医疗领域福音:不必共享数据,迁移权重也能训练出好模型
编者按:数据包含重要的隐私,尤其是医疗数据。但在训练用于医疗的神经网络时,数据又是不可或缺的。为了解决数据共享带来的隐私破坏问题,斯坦福大学的研究人员提出了一种分布式深度学习网络,为不同机构间的合作提供了新思路。

随着强大的图形处理单元的进步,深度学习在主流任务中取得了很大突破,例如图像分类、语音识别和自然语言处理。由于神经网络能高效处理形状识别,深度学习也在临床医疗诊断领域给与了一定支持。最近的研究表明,深度学习在检测糖尿病视网膜病变、分辨皮肤病变、预测神经胶质瘤变异以及评估医疗记录等方面都有很大潜力。深度学习模型可以输入原始数据,然后经过多层转换,计算出分类标签。这些转换通常有多个维度,也使得算法学习更多复杂的表示。
在医疗领域,想应用深度学习,主要问题就是大量的训练数据,尤其是当图像之间的差别很细微,或者研究群体之间的差异性很大的时候,数据就更需要多样化了。然而,来自病人的样本数量通常很少,罕见病就更少了。样本规模小,可能会导致神经网络模型的泛化能力降低。
针对上述问题,一种可能的解决方法就是进行多中心研究(multicenter study),这种方法可以增加样本规模,同时丰富样本多样性。理想情况下,病人的数据在研究中心是共享的,算法能利用这些数据训练。但是,这种方法有几个问题。首先,如果病人的数据需要很大的存储空间(例如高分辨率的图像),要想分享这些数据就很麻烦了。其次,共享病人的数据还面临着法律和道德的障碍,想要大规模传播数据似乎不太可能。另外,病人的数据非常珍贵,很多机构可能根本不想贡献出去。
在这种情况下,与其直接分享病人数据,我们想到了更吸引人的方法,即对训练过的深度学习模型进行分散。模型本身对存储空间的需求比病人数据低得多,并且不需要存储与病人有关的各类信息。因此,在多个机构间的分布式深度学习模型可以克服分散的病人数据带来的弱点。不过,据我们了解,能执行这一任务的方法目前还没有人研究过。
