领域应用 | 完备的娱乐行业知识图谱库如何建成?爱奇艺知识图谱落地实践
转载公众号 | 爱奇艺技术产品团队
2012年5月16日,谷歌首次正式提出了知识图谱的概念,希望利用结构化知识,来增强搜索引擎,提高搜索质量和用户体验。
也就是说,从诞生之日起,知识图谱就和搜索引擎密不可分。
随着大数据时代的到来和人工智能技术的进步,知识图谱的应用边界被逐渐拓宽,越来越多的企业开始将知识图谱技术融入其已经成型的数据分析业务。目前知识图谱已成为人工智能领域的重要分支,在搜索、自然语言处理、智能助手等领域发挥着重要作用。
爱奇艺搜索团队早在2015年就开始着手搭建自己的知识图谱库——奇搜知识图谱库。本文将讲述奇搜知识图谱的构建过程,及其在爱奇艺搜索、NLP服务中的具体应用。
01
什么是知识图谱?
谷歌发布的文档的描述中,知识图谱是一种用图模型来描述知识和建模世界万物之间关联关系的技术方法。本质上,知识图谱是一种揭示实体之间关系的语义网络,可以对现实世界的事物及其相互关系进行形式化地描述。
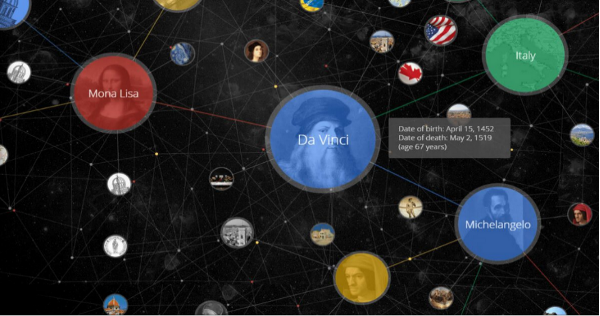
在知识图谱里,我们通常用“实体(Entity)”来表达图里的节点、用“关系(Relation)”来表达图里的“边”。实体指的是现实世界中的事物比如人、地名等,关系则用来表达不同实体之间的某种联系,比如人-“居住在”-北京、张三和李四是“朋友”、逻辑回归是深度学习的“先导知识”等等。
现实世界中的很多场景非常适合用知识图谱来表达。 比如一个社交网络图谱里,我们既可以有“人”的实体,也可以包含“公司”实体。人和人之间的关系可以是“朋友”,也可以是“同事”关系。人和公司之间的关系可以是“现任职”或者“曾任职”的关系。
02
奇搜知识图谱的构建
爱奇艺搜索(奇搜)作为国内最大的视频搜索引擎之一,致力于为用户提供优质的全网视频、娱乐领域的搜索服务。
当传统的文本检索搜索方式不能满足给用户提供更为精准和智能的搜索体验的目标时,为了丰富用户视频娱乐搜索结果、为了对用户搜索意图实现精准理解与直观回答,奇搜团队努力完善对视频内容的理解、对用户意图的理解,并在过程中构建了以视频领域为主的知识图谱库。
