【用户模拟器】原理篇二:深度建模的方法

上篇文章向大家介绍了用户模拟器的结构、特点、基于统计建模及其优缺点,本篇文章将介绍几种基于深度模型实现用户模拟器的方法。
一、动机
基于统计建模和人工编写规则的方法尽管落地性强,精准率高,但是成本很高,还有一些缺点:【用户模拟器】原理篇一:统计建模的方法
-
无法考虑长时间的对话历史; -
需要刻板的结构来保证用户行为的一致性; -
严重依赖于特定领域; -
在一次对话期间无法输出多个用户意图。
因此寻求数据驱动的模型化方法是一个很好的途径。利用对话语料进行端到端训练的效果一般优于基于统计建模的方法,它的优点是数据驱动,节省人力。
下面介绍三种基于深度模型的建模方案,这几种模型均是使用了DSTC2/DSTC3数据集进行模型训练与效果评估。
二、DSTC数据集简介
2.1 数据集整体介绍
DSTC1-DSTC3的数据情况如下所示:
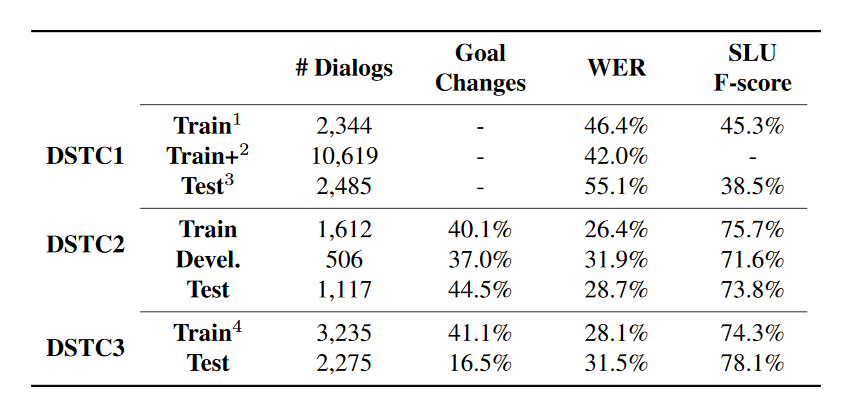
-
DSTC1:公交线路查询,目标固定不变。共5个slot(路线,出发点,重点,日期,时间),有些slot(时间和日期)的取值数量不固定。而且DSTC1的用户目标在对话过程中不会发生变化; -
DSTC2:餐馆预订,用户查询满足特定条件下的餐馆的某些信息(电话、地址等),用户目标会在对话过程中发生变化; -
DSTC3:在DSTC2数据的基础上,增加了一些新的slot,而且添加了新的域:旅游信息查询。
DSTC2/DSTC3数据集槽位情况:

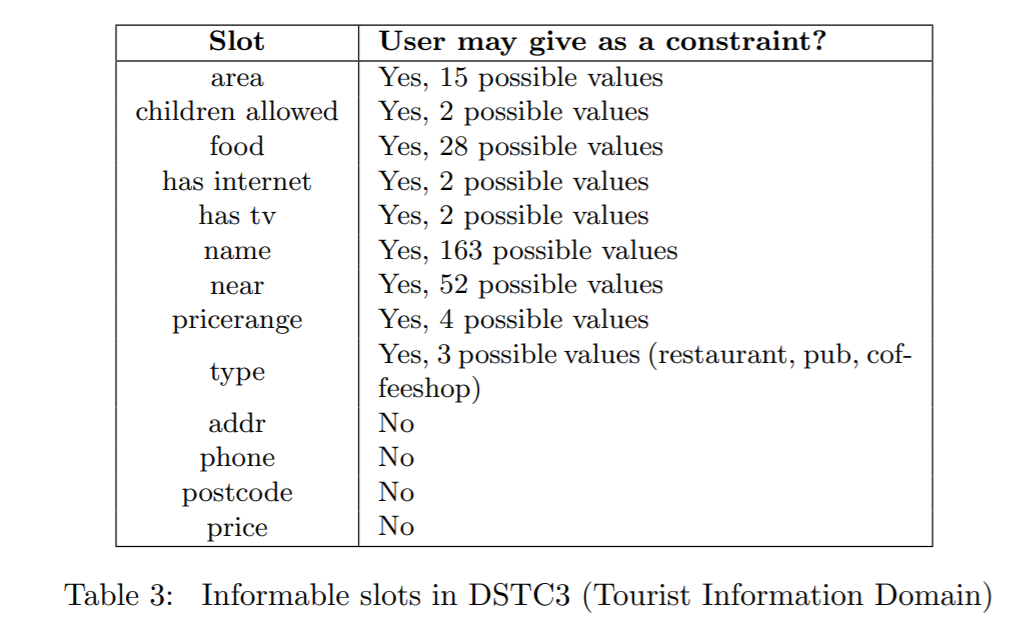
2.2 标注数据说明
一个完整的标注会话包含以下内容:
-
session-id:会话唯一id -
caller-id:用户唯一id -
turns:轮次粒度进行标注的列表[ -
turn-index: 轮数,从0开始 -
audio-file:录音文件 -
transcription:录音转文本 -
semantics:对话表征 -
goal-labels:用户目标(槽值映射) -
method-label:使用的方法 -
requested-slots:用户请求槽位 ] -
task-information:任务信息 -
success: 任务是否成功 -
comments: 用户评价 -
questionnaire:问卷(问题答案对列表) -
text:任务描述 -
constraints:约束(槽值对列表) -
request-slots:请求(槽位列表) -
goal:给工作人员目标/任务的信息 -
feedback: 用户反馈
一个样本示例:
{"caller-id": "03c2655d43","turns": [{"turn-index": 0,"goal-labels": {"food": "international","area": "east"},"transcription": "restaurant in the east part of town international