AlphaFold 虽好,但耗时且成本高,现在首个用于蛋白质结构预测模型的性能优化方案来了。
蛋白质结构预测一直是结构生物学中的一个重要的研究问题。直接从蛋白质的氨基酸序列预测蛋白质的三维结构在许多领域都有广泛的应用,包括药物设计、蛋白质设计等。
预测蛋白质结构的方法主要有两种:实验方法和计算方法。实验方法需要以高昂的时间和经济成本获得更准确的蛋白质结构。计算方法则能够以低成本高吞吐量预测蛋白质结构,因此提高计算方法的预测精度至关重要。借助深度神经网络,AlphaFold 能够周期性地以原子精度预测蛋白质结构,但 AlphaFold 模型的训练和推理由于其特殊的性能特点和巨大的内存消耗,既耗时又昂贵。
基于此,来自潞晨科技和上海交大的研究者提出了一种蛋白质结构预测模型的高效实现 FastFold。 FastFold 包括一系列基于对 AlphaFold 性能全面分析的 GPU 优化。同时,通过动态轴并行和对偶异步算子,FastFold 提高了模型并行扩展的效率,超越了现有的模型并行方法。
![]()
论文地址:https://arxiv.org/abs/2203.00854
实验结果表明,
FastFold 将整体训练时间从 11 天减少到 67 小时,并实现了 7.5 ∼ 9.5 倍的长序列推理加速
。此外,研究者还将 FastFold 扩展到 512 个 A100 GPU 的超算集群上,聚合峰值性能达到了 6.02PetaFLOPs,扩展效率达到 90.1%。
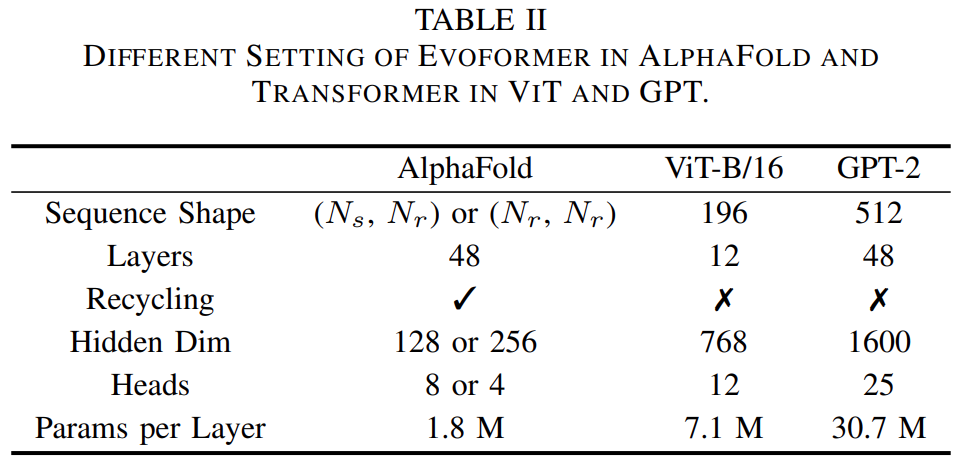
