医疗健康领域的短文本理解

分享嘉宾:杨比特 丁香园
编辑整理:叶祺
出品平台:DataFunTalk
主要内容包括:
丁香园主要的业务和所服务的对象,以及在垂直领域下NLP工作可能需要面对的挑战
在医疗健康领域短文本理解上的尝试
-
结合工业场景,展示一些应用案例
1. 关于丁香园
丁香园的起点是打造一个专业的医学学术论坛,为医生、医学生及其他医疗从业者提供一个信息交流的平台,同时也推出了一系列移动产品以提供优质的医学信息服务。
目前,丁香园围绕着医生和大众来发展,业务覆盖这两类人群的日常需求。对医生为主的医疗从业者来说,会涉及到日常的学术问题、经验分享、疑难病例的讨论以及查阅药品说明书、诊疗指南等等。对大众来说,包括线上问诊、科普知识、健康商城等服务。
2. 搜索场景的支持
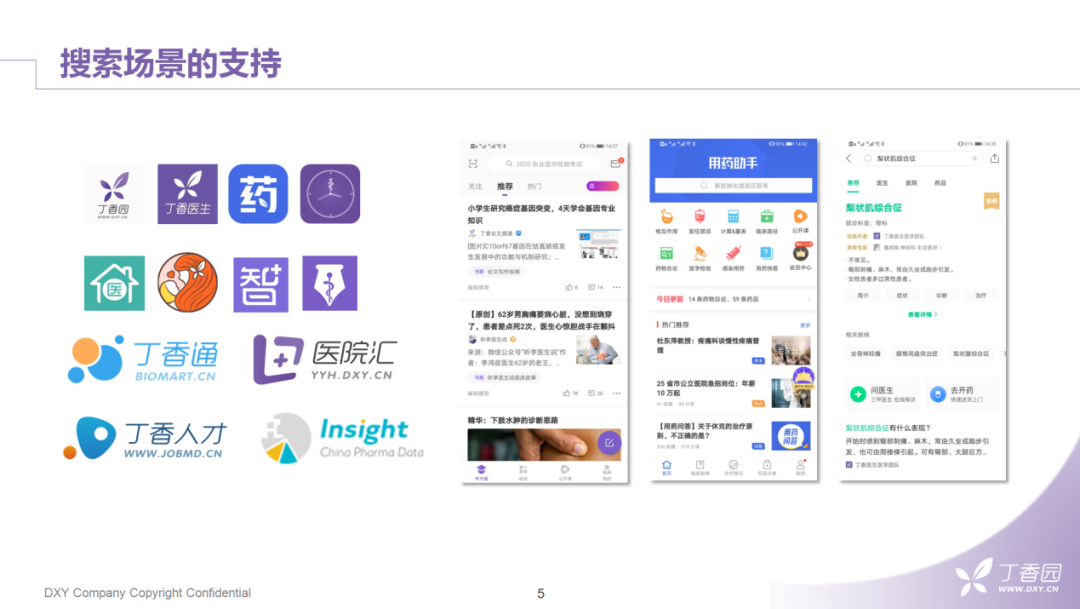
搜索作为丁香园的基础服务,需要支持多个社交与工具类的应用,主要包括:丁香园论坛、用药助手、丁香医生、丁香家商场等主要App。处理的文本数据需跨越大众和专业医学这两个领域,涉及的业务线也需处理不同的场景。

这里我们举了几个比较有代表性的场景,前三个是面向专业医学背景的。
第一个是丁香园论坛,主要用户是医疗相关的从业者。用户会在论坛中,讨论最近的热门医疗事件,新冠疫情、考博、规培的分数线、医疗纠纷,或者发帖求助一些疑难病例,求一些医疗文献等等。
第二、第三个场景是来自于用药助手,这是一个工具类的应用。用户会将其作为搜索药物信息或诊疗指南的工具。
后面三个场景是面向普通大众的,包括对科普文章的检索、线上问诊数据的检索 ( 举个例子,用户会问"湿疹反复发作怎么办?"、"坐月子能不能洗澡?"这类的问题 ) 以及电商场景 ( 大体上和市面上的电商场景都相似。不一样的是该场景会围绕健康话题去开展,如"产后康复"、"减肥减脂"等话题 )。
3. 垂直领域下的思考
① 话题性

我们观察到的第一个点:医疗健康领域的内容普遍存在着话题性。
左边第一张图是医学的新闻事件,这与大多数的普通新闻比较类似。新闻事件会天然形成一个话题。比如"新冠疫苗最新进展",用户会围绕这个话题产生一些相关的搜索行为,如搜索"肺炎"、"柳叶刀"等潜在的、需要获取的话题意图。
