智能体到底是什么?这里有一篇详细解读

来源:机器人圈
概要:根据我们希望实现的目标以及衡量其成功的标准,我们可以采用多种方法来创建人工智能。
根据我们希望实现的目标以及衡量其成功的标准,我们可以采用多种方法来创建人工智能。它涵盖的范围极其广泛,从自动驾驶和机器人这样非常复杂的系统,到诸如人脸识别、机器翻译和电子邮件分类这些我们日常生活的常见部分,都可以划为人工智能的领域范畴之内。
阅读完下面这篇文章,也许你就会了解真正创建人工智能所需要的东西有哪些。
《你真的知道什么是人工智能吗》
https://hackernoon.com/so-you-think-you-know-what-is-artificial-intelligence-6928db640c42
你所采用的路径将取决于你的AI的目标是什么,以及你对各种方法的复杂性和可行性的理解程度。在本文中,我们将讨论那些被认为对科学发展更为可行和普遍的方法,即对理性/智能体设计的研究。
什么是智能体?
通过传感器感知其周围环境
通过执行器对其进行操作
它将在感知、思考和行动的周期中往返运行。以人类为例,我们是通过人类自身的五个感官(传感器)来感知环境的,然后我们对其进行思考,继而使用我们的身体部位(执行器)去执行操作。类似地,机器智能体通过我们向其提供的传感器来感知环境(可以是相机、麦克风、红外探测器),然后进行一些计算(思考),继而使用各种各样的电机/执行器来执行操作。现在,你应该清楚在你周围的世界充满了各种智能体,如你的手机、真空清洁器、智能冰箱、恒温器、相机,甚至你自己。
什么是Intelligent Agent?
Intelligent Agent是这样一种智能体,给定它所感知到的和它所拥有的先验知识,以一种被期望最大化其性能指标的方式运行。
性能指标定义了智能体成功的标准。
此类智能体也被称之为理性智能体(Rational Agent)。智能体的合理性是通过其性能指标,其拥有的先验知识,它可以感知的环境及其可以执行的操作来衡量的。
这个概念是人工智能的核心。
Intelligent Agent的上述属性通常归结于术语PEAS(Performance, Environment, Actuators and Sensors),其代表了性能、环境、执行器和传感器。所以,以一辆自动驾驶汽车为例,它应该具有以下PEAS:
性能:安全性、时间、合法驾驶、舒适性。
环境:道路、其他汽车、行人、路标。
执行器:转向、加速器、制动器、信号、喇叭。
传感器:相机、声纳、GPS、速度计、里程计、加速度计、发动机传感器、键盘。
为了满足现实世界中的使用情况,人工智能本身需要有广泛的Intelligent Agent。这就引入了我们所拥有的智能体类型及环境的多样性。接下来我们一起来看看。
环境类型
如果想要设计一个合理性智能体,那么就必须牢记它将要使用的环境类型,即以下几种类型:
完全可观察和部分可观察:
如果是完全可观察的,智能体的传感器可以在每个时间点访问环境的完整状态,否则不能。例如,国际象棋是一个完全可观察的环境,而扑克则不是。
确定性和随机性:
环境的下一个状态完全由当前状态和由智能体接下来所执行的操作决定的。(如果环境是确定性的,而其他智能体的行为不确定,那么环境是随机性的)。随机环境在本质上是随机的,不能完全确定。例如,8数码难题(8-puzzle)这个在线拼图游戏有一个确定性的环境,但无人驾驶的汽车没有。
静态和动态:
当智能体在进行协商(deliberate)时,静态环境没有任何变化。(环境是半动态的,环境本身并没有随着时间的流逝而变化,但智能体的性能得分则是会发生相应变化的)。另一方面,动态环境却改变了。西洋双陆棋具有静态环境,而扫地机器人roomba具有动态环境。
离散和连续:
有限数量的明确定义的感知和行为,构成了一个离散的环境。例如,跳棋就是离散环境的一个范例,而自动驾驶汽车则需要在连续环境下运行。
单一智能体和多智能体:
仅有自身操作的智能体本身就有一个单一智能体环境。但是如果还有其他智能体包含在内,那么它就是一个多智能体环境。自动驾驶汽车就具有多智能体环境。
