26秒训练ResNet,用这些技巧一步步压缩时间,Jeff Dean都称赞:干得漂亮
鱼羊 乾明 发自 凹非寺
量子位 报道 | 公众号 QbitAI
更快的训练速度,更少的算力消耗,对于炼丹师们而言,这无疑是飞一般的体验。
现在,谷歌AI掌门人Jeff Dean转发推荐了一个训练ResNet的奇技淫巧大礼包,跟着它一步一步实施,训练9层ResNet时,不仅不需要增加GPU的数量,甚至只需要1/8的GPU,就能让训练速度加快到原来的2.5倍,模型在CIFAR10上还能达到94%的准确率。
甚至只需要26秒,就能训练好一个模型。
这一”大礼包“由myrtle.ai开源。Jeff Dean称赞道:
真是减少CIFAR10图像模型训练时间的好文章。其中许多技巧都可能适用于其他不同类型的模型。干得漂亮。
奇技淫巧大礼包
myrtle.ai的奇技淫巧,都可以在Colab上测试,只需配置一个V100。(链接见文末)
话不多说,快来看看都是哪些神奇的技巧,造就飞一般的感觉。
基线方法消耗的总时间是75s。
GPU上的预处理(70s)
第一个技巧是,将数据传输到GPU,在GPU上进行预处理,然后再传回CPU进行随机数据扩增和批处理。
将整个数据集(unit8格式)移至GPU仅需要40ms,几乎可以忽略不计,而在GPU上完成预处理步骤花费的时间则更少,大概只需要15ms。
这种做法下大部分的时间是消耗在数据集回传CPU上,这需要将近500ms的时间。
往常的数据预处理方法会花费掉3s以上的时间,相比之下,这样的处理方式已经把速度加快了不少。
不过,还可以更快。
那就是,不回传CPU,直接在GPU上把数据扩增这一步也做了。
当然,蛮干是不行的。为了避免启动多个GPU内核导致花销变大,可以对样本组应用相同的扩增,并通过预先对数据进行混洗的方式来保持随机性。
