葛笑雨:应用于智能体(Agent)的空间物理定性推理技术
近年来人工智能技术突飞猛进,越来越多的机器人正在走进我们的世界。与人类一样,机器人在执行日常任务时往往需要具备一定的空间物理推理能力。具备这种能力不仅使机器人可以完成指定任务,更能让他们避免在执行任务时作出对人类有潜在危害的行为。
空间物理推理是重要且有趣的领域。近日,在雷锋网 AI 研习社公开课上,澳大利亚国立大学葛笑雨博士就带领大家认识定性物理推理并感受其中的乐趣。公开课回放视频网址:http://www.mooc.ai/open/course/531
葛笑雨:Dorabot 算法团队负责人,澳大利亚国立大学博士,计算机科学系人工智能专业,导师 是 Jochen Renz,主要研究方向为空间物理推理,研究成果在 IJCAI、AAAI、ECAI、KR 上发表过。
分享主题:应用于智能体(Agent)的空间物理定性推理技术
分享提纲:
1. 空间物理推理为什么重要
2. 空间物理推理的背景与现状
3. 定性空间物理推理的未来
4. AI Birds 人工智能比赛 (www.aibirds.org)
5. 在机器人领域的实践 (Dorabot 相关)
雷锋网 AI 研习社将其分享内容整理如下:
我们本次的主题为:智能体(Agent)的空间物理推理。智能体,英文名是 Agent,它可以使用一些人工智能算法做一些事情,通过它自己的感知、规划与环境进行交互。空间物理推理,指的则是通过我们观测到的空间和物理信息推出一些有用的信息。
大家都知道,很多术语原生词都为英文,由于时间紧迫以及为了保证讲述的准确性,因此后面都使用英文 PPT。
我们今天的话题聚焦于 Motivating。首先,探讨一下为什么我们需要空间物理推理?
包括机器人等硬件形体的 AI Agent 正逐渐走入我们的生活,它以前一般都存在于软件中,对现实造成的影响不大,但是进入现实生活中会对我们的生活造成影响,一旦出现一些 bug 或者不能完整地理解它们所处的环境,就可能做出一些危害人类的行为。而我们现实世界到处充满了空间与物理元素,我们平时做的一些例如搬东西、打包行李以及倒水倒酒等事情,都需要对空间与物理具备处理能力,而机器人一旦进入现实世界,也需要具备这种空间物理处理能力。
问大家一个问题:在解决这些问题时,你们是怎么思考的呢?
有一种方法是在脑海里进行仿真、推演、想象。看右边这张定滑轮的示意图,当我用手拉起这根线,大家就会想下面这个箱子会怎么动。这个时候我们就在进行仿真,会想:当我这根线拖动时,这个轮子就会上来,下面和最下面的轮子也都会上来,最后箱子也跟着上来了。
基于这种观察,这就形成了一个理论:我们人脑中也许存在一种噪声牛顿仿真器(Nosiy Newtonian Simulator)。每当我们进行推理的时候,我们就会使用它。
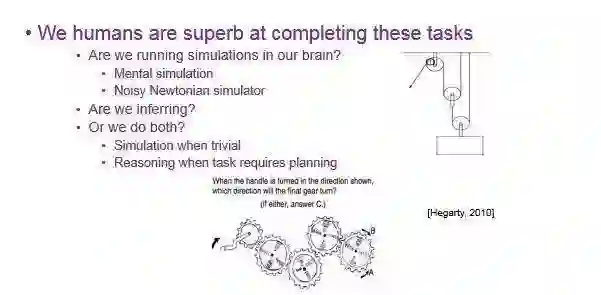
当情况变得复杂时,我们会怎么做?大家可以看下 PPT 下方这个图——齿轮,当人去摇动前面的杆,右边的齿轮会怎么转动呢?顺时针还是逆时针?遇到这个问题,我们就会进行推理,拿出手、笔和脑子去推算齿轮会怎么动。Hegarty 就提出了一个理论让这两种方式完美融合在一起。
当一个机器人来到这个世界,需要具备什么能力?