不同于一般的 Transformer 模型,AlphaFold 在 GPU 平台上的计算效率较低,主要面临两个挑战:1) 有限的全局批大小限制了使用数据并行性将训练扩展到更多节点,更大的批大小会导致准确率更低。即使使用 128 个谷歌 TPUv3 训练 AlphaFold 也需要约 11 天; 2) 巨大的内存消耗超出了当前 GPU 的处理能力。在推理过程中,较长的序列对 GPU 内存的需求要大得多,对于 AlphaFold 模型,一个长序列的推理时间甚至可以达到几个小时。
![]()
作为首个用于蛋白质结构预测模型训练和推理的性能优化工作,FastFold 成功引入了大型模型训练技术,显著降低了 AlphaFold 模型训练和推理的时间和经济成本。
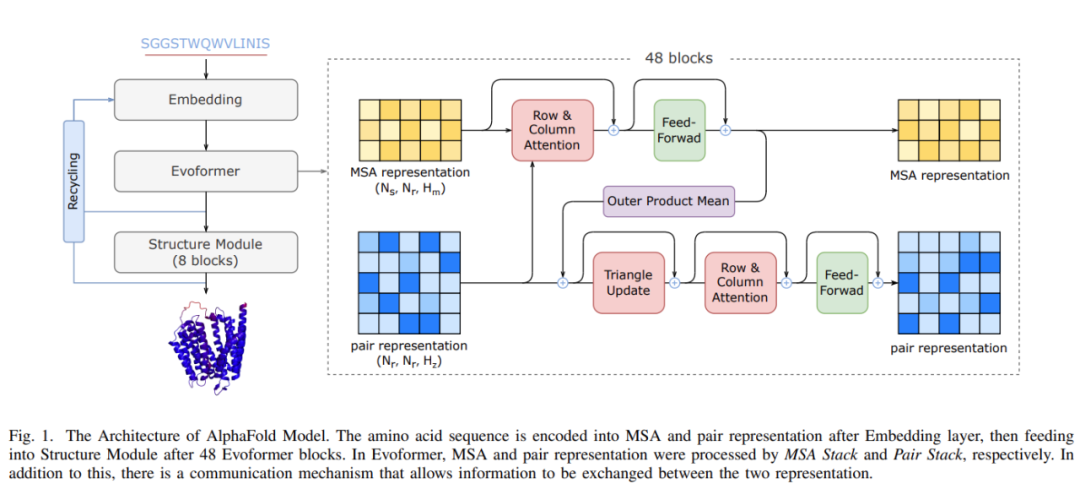
FastFold 由 Evoformer 的高性能实现、AlphaFold 的主干结构和一种称为动态轴并行(Dynamic Axial Parallelism,DAP)的模型并行新策略组成。
根据计算和存储访问的特点,该研究将算子分为三大类:
1) GEMM。这类包括矩阵乘法、批矩阵 - 矩阵相乘和其他密集矩阵计算。来自 NVIDIA Tesla GPU 的张量核可以显著加速 GEMM 算子;
2)批递减算子。这类包括 LayerNorm、 Softmax 等,计算强度低于 GEMM 算子,并且更容易出现访问瓶颈。
3)Element-wise 算子。这类包括 element-wise 的相加、相乘、dropout 和激活,是计算密集度最低的一类。
![]()
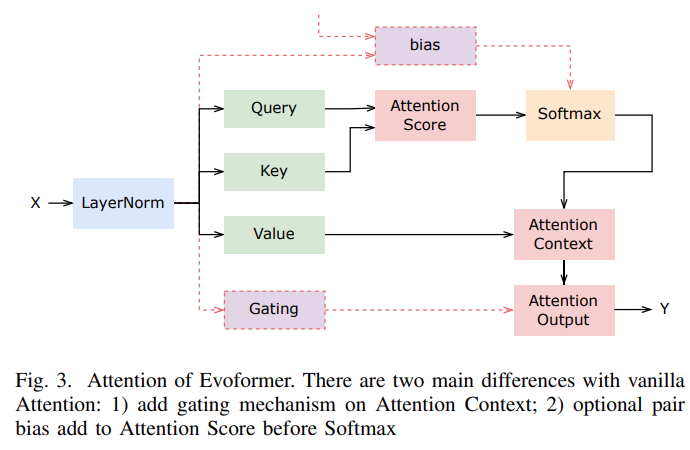
值得注意的是,Evoformer 和原版 Transformer 之间有几个关键区别:
![]()
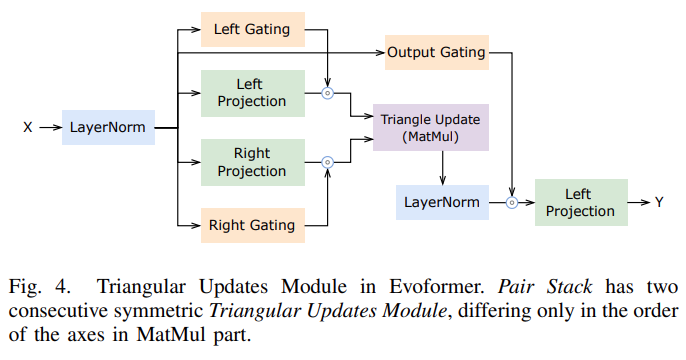
该研究分析了 Evoformer 的复杂结构并进行了内核融合,并针对 Evoformer 中的特定操作和基于性能特征的特定内核进行了优化,例如 Softmax 和 LayerNorm。高性能的 Evoformer 实现大大降低了训练和推理的经济成本。