具体的做法是这样的:
以8×8的cutout为例,即对CIFAR10图像做8×8的随机块状遮挡。
在32×32的图像中有625个可能的8×8剪切区域,因此通过混洗数据集,将其分成625个组,每个组代表一个剪切区域,即可实现随机扩增。
事实上,选择大小均匀的组,与为每个样本进行随机选择并不完全相同,但也很接近。不过为了进一步优化,如果应用同一种扩增的组的数量太大,可以对其设置一个合理的限制范围。

如此一来,迭代24个epoch,并对其进行随机裁减、水平翻转、cutout数据扩增,以及数据混洗和批处理,只需要不到400ms。
还有一个好处是,CPU预处理队列和GPU不用再相互赛跑,这样就不必再担心数据加载的问题了。
需要注意的是,这样操作的前提是数据集足够小,可以在GPU内存中作为一个整体进行存储和操作。但Nvidia DALI这样的工业强度解决方案或许可以实现进一步的突破。
移动最大池化层(64s)
最大池化和ReLU的顺序是可以交换的。经典的卷积池化是这样:

可以把它调整成这样:

切换顺序将使24个epoch的训练时间进一步减少3秒,而网络功能完全没有变化。
甚至还可以进一步把池化提前:

这能进一步使训练时间缩短5秒,但会导致网络的改变。不过实验表明,这样做对测试精度的负面影响很小,基线是94.1%,池化前移后会准确率会降到94.0%(50次运算的平均值),仅有0.1%的精度损失。
标签平滑(59s)
标签平滑是提高分类问题中神经网络训练速度和泛化的一个成熟技巧。
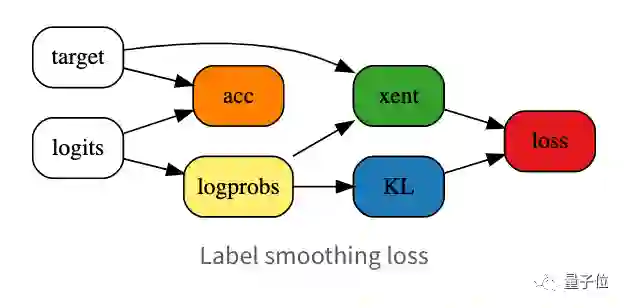
应用标签平滑之后,测试精度能提高到94.2%(50次运算的平均值),这样一来,就可以通过减少epoch的数量来换取训练速度的提升。
CELU激活(52s)
