CVPR 2019|已开源,预见未来!李飞飞等提出端到端系统Next预测未来路径与活动
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
本文授权转自机器之心,不得二次转载
作者:Junwei Liang、Li Fei-Fei 等
机器之心编辑部
破译视频中的人类行为以预测其未来路径/轨迹及活动在许多应用中都非常重要。为此,李飞飞等研究者提出了一种端到端的多任务学习系统,联合预测行人的未来路径及活动。实验表明,该方法在两个公开基准上达到了未来轨迹预测的当前最佳性能,还可以产生有意义的未来活动预测。
随着深度学习的发展,现在的系统能够从视频中分析出丰富的视觉信息,促进道路事故回避、智能个人助理等应用的实现。其中一个重要的分析是预测行人的未来路径,即未来行为路径/轨迹预测,这个问题在计算机视觉社区中广受关注。它是视频理解中的必要一环,因为查看之前的视觉信息来预测未来在很多应用中都是有用的,如自动驾驶汽车、社交感知机器人等。

图 1:研究目标是联合预测行人的未来路径和活动。绿线和黄线表示两种可能轨迹和可能活动。根据未来活动,行人(右上角)可能走不同的路径,如黄色路径「装载」(loading)和绿色路径「物品传递」(object transfer)。
人类在公共空间中行走通常是有特定目的的,包括进入房间这样的简单目的和将东西放入汽车这样的复杂目的。但是,此类人类意图在大多数现有研究中是被忽视的。考虑图 1 的示例,行人(右上角)可能因意图不同而选择不同的路径,如走绿色路径将东西给另一个人,或者走黄色路径将东西装到车里。本论文受此启发,着眼于利用视频中的此类行人意图联合建模未来路径。研究者按照包含 30 种活动的预定义集合来建模意图,这些活动由 NIST 提供,包括「装载」、「物品传递」等,完整列表详见表 4。
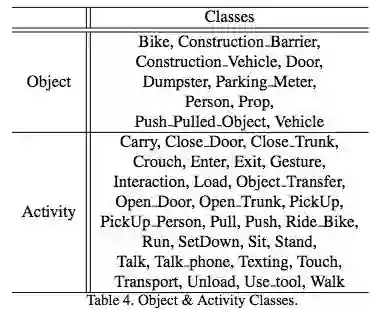
表 4:对象和活动类别。
该联合预测模型具备两大优势。一,同时学习活动和路径有助于未来路径预测。直观上,人类能够通过阅读其他人的肢体语言来预期他们是要过马路还是继续沿人行道走。在理解这些行为后,人类可以作出更好的预测。如图 1 示例,右上行人搬着一个箱子,左下的人在向他挥手。基于常识,我们可能会认为右上行人会选择绿色路径。二,该联合模型不仅提升了对未来路径的理解,还促进了对未来活动的理解,因其考虑了视频中的丰富语义语境。这提升了自动视频分析在公益应用中的能力,如实时事故提醒、自动驾驶汽车和智能机器人助理。它还可用于一些安全应用,如预测十字路口的行人移动或让道路机器人帮助人类将物品运送装载到汽车后备箱。注意,该技术聚焦于预测未来几秒内的活动和路径,不适用于非常规活动。
