南洋理工提出全场景图生成PSG任务,像素级定位物体,还得预测56种关系
![]()
新智元报道

新智元报道
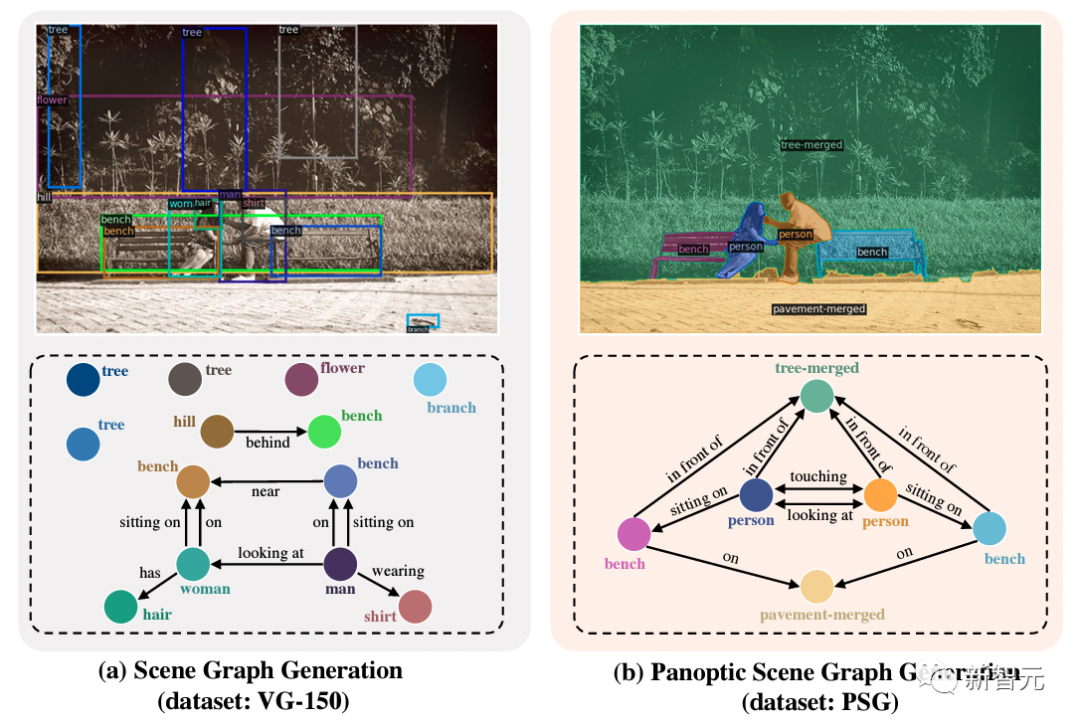
【新智元导读】本文提出基于全景分割的全场景图生成(panoptic scene graph generation,即PSG)任务。相比于传统基于检测框的场景图生成,PSG任务要求全面地输出图像中的所有关系(包括物体与物体间关系,物体与背景间关系,背景与背景间关系),并用准确的分割块来定位物体。PSG任务旨在推动计算机视觉模型对场景最全面的理解和感知,用全面的识别结果更好地支撑场景描述、视觉推理等下游任务。同时PSG数据集提供的关系标注和全景分割也为解决当前图像生成领域对关系不敏感的问题创造了新的机遇。