平滑的激活函数对于优化过程也很有帮助。
因此可以选择连续可微分指数线性单元或者CELU激活,来替代ReLU。
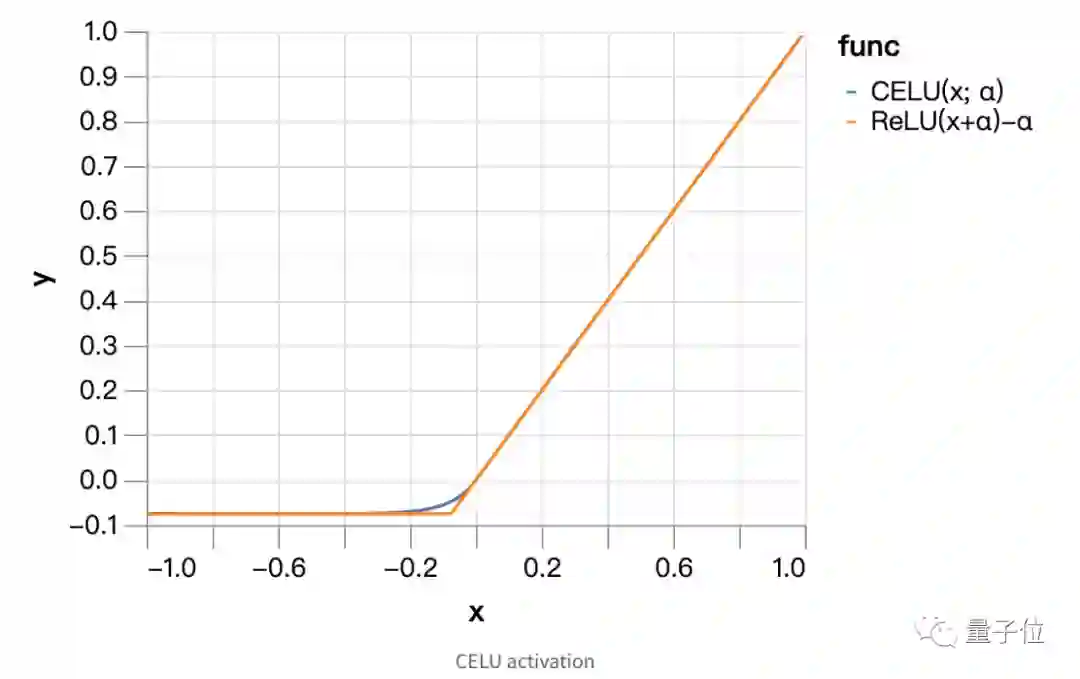
当平滑参数α为0.075的时候,测试精度能达到94.3%,于是,与标签平滑相比,又可以进一步减少epoch,速度也就从59s缩短到了52s。
Ghost批量归一(46s)
批量归一最合适的批量大小大概在32左右。
但在批量大小比较大的时候,比如512,降低其大小会严重影响训练时间。不过这一问题可以通过对batch的子集分别进行批量归一来解决,这种方法称为“ghost”批量归一。
固定批量归一规模(43s)
批量归一规范了每个通道的均值和方差,但这取决于可学习的规模和偏差。
如果通道规模发生很大的变化,就可能会减少通道的有效数量而造成瓶颈。
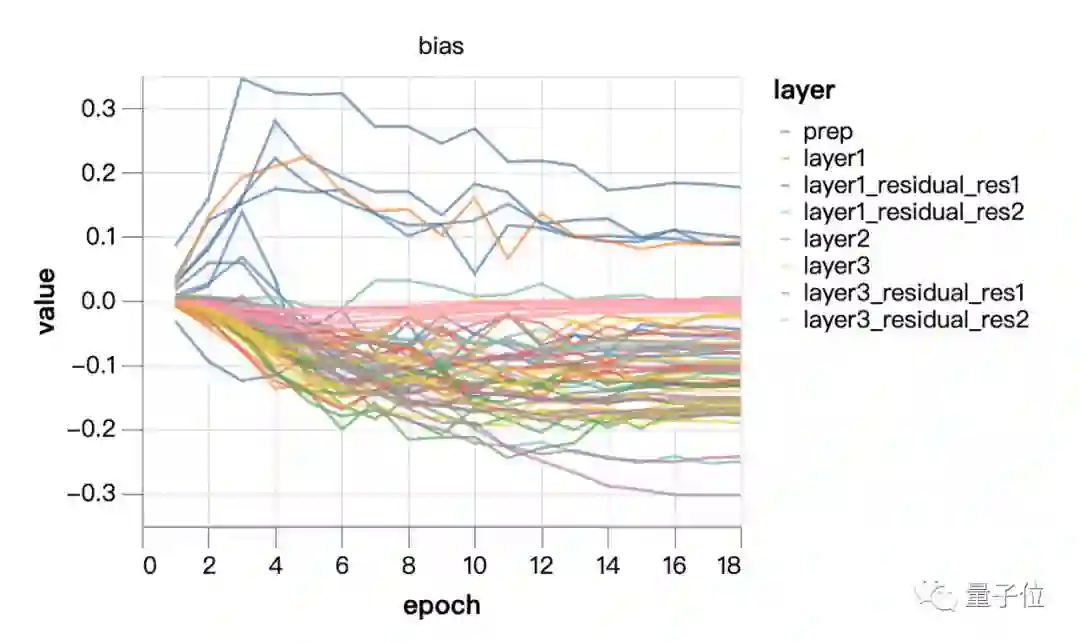
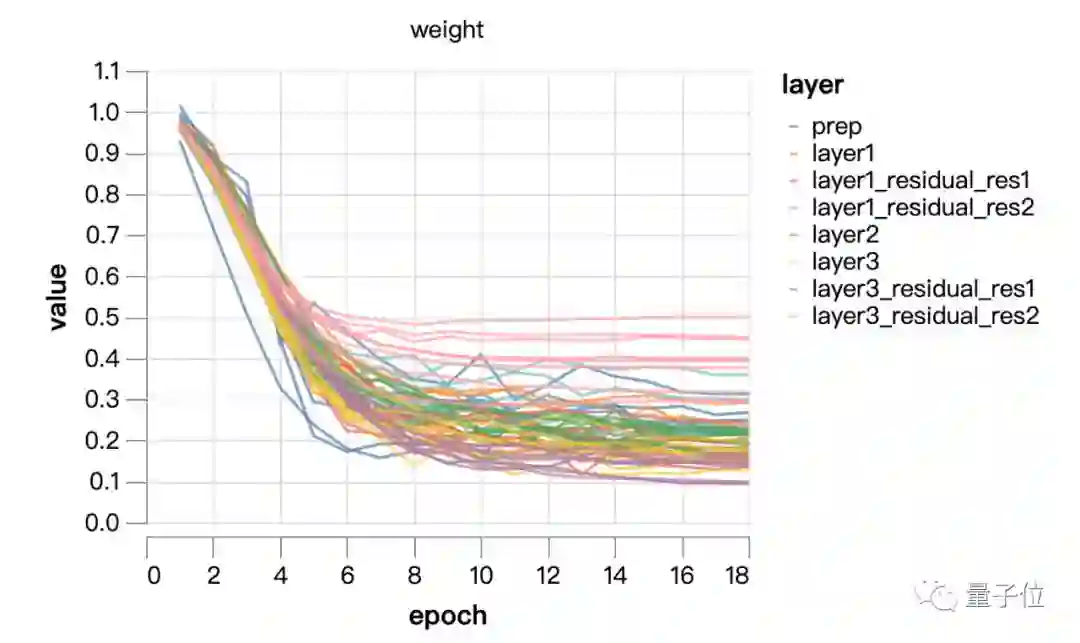
从上面这两张图中可以看出,规模并没有进行太多学习,主要是在权重衰减的控制下进化。尝试将规模固定在1/4的恒定值(训练中点的平均值)。最后一层的可学习比例稍大,这可以通过调整网络输出的比例来进行补偿。
实际上,如果将CELU的α参数重新调整为补偿因子4,批量归一偏差的学习率和权重衰减分别为4^2和(1/4)^2,则批量归一规模就为1。
需要说明的是,如果不提高批量归一偏差的学习率,最终的准确率会非常低。
至此,在DAWNBench排行榜上,这一单GPU训练出来的ResNet9训练速度已经能超越8个GPU训练出来的BaiduNet9了。
输入块(patch)白化(36s)
批量归一可以很好地控制各个通道呃分布,但不能解决通道和像素之间协方差的问题。所以,要引入“白化”版本来控制内部层的协方差。
