有了谷歌这款What-If工具,无需代码即可掌握模型的所有资料
编者按:如果不用写代码就能对机器学习模型进行审查,那会是怎样的体验?今天,谷歌开源了一款工具,名为What-If,具体有以下几种功能:
对推断结果可视化;
编辑数据点,看模型会有怎样的反应;
研究单一特征对模型的影响;
研究反事实样本;
用相似度安排样本;
查看混淆矩阵和ROC曲线;
测试算法公平性。
以下是论智对这一工具进行的详细介绍:
打造高效的机器学习系统意味着要问很多问题,仅仅训练模型是不够的,优秀的机器学习专家会像侦探一样,对模型进行详细调查,以更好地理解它们:数据点的改变将如何影响模型的预测?针对不同的群体,模型的表现有何不同?我要测试的数据集中包含多少种类的数据?
想要回答这类问题可并不容易。研究机器学习模型的使用场景通常要用定制的、一次性的代码分析。这一过程不仅低效,而且对不会编程的人员也不友好。谷歌AI PAIR计划其中一个努力方向就是让更多的人能参与到机器学习系统的检查、评估和debug中来。
今天,我们发布What-If工具,这是一款新的开源TensorBoard网页应用,能让我们无需编写代码就能分析一款机器学习模型。给定一个TensorFlow模型和数据集,What-If工具可以展示出表现模型结果的交互界面。
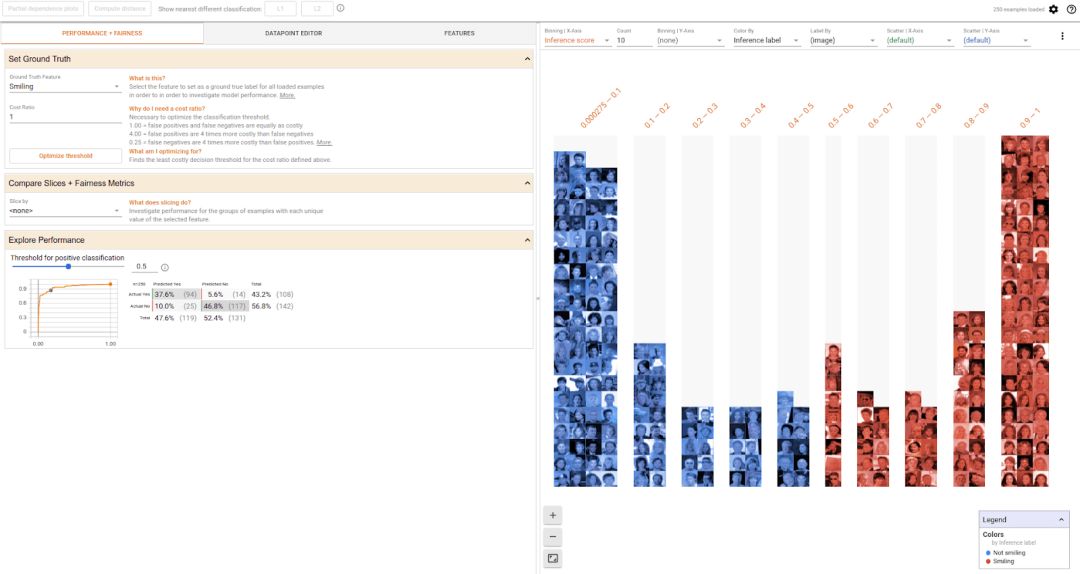
What-If工具,展示了250张人脸图像和模型在其中检测微笑的结果
What-If工具有多种功能,包括用Facets自动对你的数据集进行可视化、从数据集中手动编辑样本的能力以及观察这些变化带来的影响、并且自动生成partial dependence plots,展示模型的预测是如何随着单一特征的变化而变化的。接下来就是对这两种特征的详细介绍。
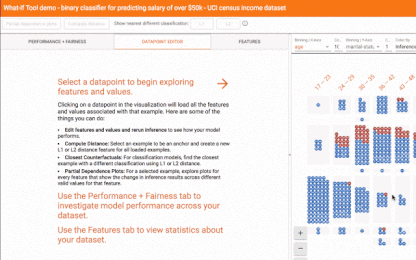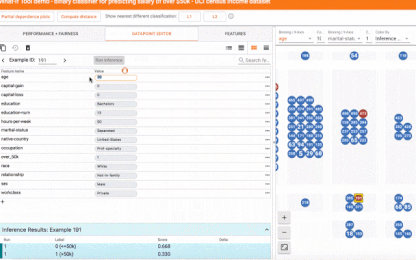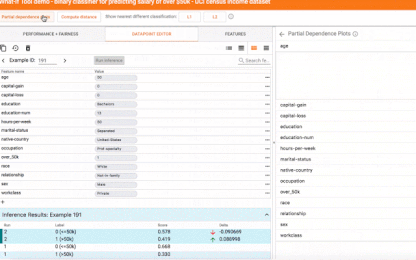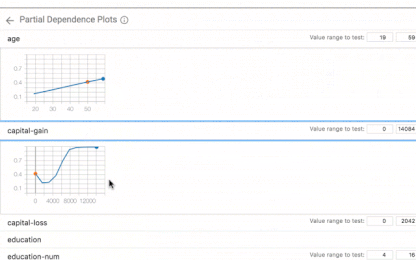
在一个数据点上探索what-if场景
反事实(counterfactuals)
只需要点击鼠标,你就能比较一个数据点和另一个相似的数据点,但模型在后者上预测出了不同的结果。我们将这样的数据点称为“counterfactuals”,它们可以告诉你有关模型决策边界的信息。
在下方的截图中,这款工具就用到了一个二元分类模型上,它是根据UCI的人口普查数据来判断某人的收入是否大于5万美元。这是很多机器学习研究者都会用到的预测模型,尤其是分析算法的公平性时。在这个案例中,对于选择的数据点,模型预测出的结果有73%的置信度认为该人的收入高于5万美金。该工具自动定位了数据集中另一位与之相似的对象,但模型预测他的收入小于5万美金,并将这两个目标进行了比对。在这种情况下,对年龄和职业进行稍稍改动,模型的预测就有了变化。