图2:场景图生成

论文信息


任务优势
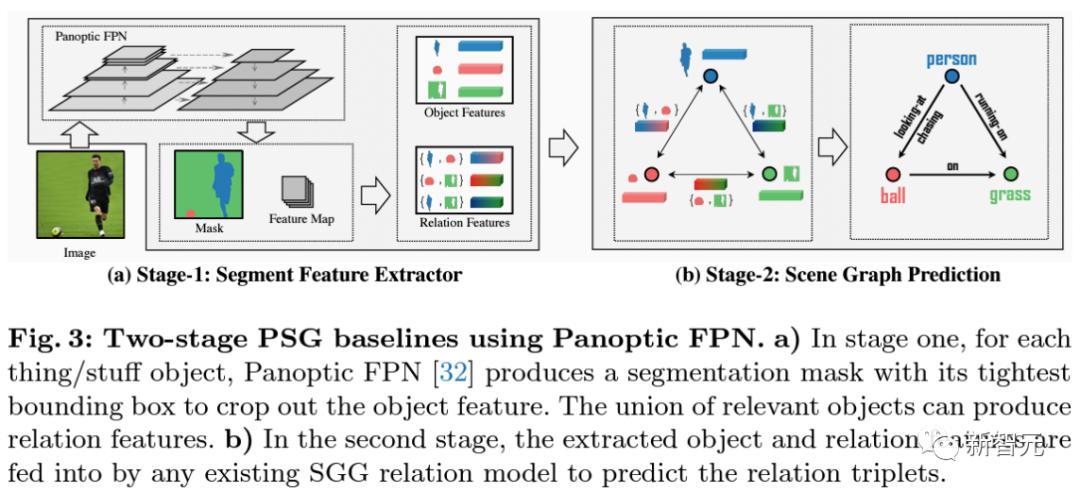
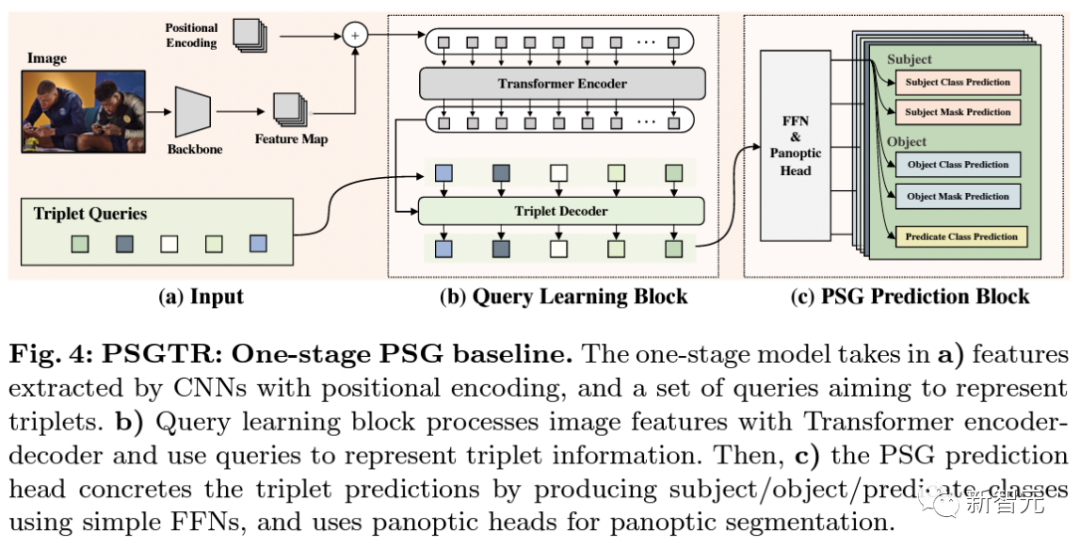
两大类PSG模型