第二张图是我们想要谈论的,在医疗领域比较特殊的话题性。因为在医疗领域关于症状相关的表述会非常多,或者用专业的表述我们会叫它"临床表现"。这里再解释一下"临床表现"的含义:你可以理解成生病后身体的一些症状,比如,头疼、发热、呕吐等。医生在做病例讨论时,常常会抛出他们认为比较关键,但又很让他们困扰、值得讨论的临床表现,如"术后出血引起的血肿"、"右下腹感染病变"、"胸部多发病变"。所以当用户发起一个讨论时,某些"临床表现"的词也会自然形成一个话题。但是这些话题相关的词并不像开放领域中的词有那么明显的边界。举个例子,在开放领域中,"梅西获得2019年金球奖"这样的话题相关的实体,如"梅西"、"2019年金球奖",在搜索时比较容易避免搜索的关键词与用户实际关注的事件间的差异。但在上述的例子中,"腹腔镜"与"术后血肿"相关,但是与"腹腔镜"相关的其他疾病和手术也非常多,同时也包含了其他非常多的复杂逻辑。所以,我们认为医疗健康领域的内容普遍存在着话题性。
最后一张图是面向大众的科普,这块比较容易理解。医疗话题的底层是由许多复杂逻辑与细节组成的。当用户提问"坐月子能不能洗澡"时,如果只回答"能"或者"不能"显然是不够的,而是需要组成一个话题来讨论或者用更加友好的方式来回答。
② 医疗话题本身的复杂、严肃性
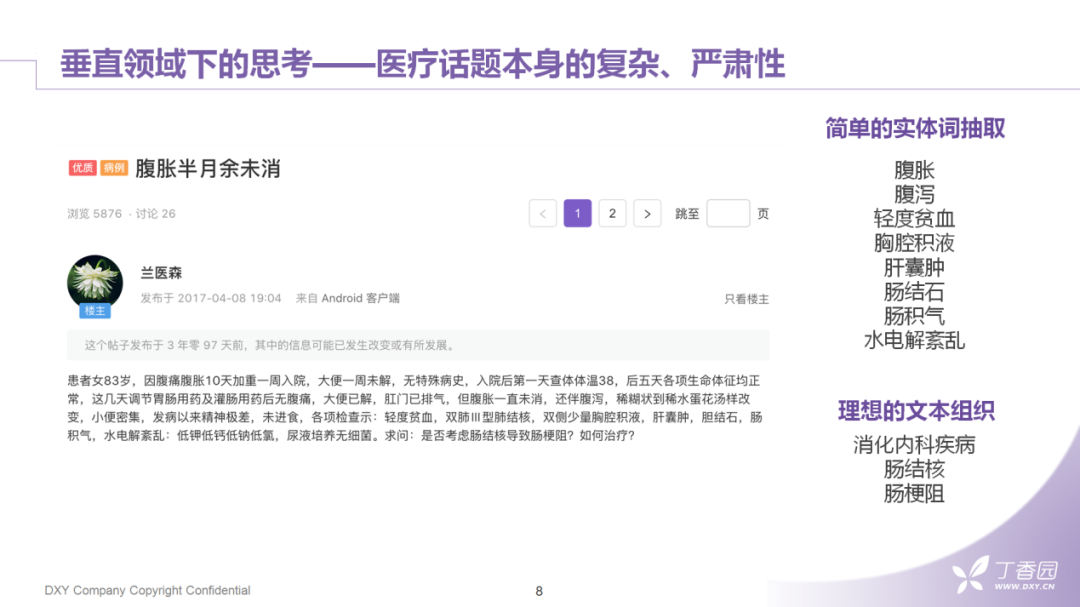
对于医学知识本身的复杂性,在处理面向医生的文本数据时,是不得不面对的问题。例如,这是在丁香园中的一则病例讨论。这位医生详细描述了在工作中遇到的一则病例,其中包括了非常多的专业术语。我们用了一个简单的实体抽取方法进行抽取可以获得"腹胀"、"腹泻"这样的疾病症状词。但是全文的信息量不仅在于这些实体词上,也有相当一部分是存在于这些词之间,复杂的逻辑关系。在常见的搜索方法中,我们会用词的倒排索引来完成文章检索这件事,但是倒排索引在执行过程中很难保证主题不会发生偏移。在理想情况下,我们更希望抽象出更具概括性的标签来结构化这些数据。
③ 普通用户与专业医疗从业者的认知差距

除了医疗话题在主题上不好做结构化,在处理面向大众的文本时,认知层面的差异也是个棘手的问题。医学知识、医学词汇都具有高度的专业性。比如用户在表述中,一个非医学背景的人会用"痘痘"、"青春痘"、"闭口"、"痘印"这样的词去表述自己的症状。在医生看来这些症状会是"寻常痤疮"、"毛囊口角化异常"等专业词汇。当我们想要帮助大众检索到想要的信息时,就要想办法跨过这些表述不一样的情况,因此我们在三个方面做了一些努力:
4. NLP技术布局
① 知识图谱构建
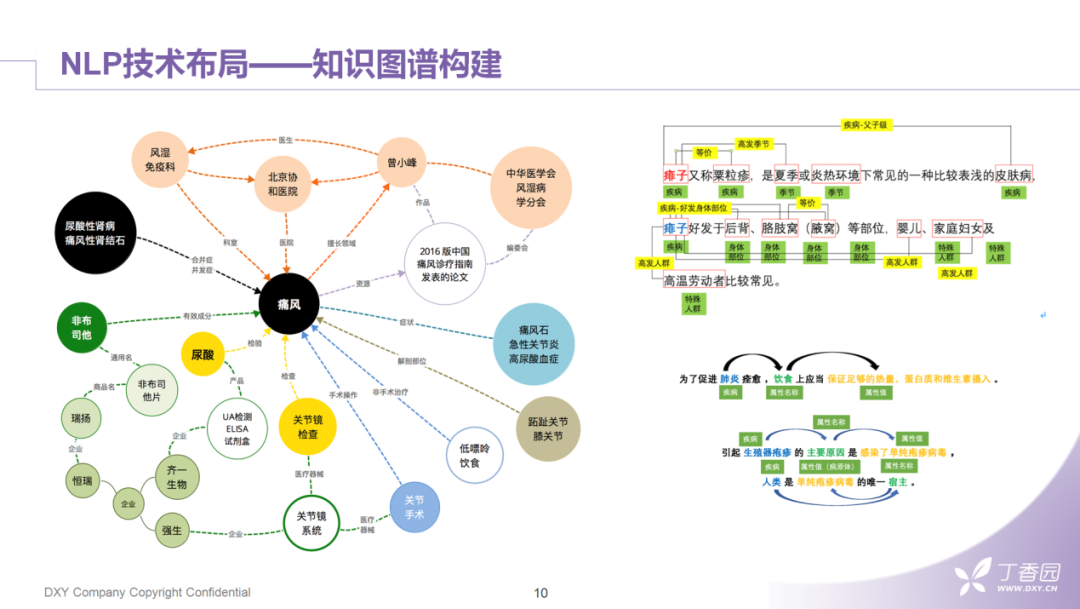
知识图谱的构建。主要目的是保证底层医学数据的准确性。由专业的、有医学背景的知识库同事来维护,包括:疾病、症状,手术、药品、非手术治疗等医学概念与60多种医学关系。同时,我们NLP组也会用算法来抽取,最后再以一种算法加人工审核的方式不断的补充实体词、实体关系和实体属性。