myrtle.ai提出了一种基于patch的方法,该方法与总图像的尺寸无关,并且更符合卷积网络的结构。
将PCA白化应用于3×3的输入块,作为具有固定(不可学习)权重的初始3×3卷积。这可以通过可学习的1×1卷积来实现。该层的27个输入通道是原始的3×3×3输入块的变形,其协方差矩阵近于恒等式(identity),更易于优化。
首先,绘制输入数据的3×3块的协方差矩阵的前导特征向量。括号中的数字是相应特征值的平方根,以显示沿这些方向的相对变化尺度,并绘制具有两个符号的特征向量以说明变化的方向。
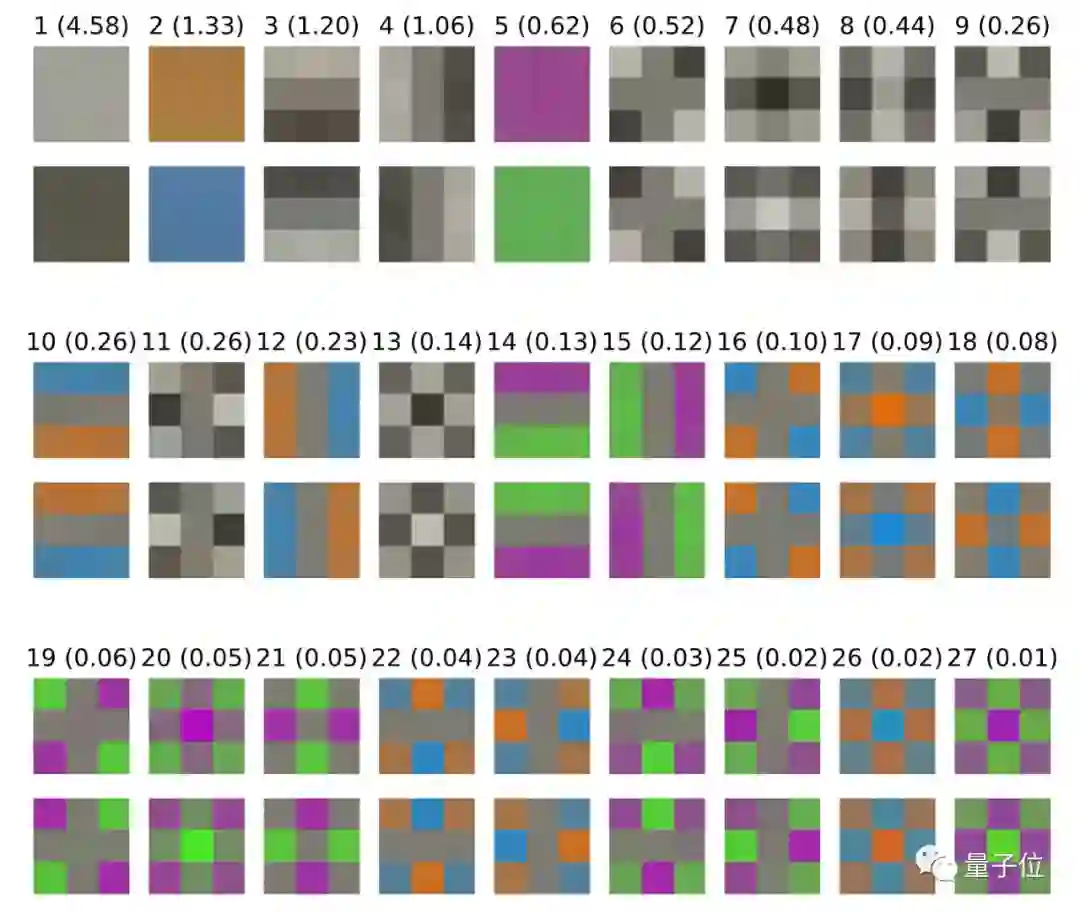
可以看出,局部亮度的变化占据主导地位。
接下来,用固定的3×3白化卷积替换网络的第一个3×3卷积,以均衡本征块的比例,而后用可学习的1×1卷积,并查看其对训练的影响。
如果将最大学习率提高50%,并把剪切扩增的总量从8×8降至5×5,以补偿更高的学习率带来的额外正则化,就可以在36s内让模型达到94.1的测试精度。
指数移动平均(34s)
高学习率,是快速训练的必要条件,因为它允许随机梯度下降在有限的时间内在参数空间中通过必要的距离。
另一方面,学习速率需要在训练结束时进行退火,以便在参数空间中沿着更陡峭和更嘈杂的方向进行优化。
参数平均方法允许以更快的速度继续训练,同时通过多次迭代进行平均,可以沿着有噪声或振荡的方向接近最小值。
myrtle.ai发现,更频繁的更新并不能改善情况,出于效率的原因,就每5个batch更新一次移动平均。
他们说,这需要选择一个新的学习率计划,在训练接近尾声时提高学习率,并为移动平均提供动力。
