这场MongDB事故暴露的潜在危机,你是否也正在忽视?

作者介绍
张开威,咪咕音乐公司数据库专家,OCM认证资质,具有10年+的数据库运维经验
一、MongoDB特性
MongoDB是一个可扩展的高性能基于文档的NoSQL数据库,具备但不限于以下特性:
无数据结构限制和高性能
MongoDB以文档结构的存储方式,能够更便捷的获取数据;
MongoDB没有表结构的概念,每条记录可以有完全不同的结构,业务开发方便快捷,而SQL数据库需要事先定义表结构再使用;
在简单的业务结构下,其性能高于MySQL,如:MongoDB不指定_id插入>MySQL不指定主键插入>MySQL指定主键插入。
丰富的支持
Redis的key-value(只能按key查询,灵活性和易用性不足),而MongoDB支持单键索引、多键索引、数组索引、全文索引、地理位置索引、过期索引等;
MongoDB执行支持范围查询,正则表达式查询,对子文档属性的查询等,是最像SQL数据库的NoSQL数据库;
内置GridFS,支持大容量的存储。
方便的冗余与扩展
MongoDB的单机可靠性较差,但其复制集可保证数据安全;
分片扩展可处理大数据量的业务,其副本、分片伸缩扩展方便,维护简单。
良好的支持
官方拥有完善的文档;
齐全的驱动支持:官方提供了多数流行编程语言的驱动支持;
拥有诸多第三方社区论坛。
二、MongoDB故障经历
基于MongoDB的优异性能,在我司也越来越多的使用。随着业务变更,负载增加,一些问题也逐渐暴露出来,在我司内部最近就遭遇多起MongoDB故障,下面简单介绍其中一个:
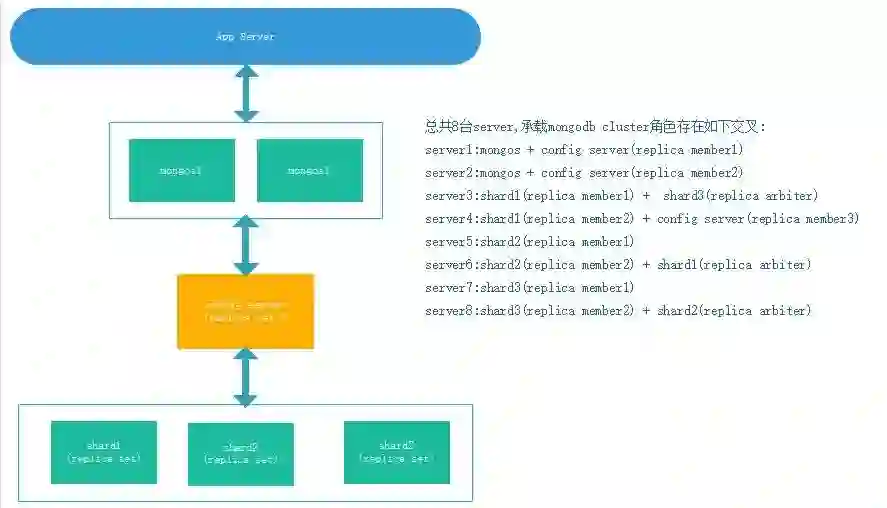
该套系统为内部主机监控系统,包括IO、CPU、内存、文件系统以及网络数据等,根据其监控项目本身特性,采样频率几秒到10分钟不等,因接入监控的主机数量较多,每日数据量较大。
该业务初始使用了3分片的cluster,分片规划由业务侧同事规划实施。
业务侧反馈特定某些时段业务无法连接到MongoDB,往往几分钟后自动恢复了正常,且最近业务响应比以前明显减慢。
接到反馈后,检查MongoDB日志,发现阶段性出现连接用尽的告警,猜测可能是业务最近有过调整。后经业务同事确认,最近确认新接入了一批主机到该监控系统。
MongoDB连接数、maxConns参数和os参数配置的单个进程能打开的最大文件描述符数总量的80%决定的,取两个之间的最小值;
maxConns配置为3000,系统open files参数为1024;
MongoDB最大连接数为(open files value) * 80%=1024* 80%=819。
理论值和故障时情况匹配,判定造成业务间断性无法连接的原因是参数设置不合理。
间断性出现和业务模式有关系,前面提到业务不同指标间隔几秒到十分钟采样,采样入库峰值时部分业务失败。
得益于MongoDB的副本集方便调整的特点,滚动修改了各个节点参数(调整open files value到64000),并重启MongoDB服务。
此次故障原因很简单,但这引发了我们一些反思:
我们的使用方式真的正确吗?