首先,它要理解世界的空间和物理性质,之后,才能理解空间上的变化,而这些变化,往往又是通过物理交互所产生的。最后,它需要知道动作执行后的结果。
举个例子,搭积木搭成了塔时,如果要在塔上放一个方块,这个方块对这个塔会有什么影响?我们必须先理解方块和塔所组成的结构的性质以及放这个动作所能产生的空间上的变化,这样我们才能预测到方块放下去会对塔有什么影响。
在最近几年,学术界一直在推动 Intelligent Physical Systems(在这里我们直接使用机器人一词)。首先机器人必须是安全的,我们才允许它执行动作,如果你站在它旁边影响了它的执行路径,它就有可能把你伤到,那就要求它们必须知道它们的目标造成的结果。再者,我们的世界是连续的,存在无限的动作,例如当我们要让机器人将水放到桌子上,我们就需要给它放置的坐标,而这个坐标的可能性也是无限的。此外,机器人的感知是不完美的,因此机器人一旦发现做出的动作与预期的不一样,它就需要调整它的世界观。
定性物理在 AI 出现的时候就出现了。研究者用定性化的语言去描述各种物理、空间问题。到 90 年代末渐渐沉寂。
然而,现在学术界为什么又对这个感兴趣?因为我们当下这个时代,硬件和机器学习技术都在飞速发展,越来越多机器人被应用于工业行业,也有一部分进入民用。商业化的推动和技术的发展,让我们对定性物理这个非常难的领域又有了期待。
定性物理,就是用一种符号化的语言去表达物理系统,从而我们就可以用一些算法和验证方法去预测这个系统的行为。当这种符号化语言完善后,我们就可以预测系统在未来任何一个时间发生的行为——预测这个系统一定不会做什么事情,它就不会做什么事情。
为什么物理推理是一个非常难的问题?
首先是它的计算复杂性非常高,举几个例子:
第一个跟踪光线。在空间的某一点打出一束光,假设空间有镜片、障碍物,光会发生折射与反射,当我们想预测光在未来某一时间点的位置时,这个问题就是一个图灵完全的问题,即我们现在可以通过让光线来模拟图灵机。

第二个桌球问题。这也是一个图灵完全问题,用桌球来模拟图灵机——曾被数学证明过,当这个球打出,假设球之间发生的是无损失的碰撞,预测它将落到哪个位置。它有一个理论 Ergodic motion,只要给这个球无限的时间,当这个球不停地动,轨迹会布满这个台球桌。力越大,走得越多,覆盖范围越大,球在这里是没有体积的点。当然,球的初始方向选择不当也会出现循环的轨迹。
第三个物理推理问题,比如我有一个学弟就曾证明出来 Angry Birds 是一个 NP-hard 问题。
在这三个问题中,我们做个预测都这么难,那么在无限多的动作里选择一个动作做规划和推理,就是一个更加难的问题了。
下图中,左上图是一个认知科学的实验,黑色边界是一个打不透的墙,里面有一个小球往右下运动,会先到黑墙还是红墙?我们都知道最终会到红墙,但是如果用仿真的方法(预测),它们会持续随机采样,虽然大多数情况下结果都会是——红墙,但是一旦我在墙上开一个小孔,随机采样就不一定成功。