![]()
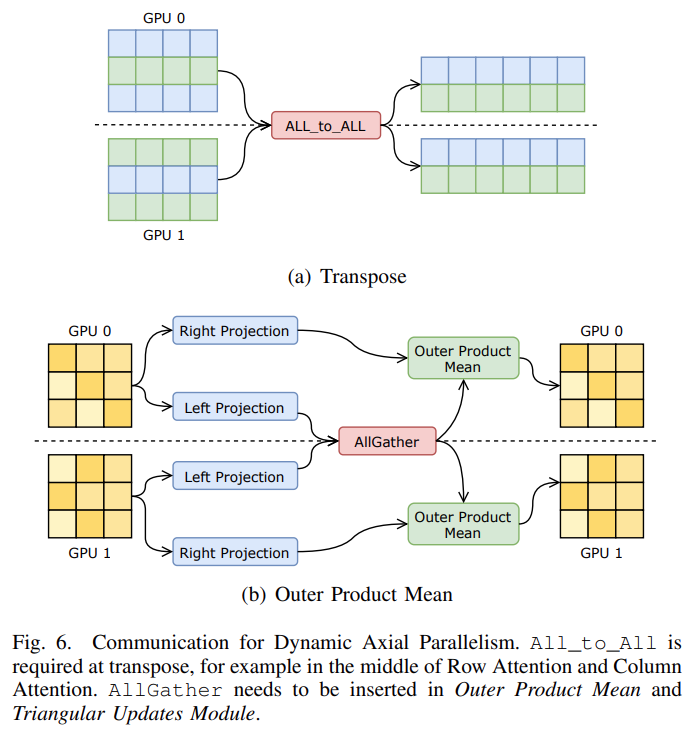
在并行策略方面,该研究根据 AlphaFold 的计算特征创新性地提出了动态轴并行策略,在 AlphaFold 的特征的序列方向上进行数据划分,并使用 All_to_All 进行通信。动态轴并行(DAP)在扩展效率方面优于当前的标准张量并行(Tensor Parallelism),DAP 具有以下几个优势:
支持 Evoformer 中的所有计算模块;
所需的通信量比张量并行小得多;
显存消耗比张量并行低;
给通信优化提供了更多的空间,如计算通信重叠。
![]()
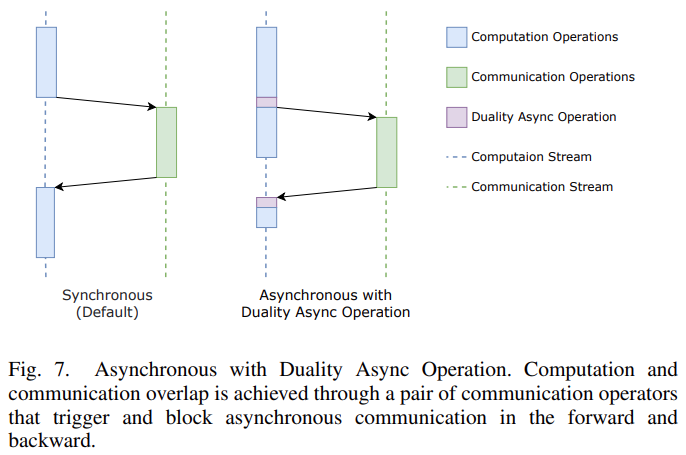
在通信方面,该研究提出了由一对通信算子组成的对偶异步算子(Duality Async Operation)。
这种新方法在模型前向传播的过程中,前一个通信算子触发异步通信,然后在计算流上进行一些没有依赖性的计算,然后后一个通信算子阻塞,直到通信完成;在反向传播的过程中,后一个算子将触发异步通信,前一个算子阻塞通信。
利用对偶异步算子可以很容易地在 PyTorch 这样的动态框架上实现前向传播和反向传播中的计算和通信遮叠。
![]()
研究者首先评估了 Evoformer 内 核的性能改进,然后对端到端训练和推理性能进行了评估。所有的实验都在 NVIDIA Tesla A100 平台上进行。基线是 AlphaFold 的官方实现和另一个 OpenFold 开源 PyTorch 实现。官方实现的 AlphaFold 只有推理部分,而 OpenFold 则是根据原始 AlphaFold 论文复制训练和推理的。
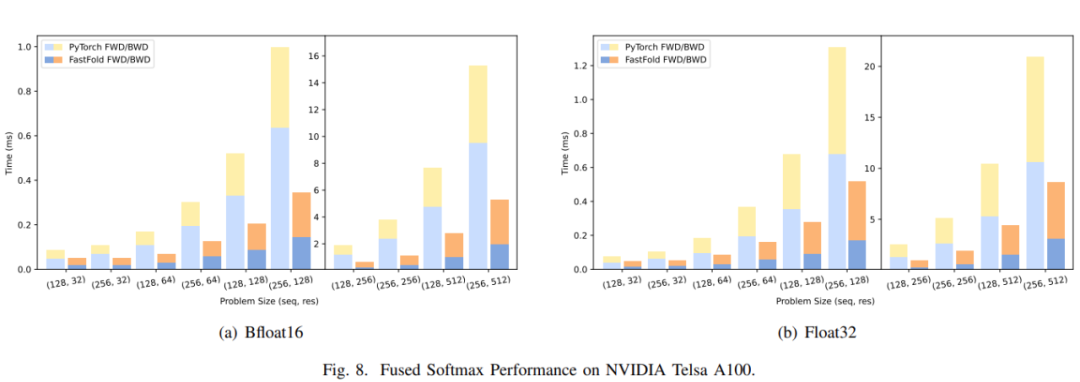
