那些有用但不为大家所熟知的 Java 特性

本文最初发表于 Piotr Mińkowski 的个人站点 Medium 网站,经作者授权,由 InfoQ 中文站翻译分享。
在本文中,你将会了解到一些有用的 Java 特性,这些特性可能你之前没有听说过。这是我最近在阅读关于 Java 的文章时,才发现和整理的私人特性清单。我不会把重点放到语言方面,而是会放到 API 方面。
你喜欢 Java,想了解它最新的特性吗?如果是的话,你可以阅读我关于 Java 8 之后新特性的文章。接下来,在本文中你将会了解到八个不为大家熟知但是非常有用的特性。那我们开始吧!
我们都知道,在 Java 中有类型众多的集合。那么你听说过 DelayQueue 吗?它是一个特殊类型的 Java 集合,允许我们根据元素的延迟时间对其进行排序。坦白来讲,这是一个非常有意思的类。尽管 DelayQueue 类是 Java 集合的成员之一,但是它位于 java.util.concurrent 包中。它实现了 BlockingQueue 接口。只有当元素的时间过期时,才能从队列中取出。
要使用这个集合,首先,我们的类需要实现 Delayed 接口的 getDelay 方法。当然,它不一定必须是类,也可以是 Java Record。
public record DelayedEvent(long startTime, String msg) implements Delayed {public long getDelay(TimeUnit unit) {long diff = startTime - System.currentTimeMillis();return unit.convert(diff, TimeUnit.MILLISECONDS);}public int compareTo(Delayed o) {return (int) (this.startTime - ((DelayedEvent) o).startTime);}}
假设我们想要把元素延迟 10 秒钟,那么我们只需要在 DelayedEvent 类上将时间设置成当前时间加上 10 秒钟即可。
final DelayQueue<DelayedEvent> delayQueue = new DelayQueue<>();final long timeFirst = System.currentTimeMillis() + 10000;delayQueue.offer(new DelayedEvent(timeFirst, "1"));log.info("Done");log.info(delayQueue.take().msg());
对于上面的代码,我们能够看到什么输出呢?如下所示。

好吧,我承认这个 Java 特性对于你们中的大多数人来讲并没有太大的用处,但是,我对这个特性情有独钟……Java 8 对时间处理 API 做了很多的改进。从这个版本的 Java 开始,在大多数情况下,我们都不需要任何额外的库来处理时间了,比如 Joda Time。你可能想象不到,从 Java 16 开始,我们甚至可以使用标准的格式化器来表达一天中的时段,也就是“in the morning”或者“in the afternoon”。这是一个新的格式模式,叫做 B。
String s = DateTimeFormatter.ofPattern("B").format(LocalDateTime.now());System.out.println(s);
如下是我运行的结果。当然,你的结果可能会因时间不同而有所差异。