在经历几个版本的迭代后,目前的奇搜知识图谱的构建流程主要分为知识表示与建模、知识获取、知识融合、知识存储、知识应用(知识查询与推理)几个步骤和模块,下面我们一一予以介绍。
2.1 知识表示和建模
构建知识图谱之前,首先需要确认知识的建模表示方式。目前主要的知识建模方式有两种:
(1)先为知识图谱设计数据模式(schema),再依据设计好的数据模式进行有针对性的数据抽取,这是自顶向下的数据建模方法;
(2)先进行数据的收集和整理,再根据数据内容总结、归纳其特点,提炼框架,逐步形成确定的数据模式,这是自底向上的数据建模方法。
爱奇艺奇搜知识图谱的构建采用的是自顶向下的建模方式,图谱Schema定义基于RDF三元组、以及RDFS的规则。
RDF(Resource Description Framework),即资源描述框架,实际上是一种数据模型,由一系列的陈述即“对象-属性-值”三元组组成。
Triples:[S, P, O]
RDF用Subject,Predicate,Object三元组与原陈述的三个部分联系起来。
主体(subject):声明被描述的事物
谓词(predicate):这个事物的属性
客体(object):这个属性的值
一个三元组就是一个关系。在RDF里我们可以声明一些规则,从一些关系推导出另一些关系。这些规则我们称为“schema”,所以有了 RDFS(RDF Schema)。这些规则用一些词汇(可以类比编程语言里的保留字,不过RDF里任何词汇都可以被重定义和扩展)表示,如常用的规则subClassOf,表示父类子类的关系。
爱奇艺基于RDF/RDFS定义了图谱的实体类型、关系(属性)类型、以及实体本身的schema定义。如下图中,Rules层,是一些基础概念的定义,包括RDF/RDFS已有的定义及基于RDF/RDFS定义的、供实体类型/属性定义使用的规则定义,该层规则的定义一般在确定后是不可变的。本体定义层,包括可实例化的实体类型(可继承)和属性(可继承)的定义,如Thing,Person,wife,name等。实体层,保存在我们的实体库中的具体实体。每一层定义在schema的表示语法上都是一致的。