② 内容画像
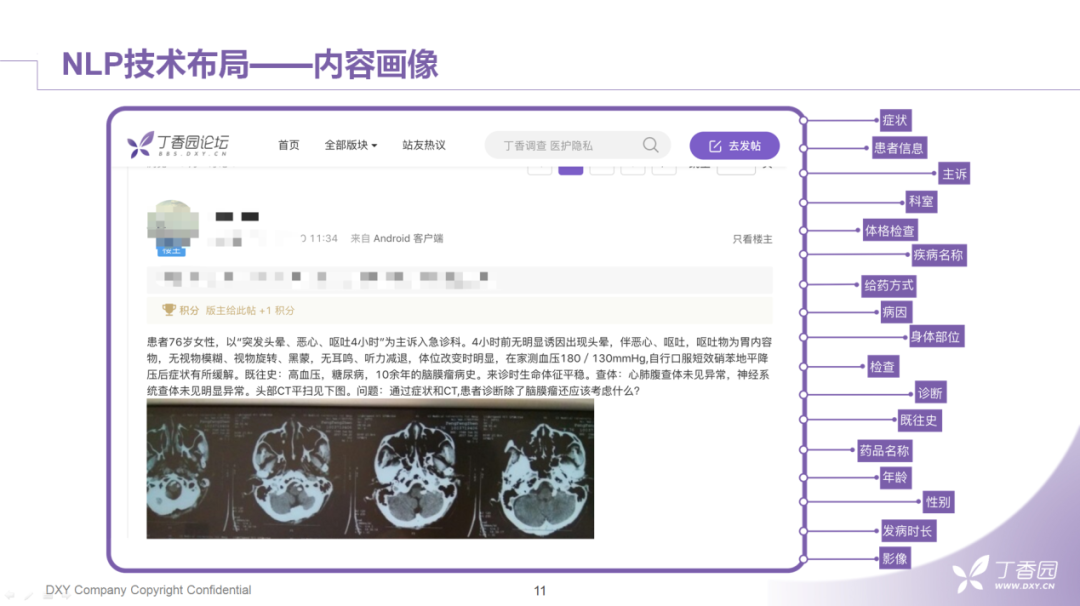
内容画像。我们会尽可能的完善内容画像的建设。除了基础信息的收集、长文本的信息抽取,也包括结合知识图谱和一些图算法构建更为抽象的标签值或者特征向量。
③ 短文本理解
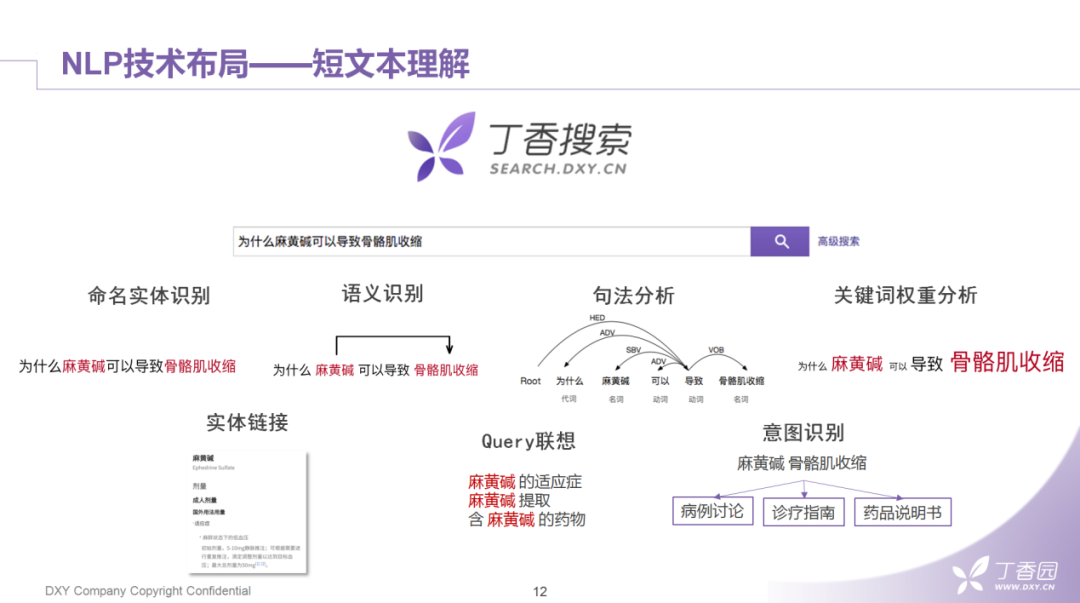
短文本理解。我们需要努力优化关于短文本理解的效果,这里包括对短文本完成关键信息的抽取以及根据这些关键信息配合下游任务,来完成特征抽取、语义扩展,以及垂直业务相关的分类任务等。
5. 基本思路
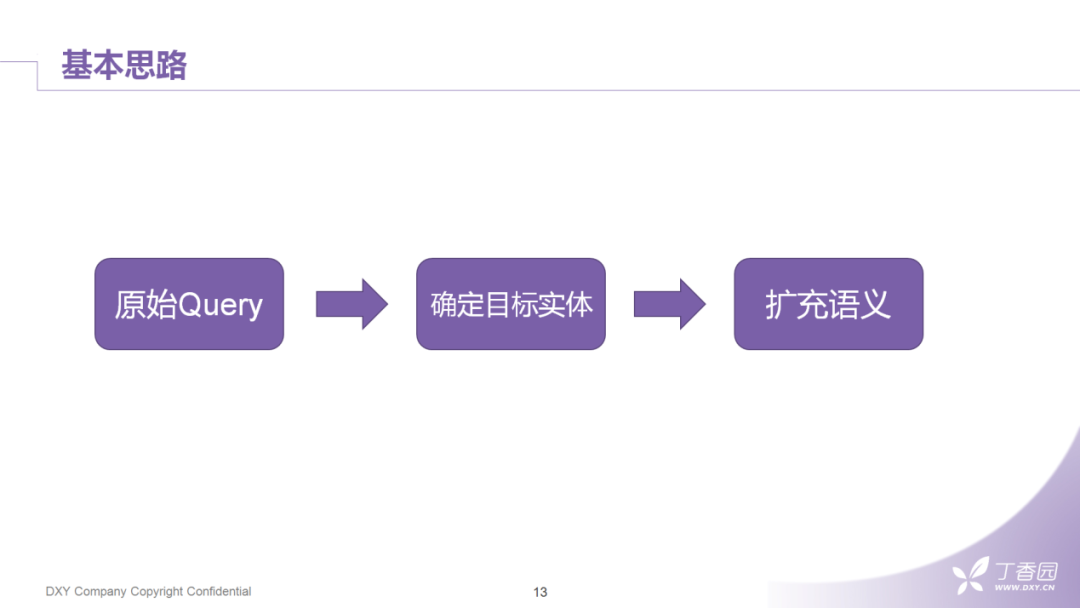
现在回到我们分享的主题。关于短文理解,由两个非常朴素的部分组成:
我们需要首先确定query中目标实体是什么,尽量保证准确度。
根据实体本身的语义、上下文语义、用户的行为对query进行扩充。
1. 常见的识别困境
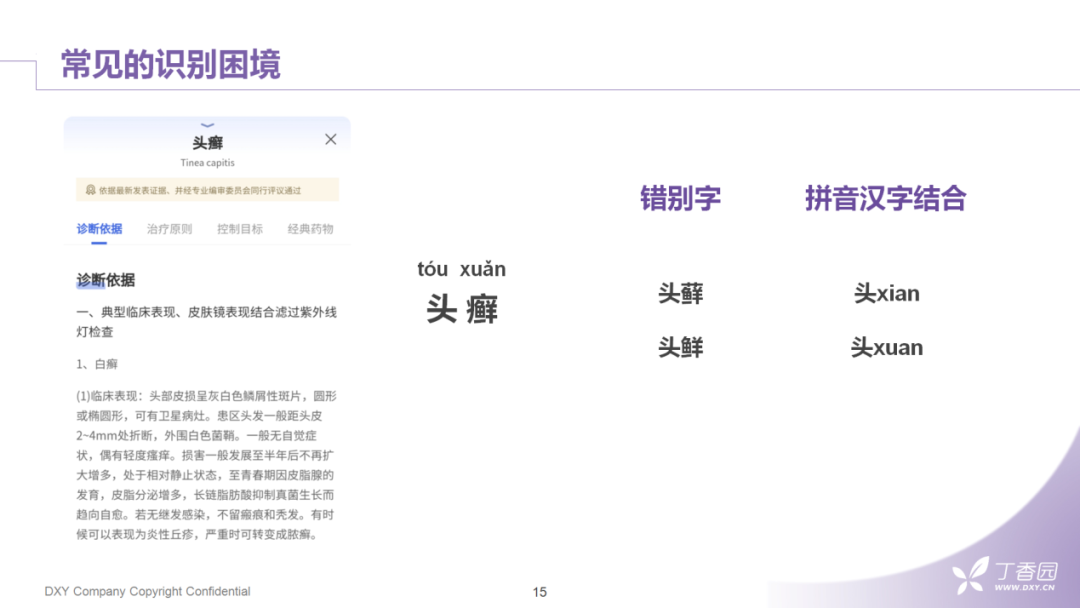
识别准确度的问题:
首先是错别字的问题。错别字问题在各个领域的搜索中都是非常常见的问题。常见的错别字原因,可能来自于拼音使用的错误。比如"头癣"这个词,大多数人会念成"头藓","藓"字就会常常出没在相关的搜索query里。另外,还会出现和拼音相关的识别问题,比如"头xian"和"头xuan",这种汉字和拼音混搭的情况。

认知层面的不同:
非医学科班的同学看到"复发性阿弗他口炎"这个词肯定是一脸懵。其实这个词和感冒一样是非常常见的问题,就是我们平常说的"口腔溃疡"。但对于大众来说,会有更多通俗的表述,如"口疮"、"口腔溃疡"、"口腔溃烂"、"嘴巴起泡"等等。如果是医学背景的用户,他大概率会知道这个专业名词,但是会出现其他的一些错误,比如表述上会缺其中的一个组成部分或者缺一到两个字,如"阿弗他口炎"或者"复发性口炎"。还有种情况就是把通俗表述和缺省表述混搭的表述方式,如"阿弗他溃疡"、"阿弗他口腔溃疡"。
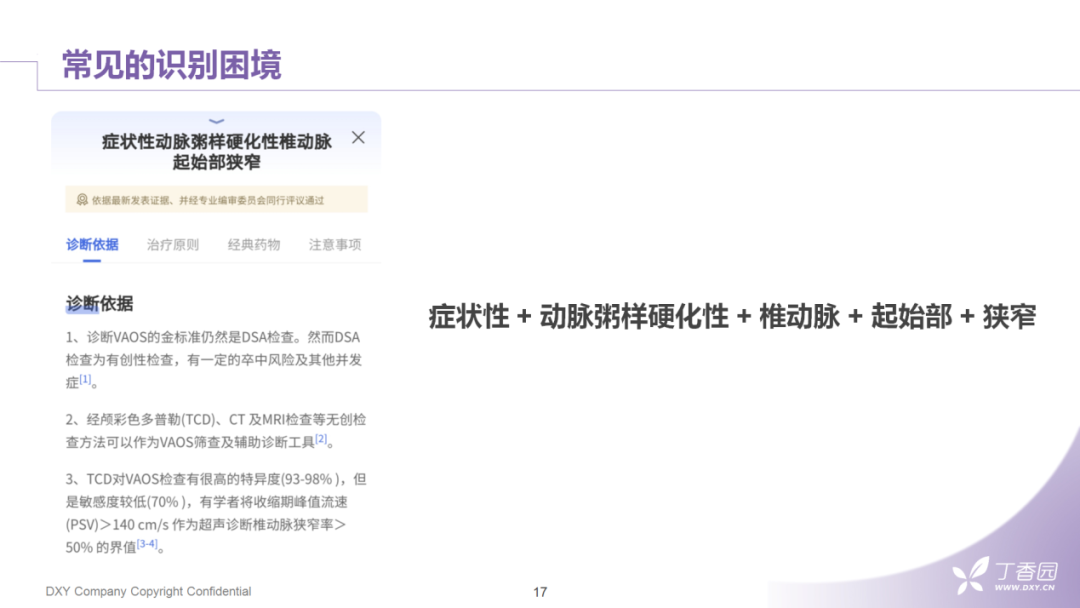
专业医学词汇的词干经常非常长:
在我们这个例子中,"症状性动脉粥样硬化性椎动脉起始部狭窄"这个词长达18个字。仔细观察,你会发现它其实具有明显的组成部分,它是通过不同的组成部分拼接成的长词。如果我们在识别一个短文本中这样的长词没有被合并在一起,而是按照不同的组成部分分开的话,那系统就会默认每个组成部分具备单独的语义,那显然非常容易检索到不相关的内容。
