技术亮点解读:Apache InLong毕业成为顶级项目,具备百万亿级数据流处理能力

Apache 软件基金会(即 Apache Software Foundation,简称为 ASF)于近日正式宣布,Apache InLong(应龙) 从孵化器成功毕业,成为基金会顶级项目。

InLong 中文名“应龙”是中国神话中引流入海的神兽,意寓 InLong 在大数据社区生态中的价值:大数据接入集成。该项目最初于 2019 年 11 月由腾讯大数据团队捐献到 Apache 孵化器,2022 年 6 月正式毕业成为 Apache 顶级项目。
InLong 以腾讯内部使用的 TDBank 为基础,依托万亿级的数据摄取和处理能力,将数据采集、聚合、存储、排序数据处理的全流程整合在一起。不仅提供自动、安全、可靠和高性能的数据传输能力,还支持基于流式的数据分析、建模和应用,帮助企业简化数据处理的过程。
比如,InLong 作为一个基于 SaaS 的服务平台,用户可以选择主题的数据发布和订阅,来轻松快速地报告、传输和分发数据,大幅降低了使用门槛。同时 InLong 可以为 100 万亿级数据流提供高性能处理能力,为 1000 亿级数据流提供高可靠服务,保障用户享受到稳定可靠的在线服务。
InLong 支持多种数据访问方式,包括不同类型的消息队列服务集成和实时数据提取、转换、加载以及基于规则的排序功能;在服务方面,InLong 为用户提供统一的系统监控和告警服务。通过细粒度的指标来促进数据可视化,用户可以在统一的数据度量平台中直接查看队列的运行状态,大大提高了业务的主动性。
Apache InLong 的毕业,标志着业界首个一站式大数据集成 Apache 顶级项目诞生,也标志着第一个由腾讯捐献的 Apache 项目孵化成功,中国本土原生的顶级项目再增一员。
Apache InLong 在孵化期间,连续发布 12 个版本,关闭超 2300 个 Issue,来自国内外的社区开发者,一起完成了 Manager 元数据管理重构、基于 Flink SQL 的 Sort ETL 方案、基于标签的跨地域多集群等特性。目前 Apache InLong 正广泛应用于广告、支付、社交、游戏、人工智能等行业,为多领域客户提供高效化、便捷化的数据集成服务。
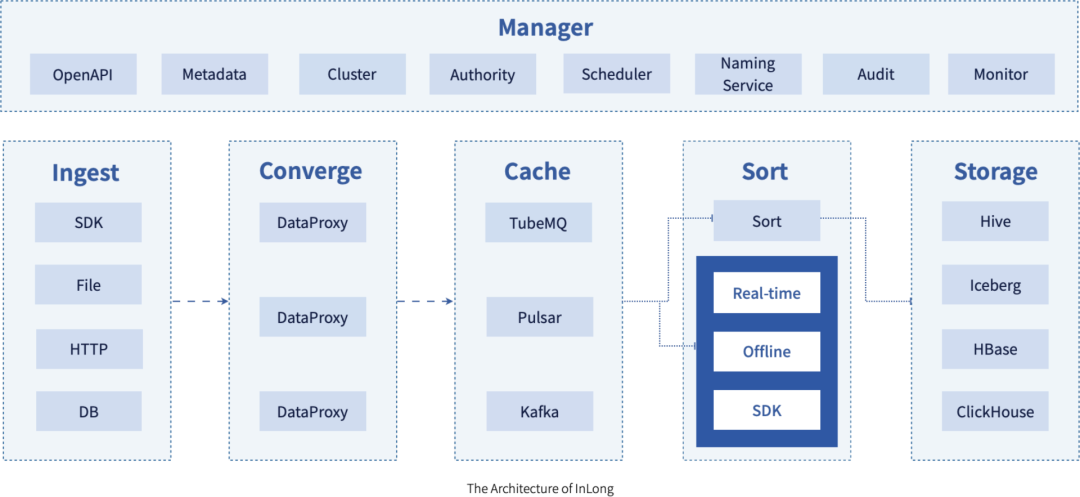
作为一个面向大数据集成的开源框架,Apache InLong 拥有架构上的优势,项目在发展的过程中逐渐形成了以下特点:
简单易用,基于 SaaS 模式对外服务,用户只需要按主题发布和订阅数据即可完成数据的上报,传输和分发工作。