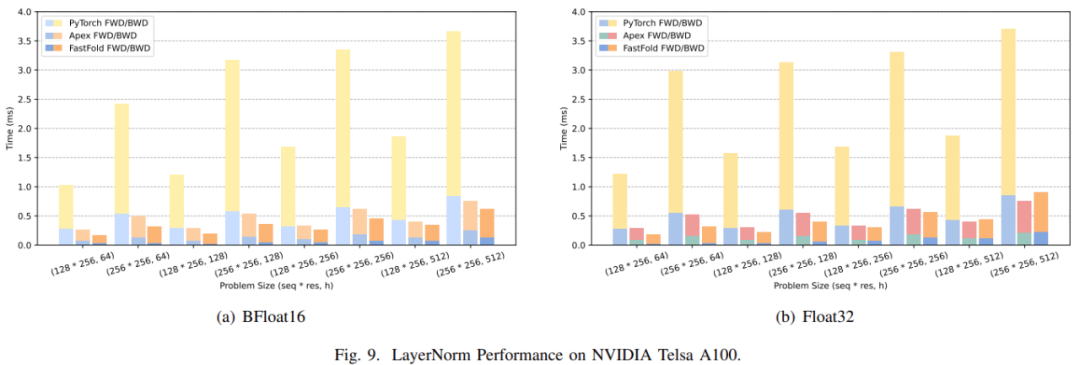
图 8(a)和图 9(a)分别展示了 Fused Softmax 和 LayerNorm 的性能比较。
对于 Fused Softmax,研究者比较了 PyTorch 原生内核和 FastFold 优化内核的性能。注意力输入序列的长度是 x,注意力的隐藏大小是 y。从图 8(a)可以看出,FastFold 内核的性能可以提高 1.77∼3.32 倍 。
![]()
对于 LayerNorm,研究者不仅比较了 PyTorch 原生内核,还比较了 NVIDIA Apex 中高度优化的 LayerNorm 内核。如图 9(a) ,FastFold 的性能比 PyTorch 和 Apex 分别提高了 5.53∼8.65 倍 和 1.20∼1.62 倍 。由于对有限范围的特别优化,相比于高度优化的 Apex LayerNorm,FastFold 也实现了良好的性能改进。
![]()
在端到端训练表现的评估中,研究者使用官方 AlphaFold 文件中的训练参数进行了尽可能多的测试。这样可以更好地比较不同的方法或实现在实际的训练场景中的工作方式。所有的训练实验都是在 128 节点的 GPU 超级计算机上进行的。在超级计算机中,每个节点包括 4 台 NVIDIA Tesla A100,并且有 NVIDIA NVLink 用于 GPU 互连。
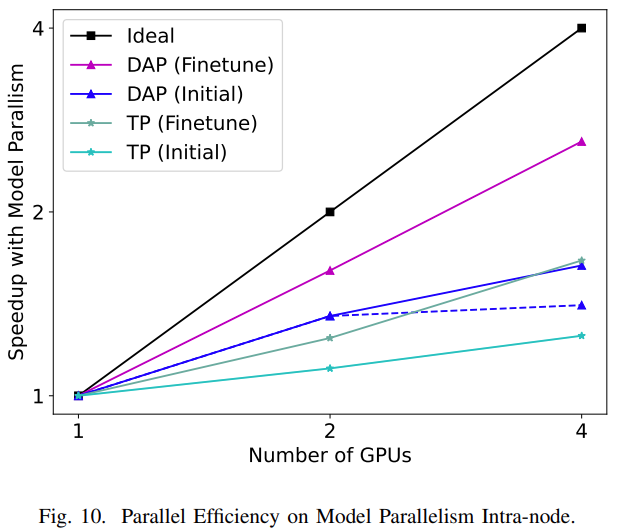
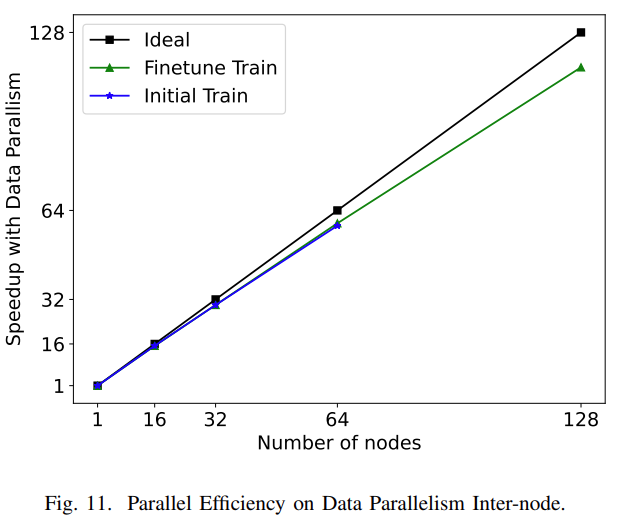
由于张量并行更多地依赖于设备之间的高速互连来进行通信,在训练期间,模型并行通常用于节点以及训练期间节点之间的数据并行。研究者分别在模型并行和数据并行两个级别测试了模型的训练性能,结果如图 10 和图 11 所示。在模型并行性方面,论文比较了张量并行和动态轴并行两种并行方法在初始训练和微调两种训练设置下的 scalability。