food","method-label": "byconstraints","audio-file": "pt344x_0000956_0001231.wav","requested-slots": [],"semantics": {"json": [{"slots": [["food","international"]],"act": "inform"},{"slots": [["area","east"]],"act": "inform"}],"cam": "inform(type=restaurant,area=east,food=international)"}},{"turn-index": 1,"goal-labels": {"food": "international","area": "east"},"transcription": "phone number","method-label": "byconstraints","audio-file": "pt344x_0001609_0001668.wav","requested-slots": ["phone"],"semantics": {"json": [{"slots": [["slot","phone"]],"act": "request"}],"cam": "request(phone)"}},{"turn-index": 2,"goal-labels": {"food": "international","area": "east"},"transcription": "thank you good bye","method-label": "finished","audio-file": "pt344x_0002245_0002362.wav","requested-slots": [],"semantics": {"json": [{"slots": [],"act": "thankyou"},{"slots": [],"act": "bye"}],"cam": "thankyou()|bye()"}}],"task-information": {"goal": {"text": "Task 09126: You want to find a restaurant in the east part of town and it should serve international food. Make sure you get the phone number of the venue.","request-slots": ["phone"],"constraints": [["food","international"],["area","east"]]},"feedback": {"questionnaire": [["The system understood me well.","slightly disagree"]],"comments": null,"success": true}},"session-id": "voip-03c2655d43-20130327_194221"}
三、深度建模的方法
3.1 固定用户目标的端到端模型
3.1.1 论文思想