稳定可靠,系统源于实际的线上系统,服务近百万亿级的高性能及上千亿级的高可靠数据数据流量,系统稳定可靠。
功能完善,支持各种类型的数据接入方式,多种不同类型的 MQ 集成,以及基于配置规则的实时数据 ETL 和数据分拣落地,并支持以可插拔方式扩展系统能力。
服务集成,支持统一的系统监控、告警,以及细粒度的数据指标呈现,对于管道的运行情况,以数据主题为核心的数据运营情况,汇总在统一的数据指标平台,并支持通过业务设置的告警信息进行异常告警提醒。
灵活扩展,全链条上的各个模块基于协议以可插拔方式组成服务,业务可根据自身需要进行组件替换和功能扩展。
选用一款消息队列服务,需要考虑成本、性能、稳定性、可靠性、可维护性等方面。在万亿级别的海量数据场景,一般的消息队列服务需要通过大量的机器资源去堆积整体的吞吐能力,会出现机器成本高、超大集群不易维护等问题。InLong TubeMQ 是 Apache InLong 全链路数据集成解决方案自带的一款消息队列服务,相比较业界主流的消息队列服务,拥有低成本、高性能、高稳定性的特点。InLong TubeMQ 是基于有损服务的前提下,采用尽可能保证数据不丢、服务不受阻的思路进行设计,力求方案简单维护简便。
在 TubeMQ 的设计里,分区故障并不影响 Topic 的整体对外服务,只要 Topic 有一个分区存活,整体的对外服务就不会受阻。同时,TubeMQ 的数据时延 P99 可以做到毫秒级,这样保证了业务可以尽可能快的消费完数据,做到尽可能不丢。另外,TubeMQ 独有的数据存储方案设计性能要比 Kafka 的 TPS 至少高出 50% 以上(有些机型上还是翻倍的效果),同时借助存储方案的不同,单机容纳的 Topic 数和分区数更多,进而可以使得集群规模更大,减少维护成本。下图给出了 InLong TubeMQ 和 Kafka、Pulsar 的全方位对比:
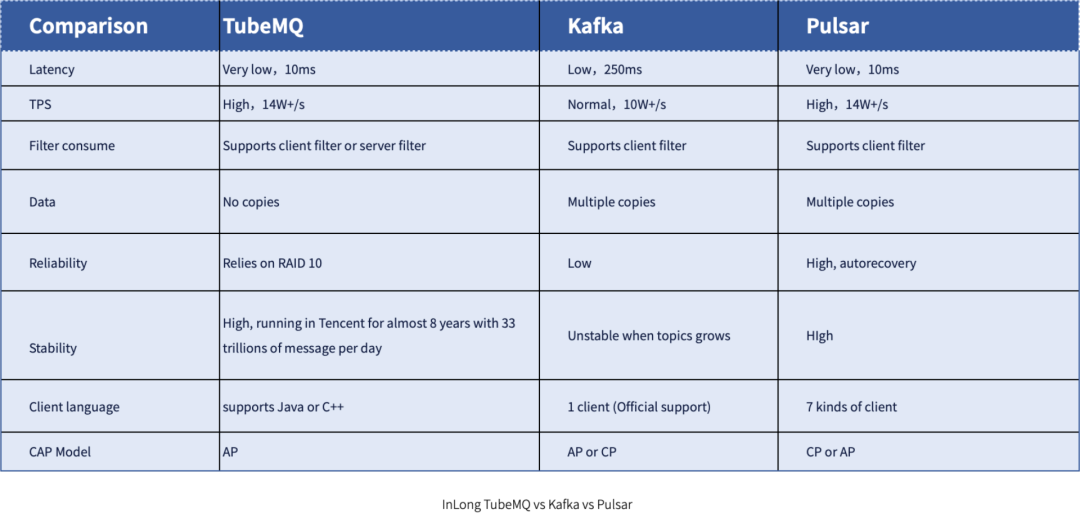
当然,在整个 Apache InLong 的架构中,由于对消息队列的支持完成了插件化,InLong TubeMQ 并不是完全和系统耦合,而是作为一种可选服务提供给社区用户。用户可根据开发和使用经验,选择其它消息队列服务,比如 Apache Pulsar 和 Apache Kafka。
随着 Apache InLong 的用户和开发者逐渐增多,更丰富的使用场景和低成本运营诉求越来越强烈,其中,InLong 全链路增加 Transform(T)的需求反馈最多。为了支持该能力,InLong 实现了基于 Apache Flink SQL 的 InLong Sort ETL 方案。首先,基于 Apache Flink SQL 主要有以下方面的考量:
Flink SQL 拥有强大的表达能力带来的高可扩展性、灵活性,基本上 Flink SQL 能支持社区大多数需求场景。当 Flink SQL 内置的函数不满足需求时,我们还可通过各种 UDF 来扩展。
Flink SQL 相比 Flink 底层 API 实现开发成本更低,只有第一次需要实现 Flink SQL 的转换逻辑,后续可专注于 Flink SQL 能力本身的构建,比如扩展 Connector、自定义函数 UDF 等。
一般来说,Flink SQL 将更健壮、运行也将更稳定。原因在于 Flink SQL 屏蔽了 Flink 底层大量的细节,有强大的社区支持,并且经过大量用户的实践。
对用户来说,Flink SQL 也更加通俗易懂,特别是对使用过 SQL 用户来说,使用方式简单、熟悉,这有助于用户快速落地。
对于存量实时任务的迁移,如果其原本就是 SQL 类型的任务,尤其是 Flink SQL 任务,其迁移成本极低,部分情况下甚至都不用做任何改动。
基于 Apache Flink SQL 的 InLong Sort ETL 方案,目前已支持 13 种常见的 Data Node,用户也可以基于该方案快速扩展新的 Extract Node 和 Load Node。另外,除了和 InLong Manager/Dashboard 搭配使用,提供全链路数据集成服务(称之为标准架构),InLong Sort 也支持独立运行(称之为轻量化架构),只需要准备 Flink 环境和 InLong Sort,就可以快速完成小规模数据集的 ETL 处理。InLong Sort 整体的技术方案可以见下图:

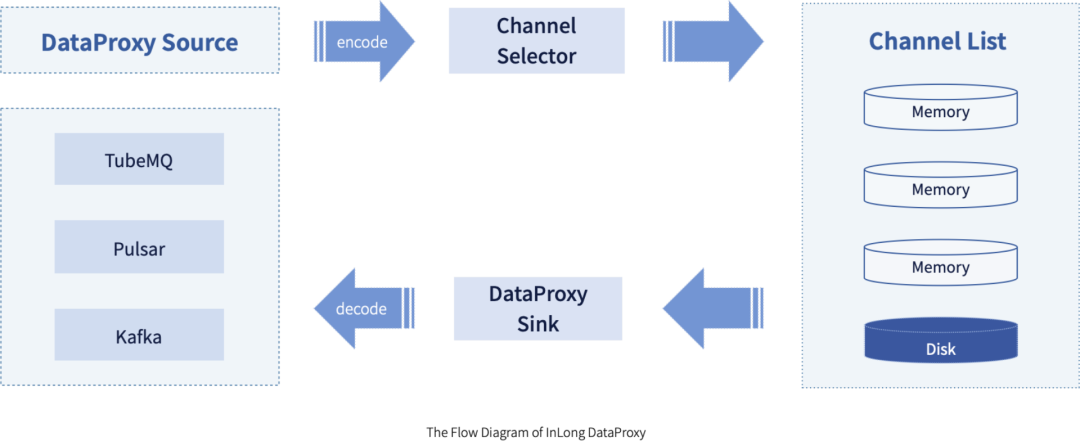
相比较其他数据集成解决方案,InLong 架构最明显的区别,在数据采集和消息队列中间,多了一个叫做 DataProxy 的服务。InLong DataProxy 主要有连接收敛、路由、数据压缩和协议转换等作用。DataProxy 充当了 InLong 采集端到消息队列的桥梁,当 DataProxy 从 Manager 模块拉取数据流元数据后,数据流和消息队列 Topic 名称对应关系也就确定了。当 DataProxy 收到消息时,会首先发送到 Memory Channel 中进行压缩,并使用本地的 Producer 往后端 Cache 层(即消息队列)发送数据。当消息队列异常出现发送失败时,DataProxy 会将消息缓存到 Disk Channel,也就是本地磁盘中。InLong DataProxy 整体架构基于 Apache Flume,扩展了 Source 层和 Sink 层,并对容灾转发做了优化处理,提升了系统的稳定性。下图为 DataProxy 数据处理流程:
