终结谷歌每小时20美元的AutoML!开源的AutoKeras了解下
机器之心报道
机器之心编辑部
谷歌的 AutoML 每小时收费 20 美元,是不是很肉疼?GitHub 上的一个开源项目为广大从业者带来了福音。这种名为 AutoKeras 的开源 Python 包为昂贵的 AutoML 提供了免费替代品。AutoKeras 使用高效神经网络自动架构搜索 ENAS,具有安装快速、运行简单、案例丰富、易于修改等优点,而且所有代码都是开源的!想要尝鲜的小伙伴可以了解一下。

每小时 20 美刀的 AutoML
Google AI 终于发布了 AutoML 的 beta 版,有人说这项服务将彻底改变深度学习的方式。
beta 版链接:https://cloud.google.com/automl/
谷歌的 AutoML 是机器学习工具中新的云软件集。它基于谷歌最先进的图像识别研究——神经网络自动架构搜索(Neural Architecture Search,NAS)。NAS 是一种在给定特定数据集中的算法,用于搜索在该数据集上完成特定任务的最优神经网络。AutoML 是一套机器学习的工具,可以让用户轻松地训练高性能的深度网络,而无需用户具备任何深度学习或人工智能方面的知识;你所需要的只是标签数据!谷歌将使用 NAS 为特定的数据集和任务找到最优网络。他们已经展示了该模型如何取得远优于手工设计网络的性能。
AutoML 完全改变了整个机器学习圈,因为对于许多应用程序来说,有了它就不再需要专业技能和专业知识了。许多公司只需要深度网络完成简单的任务,如图像分类。在这一点上,他们不需要招五个机器学习博士,只需要一个能处理数据迁移和数据组织的人即可。
那么 AutoML 会是让所有公司或者个人轻松做人工智能的「万能钥匙」吗?
没那么快!
在计算机视觉中使用谷歌的 AutoML,每小时将花费 20 刀。简直疯了!除非花钱去试,不然你都无法确定 AutoML 是否真的比你自己手工设计的网络更准确。有趣的是,在谷歌以此盈利之前,无论在谷歌还是 AI 社区,人们都更倾向于开源,将知识分享给每一个人。
而谷歌的 AutoML 就将败在「开源」上。
帮你省钱的开源 AutoKeras
AutoKeras 是一个由易用深度学习库 Keras 编写的开源 python 包。AutoKeras 使用 ENAS——神经网络自动架构搜索的高效新版本。AutoKeras 包可通过 pip install autokeras 快速安装,然后你就可以免费在准备好在的数据集上做你自己专属的架构搜索。
因为所有的代码都是开源的,所以如果你想实现真正的自定义,你甚至可以利用其中的参数。所有都来自 Keras,所以代码都很深入浅出,能帮助开发人员快速准确地创建模型,并允许研究人员深入研究架构搜索。
AutoKeras 具备一个好的开源项目该有的一切:安装快速,运行简单,案例丰富,易于修改,甚至可以看到最后 NAS 找到的网络模型!偏爱 TensorFlow 或 Pytorch 的用户可点击以下链接:
https://github.com/melodyguan/enas
https://github.com/carpedm20/ENAS-pytorch
用户可以尝试利用 AutoKeras 或其他任何实现方式替代 AutoML,它们的价格便宜得离谱。或许谷歌正暗中改进 AutoML,与各种开源方法拉开差距,但 NAS 模型的表现与手工设计的模型差距很小,付出这么高的代价真的值得吗?