鉴于统计模型的缺点,论文A Sequence-to-Sequence Model for User Simulation in Spoken Dialogue Systems提出了一种考虑全部对话历史,不依赖固定结构,基于编码解码的端到端模型,它将对话上下文序列作为输入,然后输出一系列用户动作序列。
3.1.2 工作机制
模型结构如下图所示:
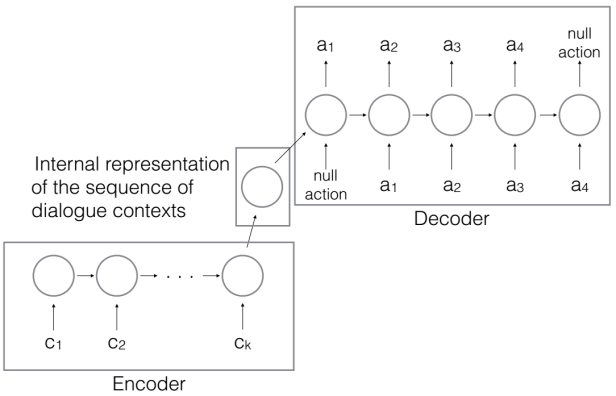
其中 为对话上下文序列, 为输出的用户动作序列。
-
在每次对话开始之前,统一的构建出一个 Goal G=(C,R),对于餐馆查询任务而言,约束条件C通常指的是菜品口味、菜品价格以及餐馆所在方位,问询内容R为以下槽位:餐馆名称、餐馆地址、餐馆电话等。
-
在第 t 轮对话,一个上下文序列 包含以下 4 部分:
在每次对话的过程中,会根据 dialogue acts 的个数以及 Goal 的状态,对以上 4 部分进行 one-hot 编码,从而得到对话上下文的向量化表示。
-
上一轮的系统动作 ; -
上一轮系统回复的信息与 User Goal 不一致的部分 ; -
约束条件的状态(告知与否) ; -
问询内容的状态(被告知与否) 。
-
在 t 时刻,将上下文序列 输入到一个 encoder LSTM 网络,得到一个向量 作为对话历史的内部表示。
-
然后再将向量 输入到 decoder LSTM 网络,输出 dialogue acts 序列,比如 (inform, request)。接下来可以通过启发式规则将 dialogue acts 映射为带槽的用户行为,比如 inform(food=Chinese), request(price_range);也可以训练一个模型,让它直接输出最终的行为,比如 request_area,inform_pricerange。这种方式的优点是不需要写启发式规则,可以做到更细粒度的建模。
3.1.3 结果对比
论文使用F1-score作为评价指标,最后的实验结果显示该模型的效果优于基于议程的方法。

3.2 可变用户目标的端到端模型
3.2.1 论文思想
上一篇论文中提到的一些端到端系统虽然对整个对话历史都进行了跟踪,并且用户的行为是从数据中学习得到的,但是依旧存在两个问题:
-
没有对用户的目标改变(goal change)进行建模; -
只在语义层面进行用户模拟,需要耗费人力标注出每轮用户语句的语义标签进行模型训练,而不是直接利用自然语句进行训练。
因此论文Neural User Simulation for Corpus-based Policy Optimization for Spoken Dialogue Systems提出了基于 RNN 的 Neural User Simulator (NUS) 模型,对用户的目标改变(goal change)进行建模,将对话上下文序列作为输入,然后输出去词汇化的自然语句。
3.2.2 工作机制
-
首先 NUS 通过用户目标生成器,对原对话数据中的对话状态标签进行预处理,得到一个完整对话中每一轮的具体用户目标,这样就相当于对用户目标改变进行了某种程度上的建模,如下表所示:
-
表中显示某个对话一共有四轮,其中 第 2、3 轮之间出现了对 food 这个槽位的目标变化, 因此右边处理之后得到了用户目标也出现了变化。这样的用户目标不再是一成不变,而是充分根据对话数据给出了动态的用户目标,更加贴近实际。