InLong Audit 是独立于 InLong 的配套服务,主要用于对 InLong 全链路的 Agent、DataProxy、Sort 模块的入条数、入流量、出条数、出流量等进行实时审计对账,查看数据流是否有丢失或者重复,方便快速定位数据和服务异常。目前 InLong Audit 对账的粒度有分钟、小时、天三种粒度。InLong Audit 的整体架构图,可以参考下方:
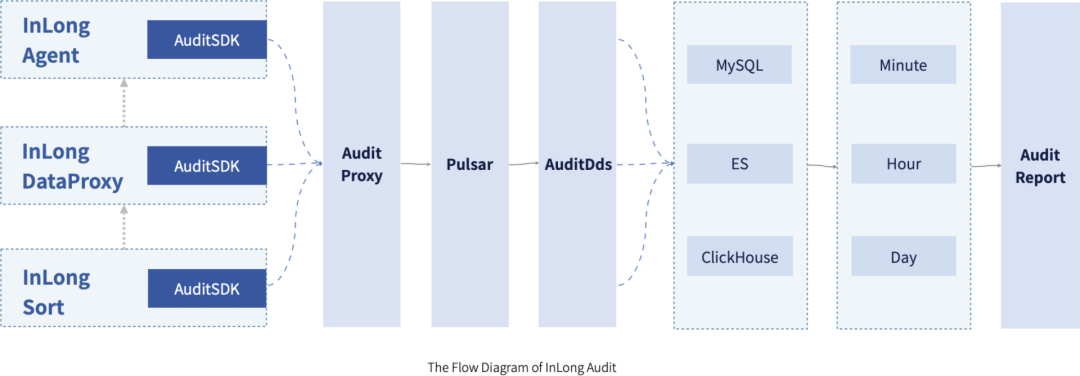
在整个 InLong Audit 审计流中,审计 SDK 嵌套在需要审计的子系统中,在数据流级别进行数据埋点,并将审计结果发送到审计接入层。审计接入层将审计数据写到 MQ ( Kafka 或者 Pulsar) 的专门的审计 Topic 中,审计分发服务(AuditDds)消费 MQ 的审计数据,并将审计数据写到 MySQL/Elasticsearch/ClickHouse。在接口层,提供多个时间粒度将 MySQL/Elasticsearch/ClickHouse 的数据进行封装,向前端页面展示、审计对账等提供对账查询服务。
"InLong 社区专注于为海量数据打造统一的、一站式的数据集成框架,帮助企业简化数据的接入、ETL 和分发过程”,Apache InLong PMC Chair 张超表示,“InLong 的毕业,标志着一个开放、多元、成熟的开源社区成功建立。感谢所有帮助过项目的所有导师、开源社区、贡献者等, 在未来的征程中,项目将继续践行 Apache Way,通过社区开发者的共同努力,助力企业数字化转型”。
上一个十年,最主流的大数据平台主要面向的场景是对企业离线数据的统一汇聚和分析洞察,但无法满足交互型业务场景 (OLTP) 和新一代的运营分析 (Operational Analytics) 对来自业务系统的实时数据的诉求。实时数据怎么来?常见的方案有 API 集成,ETL,ESB,以及 Kafka 等。这些方案都有哪些优缺点?新的十年,实时数据架构技术又有什么革新?6 月 29 日(周三)Tapdata 创始人唐建法与多位来自数据库厂商、头部企业客户、投资机构的嘉宾进行探讨与分享,期待您的参与。扫码报名 ↓↓

点个在看少个 bug 👇