【2021年度发展报告】表格识别技术研究进展




图片来源摄图网

题目:表格识别技术研究进展
作者:高良才, 李一博, 都林, 张新鹏, 朱子仪, 卢宁, 金连文, 黄永帅, 汤帜
引用格式:Gao L C, Li Y B, Du L, Zhang X P, Zhu Z Y, Lu N, Jin L W, Huang Y S, Tang Z . 2022. A survey on table recognition technology. Journal of Image and Graphics, 27(6): 1898-1917. (高良才, 李一博, 都林, 张新鹏, 朱子仪, 卢宁, 金连文, 黄永帅, 汤帜. 2022. 表格识别技术研究进展. 中国图象图形学报, 27(6): 1898-1917.) [DOI: 10.11834/jig.220152]
点击文末“阅读原文”查看论文全文
1)该文围绕表格区域检测、结构识别和内容识别等3个表格识别子任务,从传统方法、深度学习方法等方面,综述该领域国内外的发展历史和最新进展。梳理了表格识别相关数据集及评测标准。
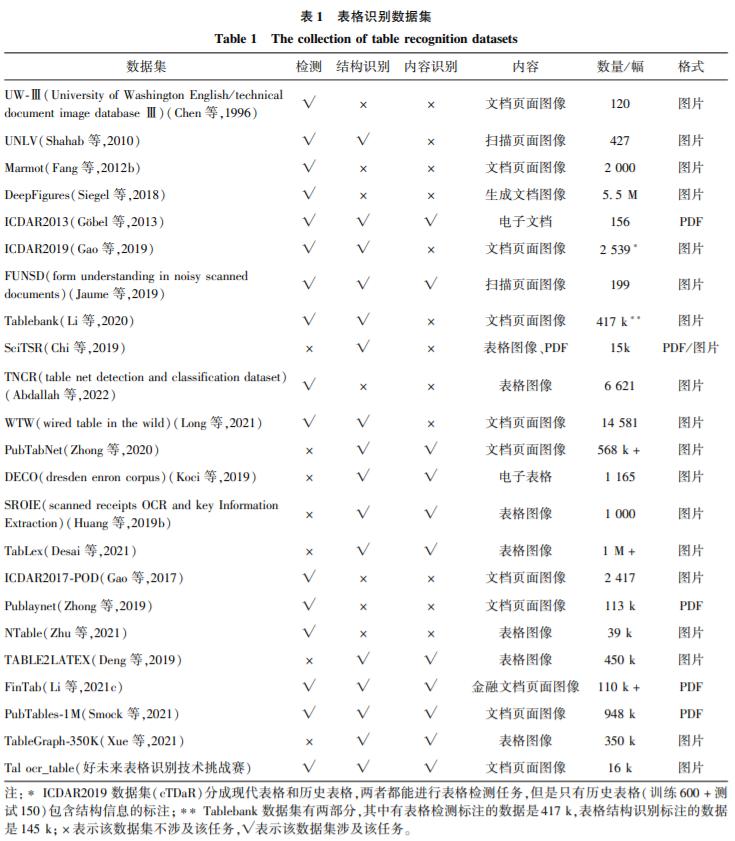
2)基于主流数据集和标准,分别对表格区域检测、结构识别、表格信息抽取的典型方法进行了性能比较。