2. 短文本理解蓝图
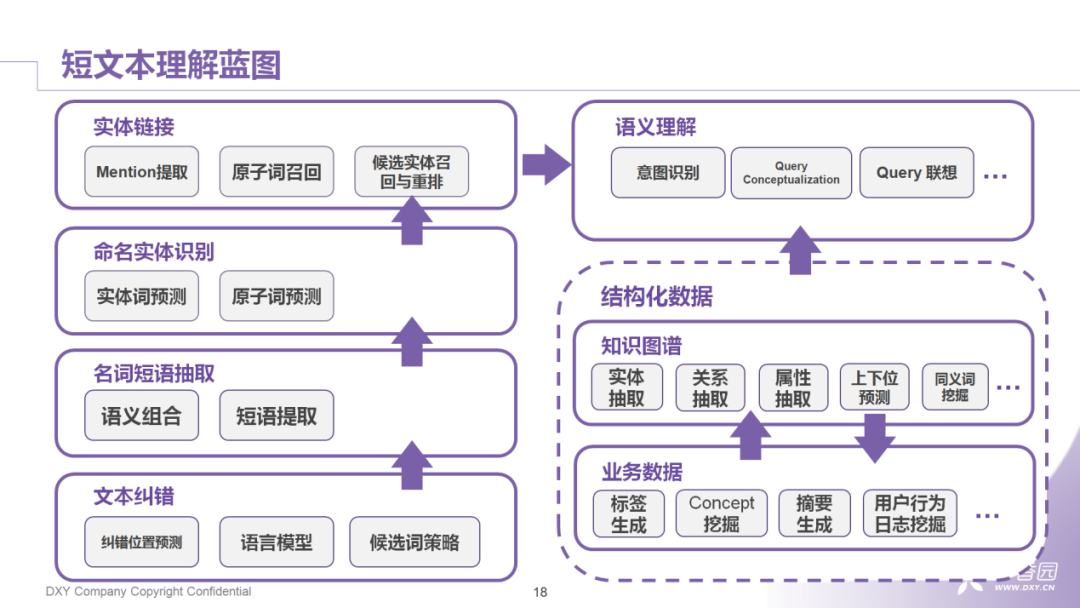
为了改善上面提到的几种情况,我们尝试把短文本理解的流程拆成了五个步骤。前四个步骤主要解决实体识别的准确率问题,包括文本纠错、名词短语抽取、NER ( 命名实体识别 ) 和实体链接。第五步需要结合底层数据的积累,包括知识图谱的建设以及结合具体业务场景的数据来完成query语义上的扩充。
3. 文本纠错
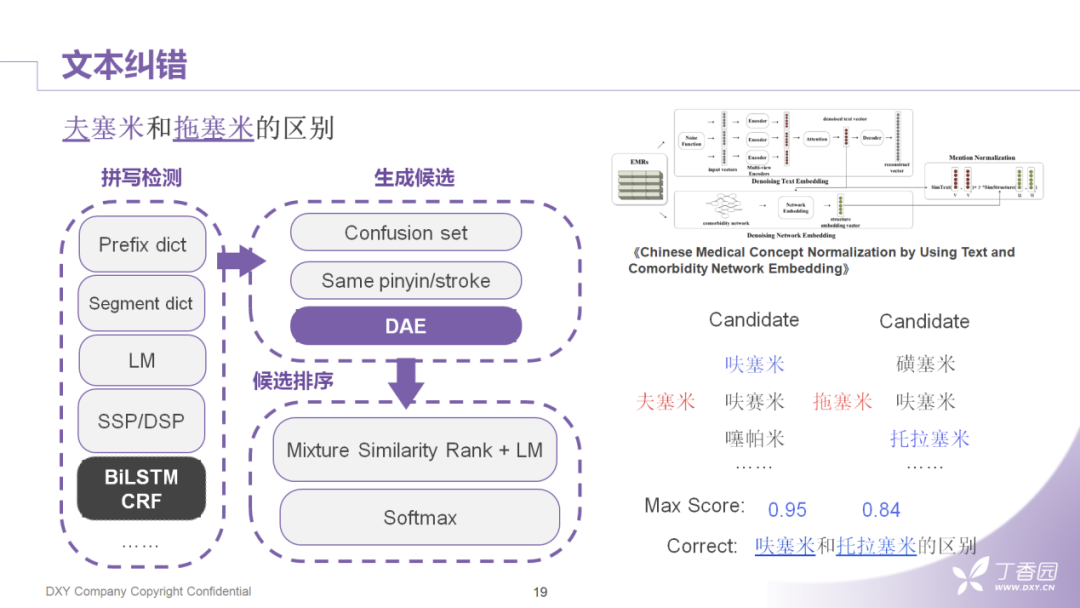
首先是文本纠错,目前业界标准的流程有三个步骤:
拼写检测。就是检测query中到底哪个字错了。常用的方案是利用已有的词典或语言模型的统计结果,结合句法分析的规则来确定错误的字。目前学术界有些新颖的方案,比如说利用序列标注找错误点。但是在实际测试中,这样的模型都比较重,并且在我们的场景中其预测准确率的问题不会特别突出,所以我们目前还是保留比较传统的方式。
生成候选词。常见的做法就是利用同音、同型字典把出错的字替换掉,然后生成一个候选集合。这里值得一提的是:如果我们所在的业务场景是比较窄的情况下,比如只需要搜索药品或者搜索疾病时,我们借鉴18年发表在IEEE上一篇关于医疗概念归一化的文章,它的主要思路是对原文本中一些字做增减或者替换,然后构建一个confusion set ( 混淆字集合 ),把词跟字的连接构成一个graph,然后获得graph上的embedding之后一起放进端到端的auto encoder,即DAE,把DAE训练到收敛之后会使用一个向量集的检索生成候选集。在实践中,这个方案效果更优一些。
候选排序。常规地对候选集做一个重排序和打分。
4. 名词短语抽取

完成纠错之后会正常进入一个分词的阶段。分词器常规会带上一个业务词典。但是因为预测的文本上下文语境或者词在词典中会存在一些嵌套现象,有时包含一个完整语义的短语还是会被分开。因此,第二步的目标就是做名词短语抽取工作,把分词阶段已经被分开的词重新组合在一起。大致的思路:
构建一个有标注的数据集,用PMI等统计量特征,借助automated prhase算法进行正负样本拆分,然后训练分类器,最后用一个对长度做修正的函数对名词短语打分。在本例中"芒果过敏"就是我们最终想要的名词短语。
5. 命名实体识别
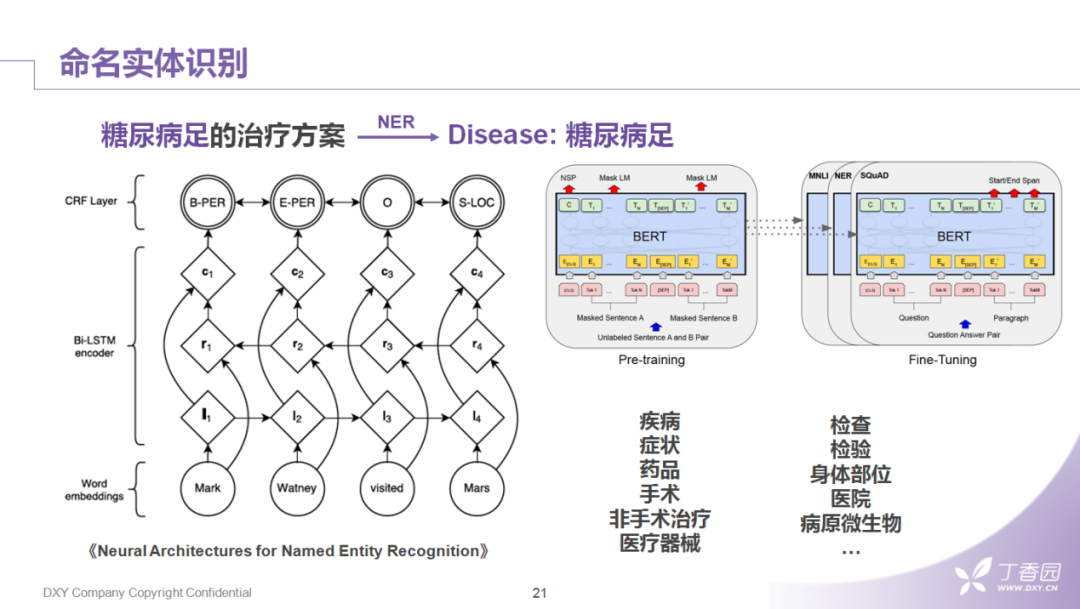