右上图是一位专家解决这个球在空间中运动的问题。给定轨迹后,球最终会是怎样的轨迹和状态?在定性物理中,我们会把空间离散化变成几个区域(右下图),小箭头指球在这个区域可以前进的方向,同时,我们也有自己的一套规则和求状态的描述来知道系统去推理球的运动方向,在这里不展开,有兴趣可以参考一下 1980 年 Forbus 的这篇文章。左下图是在一个 3D 高尔夫球场,预测球的运动的问题,这是我最近比较关注的问题。
还有一个案例是,Forbus 曾经用约束力学(Constrained Mechanics)去描述钟表,用符号化的推理和表达模拟时钟的走动。
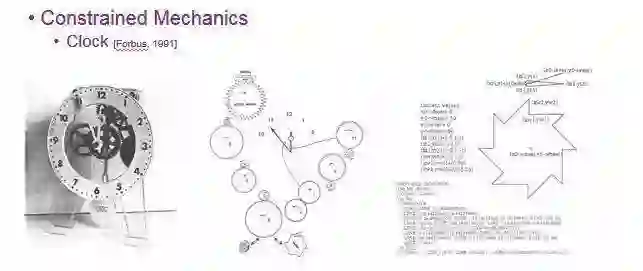
他当时使用非常古老的扫描仪将零件扫描(如中间图所示),每个齿轮都有自己的 ID 和全描述(最右图),可以通过描述去推理时钟是怎么转动的。在工业应用中,定性物理推理往往被用来定性的分析一个复杂物理系统的性质。其能快速得出初步的定性的结果。根据结果,再决定是否要进一步进行严密的仿真。
稍微讲一下表达方法。
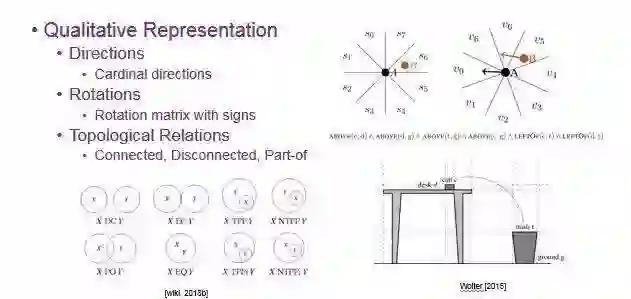
首先,方向可以离散化和符号化,提到方向关系问题,在左图中会说 B 在 A 的 S6 方向,而右图中会说 B 在 A 的右边。同时,旋转和运算都可以符号化,这样就能在不能求到精确值的情况下,依旧能得到比较好用的解。此外,拓扑结构符号化后,可以描述两个空间物体的相离、相交或者包含等拓扑关系。比如右图描述 2D 空间,机器人想将易拉罐扔到垃圾桶,我们同样采取了空间离散化来进行表达,另外,我们通过对这个场景进行描述,能够做模型追踪,还能进行形式化验证机器人对所处的环境所造成的影响。
接下来讲推理。
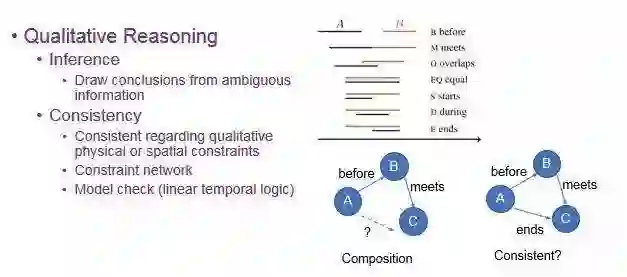
第一个就是字面的推理,指在有限、不精确的信息里面,我们还能找到一些比较有用的结果。
第二个是一致性,即探索空间中物体的关系是否真实,是否会有不正常的情况。左上图的案例是最简单的事件表达方法,before 指 事件 A 发生在事件 B 之前,meet 指 A、B 相邻发生,依次类推。右下图,说的就是从 A 和 B 的关系和 B 和 C 的关系中推出 A 和 C 的关系。
上面讲的是定性物理,而对于物理推理,还有一个流派叫仿真推理(Simulation-based reasoning),它通过不停做仿真,用概率分布做采样,得到可接受的解。比如问到下面这个塔会向左倒还是向右倒的问题,我们的脑子就会不停做仿真、预测,最后得到答案。不过,这个方法还是存在很多问题的,仿真很难做到尽善尽美,根基就不太稳的话,仿真的结果就不能很精确。
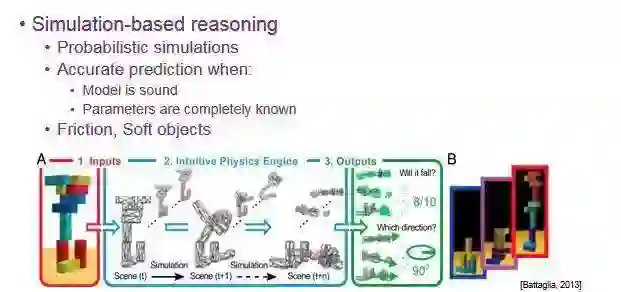
之前讲到很多图灵完全问题,就是指你给它输入,它会停机,我们无法在有限的时间里确定答案。
而当我们给这个问题设定一个时间限制的时候,图灵完全问题就会变成半图灵问题或者一个有效算法可以解决的问题。当我们遇到一个计算很复杂的问题,可以找出一个可被利用的结构,通过多项式算法或者估算的方式去解决。