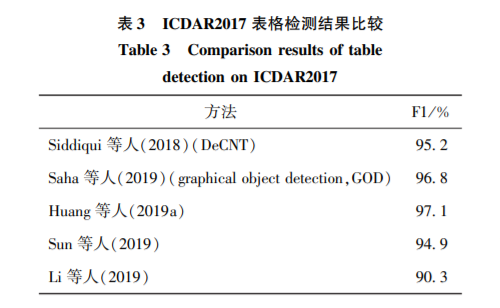
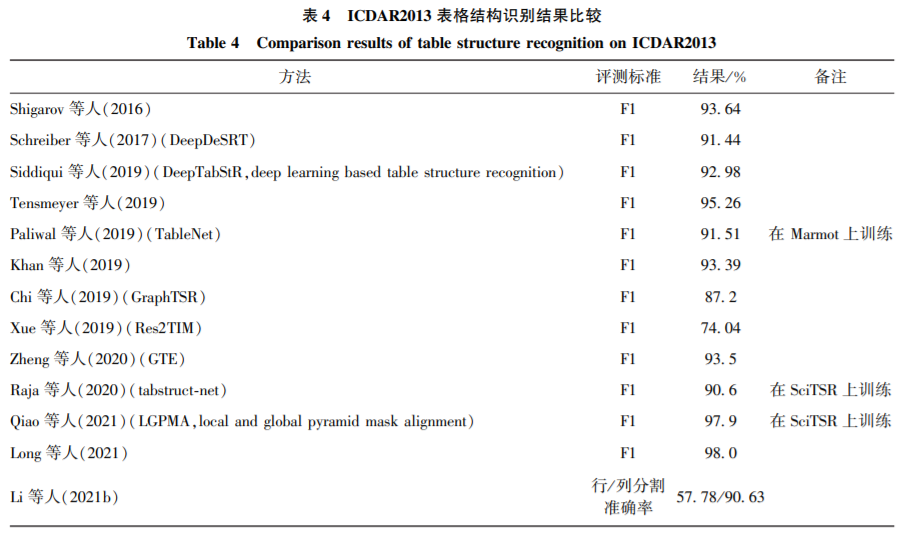
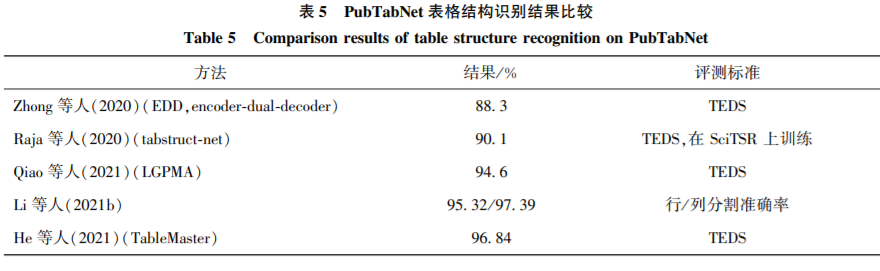
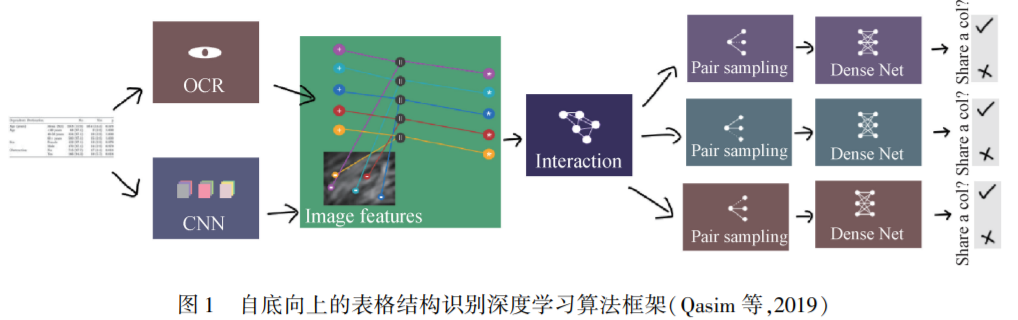