我们的配置真的合理吗?
我们关注过性能吗?
我们的设计真的合理么?
带着这样的问题,我们重新审视分析了该系统的使用情况。不查不知道,一查下一跳,真的检查出诸多问题:
操作系统所有参数均为默认参数;
MongoDB除必要参数外均为默认配置;
MongoDB集合未分片或分片不合理,不能发挥MongoDB分片的优势,所有负载都集中在一个分片。
针对存在的问题做了以下几方面的调整:
调整系统参数
/etc/security/limits.conf
mongo soft nofile 64000
mongo hard nofile 64000
mongo soft nproc 32000
mongo hard nproc 32000
/etc/sysctl.conf
fs.file-max=98000
kernel.pid_max=64000
kernel.threads-max=64000
vm.max_map_count=128000
此外禁用了numa,Transparent HugePages及修改了磁盘调度策略:
开启MongoDB Profile
profile = 1
slowms = 200
结合业务重新设置集合片键
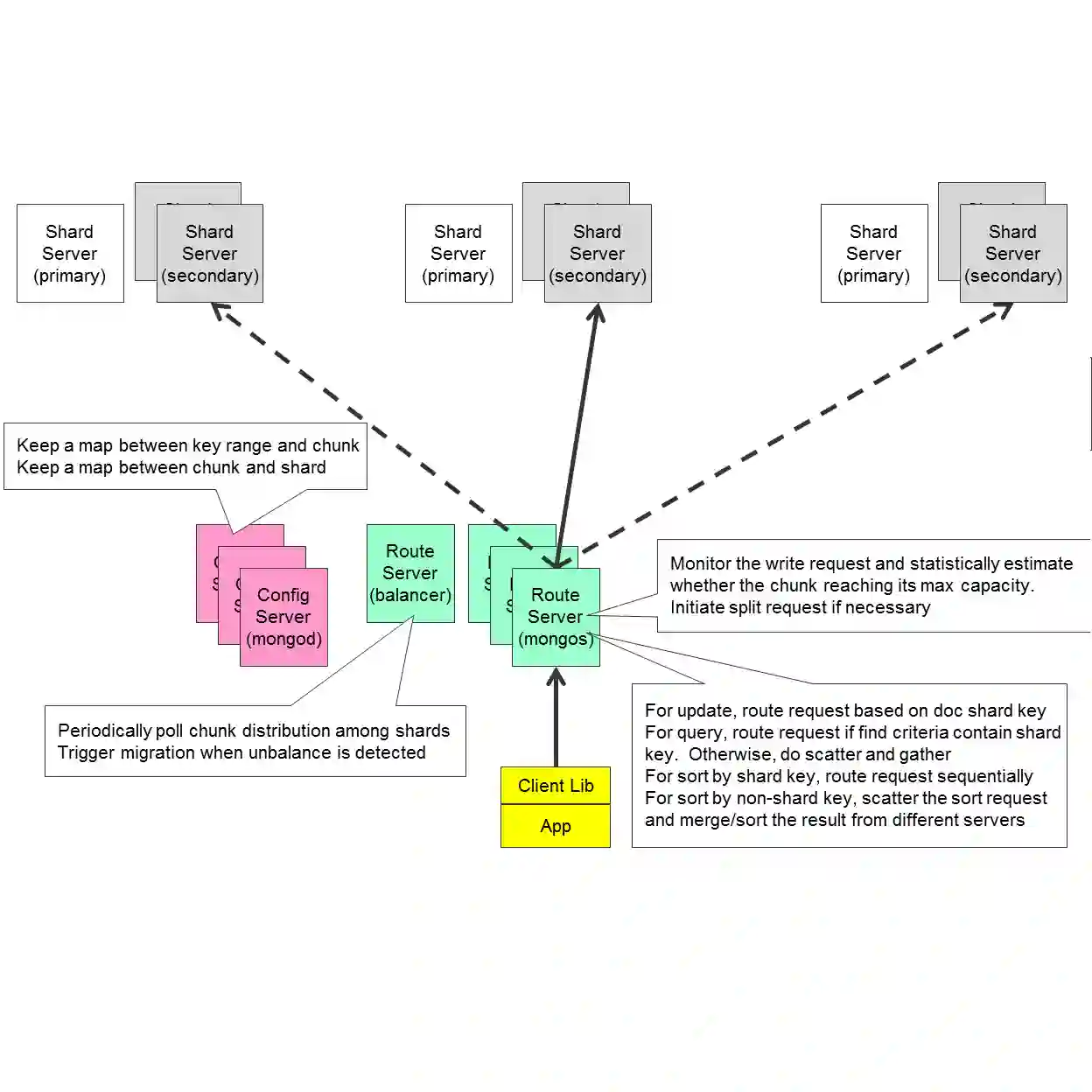
重新设计分片是本次调整的重点,那么为什么说当前系统的分片不合理,分片的依据是什么呢?这里先说一下我们评估的依据:
好的片键
将插入数据均匀分布到各个分片上;
保证CRUD操作能够利用局部性;
有足够的粒度进行块拆分;
片键上必须有索引,最好选择业务会用到的索引字段分片。
不好的片键
小基数片键:随着数据的增加,一个chunk逐渐变大,无法继续分裂,只能添加硬盘来保证足够的空间存储数据;
避免升序片键:范围分片的范围为正负无穷,如果使用升序片键(包含object_id及时间,自增主键等),那么最近的数据始终存储在一个分片,不能充分利用到分片带来的好处;
随机片键:随着数据的增大,由于其随机性,分片间的数据平衡可能需要加载大量的块到内存和引发大量IO,导致性能降低。
当前数据库内仅有少数集合进行了分片,并且片键均为时间类型,造成负载集中在其中一个分片上。我们希望能找到一种既能保证足够的粒度,不会造成巨型chunk,也能控制分片粒度,不会降低效率。
按照上述原则,我们搭建了测试环境,与业务同事共同讨论并进行了多次测试,尝试了不同的分片组合及分片方式,对比了不同分片下的业务性能,我们总结出如下规则:
{Locality: 1,search : 1}:第一个字段控制局部的数据,第二个字段为常用的搜索字段;第一个字段为粗粒度字段,第二个字段为细粒度字段。
在整个调整过程中,经历了多次压测,下面展示部分测试数据:
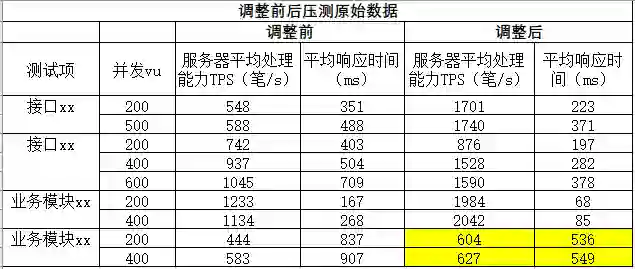
服务器ip+信息采集时间组合分片测试数据
上表为最终的片键改造方案下的部分压测数据,可以看出,调整前后性能提升较大。
三、心得
我们整理一下mongodb在咪咕的运维心得,希望能抛砖引玉。