关于分布式训练,目前有好几种方法。对模型取平均值指的是,分离的模型在不同的数据上进行训练,模型每隔几个mini-batches就会计算一次平均权重。在非同步的随机梯度下降上,分离的模型在分离的数据上训练,而每隔分离模型的梯度就会转移到中心模型上。然而,这些方法都是为了优化训练速度而提出的。虽然在多个机构间,对这些数据进行平行训练是可能做到的,但同样会出现重要的逻辑挑战。如果各个机构减的网络连接速度不同,或者有不同的深度学习硬件,就会有挑战性。虽然非平行的分布式训练方法会比平行式的要慢,但可以避免这些逻辑上的问题。
在这篇论文中,我们利用多种非平行的训练方法,模拟了在各机构间分布的深度学习模型。我们比较了在中心数据上训练过的深度学习模型结果。我们在三个数据集上对这一模拟结果做出展示:视网膜眼底照片、乳房X光片和ImageNet。主要评估的目的有三点:
分布式深度学习模型的性能与共享病人数据有何不同;
当向某个机构发生变化时,分布式深度学习模型的性能会不会衰减;
当机构数量越来越大,分布式深度学习模型的性能会不会更好。
我们的方法
收集图像
我们从Kaggle的糖尿病视网膜病变的挑战赛中获得了35126张彩色数字化的视网膜眼底照片,它们的质量、像素各不相同。我们用挑战赛冠军Ben Graham的方法对其进行了处理,尺寸改为256×256,打上表示病情严重程度的标签。
我们的网络架构是一个34层的残差网络,如图1所示:
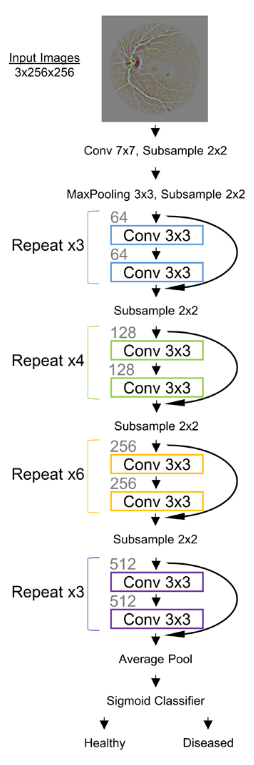
图1
网络在NVIDIA Tesla P100的图形处理单元上运行。网络的权重通过一个随机梯度下降算法进行优化,mini-batch的尺寸为32。