当然,名词短语也没有办法完全保证所有实体或者需要保留完整语义的短语结构完整。有些名词会被分词器切得太碎,名词短语可能也合并不回来,所以需要流程的第三步,用NER作为补充。
这里的NER在结构上采用了业界的标配:CRF+Bi-LSTM。在离线场景,允许NER耗时长一点,可加一些BERT之类的encoder作为输入。目前在我们的场景,该NER可以支持20多种医学实体的识别。
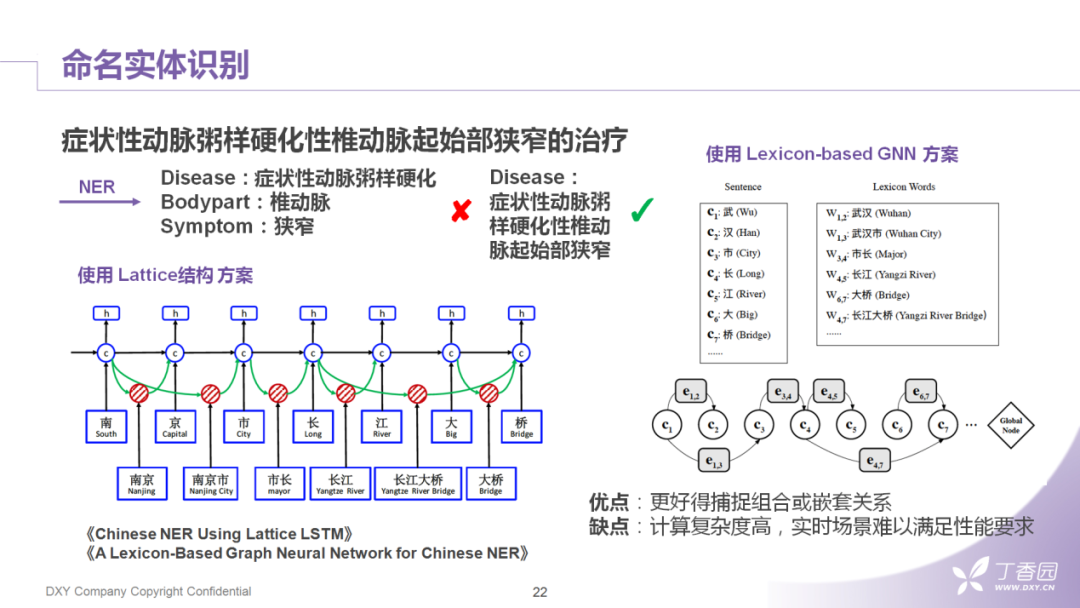
看到这里有小伙伴可能会疑惑:为什么不把名字性短语和实体词同时train到NER中。其实我们也注意到:学界从18年开始,在这个方向有了很多的方案。总的来说有两种思路:
使用lattice的结构把每个字作为词根或词尾的情况都train到模型中;
生成类似短语的那种lexicon,把字、词、lexicon的关系建成一个graph,再把graph的特征融进NER中。
这两种方案在效果上确实有提升,但坦率地说,因为带有lattice这种结构,计算复杂度一般都比较高。我们这里谈论的是短文本理解,作为一个相对前置的任务,可能这样的复杂度耗时还是长了些。所以在实际的应用中我们还是会使用基础版NER模型作为我们流程中的一个组件。
6. Mention提取
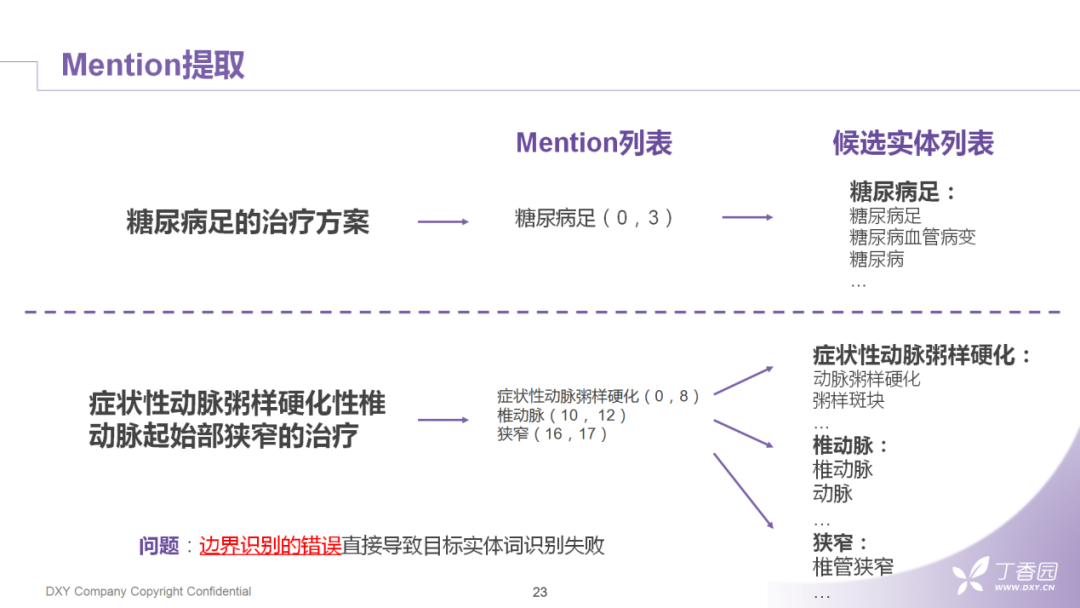
我们现在还是以基础版的组件继续往下走,以上的几个步骤为后续做实体链接框定了词的边界。候选词一般我们用常见的搜索引擎,比如solr,给它做一个倒排索引,然后我们再拿mention去找目标实体词。如果是下面的情况,医学名词的span非常长,mention提取时,其实就失败了。这种失败也会直接导致实体链接的失败,所以我们的思路就是在召回阶段再做一层补充的策略。
7. 召回增强与实体链接

前面提到医学中的长词通常会由多个组成成分进行组合。这种组成成分其实可以根据一些先验知识把它先规范好。相似的思路,我们在华东理工大学的一篇工作中也看到了。文章作者是根据SNOMEDCT中"临床发现"的分类层次体系把症状词拆分成了不同的组成。我们也根据自身的场景完善了12个类别的成分原子词,比如例子中的"主动脉瓣退行性病变",然后可以分成:身体部位+特征词+性质修饰词。
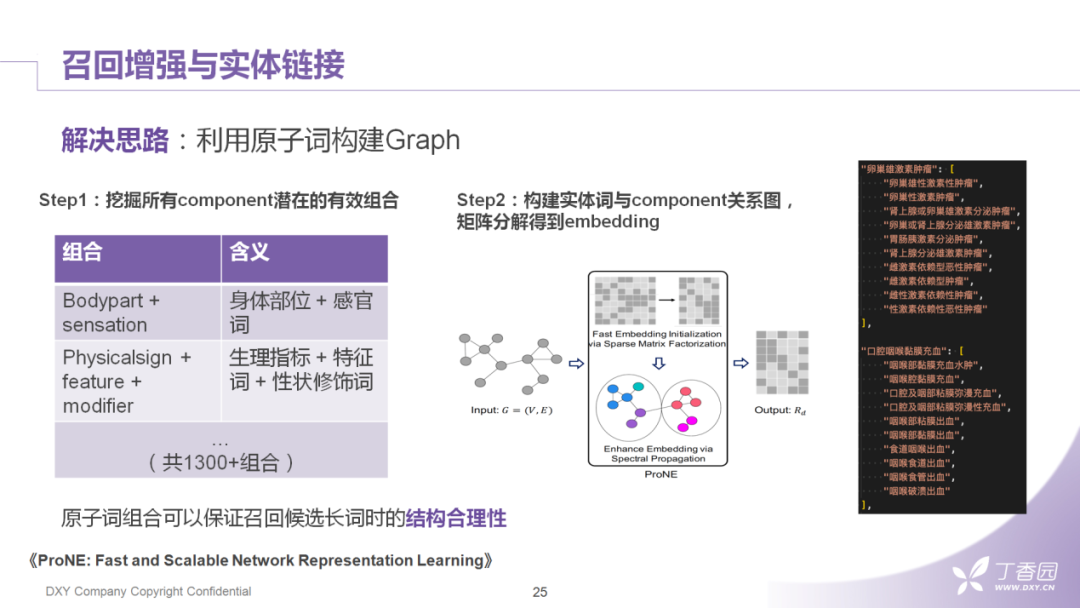