知识应该是开源的
总体来看,深度学习和 AI 是一种非常强大的技术,我们不应该为其设置如此之高的成本壁垒。没错,谷歌、亚马逊、苹果、Facebook 及微软都需要赚钱才能在竞争中存活下来。但现在,研究论文是公开的,我们的深度学习库可以快速复制这些方法,在公开内容唾手可得的情况下,为用户设置使用障碍是没有意义的。
这里有一个更严重的潜在问题:知识本身正在被隐藏。AI 领域最新趋势中非常可圈可点的一点就是:许多研究社区都决定在 arXiv 等网站上快速、公开地发表自己的研究成果,以与其他社区分享并获得反馈。此外还有一个趋势变得越来越明显,即在 Github 上发布研究代码以供复制以及在研究和实际应用中实现算法的进一步应用。然而,我们仍然能看到这种研究受困于高高的成本壁垒。
分享有助于每个人知识的增长和科学的进步。知识应该是开源的,这一点毋庸置疑,而且造福人人。
项目链接:https://github.com/jhfjhfj1/autokeras
AutoKeras 技术解析
相比于 AutoML,AutoKeras 采用的架构搜索方法是一种结合了贝叶斯优化的神经架构搜索。它主要关注于降低架构搜索所需要的计算力,并提高搜索结果在各种任务上的性能。以下我们将从神经架构搜索到贝叶斯优化介绍 AutoKeras 背后的技术,并期望读者们能尝试使用这样的开源技术完成各种优秀的应用。
神经架构搜索(NAS)是自动机器学习中一种有效的计算工具,旨在为给定的学习任务搜索最佳的神经网络架构。然而,现有的 NAS 算法通常计算成本很高。另一方面,网络态射(network morphism)已经成功地应用于神经架构搜索。网络态射是一种改变神经网络架构但保留其功能的技术。因此,我们可以利用网络态射操作将训练好的神经网络改成新的体系架构,如,插入一层或添加一个残差连接。然后,只需再加几个 epoch 就可以进一步训练新架构以获得更好的性能。
基于网络态射的 NAS 方法要解决的最重要问题是运算的选择,即从网络态射运算集里进行选择,将现有的架构改变为一种新的架构。基于最新网络态射的方法使用深度强化学习控制器,这需要大量的训练样例。另一个简单的方法是使用随机算法和爬山法,这种方法每次只能探索搜索区域的邻域,并且有可能陷入局部最优值。
贝叶斯优化已被广泛用于基于观察有限数据的寻找函数最优值过程。它经常被用于寻找黑箱函数的最优点,其中函数的观察值很难获取。贝叶斯优化的独特性质启发了研究者探索它在指导网络态射减少已训练神经网络数量的能力,从而使搜索更加高效。
为基于网络态射的神经架构搜索设计贝叶斯优化方法是很困难的,因为存在如下挑战:首先,其潜在的高斯过程(GP)在传统上是用于欧氏空间的,为了用观察数据更新贝叶斯优化,潜在高斯过程将使用搜索到的架构和它们的性能来训练。然而,神经网络架构并不位于欧氏空间,并且很难参数化为固定长度的向量。
其次,采集函数需要进行优化以生成下一个架构用于贝叶斯优化。然而,这个过程不是最大化欧氏空间里的一个函数来态射神经架构,而是选择一个节点在一个树架构搜索空间中扩展,其中每个节点表示一个架构,且每条边表示一个态射运算。传统的类牛顿或基于梯度的方法不能简单地进行应用。第三,网络态射运算改变神经架构的的一个层可能会导致其它层的很多变化,以保持输入和输出的一致性,这在以前的研究中并没有定义。网络态射运算在结合了跳过连接的神经架构搜索空间中是很复杂的。