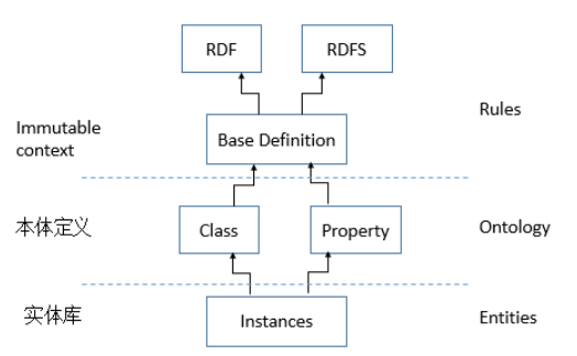
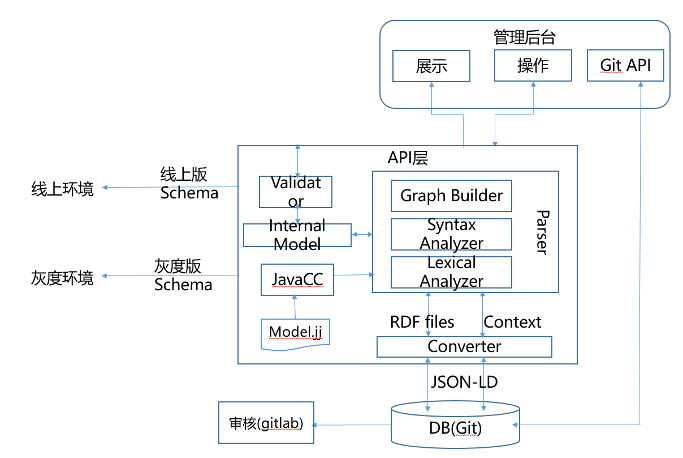
为了帮助定义和使用图谱schema(主要是上图中的本体定义层),爱奇艺开发了一套schema系统来负责管理、解析奇搜知识图谱的schema定义:
最终定义的实体类型的继承关系片段示例如下图:

2.2 知识获取
在知识图谱中,数据扮演着底部基石的作用。知识图谱是源于数据的,是从数据中抽取结构化信息,数据的好坏直接关系到知识图谱构建的效率和质量。比如从结构化的数据中构建知识图谱会比从非结构化的数据中构建效率和准确率要高,数据越复杂,噪音越大,构建成本也就越高。
知识获取是构建知识图谱的核心与前提条件,也是自动构建知识图谱最关键的影响要素和重点研究领域。我们经过各种尝试后,目前奇搜知识图谱的数量来源除去人工创建的数据外,主要有以下站内、垂直网站与百度百科三种数据来源:
| 来源 | 优势 | 劣势 |
| 站内数据 | 结构化好、类别明确、易于获取 | 类型有限,且有的数据类型只是站内已有的数据,并不是广义上的知识类型 |
| 垂直网站数据 | 类别明确 | 获取和解析成本高,数据质量层次不齐 |
| 百度百科数据 | 数据量大,内容丰富。是目前主要的数据来源 | 没有分类信息,结构不完全固定 |
2.2.1 实体分类
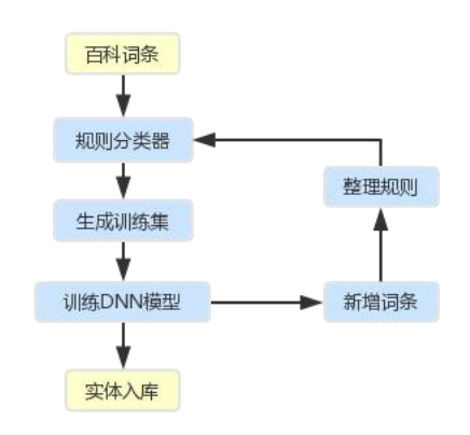
实体分类主要针对百度百科的数据,因为百度百科的数据没有类别信息,需要先对词条进行实体类型的识别。具体实现是为每种实体类型训练一个实体分类器,准确率可衡量,并且互不影响,可以快速拓展。
分类器的模型生成是通过启发式方法,构建基于规则池的分类器,生成训练数据,训练DNN模型(self-attention)文本分类模型,DNN分类器与规则分类器互相扩充迭代(一到两轮),最终线上使用规则分类器。生成过程中会用上百科词条中的描述文本、infobox字段、超链接词条、词条标签等信息作为特征。