同时,不同的组成成分在位置上存在的是有限的组合,通过对已有的一些实体词挖掘,最后我们可以固定1300多种组合。后续我们再将这些原子词和组成成分相互连接,构成一个graph。然后固定的组成成分的组合类型,就为图中的有向边提供了数据来源。我们拿这个graph可以使用LINE、node2vec之类的方式train一个embedding。我们采用的是清华大学19年在IJCAI上发表的矩阵分解的方法。可以看到我们train完graph embedding后,相似度聚合的一些结果。可以发现以这种方式结构化一个疾病词可以保证疾病词在结构上的稳定。也就是说,原始的排列组合想要表述的是某种肿瘤,我们需要保留这个肿瘤作为base词的结构。
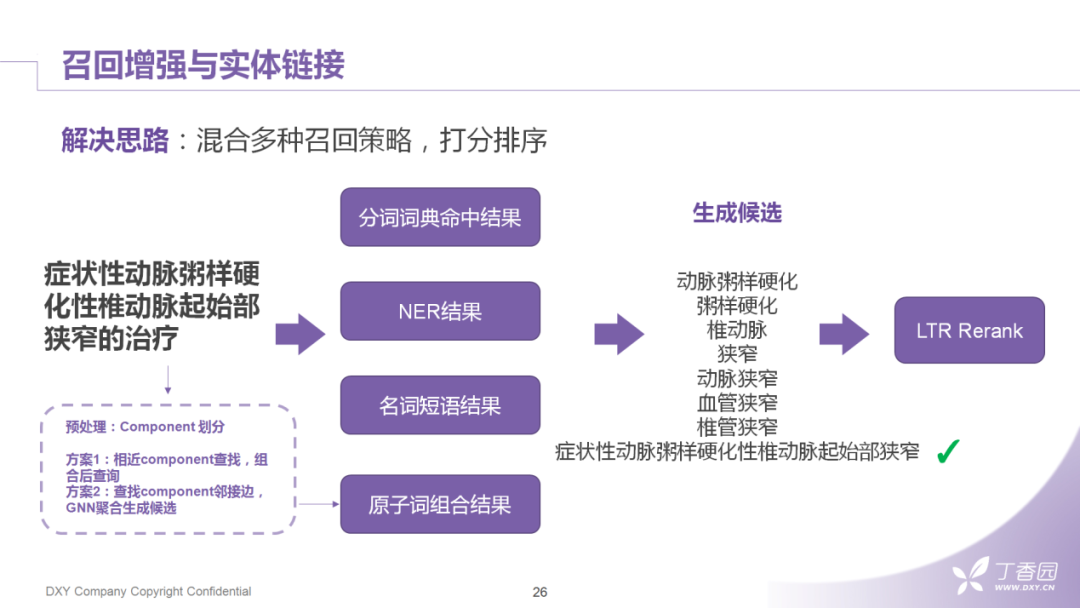
在召回策略中除了使用词典命中的结果、NER的结果、名词短语的结果,现在可以补充原子词召回的结果,这样可以提高长词被命中的概率。最后,对候选词进行LTR ( learning to rank ) 的排序,获得top1结果。
1. 语义从何而来

当我们解决了识别准确率的问题后,接下来就是如何解决短文本的理解问题。我们认为短文本之所以难理解,不仅在于长度较短,同时也因为文本中的语法相对比较自由,且需要在非常有限的信息中解析出语义的逻辑。所以我们分析了在我们搜索场景中用户日常表述的特点,除了单一实体词为搜索query外,其他大致可以分为这四种情况:
第一种情况就是用户的需求在于想要获取围绕某个实体词的属性信息,比如:"高血糖的判断标准"、"糖尿病的并发症"。常规做法上,我们会对query做实体链接,"高血糖"是知识库中的一个实体词。在这样的流程下,经过一个倒排索引做文章的检索,或者帖子的检索,会很容易发生主题上的偏移。
第二种情况是由多个实体词合并出完整语义,比如"2020年执业医师考试大纲"。"2020年"、"执业医师"和"考试大纲"三者都是独立的实体词,但是存在相互约束和限制,所以需要合并成整个短语来保留语义。
第三种情况比较类似上面的例子,也是多个实体词,但不同的是:他们是围绕一个潜在的主题来表达的一些关键词。比如:"新冠疫情在哈萨克斯坦的现状"这一主题,用户可能只会搜索"新冠+空格+哈萨克斯坦"之类的表述。
第四种情况是包含复杂逻辑的句子。句子中会包含一些上下文的语境以及复杂的逻辑。

来看一个具体的query——"短T1长T2","短T1长T2"是什么意思呢?其实"T1"和"T2"分别代表着核磁共振中纵向与横向磁场变化的一个常量系数,两种磁场变化最终会影响骨骼与肌肉脏器在片子中的成像情况。这样的表述,通常会出现在病例影像讨论的帖子中,用户搜索的目的可能是想找类似的病例讨论,也可能是想学习一下核磁共振读片的方法。