在 AutoKeras 作者提交的论文中,研究人员们提出了一种带有网络态射的高效神经架构搜索,它利用贝叶斯优化通过每次选择最佳运算来引导搜索空间。为应对上述挑战,研究者创建了一种基于编辑距离(edit-distance)的神经网络核函数。与网络态射的关键思路一致,它给出了将一个神经网络转化为另一个神经网络需要多少运算。此外,研究者为树形架构搜索空间专门设计了一种新的采集函数优化器,使贝叶斯优化能够从运算中进行选择。优化方法可以在优化过程中平衡探索和利用。此外,作者还定义了一个网络级态射,以解决基于前一层网络态射的神经架构中的复杂变化。该方法被封装成一个开源软件,即 AutoKeras,在基准数据集上进行评估,并与最先进的基线方法进行比较。
该论文的主要贡献总结如下:
结合网络态射提出了一种高效的神经架构搜索算法;
提出了利用神经网络内核的 NAS 贝叶斯优化、树结构采集函数的优化以及网络级的态射;
开发了一个开源软件 AutoKeras,基于本文提出的神经架构搜索方法;
在基准数据集上运行了大量试验来评估该方法。
论文:Efficient Neural Architecture Search with Network Morphism

论文地址:https://arxiv.org/abs/1806.10282
虽然目前深度神经网络自动调参领域非常关注神经架构搜索(NAS),但现存的搜索算法通常面临计算成本高昂的困境。网络态射(Network morphism)在改变神经网络架构的同时保留它的功能,因此能在搜索过程中实现更有效的训练来帮助 NAS。然而,基于 NAS 的网络态射仍然在计算上比较昂贵,这主要因为对现有的架构选择合适的变形操作效率比较低。
众所周知,贝叶斯优化已经广泛应用于优化基于有限观察值的目标函数,这激励我们探索利用贝叶斯优化加速变形运算选择过程。本论文中提出了一种新颖的框架,它引入了神经网络核函数和树架构的采集函数最优化方法,并允许使用贝叶斯优化为高效的神经架构搜索引导网络态射。通过使用贝叶斯优化选择网络态射操作,搜索空间的探索会更加高效。此外,将这一方法精心包装成一个开源软件,即 AutoKeras,没有丰富机器学习背景的开发者也可以便捷地使用它。研究者已经对真实数据集做了密集的实验,并证明了开发的框架对于当前最优的基线模型有更优的性能。
研究过程中需要解决的第一个问题是:NAS 空间不是欧氏空间,它并不满足传统高斯过程的假设。由于架构包含的层级数和参数数量并不确定,因此向量化所有神经架构是不切实际的。此外,因为高斯过程是一种核方法,所以研究人员使用神经网络核函数以解决 NAS 搜索空间的问题,而不是直接向量化神经架构。核函数背后的原理可直观理解为将一个神经架构变形为另一个所需的编辑距离。
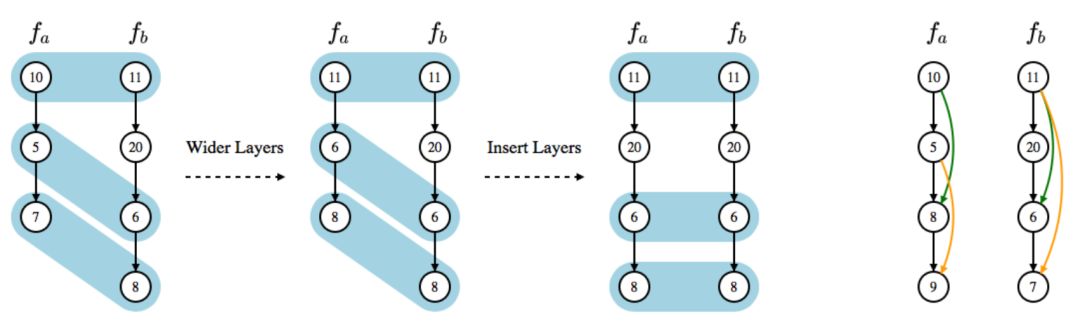
图 1:神经网络核函数
我们需要解决的第二个问题是采集函数(acquisition function)最优化。在欧氏空间上定义了传统采集函数,其优化方法不适用于通过网络态射进行的树架构搜索。因此本文提出一种优化树架构空间采集函数的新方法。

评估该方法有效性的结果如表 1 所示。我们的方法在所有数据集上的错误率最低。
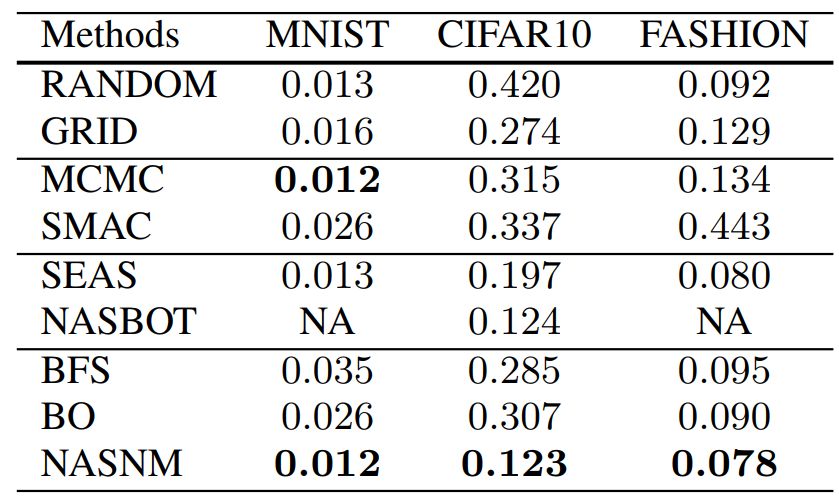
表 1:分类错误率

参考原文:https://towardsdatascience.com/autokeras-the-killer-of-googles-automl-9e84c552a319
本文为机器之心报道,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com