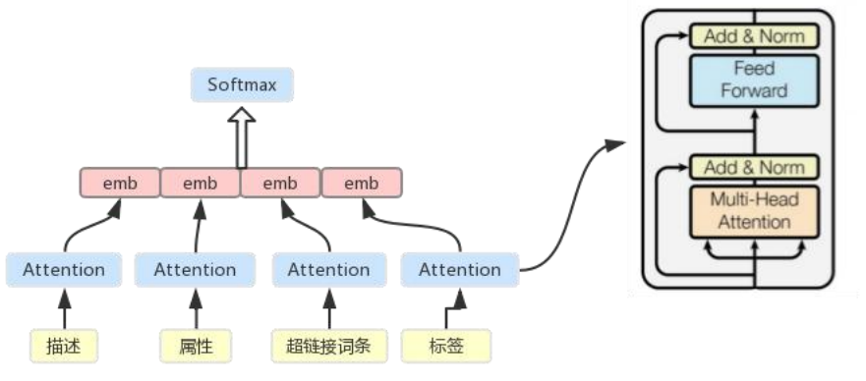
2.2.2 实体抽取
实体抽取是指从数据中的识别和抽取实体的属性与关系信息。对不同类型与不同数据源分别开发属性、关系抽取脚本进行数据抽取,由易到难主要包括以下三类抽取方式:
(1)结构化数据抽取:
大部分站内、垂直网站的信息,以及部分百度百科的信息是结构化的数据,这类数据的信息比较易于抽取。但因为源数据结构和实体类型定义(即目标数据结构)多种多样,为了提高开发效率,我们将结构化数据的抽取过程进行抽象,将抽取的流程写成统一的框架,利用策略模式将抽取的具体规则用groovy脚本来实现。当扩展新的来源和目标实体类型时,只需实现新的抽取脚本。
(2)半结构化数据抽取:
百度百科中存在很多表格、列表等半结构化信息,因为格式不完全规则,所以抽取有一定难度。但有的半结构化信息中存在一些质量较高的统计性的数据。对于这类数据,我们采用基于有监督学习的包装器归纳方法进行抽取。
(3)文本数据挖掘:
百度百科以及站内的描述等大量文本中也存在有很多宝贵的信息,对于这类数据的实体挖掘,需要借助NLP(自然语言处理)的手段。这里主要用到了我们的NLP团队提供的实体识别等服务。一方面通过实体链接服务把从文本中抽取得到的实体对象,链接到实体库中对应的正确实体对象,以挖掘文本中关系。另一方面利用实体识别技术来识别来挖掘文本中的实体。
2.3 知识融合
知识融合主要是实体对齐(Object Alignment),旨在发现具有不同ID但却代表真实世界中同一对象的那些实体,并将这些实体归并为一个具有全局唯一标识的实体对象添加到知识图谱中。
我们的实体数据有不同的来源,而且在同一来源中,也可能存在实际是同一实体的多条数据。
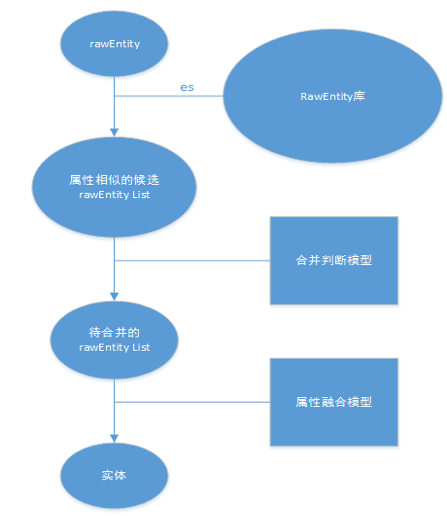