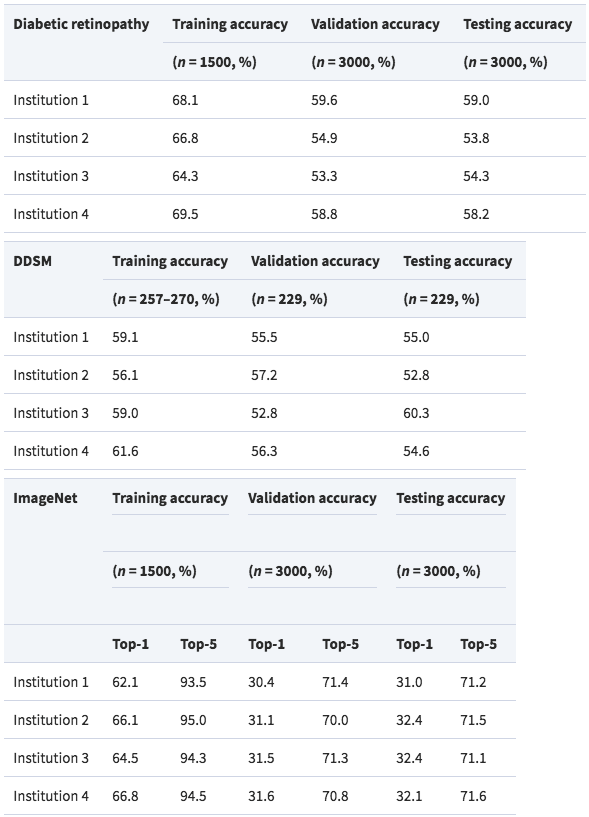
数据集是随机采集的,来自四个不同的医疗结构,每个机构有n=1500名病人,类别分布的数量相同。

图2
我们在多个不同的训练方法上进行了测试,并比较了结果。第一种方法是让神经网络在每个机构上单独训练,假设没有其他机构与之合作。第二种方法是通过将所有病人的数据共享(图3A)。第三种方法是先将模型在各个机构上单独训练,然后计算输出结果的平均值(图3B)。第四种方法是将一个模型在单一机构的数据上训练,直到达到验证损失不再下降,然后再训练下一个机构(单一权重转移,图3C)。除此之外,还有一种方法是让一个模型在每个机构上训练一定次数之后在转移到下一个机构上(循环权重转移,图3D)。
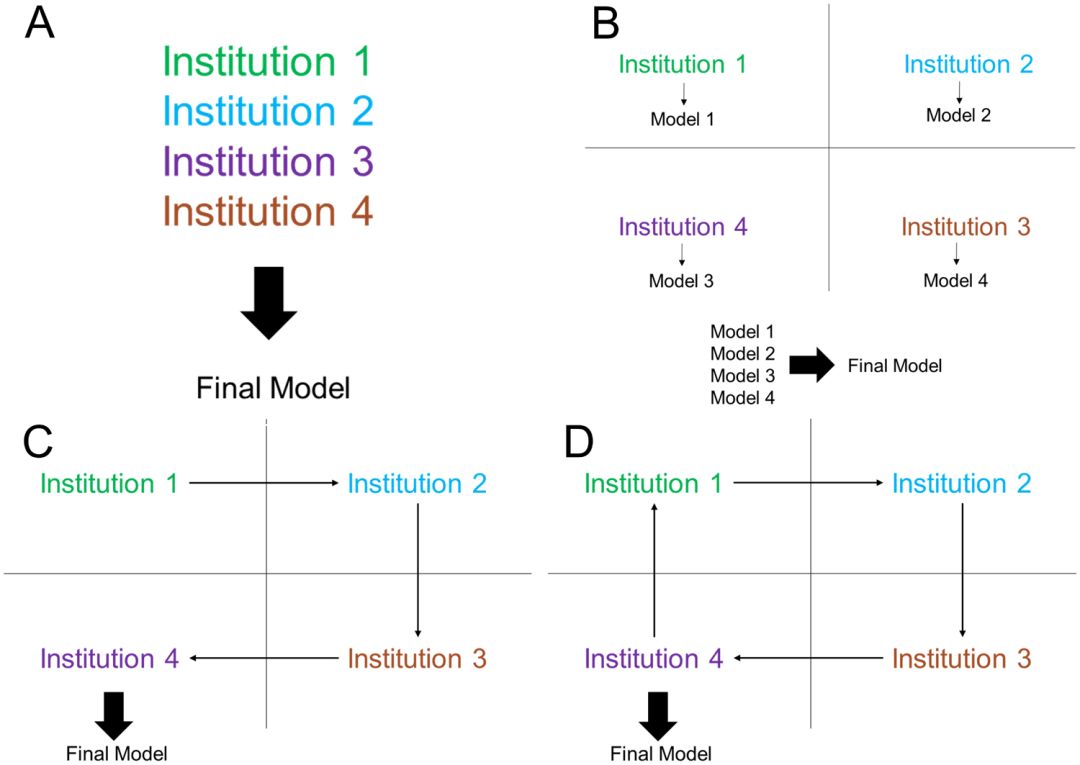
图3
实验结果
首先是模型在单一的机构上的视网膜眼底数据集训练结果,表现的性能很不好,平均测试精度只有56.3%
其次,在中心共享数据集上训练后,网络的性能有所提升,测试精度达到了78.7%
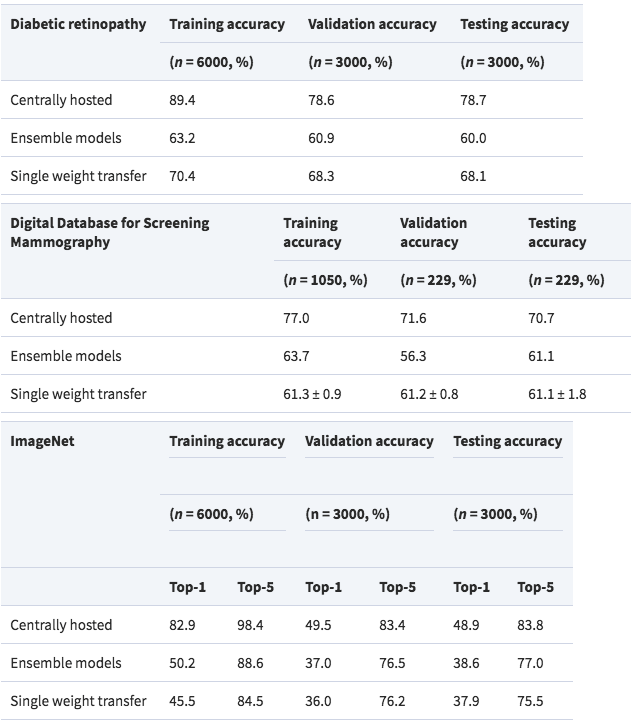
平均法下,模型的测试精度为60%,单一权重转移下的精度为68.1%,循环权重转移的精度为76.1%。
结论
在这项研究中,我们解决了如何在不共享病人数据的情况下训练深度学习模型的方法。最终发现,循环权重转移方法和共享数据的方法结果差不多,说明共享病人数据并非是创建模型的唯一方法。这项发现对合作型的深度学习研究大有帮助。
论文地址:academic.oup.com/jamia/article/25/8/945/4956468#.W1dylyjBflQ.twitter




