不如跳舞!伯克利的舞蹈动作迁移效果逆天
编者按:UC Berkeley近日发表了一篇论文,题目简洁明了:Everybody Dance Now,大家一起跳起来!没错,这个被网友称为“mad lab”的实验室提出了一种框架,把专业舞蹈演员的动作迁移到不会跳舞的人身上,不论是酷酷的街舞还是优雅的芭蕾,效果简直是神同步,流畅度和还原度都非常高。下面跟着论智一起看看这篇论文吧。
我们在这篇文章中提出了一个简单的方法进行动作迁移:首先选择一支单人跳舞视频作为源视频,几分钟后,在另一个目标视频上(完全不会跳舞的人)会呈现同样的动作。我们将这一问题看作是每一帧上图像到图像的转换,同时保证时间和空间的流畅。用动作探测器作为源视频和目标视频中间的表示,我们学习了一种从舞者动作画面到目标物体的映射,并且对这一设置进行调整,让它与视频完美融合,同时还加上了真实的人脸合成。
先放个视频感受一下这惊艳的效果,在后半部分的补充案例中,还展示了芭蕾舞的迁移。可以看到,原视频中芭蕾舞演员的大腿部分被裙子遮挡,但是映射到目标视频中,大腿动作也能正确呈现,效果满分!
简介
我们提出了一种方法,实现了动作在不同视频中的不同人物之间的转换。现在有两段视频,其中一段是我们希望进行合成的目标(不会跳舞的人),另一个是模仿的源视频(专业舞者)。我们通过基于像素的端到端通道实现了这一动作迁移。这一方法与过去二十年常见的最近邻搜索或3D中的重新制定目标动作不同。通过这一框架,我们让很多未经训练的人跳出了芭蕾和街舞。
为了实现两视频之间每帧的动作迁移,我们必须学习一种两个人物之间的映射。我们的目标是在源视频和目标视频之间进行图像到图像的转换。然而,我们没有两个目标物体做出同样动作的图片,也就无法直接对这一转换进行监督学习。即使视频中的两个人做出一系列同样的动作,还是很难提取每一帧的姿势,因为身体形状和风格完全不同。
我们发现,能体现身体各部分位置的关键点可以用作二者之间的表示。于是,我们设计了用来体现动作的“中间表示(火柴人)”,如图所示:

从目标视频中,我们用动作识别器为每一帧制作了(火柴人, 目标人物图像)的组合。有了这样相关的数据,我们就能用监督方法学习火柴人和目标人物之间图像到图像的转换模型了。于是,我们的模型通过训练,可以生成个性化的视频。之后,为了将源视频的动作迁移到目标视频中,我们把火柴人输入到经过训练的模型后,得到和源视频中人物相同的目标动作。另外,为了提高生成的质量,我们添加了两个元素。为了使生成的模型更流畅,我们都会根据上一帧对目前的帧进行预测。为了提高生成人脸的真实性,我们还加入了经过训练的GAN来生成目标人物的脸部。
具体方法
这一任务大致分为三步:动作检测、全局动作规范化和动作映射。训练和迁移过程如下图所示:
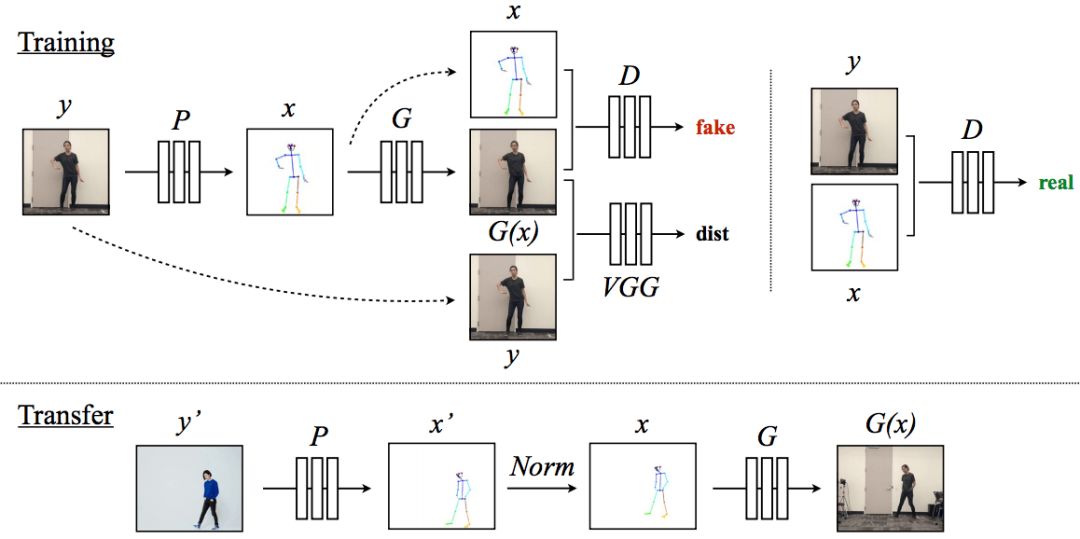
模型通过探测器P创造目标视频中人物所对应的火柴人。训练时,我们学习了映射G和一个对抗判别器D。D的作用是尝试判断火柴人和视频中的人是否符合。
下面一行是迁移过程。我们用动作探测器P:Y’→X’来获得源视频中的火柴人形象,这个火柴人形象通过归一化处理变成了为目标人物设计的火柴人。接着对其应用经过训练的映射G即可。
为了让效果更真实,我们还专门增加了生成对抗网络设置,让面部更真实,效果也显著提高。
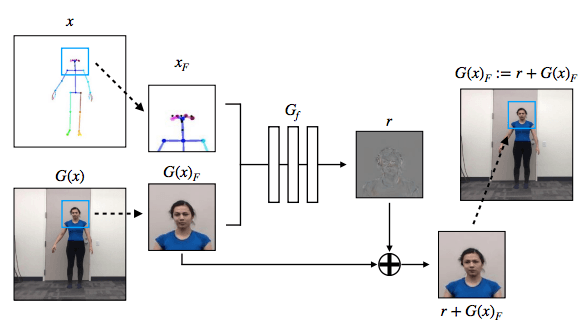
网络架构
为了提取身体、面部和手部的动作关键点,我们使用了最先进的动作检测器OpenPose。在图像转换阶段,我们使用了Wang等人提出的pix2pixHD模型。对于面部图像的生成,我们没有使用完全的pix2pixHD生成器,而是利用pix2pixHD的全局生成器。
实验对比
由于我们没有标准答案,为了对比两个不同视频中的目标人物,我们分析了目标人物的重建过程(也就是将源视频人物当做目标人物)。另外,为了评估每一帧的生成质量,我们测量了结构相似度(SSIM)和学习认知图像补丁相似性(LPIPS)。
除此之外,我们还在每个系统的输出上应用了动作检测器P,比较这些重建之后的关键点和原始的动作有何不同。


迁移结果。最上方的是源目标人物,中间是对应的“火柴人”,最下面一行是输出的目标人物动作
我们对比了标准pix2pixHD、只含有流畅度设置的我们模型版本(T.S.)以及我们模型的最终版本(有流畅设置和人脸GAN)。首先,三种模式下相似度的对比如图:


而在脸部区域,三种生成图像的质量对比:


可以看到,我们的完整版模型的分数是最好的。
讨论
看过这篇论文后,许多人只有一个反应:“Amazing!!”的确,效果这么好的视频生成技术未来可应用的场景有很多,比如电影拍摄、VR动画等等。但也有人表示担心,会不会像之前的deepfakes换脸一样,再产生一堆虚假视频?
不管怎样,炫酷的技术还是要学习下的,小编再次推荐观看上面的视频!
论文地址:arxiv.org/pdf/1808.07371.pdf