务必建立完善的运维管理流程,故障处理机制等;
规范化、模板化:对日常运维务必做到规范化,比如安装规范,避免人为原因重复踩坑。
确保内存设置能满足性能需求:确保内存>索引容量+高频访问数据容量
大多数情况下,MongoDB热数据(索引和最频繁访问的数据)全部缓存在RAM中时性能最好;
相对于其它优化,扩大内存的效果尤为显著;如果热数据超过了单个服务器的RAM,此时往往需要考虑扩大内存或者分片。
使用SSD磁盘
写操作负载高的应用采用SSD:SSD提供强大随机读取性能,大部分情况下符合MongoDB的数据访问模式。
使用RAID
出于安全和性能考虑,可采用合适的RAID模式,推荐RAID-10。
选用多核和更快的CPU
MongoDB在更快的CPU上提供更好的性能,且WiredTiger存储引擎能够充分利用多核处理器资源(并发线程数和cpu核心数量相等)。
开启NTP时间同步
使用复制集或者分片集群需要开启NTP时间同步,这对于MongoDB正常运行尤为重要。
禁用NUMA
MongoDB运行在NUMA系统上会导致性能下降,因此需关闭NUMA配置。
linux6 修改/boot/grub/grub.conf中kernel,添加numa=off
linux7 修改/etc/grub2.cfg中linux16部分添加numa=off
禁用Transparent Huge Pages
数据库往往具有稀疏而不是连续的内存访问模式。应该在Linux机器上禁用THP以确保使用MongoDB获得最佳性能。
设置readahead
预读值是文件操作系统的一个优化手段,程序请求读取一个页面的时候,文件系统会同时读取下面的几个页面并返回。
设置合理的readahead值有利于提高MongoDB性能,使用MMAPv1引擎推荐设置为32或16,对于WiredTiger无论何种存储介质都建议设置为0。
blockdev --report
blockdev --setra 0 /dev/sda
设置合适的磁盘调度策略
磁盘调度策略应当根据应用类型和硬件配置进行设置,对于MongoDB,推荐使用noop。
文件系统选择
MongoDB在WiredTiger存储引擎下建议使用XFS文件系统。
关闭数据库文件的atime
操作系统会维护文件最后的访问时间metadata,对于数据库意味着每次文件系统每访问一个页就会提交一个写操作,这将降低整个数据库的性能,禁止系统对文件的访问时间更新会有效提高文件读取的性能。
设置合理的系统内核参数
系统为防止单个用户/进程占用大量资源(比如线程、文件等),在内核参数上进行了限制,这些限制默认值较低,这会导致MongoDB运行可能遭遇一些不必要的问题。因此应当根据实际情况对内核参数进行适当调整。
mongo soft nofile 64000
mongo hard nofile 64000
mongo soft nproc 32000
mongo hard nproc 32000
fs.file-max=98000