![]()
如图 10 所示,在初始训练和微调方面,DAP 的扩展性能明显优于 TP。
![]()
扩展结果如图 11 所示。我们可以看到,在接下来的几个平行里,基本上是线性规模的。微调训练的扩展效率达到 90.1% 。
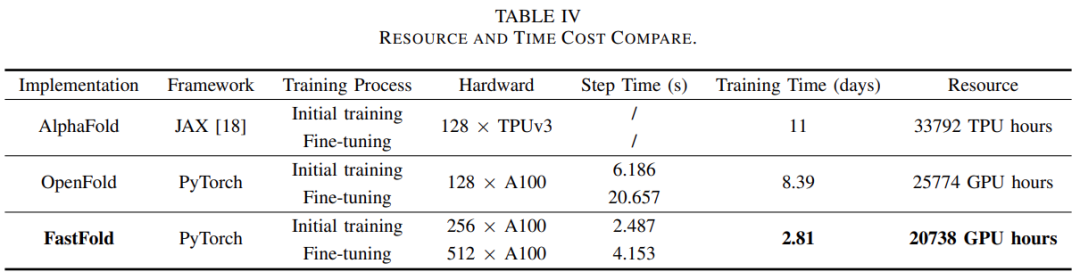
根据训练效果的评估结果,可以推算出 AlphaFold 的总体时间和经济成本。表 IV 列出并比较了 AlphaFold、 OpenFold 和 FastFold 三种实现的时间和经济成本。由于没有公开的训练代码,所以 AlphaFold 的数据来源于官方文件。
![]()
考虑到时间和经济成本,研究者选用了 256 个 A100 进行初始训练,然后在微调阶段扩展到 512 个 A100。
基于这种设置,FastFold 可以将训练时间减少到 2.81 天。
与需要 11 天训练的 AlphaFold 相比,训练的时间成本减少了 3.91 倍。与 OpenFold 相比,训练的时间成本降低了 2.98 倍,经济成本降低了 20% 。
在微调阶段,FastFold 在 512 × A100 的设置下实现了 6.02 PetaFLOPs 的计算速度。由于时间和经济成本的显著降低,FastFold 使得蛋白质结构预测模型的训练速度更快、成本更低,这将推动相关模型的研究和开发效率,并促进基于 Evoformer 的蛋白质结构预测模型的开发。
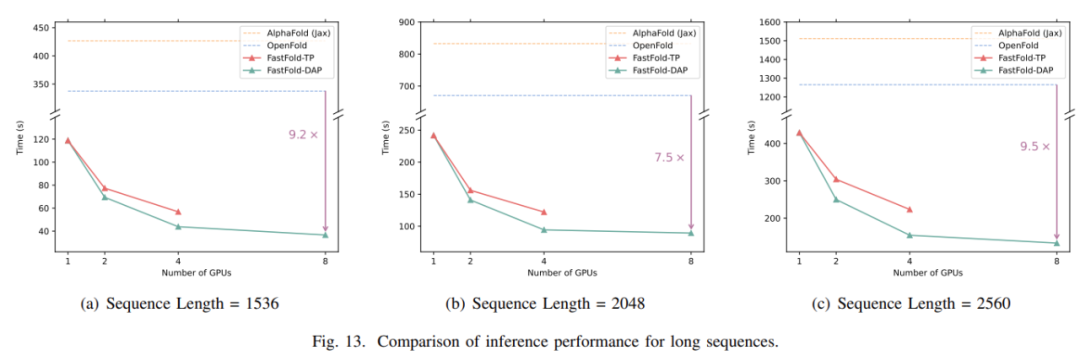