所以其语意从短短的几个字是无法从字面上获取的。所以,这些语义从何而来?可以很朴素的理解,信息始终只有两个来源:一个是人的先验知识,源自我们专业医学知识图谱的构建;第二是行为数据,对应的就是我们日常的业务日志以及文本上的挖掘。在理想的情况下,我们希望"短T1长T2"可以转换成,如:核磁共振的成像原理、影像、核医学、神经内科这样的主题,然后在这样的主题下再去关联到具体资讯的文章。
2. 医学健康领域Concept
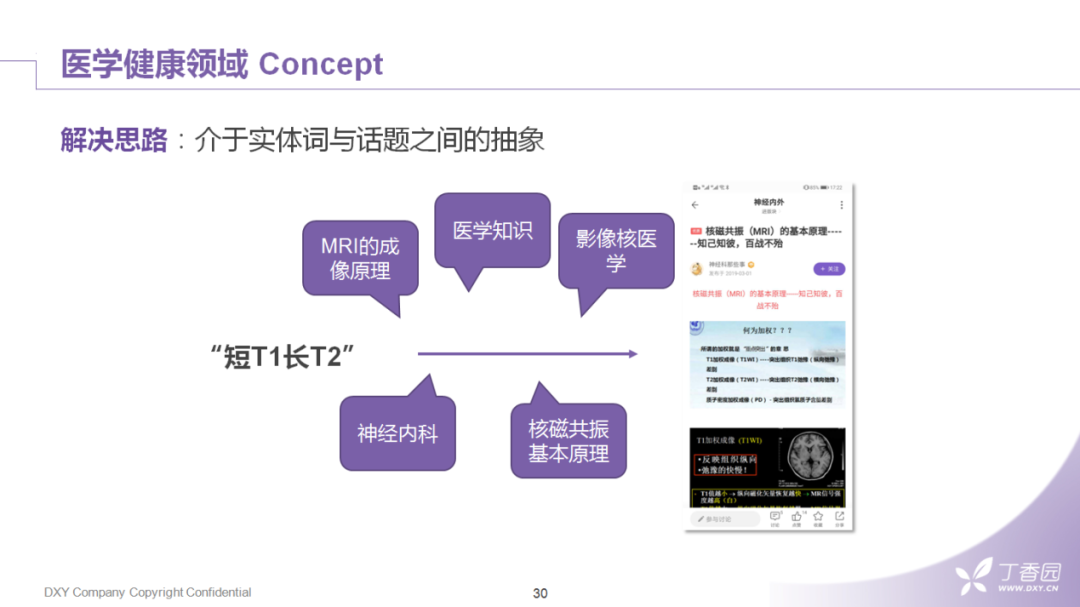
我们还可以换个思路,比如"短T1长T2"本身就是一个非常具有代表性的术语,是不是我们可以把它直接作为一种介于把实体词与话题之间的一种抽象?这样既保证了关联性又具备了可解释性。
3. Concept挖掘
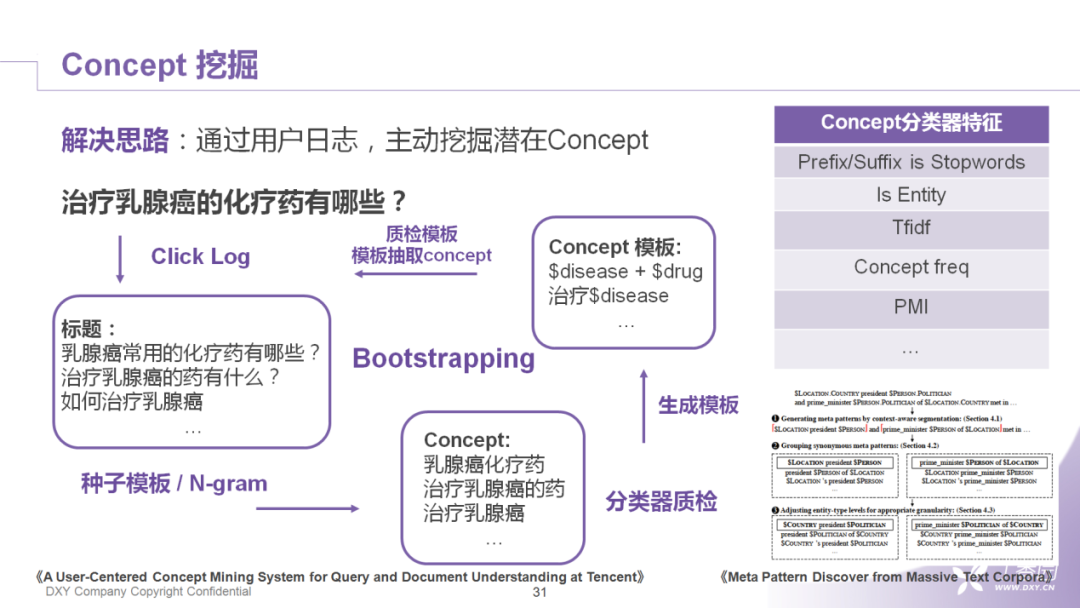
根据这样的思路,我们在丁香园的场景中,主动挖掘了大量的医学concept。具体的方法:
首先,我们收集了一批用户的搜索点击日志,然后在启动阶段定义一些种子模板,再利用模板和N-gram的策略产生一批短语,这些短语不会直接拿来用,因为其中会有一些边界问题或者模板带来的语义漂移问题。所以对生成的这些原始concept,我们会做一个分类器,作为在质量上的约束,留下质量比较高的concept。此外,再把生成的concept重新放到Query或者句子中,让它产生新的模板。这里模板的产生,我们也借鉴了韩家炜老师在MetaPAD上的一些工作。
最后,我们再对pattern做一层过滤,新的模板就可以重新再去抽concept。该算法整个结构就可以形成一个bootstrap的循环。这里安利一下腾讯团队郭老师等在去年KDD上发表的工作,工作做得非常的漂亮,也给我们提供了非常多的启发。
4. 结合专业医学知识与Concept
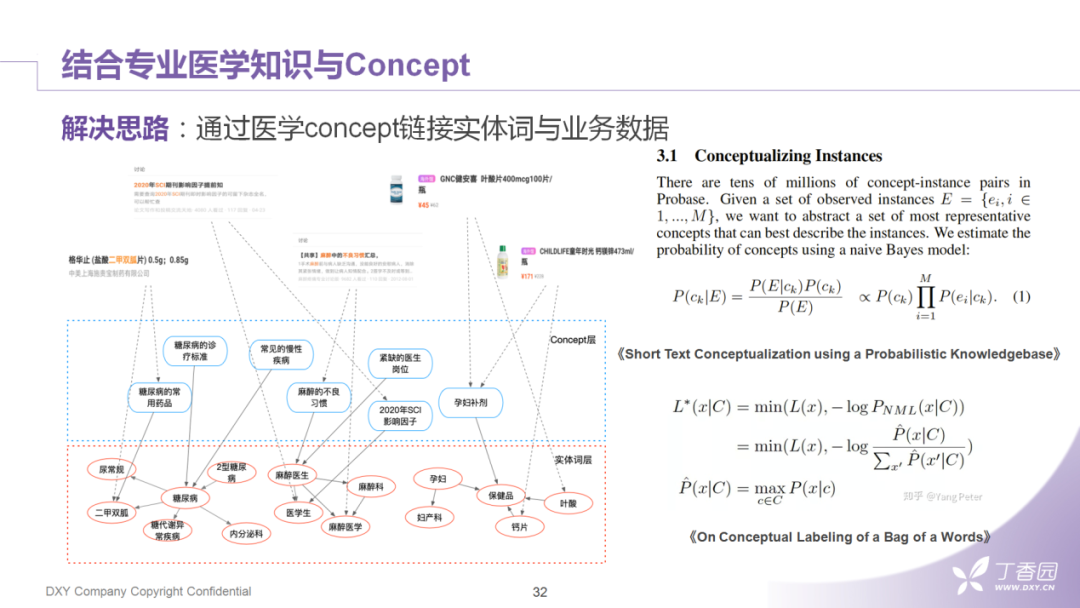
利用挖掘到的concept词,我们可以联合底层的专业的医学实体和上层的业务数据构建起一个完整的业务图谱,其中一对一的边计算的都是以Bayes模型为基础,会考虑全局统计量或者文本的局部特征;生成的多对多的边之后,我们参考王仲远老师的一些相关工作中提到的MDL ( Minimum Description Length ) 的原则做concept的筛选。这样,论坛帖子、药品信息、商城的商品就可以通过中间的concept层完成了实体链接。
1. Query扩展

在得到业务图谱之后,我们在搜索优化中就可以非常容易的利用它。比如,搜索优化中常见的Query扩展任务。