对于表格区域检测,其准确率已经达到了比较高的水平。而检测作为识别的一部分,两者逐渐一体化,单独的检测逐渐弱化。如何让检测和结构识别的结果相互促进将是以后研究的方向和重点。
由于表格应用场景较为广泛,表格形式多种多样,文档图像质量参差不齐,表格结构识别仍存在着较大的挑战。具体表现为:1)跨页表格对结构识别带来的识别困难;2)表格线未对齐带来的行列判定困难;3)表格嵌套(某些小表格是大表格的单元格)带来的识别困难;4)一些非常规的表格线标注形式;5)现实场景带来的扭曲、褶皱和光照等问题。
对于表格结构识别,现阶段主流的方案包括两种:1)单元格检测+单元格关系判断;2)编码解码器同时生成HTML或Latex代码以及相对应的单元格位置。方案1)主要关注如何检测出更准确的单元格,在后续研究中可尝试使用表格文本的语义信息来提高;方案2)主要关注生成的代码过长时,准确率的降低以及回归的单元格框漂移等问题,可尝试由目标检测网络提出单元格候选框来改善。未来随着表格应用场景的增加,表格数据集的丰富,现实场景的表格识别以及表格识别的预训练模型都是值得深入挖掘的方向。
对于表格内容识别与理解,总体来说,随着自然语言模型的成熟和发展,自然语言处理的方法所能处理的信息形式已经不仅仅局限于1维的顺序文本,研究者们对于表格、票据等(半)结构化文档信息提取的研究热情日益增长。然而,由于表格形式复杂多样,并涉及各个行业的专业知识,目前研究者们面临着两大挑战:一方面是表格信息的表示方式难以统一,不同形式的表格有着不同形式的结构关系,很难构建出从表格信息到机器表征的通用识别框架,目前的大部分研究还处于针对某类特定的表格数据进行性能优化的阶段;另一方面,对于表格的查询、问答和文本生成等以内容为主导的任务,由于表格数据通常具有一定的专业性且表格中表达的语义不唯一,数据的标注难度很大且成本高昂,训练出的模型迁移能力较差。
随着深度学习技术的发展,大规模预训练模型已经成为自然语言处理领域中广泛认可的有效方法,表格内容的识别及理解在近年来快速发展,但在这一领域中目前并没有出现具有关键影响力的大规模预训练表格理解和表格生成模型。目前常用的方案大多都是对已有的语言模型进行改进,尽管这类方法针对某类具体问题可能是行之有效的,但往往不能很好地应用于其他表格内容识别相关的任务中。因此,寻找并构建出针对表格结构的大规模预训练模型,或是构建出在顺序文本、结构化文本和场景文本等多种形式的文档结构中都有良好表现的预训练语言模型,也是该领域目前面临的一大挑战和重要研究方向。
就整体趋势而言,一方面表格内容识别的任务具有具象化的特征,新的任务和新的应用场景纷纷出现,体现出了很高的应用价值,相关的任务类型和涵盖的领域也趋于具体,出现了很多专门针对具体问题的方法和模型;另一方面,表格内容识别也具有理论意义,研究者们对于基础模型的构建具有很高的研究兴趣,一些与表格内容识别相关的方法已经体现出了很高的泛化能力,能适用于序列文本、结构化文本和场景文本等不同类型的对象。在抽象层次,力图构建泛化性更好的基于文档的表征模型,寻找更加具有普适性的方法来描述、理解和处理表格信息,也是未来的研究热点之一。
【作者简介】

高良才,北京大学王选计算机研究所副教授,主要研究方向为模式识别。
E-mail: glc@pku.edu.cn

汤帜,通信作者,北京大学王选计算机研究所研究员,主要研究方向为人工智能、文档处理技术。
E-mail: tangzhi@pku.edu.cn
李一博,北京大学王选计算机研究所硕士研究生,主要研究方向为表格识别。
E-mail: yiboli@pku.edu.cn
都林,华为技术有限公司 AI 应用研究中心工程师,主要研究方向为机器学习、文字识别。
E-mail: dulin09@huawei.com
张新鹏,北京大学王选计算机研究所硕士研究生,主要研究方向为表格理解。
E-mail: zhangxinpeng@pku.edu.cn
朱子仪,北京大学王选计算机研究所本科生,主要研究方向为表格识别。
E-mail: zhuziyi@pku.edu.cn
卢宁,华为技术有限公司 AI 应用研究中心博士,主要研究方向为计算机视觉。
E-mail: luning12@huawei.com
金连文,华南理工大学电子与信息学院教授,主要研究方向为计算机视觉、文字识别。
E-mail: eelwjin@scut.edu.cn
黄永帅,华为技术有限公司 AI 应用研究中心工程师,主要研究方向为计算机视觉。
E-mail: huangyongshuai1@huawei.com
中国图象图形学学会
文档图像分析与识别专委会简介
中国图象图形学学会文档图像分析与识别专委会聚焦于光学文字识别(OCR)、文档图像处理、文档图像理解、联机手写识别领域的学术研究、技术交流及产业应用发展,汇集国内学术界及企业界知名专家及专业技术人员,在中国图象图形学学会的领导下,旨在推进文档图像分析与识别领域的发展战略研究、学术进步与技术交流,促进全国性跨地区学术技术交流与合作,为我国模式识别与人工智能学科发展、为国家信息化、智能化建设贡献力量。
| 主任 | 金连文 | 华南理工大学 | 教授 |
| 副主任 |
吕岳 | 华东师范大学 | 教授 |
| 孙俊 | 富士通研究开发中心 | 部长 | |
| 殷绪成 | 北京科技大学 | 教授 | |
| 秘书长 | 殷绪成(兼) | 北京科技大学 | 教授 |