针对短序列、长序列和超长序列,研究者对比了 FastFold、OpenFold、AlphaFold 的推理性能。所有推理实验均在由 8 个 NVIDIA A100(带有 NVLink)组成的 GPU 服务器上完成。
对于短序列,典型的氨基酸序列长度不超过 1k,单个模型推理需要几秒钟到大约一分钟。在这个序列范围内,视频内存消耗相对较小,分布式推理的效率较低。
研究者在 1 个 GPU 上比较了三种实现的推理延迟,结果如图 12 所示:
![]()
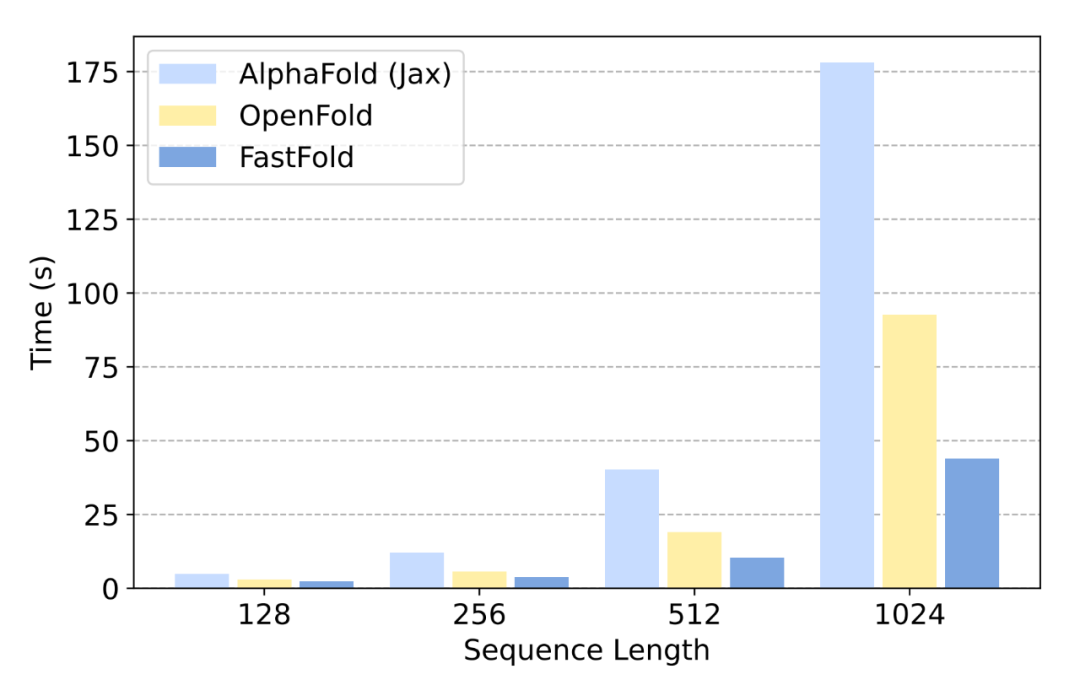
对于长度为 1k 到 2.5 k 的氨基酸序列的长序列推断,直接推理会遇到内存容量问题,推理时间达到几分钟甚至几十分钟。对于 FastFold,采用分布式推理方法可以减少内存容量的需求,显著缩短推理时间。如图 13 所示,当使用分布式推理时,FastFold 比 OpenFold 减少推理时间 7.5∼9.5 倍 ,比 AlphaFold 减少推理时间 9.3∼11.6 倍 。
![]()
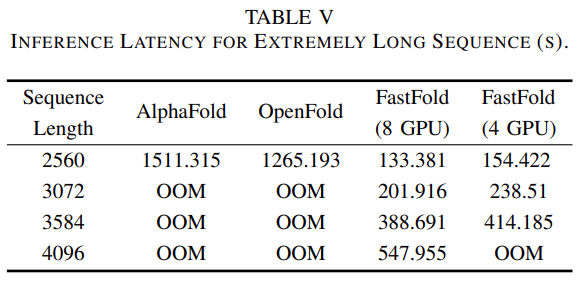
如表 3 所示,对于 AlphaFold 和 OpenFold,当序列长度达到 3k 之上时,都会遇到内存不足 (OOM) 问题。然而,对于 FastFold,由于分布式推理方法,它可以利用 GPU 更多的计算和内存来完成极长的序列推理。此外,对于长度高达 4k 的序列,FastFold 的推理延迟 在 10 分钟之内。
![]()
![]()
本文的作者之一尤洋现为新加坡国立大学计算机系任助理教授。2020 年,尤洋在加州大学伯克利分校计算机系获得博士学位。