研究者提出了一个多任务学习模型 Next,它具备一个预测模块,可同时学习未来路径和未来活动。由于预测未来活动很难,研究者引入了两项新技术。一,与大部分现有研究将行人过度简化为空间中一个点不同,该研究通过丰富的语义特征来编码行人,如视觉外观、身体活动和与周围环境的交互。二,为了促进训练,研究者引入了两个辅助任务用于未来活动预测:活动标签分类和活动位置预测。在后一个任务中,研究者设计了名为 Manhattan Grid 的离散网格(discretized grid),作为系统的位置预测目标。实验表明这些辅助任务可改善未来路径预测的准确率。
该研究是首个在流视频中进行联合路径和活动预测的研究,且首次展示了此类联合建模可以显著改进未来路径预测。研究者在两个基准(ETH & UCY [22, 15] 和 ActEV/VIRAT [21, 3])上对该模型进行了验证。实验结果表明,该方法优于当前最优的基线模型,在两个常见基准上达到了已发布研究的最佳结果,且可生成对未来活动的额外预测。总之,该研究有三项贡献:1)对在视频中执行未来路径和活动联合预测进行了探索性研究,并首次展示了联合学习的优势;2)提出了一个多任务学习框架,引入了新技术来解决未来路径和活动联合预测的难题;3)提出的模型在两个公开基准上达到了已发布研究的最佳性能。研究者还进行了模型简化测试,验证该研究所提出子模块的贡献。
网络架构
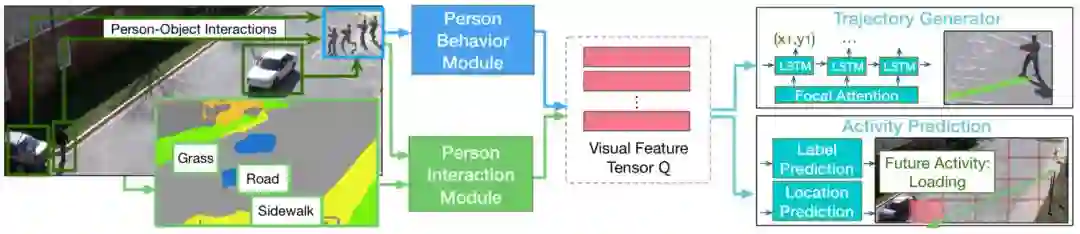
图 2:模型架构概览。给定行人的行为视频帧序列,该研究提出的模型可以利用行人行为模块和行人交互模块编码丰富的视觉语义信息形成特征张量。该研究提出了全新的行人交互模块,可以同时考虑行人-场景和行人-对象关系,对人的活动和位置进行联合预测。
图 2 展示了 Next 模型的整体网络架构。多数现有研究将空间中的人简化为一个点,但本文中的模型利用两个模块编码与每个人的行为及其与环境交互相关的丰富视觉信息。该模型主要组成部分如下所示:
行人行为模块:从行人的行为序列中提取视觉信息。
行人交互模块:着眼于人与周围环境的交互。
轨迹生成器:借助带有焦点注意力(focal attention)的 LSTM 解码器对编码后的视觉特征进行总结,并预测未来轨迹。
活动预测:利用丰富的视觉信息预测行人的未来活动标签。除此之外,研究者还将场景分成多种尺寸的离散网格(其命名为 Manhattan Grid),以计算分类和回归,实现稳健的活动位置预测。