对于学习速率,一个简单的选择就是坚持他们一直使用的分段线性时间表,在最后两个epoch以一个较低的固定值表示,他们选择的是一个0.99的动量,这样平均就可以在大约上一个时期的时间尺度上进行。
测试精度提高到94.3%,也意味着可以进一步削减epoch。
最后的结果是:13个epoch训练达到94.1%的测试精度,训练时间低于34秒,比这一系列开始的时候单GPU表现提高了10倍!
测试状态增强(26秒)
如果你想让你的网络在输入的水平翻转下,也能以相同的方式对图像进行分类。
一种方法是向网络提供大量的数据,通过保存左右翻转的标签来增强数据,然后希望网络最终通过广泛的训练来学习不变性。
第二种方法,是同时呈现输入图像和水平翻转后的图像,并通过对两个版本的网络输出进行平均来达成一致,从而保证不变性。
这种非常明智的方法被称为测试状态增强(Test-time augmentation,TTA)。

在训练时,myrtle.ai仍然向网络呈现每个图像的单一版本——可能会进行随机翻转来增强数据,以便在不同的训练阶段呈现不同的版本。
他们采取的另一个做法是,在训练时使用与测试时相同的程序,并将每个图像及其镜像显示出来。
在这种情况下,myrtle.ai可以通过将网络分成两个相同的分支来改变网络,其中一个分支可以看到翻转后的图像,然后在最后合并。
通过这一视角,原始训练可以被看作是一个权重绑定的随机训练过程,即两个分支网络,其中每个训练示例都有一个分支被”dropped-out“。
这种dropout-训练的观点清楚地表明,任何试图引入禁止测试状态增强从基准中删除的规则都将充满困难。
从这个角度看,myrtle.ai刚刚介绍了一个更大的网络,他们有一个有效的随机训练方法。
另一方面,如果myrtle.ai不限制准备在测试时做的工作量,那么就会出现一些明显的退化解决方案,其中训练所需的时间与存储数据集所需的时间一样少!