尤洋的主要研究方向是高性能计算与机器学习的交叉领域,当前研究重点为大规模深度学习训练算法的分布式优化。他曾其以一作作者的身份发表研究论文《Large Batch Optimization for Deep Learning :Training BERT in 76 Minutes》,提出了一种 LAMB 优化器(Layer-wise Adaptive Moments optimizer for Batch training),将超大模型 BERT 的预训练时间由 3 天缩短到了 76 分钟,刷新世界记录。到目前为止,LAMB 仍为机器学习领域的主流优化器,成果被 Google、Facebook、腾讯等科技巨头在实际中使用。
2021 年 7 月,尤洋在北京中关村创办了高性能计算公司「潞晨科技」。不久后,潞晨科技即宣布完成超千万元种子轮融资,该公司创业目标是「最大化人工智能开发速度的同时,最小化人工智能模型部署成本」。
https://weibo.com/ttarticle/p/show?id=2309404742878697226261
时在中春,阳和方起——机器之心AI科技年会
机器之
心AI科技年会将于3月23日在北
京举办,在分享交流对人工智能的判断与思考外,更重要的是与读者、合作伙伴和好友们真实的见一面。
这是一次注重交流与见面的聚会,所以叫「年会」,没叫「大会」。
在这场年会上,有三个方向我们希望和大家分享:人工智能、AI for Science和智能汽车。
人工智能论坛关注高性能计算、联邦学习、系统机器学习、强化学习、CV与NLP发展、RISC-V等。
AI x Science论坛关注AI与蛋白质、生物计算、数学、物理、化学、新材料和神经科学等领域的交叉研究进展。
首席智行官大会关注智能汽车、汽车机器人、无人驾驶商业化、车规级芯片和无人物流等。
当然,按以往的惯例,我们还将邀请行业内最具代表性与专业的权威嘉宾带来他们的思考与判断。
欢迎大家点击「阅读原文」报名活动,「中春」见。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com