上图是我们实体对齐的流程图。首先我们所有来源的实体数据都会进入原始实体库(RawEntity库),并且对原始表中的数据建立索引。当一个原始实体rawEntity入最终实体库之前,要在原始实体库中找是否有其它原始实体和rawEntity实际上是同一个实体。步骤是首先在索引中根据名字、别名等字段查询出若干个可能是相同实体的候选列表,这个步骤的目的是减少接下来流程的计算量。然后经过实体判别模型,根据模型得分识别出待合并对齐的原始实体,最后经过属性融合模型,将各原始实体的属性字段进行融合,生成最终的实体。这个流程中的合并判断模型实际上是通过机器学习训练生成的二分类器。
2.4 知识存储
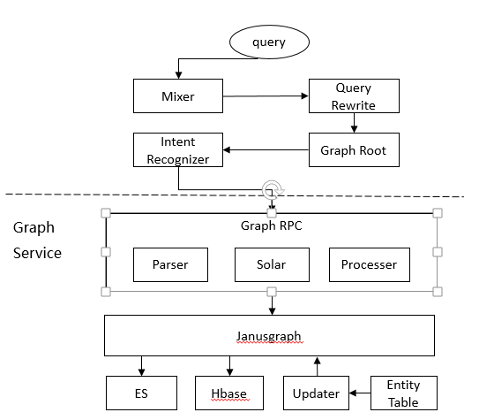
我们在线上使用的图数据库引擎选择了JanusGraph。JanusGraph需要外部的存储系统与外部索引系统的支持。所以我们借助公司云平台的Hbase和ES集群,搭建了自己的JanusGraph分布式图数据库引擎,支持在线游走查询服务。
03
奇搜知识图谱的应用
3.1 问答式搜索服务
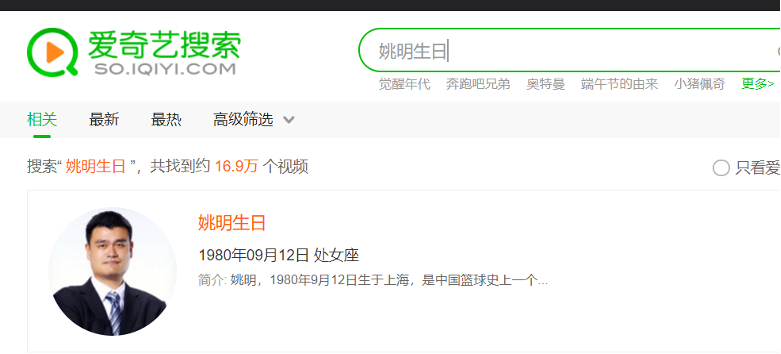
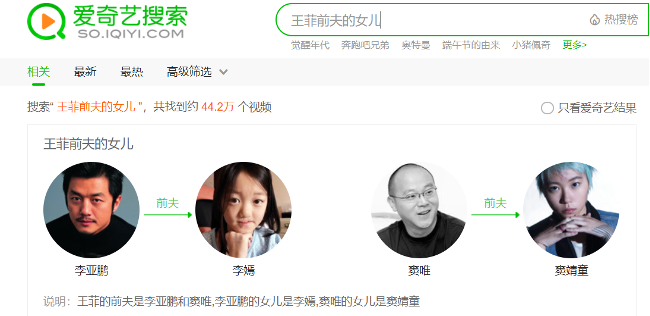
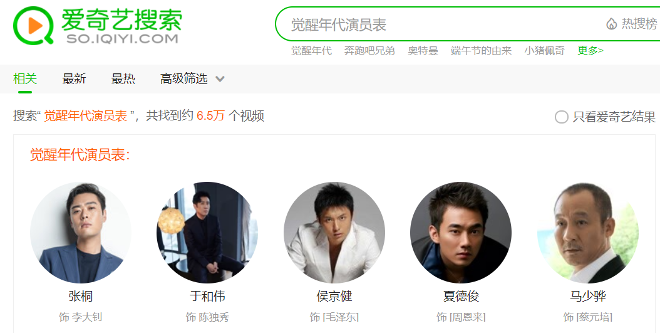
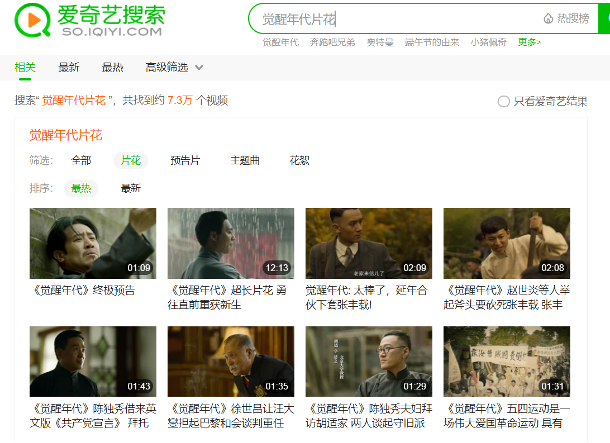
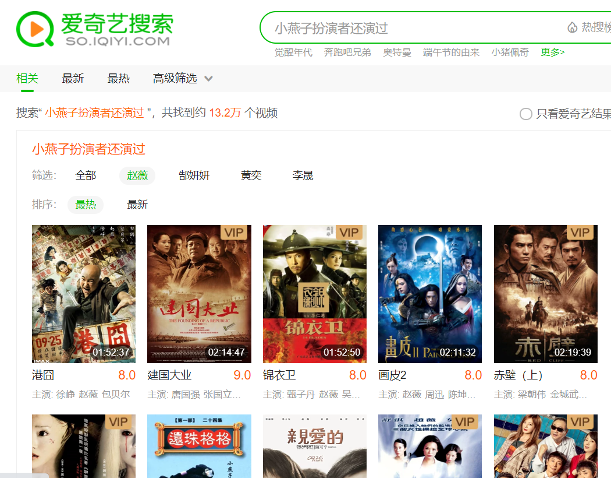
基于图数据库引擎提供的查询服务,以及NLP技术对用户query的意图理解,我们提供了多种类型的问答式搜索结果服务。包括明星、剧集的属性类的查询:XXX的生日、XXX剧的播出时间等,以及实体的关系类的查询:明星的关系(如“王菲的前夫的女儿”)、剧集与明星/角色的关系(如“觉醒年代演员表”)、剧集间的关系(如“觉醒年代片花”)、以及各种关系的组合(如“小燕子扮演者还演过”)等等。如:
3.1.1 智能问答
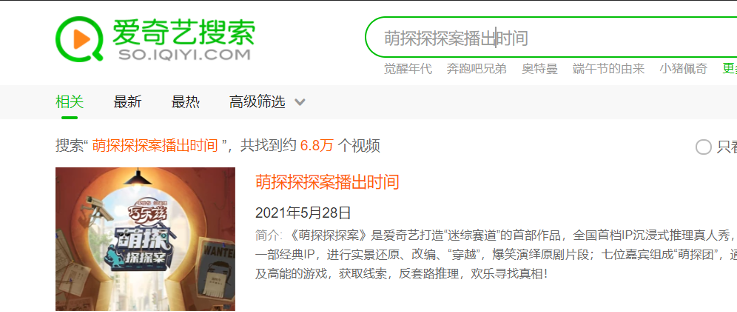
3.1.2 关系查询
3.1.3 剧集周边
3.1.4 关系组合
3.2 基础数据