这些参数不仅与人工基准测试相关,而且与最终的用例有关。在一些应用程序中,对分类精度有所要求,在这种情况下,绝对应该使用测试状态增强。
在其他情况下,推断时间也是一种约束,明智的做法是在这种约束下,将精度最大化。这可能也是一个训练基准测试的好方法。
在目前的案例中,Kakao Brain团队应用了这里描述的测试状态增强的简单形式——在推断时呈现图像及其左右镜像,从而使计算量加倍。
当然,对于其他对称(如平移对称、亮度/颜色的变化等)来说,测试状态增强的应用也会更广泛,但这将付出更高的计算成本。
现在,由于目前是基于一个计算量较少的9层ResNet,因此包括测试状态增强在内的总推断时间,可能比100多个层网络中要短得多。
根据上面的讨论,任何限制这种方法的合理规则,都应该基于推断时间约束,而不是实现的功能,因此从这个角度来看,myrtle.ai团队说,应该接受这种方法。
为了与当前DAWNBench提交数值的一致,他们将限制自己使用水平翻转测试状态增强,因为这似乎是准确性和推断成本之间的最优平衡点。
最后的结果是:在现有的网络和13个epoch训练设置下,测试状态增强的精度提高到94.6%。
如果移除了对剩余数据的增强操作,可以将训练减少到 10 个 epoch,而且能在26 秒实现测试状态增强精度——94.1%。
训练效果
单块GPU就能有这么快的速度,效果又如何呢?myrtle.ai团队还用了ImageNet来验证。
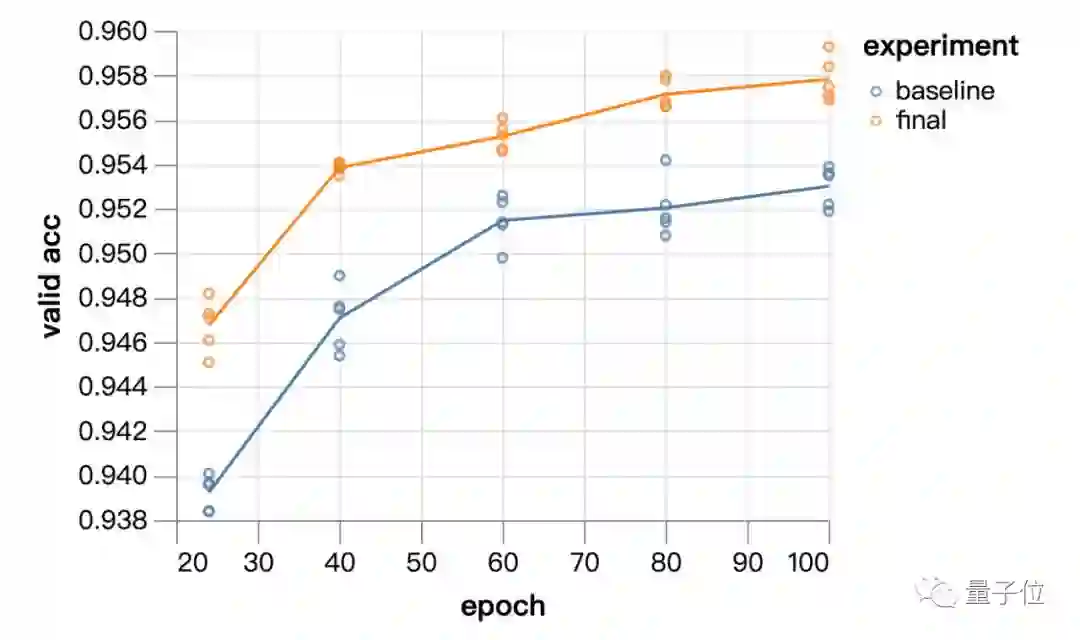
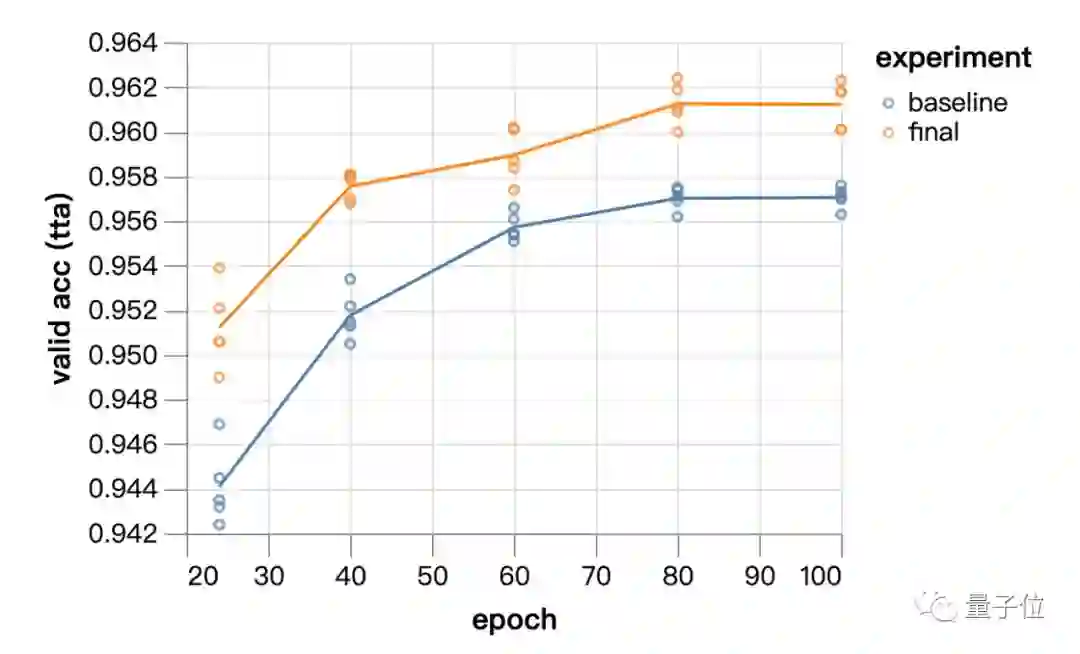
从24个epoch到100个epoch,实验模型的表现始终优于基线方法。
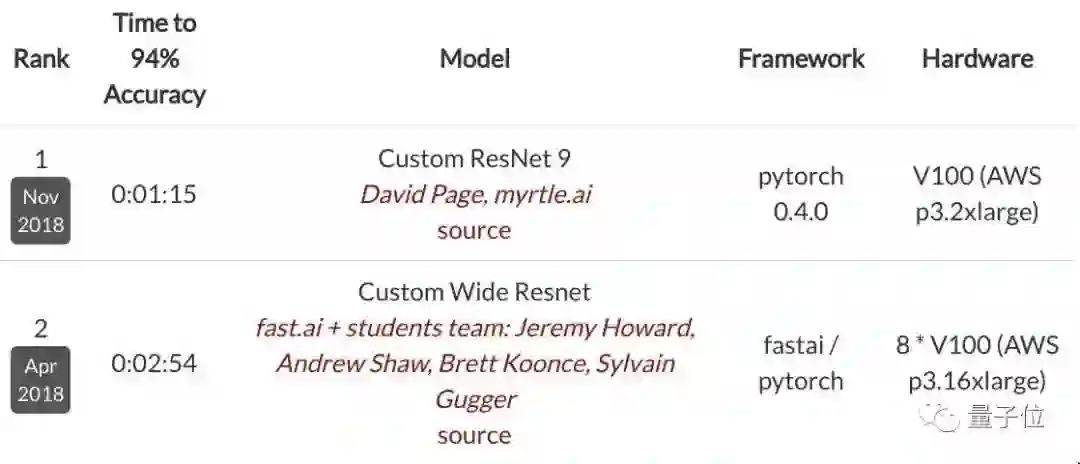
用上了奇技淫巧大礼包的9层ResNet其实去年11月就登上了DAWNBench CIFAR10排行榜的榜首,速度提高近2.5倍,而GPU从8个降到了1个。
DAWNBench是斯坦福大学提出的基准,在这一排行榜中,准确度只要达到94%即可。
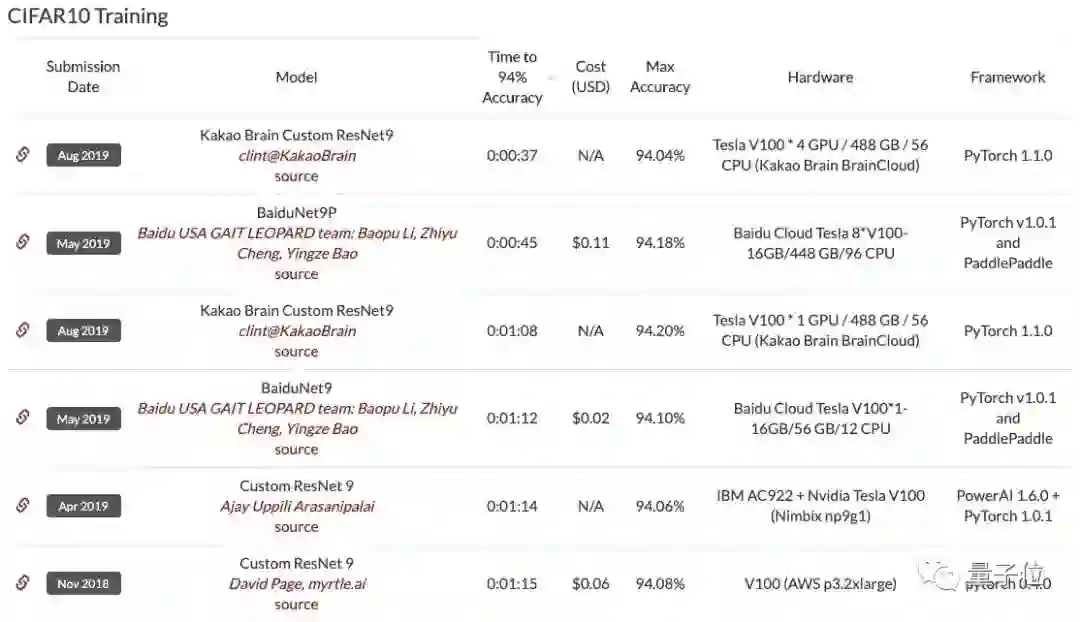
现在,虽然这一登顶成绩已经滑落到了第六位,但myrtle.ai表示在使用了与榜首Kakao Brain相同的TTA方法之后,实验模型的训练速度能降至26秒,超过Kakao Brain近10秒。
传送门
博客地址:
https://myrtle.ai/how-to-train-your-resnet-8-bag-of-tricks/
Colab地址:
https://colab.research.google.com/github/davidcpage/cifar10-fast/blob/master/bag_of_tricks.ipynb#scrollTo=n___bs94Rvm2
GitHub地址:
https://github.com/davidcpage/cifar10-fast/blob/master/bag_of_tricks.ipynb
作者系网易新闻·网易号“各有态度”签约作者
— 完 —
活动推荐 | AI计算盛会限时免费报名
2019人工智能计算大会将于8月27日-28日在北京举办,通过量子位特邀渠道,即可获得原票价1099的限时免费报名通道。识别下图二维码即可报名。


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「好看」吧 !