还存在着其他类型的环境,情景和顺序,已知和未知,这些定义了智能体的范围。
智能体的类型
一般有4种类型的智能体,根据智能水平或其能够执行任务的复杂性不同而区分。所有类型都可以随着时间的推移改进性能并产生更好的操作。这些可以概括为学习智能体(learning agents)。
单反射性智能体(Simple reflex agents)
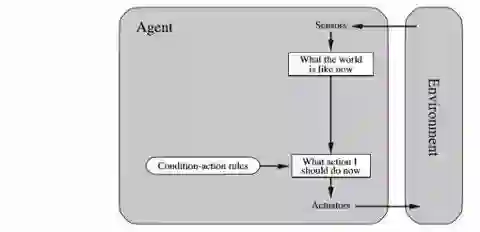
这些选择操作仅基于当前状态,忽略感知历史。
如果环境完全可观察到,或者正确的行为是基于目前的感知,它们才能工作。
基于模型的反射性智能体(Model-based reflex agents)
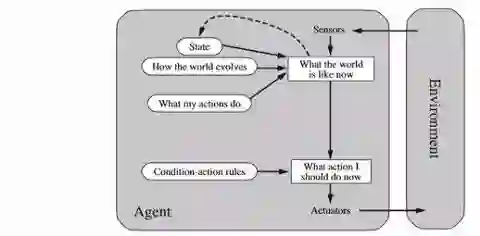
智能体跟踪部分可观察的环境。这些内部状态取决于感知历史。环境/世界的建模是基于它如何从智能体中独立演化,以及智能体行为如何影响世界。
基于目标的智能体(Goal-based agents)
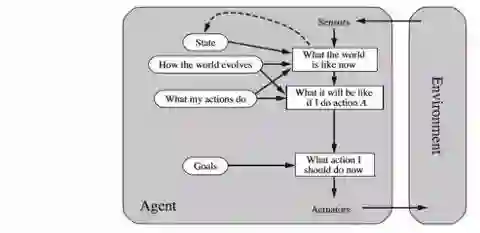
这是对基于模型的智能体的改进,并且在知道当前环境状态不足的情况下使用。智能体将提供的目标信息与环境模型相结合,选择实现该目标的行动。
基于效用的智能体(Utility-based agents)
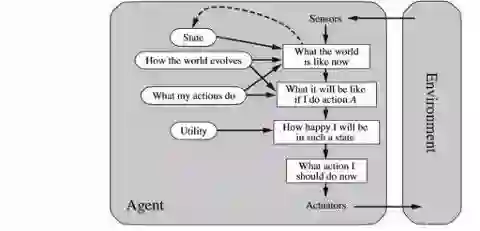
对基于目标的智能体进行改进,在实现预期目标方面有所帮助是不够的。我们可能需要考虑成本。例如,我们可能会寻找更快、更安全、更便宜的旅程到达目的地。这由一个效用函数标记。效用智能体将选择使期望效用最大化的操作。
通用智能体,也称为学习智能体,由阿兰•图灵提出,是目前人工智能系统中最先进的方法。
上述所有智能体可以被概括为学习智能体以产生更好的操作。
学习智能体(Learning Agents)
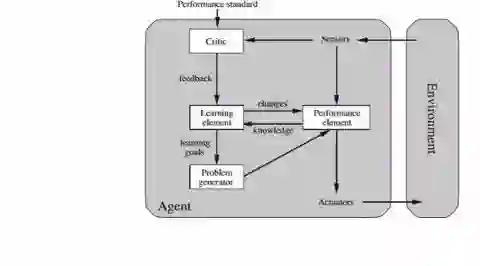
学习要素:负责改进
性能要素:负责选择外部行为,这是截至目前我们通常认为的智能体。
评论:关于确定的性能标准,智能体做得如何?
问题生成器:允许智能体探索。
内部状态表示
随着智能体的复杂化,内部结构也越来越复杂。它们存储内部状态的方式也发生变化。由于其性质,简单的反射型智能体不需要存储状态,其他类型则需要。下面的图像提供智能体状态的高级别表示,按表示能力增长顺序排列(从左到右)。

原子表示法(Atomic representation):
在这种情况下,状态存储为黑箱,即没有任何内部结构。例如,对于Roomba(机器人真空吸尘器),内部状态是已经进行了真空的补丁,您不必了解任何其他内容。如图所示,这种表示适用于基于模型和目标的智能体,并用于各种AI算法,例如搜索问题和对抗游戏。
因素化表示法(Factored Representation):
在这种表示中,状态不再是黑箱。它现在具有属性值对,也称为可以包含值的变量。例如,在找到一条路线时,你有GPS位置以及油箱中的油量值。这为问题增加了一个约束。如图所示,这种表示适用于基于目标的智能体,并用于各种AI算法,如约束满足(constraint satisfaction)和贝叶斯网络(bayesian networks)。
结构化表示法(Structured Representation):
在这种表示中,我们在变量/因子状态之间有关系,这在AI算法中引发逻辑。例如,在自然语言处理中,陈述是否在语句中包含对某人的引用,以及该语句中的形容词是否形容该人。这些陈述关系将决定这个陈述是否是讽刺的(sarcastic)。这是高级别的人工智能,用于一阶逻辑、基于知识的学习和自然语言理解的算法。
对于人工智能来说,这些理性智能体还有很多,这只是一个概述。正如你所知道的,理性智能体的设计研究是人工智能的重要组成部分,因为它在各种领域中有着广泛的应用。但是,这些智能体不能独立工作,他们需要一个人工智能算法来驱动它们。这些算法大多涉及搜索。很快,我就会写一些关于驱动理性智能体的AI算法,以及在AI中使用机器学习的文章。