提一下我们这个领域一直在研究的三个问题:
动作预测问题:比如打高尔夫球——打出第一杆怎么去预测球去哪。
感知:大家要注意视觉是感知的一种,感知也可以感知物体的物理性质。
规划:前两个问题解决后我们才能谈规划,需要对这个世界的感知、行为理解,最后需要一个算法从上面的行为中找解。
目前主流的物理推理包括以下四个:
第一个是仿真推理(Simulation-based reasoning)。在吴同学 2015 年的这篇论文中,探索用手推一下这个 Cube,物体会发生怎样的运动的问题。实验中,系统首先有一套深度学习去学习它的物理性质,再去(不停)做仿真,直到找到一个概率很高的结果做预测。最后通过真正去推这个 Cube 得到真实结果,去跟之前的预测做比较。
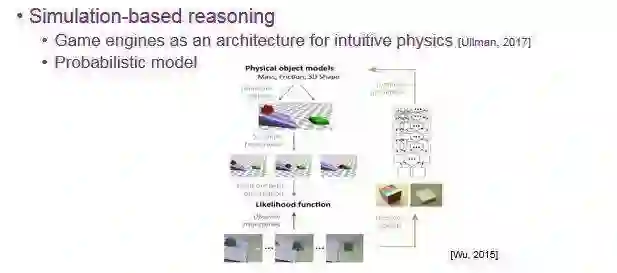
第二个是迁移学习(Transfer learning),即在仿真中进行深度学习,我对这个领域我不太了解就不多说,不过我建议有需要的同学使用 Mujoco 这个物理仿真器。
第三个是联合任务规划(Combined-task planning),它跟物理推理没什么关系,但是跟机器人相关。它指在抽象层面用定性物理去找到定性的解,发现行为可执行后,就会用数字模型计算数值的解。
第四个是定性物理推理(Qualitative physical reasoning),这也是我主要在研究的领域。领域背景在此不多做介绍,大家感兴趣可以去看一下 Davis 的这篇《物理推理调查》(Physical reasoning survey)。而我之前做的研究主要是把物理推理用到感知、运动、稳定性和解释物理运动这些方面。比如下图中我动了一下木块,要找出到底动了哪一块,就可以使用这个方法,推理出来所有有可能被动过的木块。

研究过程中,我总结了一些方法论:
第一,给定一个问题,去设计一个好的定性表达方式,它需要要保证能涵盖解,同时,该表达方式的解跟其他的有误导的解应该是可区别的。
第二,表达方式会形成一个约束网络,在这个网络上进行推理,就能拿到一套定性的解,但是解还是太模糊。
第三,在被缩减的解空间进行数值计算,最终得到具体的解。
第四,得到解之后,还需要根据在现实环境中的反馈对模型进行更改。
为了鼓励世界范围内的研究者一起研究该领域,我们 2012 年开始举办 AI Birds 国际人工智能比赛。
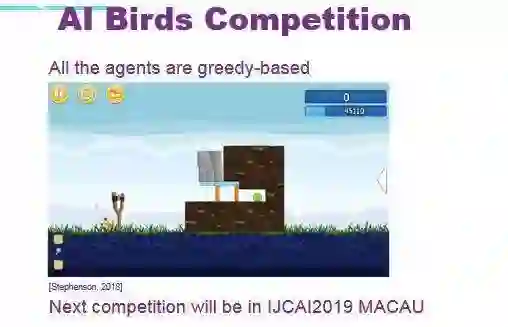
我们会提前几天去设置游戏关卡,关卡中就涉及到物理推理的因素。此外,我们还做了一套服务器,所有的 AI 都部署在独立的笔记本上,AI 只能从服务器获得游戏截图。而游戏动作包括发射小鸟,以及点击屏幕触发小鸟的技能。
六年以来,共有三十几个国家的四十几个参赛队伍参与比赛,其中表现最佳的几个参赛队伍使用的方法包括:
逻辑编程(Logic programming):用符号化的语言描述场景再进行符号化的推理,找出获胜策略。