kernel.pid_max=64000
kernel.threads-max=64000
vm.max_map_count=128000
尽量避免使用单机
单机不具备容错能力,生产中应当尽量避免使用,如处于某些限制只能使用单机,那么需要确保拥有完善的备份机制和故障恢复机制。
每台服务承载一个MongoDB实例
为获得最佳性能,每个服务器只部署一个MongoDB实例,降低资源争夺;如一台服务器上需要运行多个MongoDB实例,应当为每个实例分配合理的内存,避免内存争夺导致oom。
分片使用多路查询路由
在不同服务器上部署mongos,最好将mongos部署在应用服务器上,应用连接本机的mongos。
存储引擎配置数据压缩
MongoDB在使用WiredTiger和encrypted引擎时默认开启了压缩,压缩比约为70%--80%;
MongoDB WiredTiger默认使用Snappy,该选项消耗较低的CPU资源获得较高的压缩率,此外提供zlib选项,该选项比Snappy拥有更高的压缩率,但会消耗更多的CPU资源。
设置合理的Path
如条件允许,将数据和索引目录分开,每个目录挂在不同的硬盘设备,将数据和目录存放到不同的物理设备。
启用directoryPerDB,每个数据库不同目录,每个目录挂在不同的设备。
设置合理的oplogsize
设置足够的oplog大小,确保足够的同步/维护时间窗口,避免因oplogsize太小导致同步中断。
启用安全认证
启用安全认证会降低MongoDB性能,出于安全考虑,任然建议开启安全认证,除非MongoDB运行在安全的网络环境之内。
选择合适的片键
片键的选择对于分片集群的性能至关重要,合理的片键可以提高MongoDB整体性能,糟糕的片键可能会让你的MongoDB集群不如单机MongoDB。
好的片键应当具有以下特征:
将插入数据均匀分布到各个分片上;
保证CRUD操作能够利用局部性;
有足够的粒度进行块拆分;
片键上必须有索引,因此选择业务会用到的索引字段分片,好处是可以避免索引浪费,减少空间和性能损失。
善用索引
如果没有索引MongoDB需要把所有的Document从盘上读到内存,这会对MongoDB服务器造成较大的压力并影响到其他请求的执行。
同时,应当根据业务选择合适的索引属性,比如可以利用TTL自动删除过期的数据。
避免索引滥用
不依赖于每个字段的独立索引,合适的组合索引相比于每个字段创建索引占用存储空间更小且同样能提升效率,但需要注意组合索引字段顺序及排序问题。
监控profile
开启mongodb的profile对该实例的操作进行监控,为性能优化提供依据;
启用Log Rotation
MongoDB默认情况下不会自动的切换日志的,这将会导致日志逐渐增大,在繁忙的业务下,日志增长快。查看某一时段的日志极不方便。需要对MongoDB日志文件进行切换,根据实际需求保留若干天。
程序合理配置驱动
程序应根据MongoDB架构和业务需求配置驱动程序,从而实现读写分离、故障转移等。

近期热文