目前Query扩展的问题主要有两类方法:第一种是利用query词和document词的相关性构建一个贝叶斯模型,扩展的结果就是document词或者是document中出现的一些词组,这样会帮助在召回阶段扩大潜在用户想要的文本。第二种方法,是把它作为一种翻译模型,从query词翻译到document词。
早期比较朴素的方案是用EM算法找两类词的对齐关系,现在新的方案都是上神经网络train一个生成模型。在我们有了concept层之后,用一些很简单的策略就能有不错的效果,比如我们会直接使用相关性的方式,也就是刚才提到的第一类方法去建模,就可以把原始query向concept层上扩展。比如"哈萨克斯坦",就可以扩展出"新冠疫情"或"不明肺炎";同样,在电商场景下,我们可以利用扩展的concept和其他的实体关系做一个二级扩展,比如"产褥垫"可以扩展出"待产包",然后再从待产包扩展出"卫生巾"、"纸尿裤"。这样的应用其实也带了一点推荐的意思。
2. 标签生成增强

我们在文本结构化上也可以利用concept做一些提升,文本结构化对于提升搜索效果起到了非常重要的作用。有了concept之后可以帮助我们从抽象的层面完成对文本打标签。业界中比较好的方案,是先用一个TransE之类的知识表示模型,把知识图谱train出Embedding,然后将这些Embedding融合进LDA的模型中。在模型中,会用vMF分布代替原来的高斯分布来处理实体词的部分。这样我们就会对一篇,如"麻醉不良习惯"的讨论帖子抽出"麻醉医学"和"麻醉的不良习惯"这样的关键词。

最后,总结一下短文本理解需要做的几项工作:
首先,需要解决的是实体词识别的准确率问题,因为实体词是我们扩充语义的根基。实体识别不准的话,语意也无从谈起。
第二点是从用户行为日志中挖掘出concept,然后把这些concept作为跨越业务数据和底层专业医学知识的语义媒介。
最后,将concept结合业务数据构建其业务图谱。从而协助下游完成包括搜索,推荐之类的任务。
在文末分享、点赞、在看,给个三连击呗~~
嘉宾介绍:

杨比特
丁香园 | 资深NLP算法工程师
杨比特,硕士毕业于军事医学科学院,负责丁香园大数据NLP组,目前专注于医疗健康领域下的自然语言处理、知识图谱构建与应用、搜索与推荐技术。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“医疗健康” 可以获取《医疗健康领域的短文本理解》专知下载链接索引