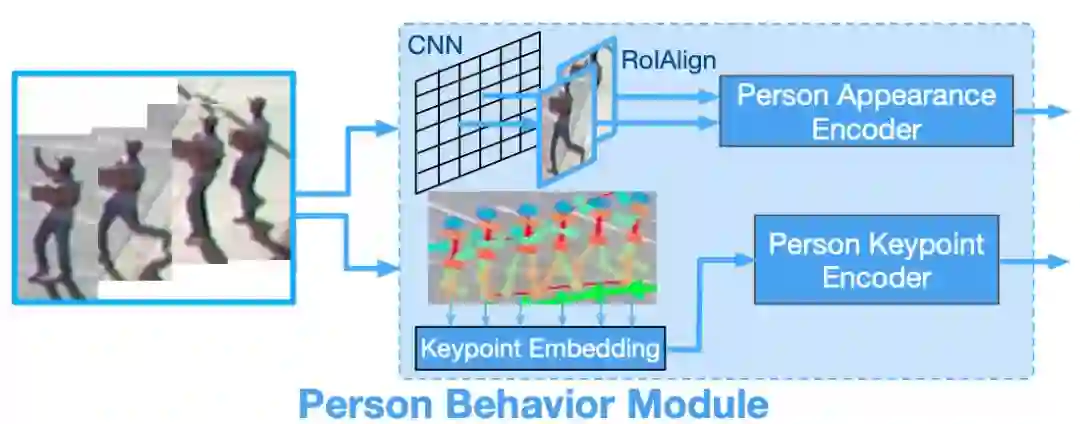
图 3:给定一系列行人帧(左),图中展示了对应的行人行为模块。研究者提取了人的外观和姿势特征来建模行人的行为变化。
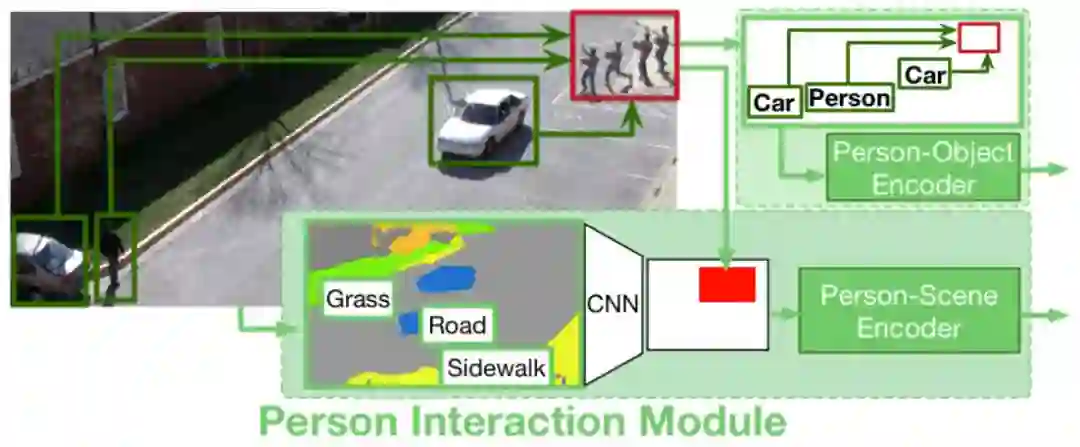
图 4:图中展示了行人交互模块,包含行人-场景建模和行人-对象建模。对于行人-对象建模,给定行人视频帧序列(如红色框所示),研究者提取了每个时间点人与其他对象之间的空间关系。对于行人-场景建模,研究者将人周围的场景语义特征汇集到编码器中。
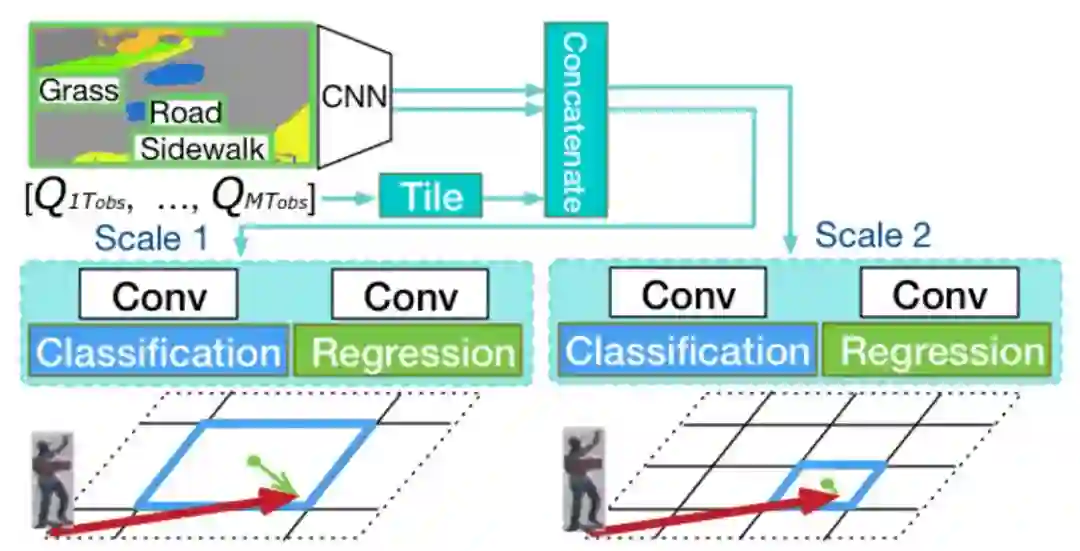
图 5:在多尺度 Manhattan 网格上通过分类与回归进行活动位置预测。
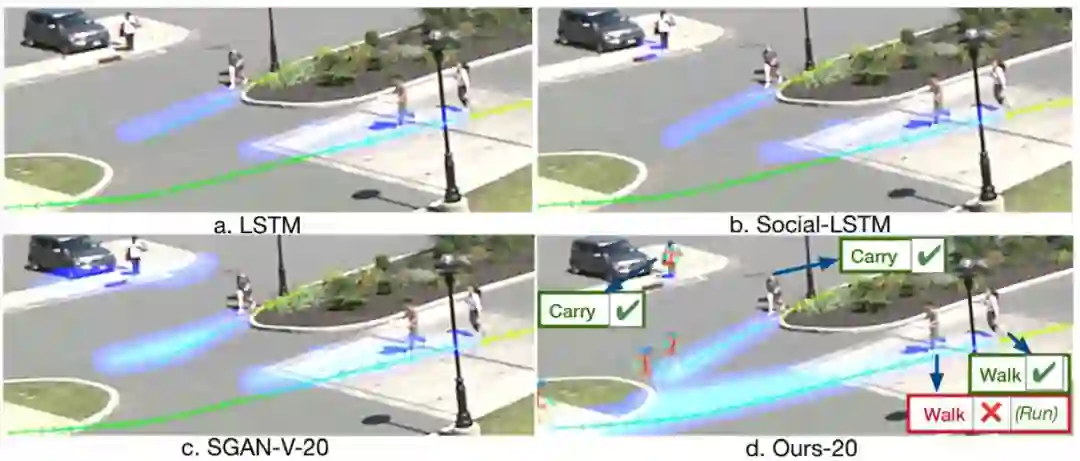
图 6:该研究提出方法与基线模型之间的对比。黄色线路是观察到的轨迹,绿色线路是预测阶段的真值轨迹。蓝色热图是预测结果。该研究提出的模型还预测了未来活动(在图中通过文本形式展示)与人体姿态模板(person pose template)。
论文:Peeking into the Future: Predicting Future Person Activities and Locations in Videos

论文链接:https://arxiv.org/abs/1902.03748
GitHub链接:https://github.com/google/next-prediction
B站视频链接:https://www.bilibili.com/video/av46267583/
摘要:破译视频中的人类行为以预测其未来路径/轨迹以及接下来的举动在许多应用中都非常重要。受此想法启发,本论文主要研究联合预测行人的未来路径及活动。我们提出了一种端到端的多任务学习系统,该系统利用人类行为信息及其与环境交互的丰富视觉特征。为了便于训练,我们引入了两项辅助任务,一是预测未来活动,二是预测活动将要发生的位置。实验结果显示,我们的方法在两个公开基准上达到了未来轨迹预测的当前最佳性能。另外,除了路径以外,我们的方法还可以产生有意义的未来活动预测。该结果提供了首个实验证据,证明对路径和活动进行联合建模有助于未来路径预测。
-完-
*延伸阅读
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台
觉得有用麻烦给个在看啦~