-
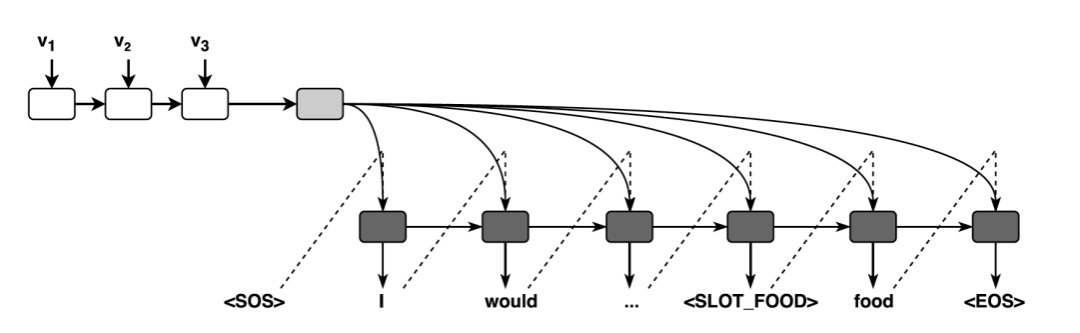
有了每轮的用户目标,NUS 通过 RNN 来生成用户语句:
图中 是每一轮提取出来的特征,它一共包含四个向量 :
-
是系统动作向量,包含,是一个长度等于所有可能的系统动作的二进制向量,是一个长度为可告知槽(informable slots)总个数 4 倍的二进制向量,用来表示本轮系统动作是否出现了 request、select、inform 和 expl-conf 这四个以可告知槽为参数的动作;
-
称作问询向量,是一个长度和可问询槽(requestable slots)总个数相等的二进制向量,用来标记哪些用户目标中需要问询的可问询槽还没有被用户向系统提问;
-
称作不一致向量(inconsistency vector), 长度等于可告知槽总个数,一旦系统动作中对某个槽出现了和本轮用户目标不一致的情况,对应的位置处元素置 1;
-
是用户目标约束向量,长度等于可告知槽总个数,用来表示本轮用户目标中出现了哪些可告知槽。
-
NUS 生成的回复是去词汇化的自然语句,经过后处理则得到了用户的自然语言回复。

3.2.3 结果对比
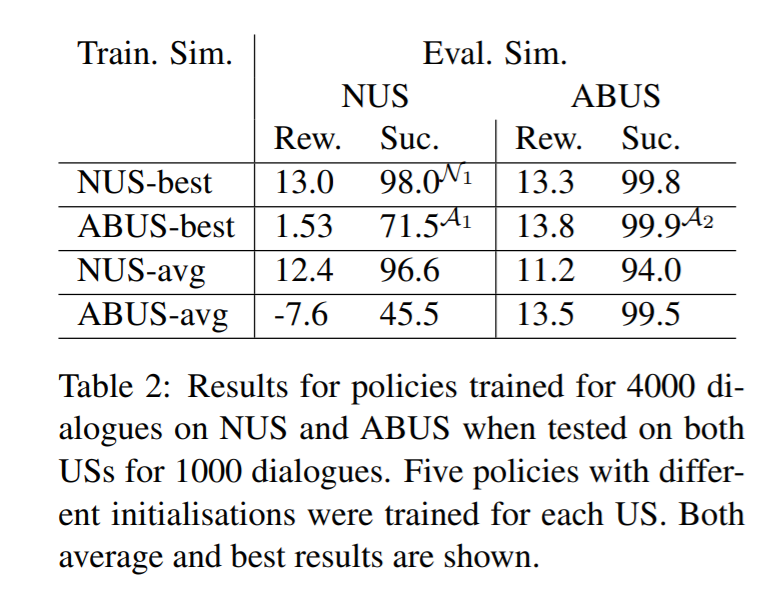
论文为了论证 NUS 效果优于 Agenda-based User Simulator (ABUS), 提出了一个交叉模型评估的方法,即在一个 User Simulator 上训练一个 agent,在其他 User Simulator 上测试该 agent,如果 agent 效果依旧很好,说明用于训练的 User Simulator 是更加贴近真实用户。论文使用平均奖励分数(任务完成+20,每轮-1)和任务完成率(同时满足约束和请求)作为评价指标。最终实验结果证明,在 NUS 上训练得到了的 agent,在 ABUS 和真实用户上测试得到的成功率均优于 ABUS,而在 ABUS 上训练得到的 agent 效果只在 ABUS 上测试好。
3.3 联合优化模型
3.3.1 论文思想
使用RL进行对话策略学习需要对话系统与用户模拟器进行交互。然而,构建一个可靠的用户模拟器并不简单,它通常与构建一个好的对话系统一样困难。用户模型和对话管理模型功能十分接近,因此可以将用户模拟器和对话系统进行联合优化。
论文Iterative Policy Learning in End-to-End Trainable Task-Oriented Neural Dialog Models对用户模拟器和对话系统分别采用了 RNN 进行端到端的建模并使用同一个回报函数优化,两者交替训练共同最大化累计回报。
3.3.2 工作机制
-
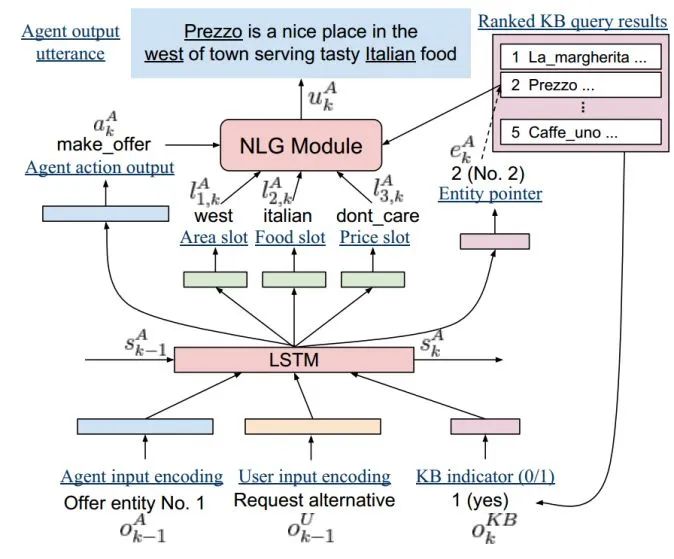
对话系统模块:论文使用的对话系统是一个端到端的 LSTM 模型,如下图所示:
对话系统的状态由 LSTM 的隐层节点编码,每一轮都会进行更新。在第 k 轮对话,给定上一轮的系统语句 ,用户语句 ,数据库查询结果 作为输入,LSTM 模型更新上一轮的对话状态 为 。新的对话状态 通过前馈神经网络可以直接预测出本轮各个槽的跟踪分布、系统应采取的对话动作 和一个 one-hot 编码的数据库指针 。NLG 部分作者选择采用模板的方法生成。
