延伸阅读
CV细分方向交流群
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群(已经添加小助手的好友直接私信),更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台
觉得有用麻烦给个在看啦~