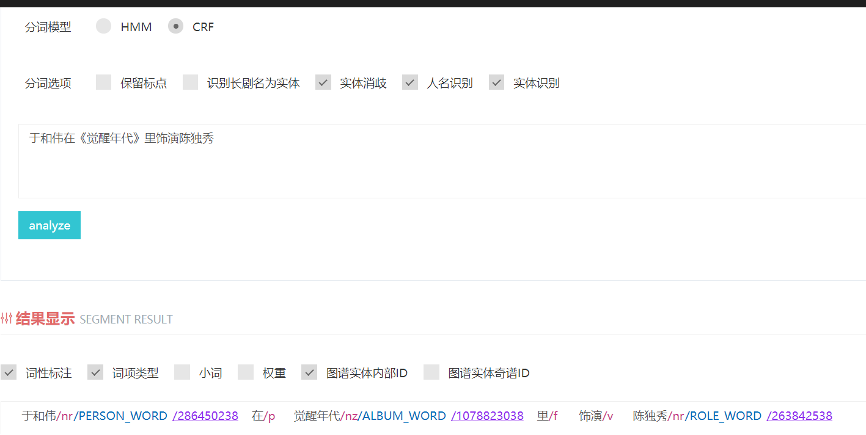
奇搜知识图谱的实体库作为基础数据被用于NLP团队提供的分词和实体识别、意图识别等服务,也在明星图谱等业务场景下直接展示。
3.2.1 分词实体识别
3.2.2 明星图谱展示

3.3 标签挖掘
利用知识图谱数据可以帮助建立和完善标签体系,以及挖掘视频数据上的标签,同时标签体系也可以反过来丰富知识图谱。
我们利用推理等技术对知识图谱进行挖掘。推理功能一般通过可扩展的规则引擎来完成。包括属性的推理,如根据出生年月推理出年龄、星座等属性,以及关系的推理,如根据已有的妻关系子推理出反向丈夫关系,根据儿子的儿子链式关系推理出孙子关系等。
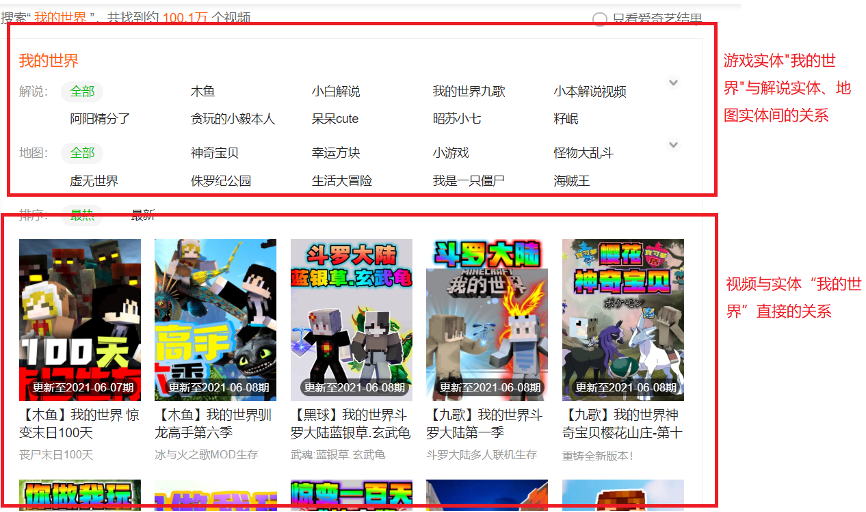
视频上的标签与图谱实体进行映射之后,相似的推理过程也可用于视频标签的扩展,主要用到实体的上下位词、属于、包含等关系。
另外也可用Graph Embedding等技术扩展同类型的关联性强的实体。
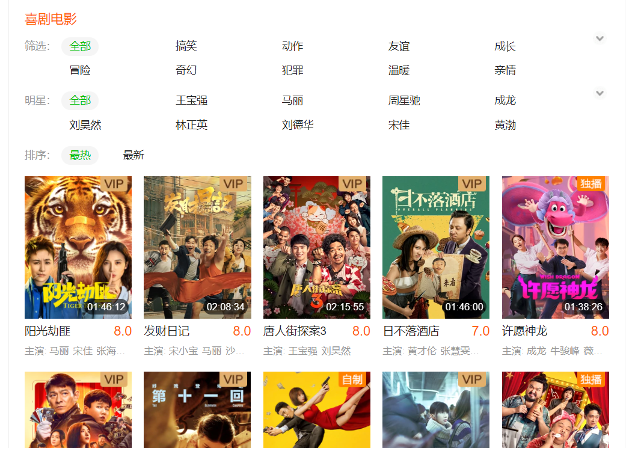
下面是一些标签挖掘的线上应用实例:


04
总结
以上是奇搜知识图谱的构建和在搜索中应用的介绍。我们可以看出,经过几年的努力,奇搜知识图谱已经被打造成为了完备的娱乐行业知识图谱库。
传统的视频搜索通过为整段视频添加文字标签,并与用户搜索信息匹配完成搜索,搜索原理与传统文字搜索相同。伴随着奇搜知识图谱的发展,全新的娱乐搜索功能给用户带来了更佳的搜索体验。知识图谱在帮助用户精确找到想要的内容、回答用户问题、以及理解用户搜索意图方便都发挥了巨大的作用。随着视频内容理解和视频知识图谱库的不断完善,未来,用户观看视频将像使用文字一样轻松便捷,对于视频搜索、互动的想象空间也在不断清晰。
近年来人工智能技术的飞速发展,给知识图谱的应用带来了更多的可能性,我们也会在知识图谱在搜索、推荐等领域的新的应用进行更多的探索。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。