-
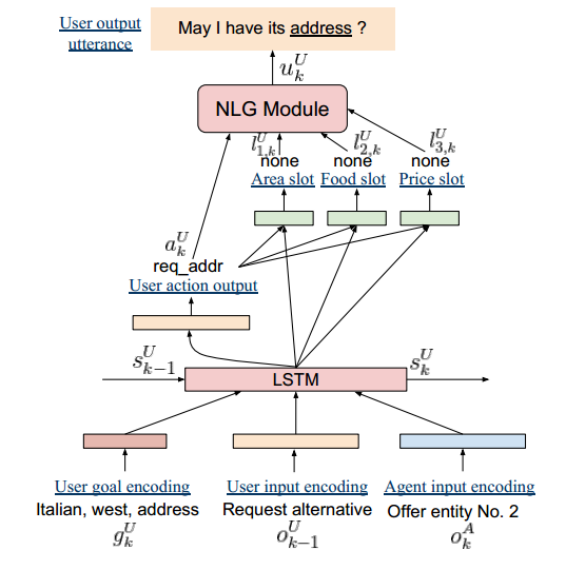
用户模拟器模块:对应的用户模拟器的结构也是采用了端到端的 LSTM 模型,如下图所示:
输入换作了用户目标编码 ,上一轮用户语句 和当前轮系统语句 ,模型每轮更新用户状态 为 。新的用户状态 也通过前馈神经网络得到本轮用户应采取的动作和槽值参数。NLG 部分采用模板的方法直接生成。
-
回报函数:作者对用户模拟器和对话系统进行联合策略优化,使用了策略梯度(policy gradient)算法,两者各自的状态为 和 ,动作为 和 。回报函数采用:
其中 是用户目标, 是对话系统对用户目标的估计,D(・) 是一个得分函数,论文中奖励是根据任务完成的程度来计算的。根据相邻轮得分函数之差可以得到单轮回报函数 。用户模拟器和对话系统交替优化,共同最大化累计回报函数 。
-
策略梯度:求解时使用策略梯度的方法,根据强化学习公式,目标函数可以写为:
其中, 为折扣因子,通过寻找最优的对话系统参数 和模拟器参数 来使目标函数 最大化。梯度计算公式分别为:
3.3.3 结果对比
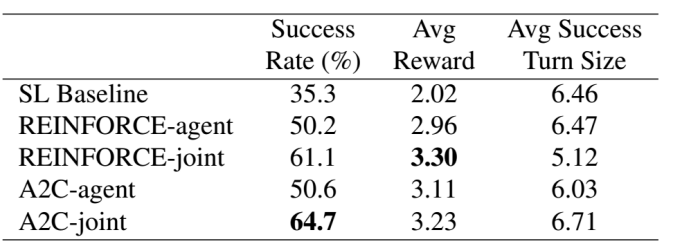
为了降低策略梯度优化的方差,论文采用 Advantage Actor-Critic (A2C) 算法,并使用 ε-softmax 进行策略探索,在 DSTC2 数据集上进行了初步实验,结果如下:
四、总结
针对统计模型需要通过人工编写规则,成本高的缺点,本文介绍了几种易于实现的数据驱动的模型化方法。利用对话语料进行端到端训练的效果一般优于基于议程的规则方法,它的优点是数据驱动,节省人力;但缺点是复杂对话建模困难,对数据数量要求很高,因此对于一些对话语料稀缺的领域效果很差。
五、参考文献
-
https://blog.csdn.net/c9yv2cf9i06k2a9e/article/details/98549007 -
A Sequence-to-Sequence Model for User Simulation in Spoken Dialogue Systems -
Neural User Simulation for Corpus-based Policy Optimization for Spoken Dialogue Systems -
Iterative Policy Learning in End-to-End Trainable Task-Oriented Neural Dialog Models -
User Simulation in Dialogue Systems using Inverse Reinforcement Learning
作者介绍
刘娜,2019年6月毕业于北京邮电大学自动化学院,毕业后加入贝壳找房语言智能与搜索部,主要从事NLP及强化学习相关工作。
相关文章
下期精彩
【用户模拟器】实践篇:用户模拟器在贝壳IM场景中的应用

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,点个在看吧👇