结论分享
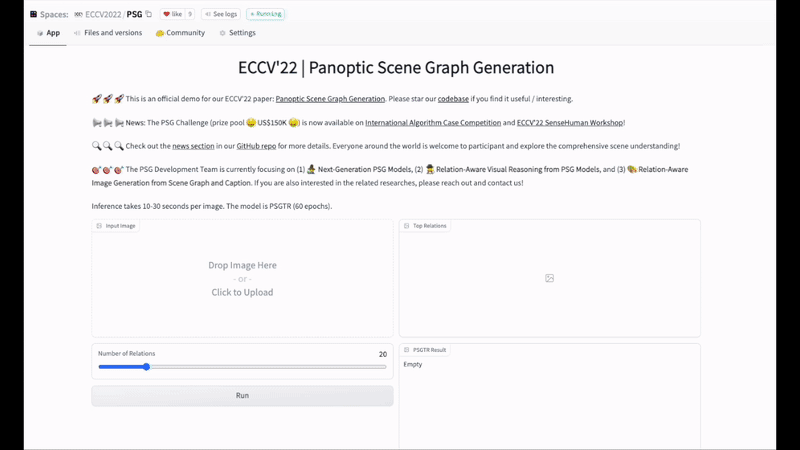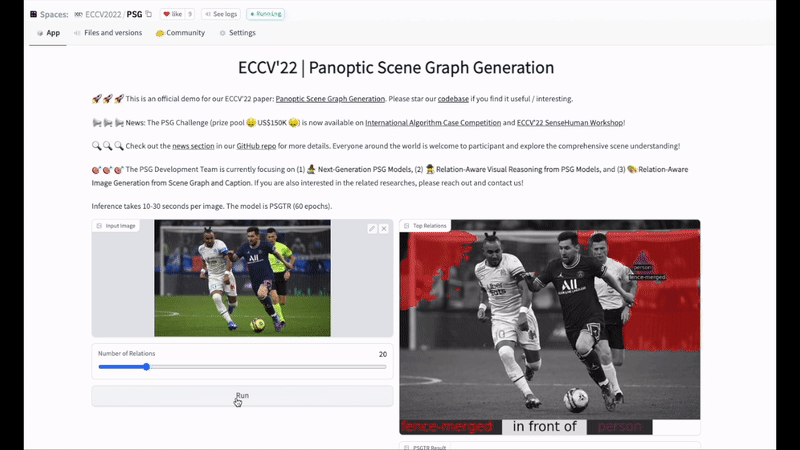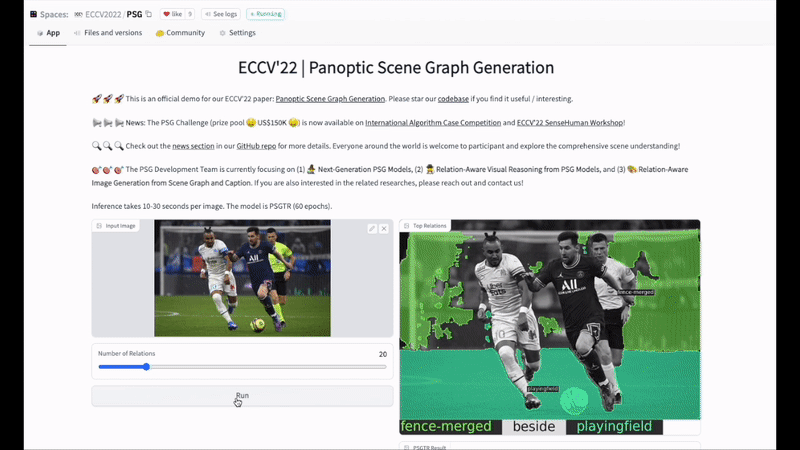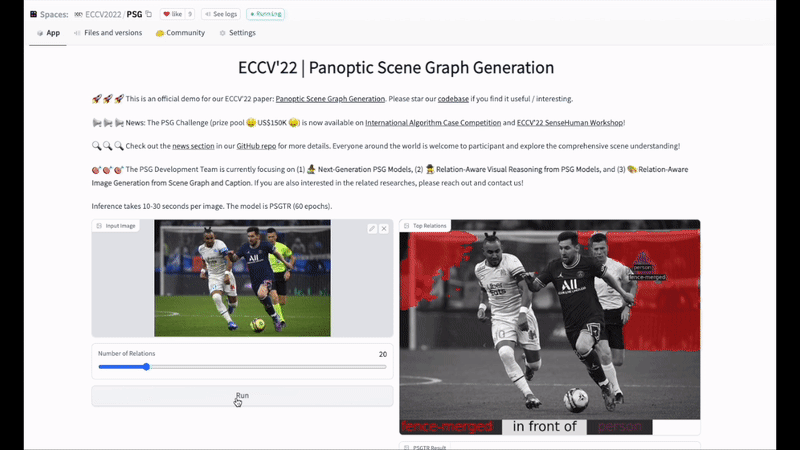
关于图像生成的展望



登录查看更多
相关内容

相关VIP内容
相关资讯
相关论文