调试法(Heuristics-based):其中一个韩国队伍使用的调参方法,最后调的参数非常好,取得了不错的成绩。
仿真(Simulation):因为游戏的物理引擎是不被公布的,参赛队伍是不知道参数的,因此有一些参赛队伍自己用 Box2D 写了一个类似的环境,通过自己的仿真去玩,但是 因为游戏中 Action 的可能性非常多,他们无法很有效的找到最佳 Action。
机器学习(Machine learning):2012/2013 年的时候深度学习还没有起飞,大家普遍使用经典机器学习方法。
至今所有的参赛选手的 AI 都是贪心的(greedy-based),意思是说他们在当前时刻只做对当前最有益的事情。例如,面对图中的关卡,贪心的算法会采用获得当前最高得分的方法,即尽量多的破坏当前障碍物。但是蓝色的冰一旦被打掉,就会掉下来堵住路,使他们最终无法打到猪。而可取的方式是,他们可以放弃掉蓝色的小鸟,用黄色的小鸟打掉木头,再打掉猪。
我们这个比赛明年会在澳门举行,欢迎大家参加。
在 ANU 的物理推理研究组,主要做三件事情:
感知:从多个视图的照片中,找出真正的结构。
知识表示和推理:例如我一个师弟 2018 年发表论文讲怎么统一空间表达法;我近一年则关注在 3D 空间中做一些理论去描述空间物理运动。
物理、空间规划:比如堆盘子的实验。
重点说一下我目前所在公司 Dorabot 的研究和开发。我是算法研究负责人,下面为四个我认为比较有意思的方向:
第一个方向,对机器人进行形式化验证。我们将一套空间表达方法逻辑化,对机器人进行验证,以保证机器人不会做出异常行为。
第二个方向,多机器人协作。比如,探索机器人怎么从类型不同传感器的输入找出它们所处世界的真实样貌,实现机器人本地协作,以及在 2D 仿真都是元胞机(图灵完全)的情况下,怎么解决 3D 环境中多机器人的仿真、规划和协作等问题。
第三个方向,感知问题。包括从原始点云检测空间实体,比如机器人洗盘子,看到厨房一堆碗,需要分清哪个是盘子,哪个是抹布,这就需要使用深度感知器去观察点云;以及通过实质性空间变化去跟踪空间实体。
第四个方向,规划。比如对将箱子装入集装箱、拖车或轮船等地方的动作进行规划,以及对静态和动态稳定性的考量。
上面四个方向都是我们公司在研发的问题,感兴趣的同学可以加入我们这个算法团队。
你可以选择我们公司的研究和开发方向之一,将其进行形式化及建模,比如说将这些话题形式化成 SAT、优化、搜索以及机器学习等问题,找到合理建模方式后,看看有什么建议的算法,来跟我进行交流。你可以通过邮件 dream@dorabot.com 跟我联系。
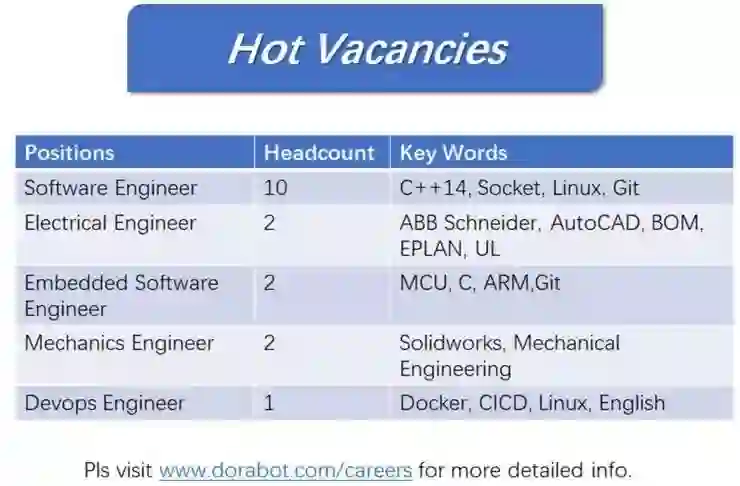
另外我们公司急需以下岗位,欢迎大家的加入。
以上就是本期嘉宾的全部分享内容。更多公开课视频请关注雷锋网 AI 研习社社群或点击阅读原文。关注微信公众号:AI 研习社(okweiwu),可获取最新公开课直播时间预告。