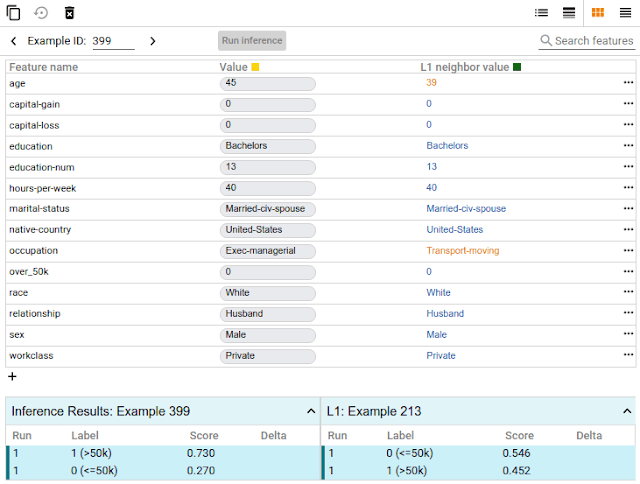
比较counterfactuals
分析模型性能和算法公平性
你还可以探索不同分类阈值所带来的不同影响,下方的截图展示了另一个微笑监测模型的结果,他在开源的CelebA数据集上进行的训练,该数据集含有经过标记的名人人脸图像。在下方的案例中,数据集中的人脸根据头发颜色进行了分类,每两组数都有一个ROC曲线和针对预测的混淆矩阵,以及设置了模型判断人脸在微笑的信心有多少。在这个案例中,两组数据的置信区间是用该工具自动设置的,从而保证公平性。
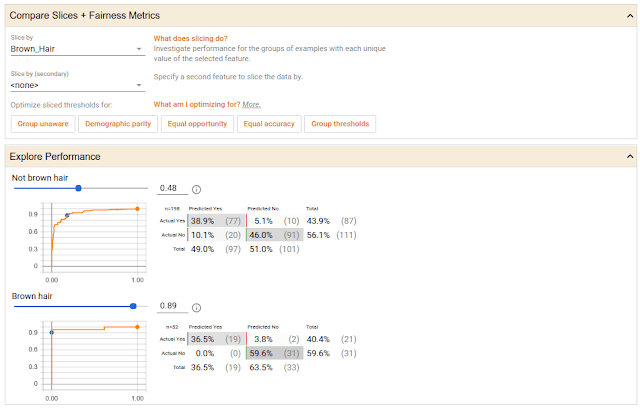
比较两部分数据在微笑探测器上的性能
Demos
为了说明What-If工具的能力,我们用预训练模型展示了一套demo:
检测错误分类:一个多种类分类模型,它可以从众多植物中预测某株植物的种类。这一工具在展示模型决策边界、判断如何造成错误分类时是非常有用的。模型是在UCI iris数据集上进行训练的。
评估二元分类模型中的公平性:正是上文中我们提到的微笑探测模型。What-If工具可以帮助我们在多个分类中评估算法公平性。模型在训练时没有提供任何具体任务的图片,为的就是证明What-If工具能如何帮助模型解除偏见。评估公平性需要仔细考虑所有语境,但这的确是有用的量化起始点。
在不同子集中研究模型性能:例如一个可以预测目标对象年龄的回归模型,What-If工具就可以展示与模型相关的其他子集上的性能信息,以及不同的特征是如何影响预测结果的。模型同样是在UCI人口普查数据集上进行的训练。
在实际中应用What-If工具
我们在谷歌内部团队中对What-If进行了测试,发现了它的很多好处。其中一个团队很快就发现了他们的模型忽视了数据集中的一个重要的特征,从而修复了之前没有发现的代码bug。另一个团队用该工具对它们的样本性能进行从优到劣的可视化排序,让他们看到了模型样本的类型构成。
不论是谷歌的员工还是其他领域的从业者,我们都希望这款工具能让用户更好地了解机器学习模型,并对公平性有所了解。另外,此工具的代码是开源的,欢迎大家尝试并提出意见。
博客地址:ai.googleblog.com/2018/09/the-what-if-tool-code-free-probing-of.html
代码地址:github.com/tensorflow/tensorboard/tree/master/tensorboard/plugins/interactive_inference