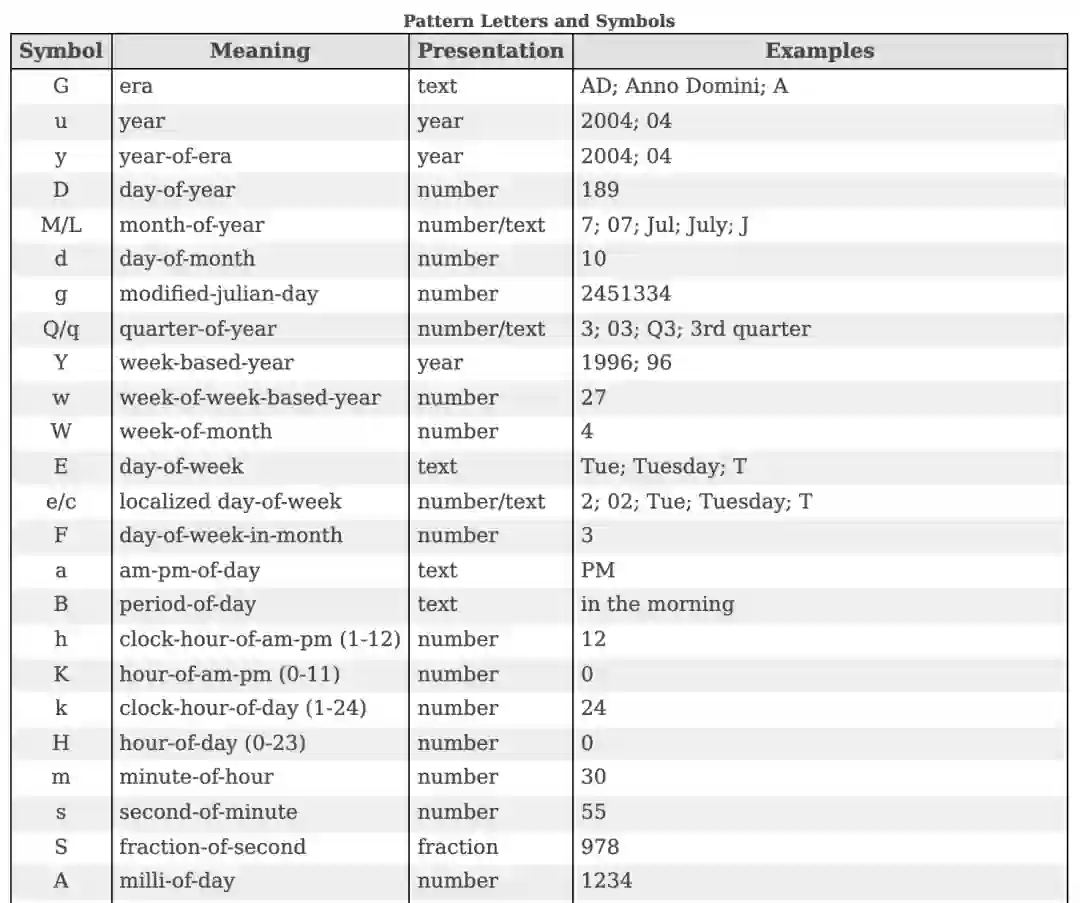
好,稍等……现在,你可能会问这个格式为什么叫做 B。事实上,对于这种类型的格式来讲,它不是最直观的名字。但也许下面的表格能够解决我们所有的疑惑。它是 DateTimeFormatter 能够处理的模式字符和符号的片段。我猜想,B 是第一个空闲出来的字母。当然,我可能是错的。
我认为,Java Concurrent 是最有趣的 Java 包之一。同时,它也是一个不太为开发者所熟知的包,当开发人员主要使用 web 框架的时候更是如此。我们有多少人曾经在 Java 中使用过锁呢?锁是一种比 synchronized 块更灵活的线程同步机制。从 Java 8 开始,我们可以使用一种叫做 StampedLock 的新锁。StampedLock 是 ReadWriteLock 的一个替代方案。它允许对读操作进行乐观的锁定。而且,它的性能比 ReentrantReadWriteLock 更好。
假设我们有两个线程。第一个线程更新一个余额,而第二个线程则读取余额的当前值。为了更新余额,我们当然需要先读取其当前值。在这里,我们需要某种同步机制,假设第一个线程在同一时间内多次运行。第二个线程阐述了如何使用乐观锁来进行读取操作。
StampedLock lock = new StampedLock();Balance b = new Balance(10000);Runnable w = () -> {long stamp = lock.writeLock();b.setAmount(b.getAmount() + 1000);System.out.println("Write: " + b.getAmount());lock.unlockWrite(stamp);};Runnable r = () -> {long stamp = lock.tryOptimisticRead();if (!lock.validate(stamp)) {stamp = lock.readLock();try {System.out.println("Read: " + b.getAmount());} finally {lock.unlockRead(stamp);}} else {System.out.println("Optimistic read fails");}};
现在,我们同时运行这两个线程 50 次。它的结果应该是符合预期的,最终的余额是 60000。
ExecutorService executor = Executors.newFixedThreadPool(10);for (int i = 0; i < 50; i++) {executor.submit(w);executor.submit(r);}
在 Java Concurrent 包中,有意思的并不仅仅有锁,另外一个很有意思的东西是并发累加器(concurrent accumulator)。我们也有并发的加法器(concurrent adder),但它们的功能非常类似。LongAccumulator(我们也有 DoubleAccumulator)会使用一个提供给它的函数更新一个值。在很多场景下,它能让我们实现无锁的算法。当多个线程更新一个共同的值的时候,它通常会比 AtomicLong 更合适。
我们看一下它是如何运行的。要创建它,我们需要在构造函数中设置两个参数。第一个参数是一个用于计算累加结果的函数。通常情况下,我们会使用 sum 方法。第二个参数表示累积器的初始值。
现在,让我们创建一个初始值为 10000 的 LongAccumulator,然后从多个线程调用 accumulate() 方法。最后的结果是什么呢?如果你回想一下的话,我们做的事情和上一节完全一样,但这一次没有任何锁。
LongAccumulator balance = new LongAccumulator(Long::sum, 10000L);Runnable w = () -> balance.accumulate(1000L);ExecutorService executor = Executors.newFixedThreadPool(50);for (int i = 0; i < 50; i++) {executor.submit(w);}executor.shutdown();if (executor.awaitTermination(1000L, TimeUnit.MILLISECONDS))System.out.println("Balance: " + balance.get());assert balance.get() == 60000L;
关于这个特性并没有什么大的故事。有时我们需要在十六进制的字符串、字节或字符之间进行转换。从 Java 17 开始,我们可以使用 HexFormat 类实现这一点。只要创建一个 HexFormat 的实例,然后就可以将输入的 byte 数组等格式化为十六进制字符串。你还可以将输入的十六进制字符串解析为字节数组,如下所示。
HexFormat format = HexFormat.of();byte[] input = new byte[] {127, 0, -50, 105};String hex = format.formatHex(input);System.out.println(hex);byte[] output = format.parseHex(hex);assert Arrays.compare(input, output) == 0;
假设我们想在排序的数组中插入一个新的元素。如果数组中已经包含该元素的话,Arrays.binarySearch() 会返回该搜索键的索引,否则,它返回一个插入点,我们可以用它来计算新键的索引:-(insertion point)-1。此外,在 Java 中,binarySearch 方法是在一个有序数组中查找元素的最简单和最有效的方法。
让我们考虑下面的例子。我们有一个输入的数组,其中有四个元素,按升序排列。我们想在这个数组中插入数字 3,下面的代码展示了如何计算插入点的索引。
int[] t = new int[] {1, 2, 4, 5};int x = Arrays.binarySearch(t, 3);assert ~x == 2;
如果我们需要对 bit 数组进行一些操作该怎么办呢?你是不是会使用 boolean[] 来实现呢?其实,有一种更有效、更节省内存的方法来实现。这就是 BitSet 类。BitSet 类允许我们存储和操作 bit 的数组。与 boolean[] 相比,它消耗的内存要少 8 倍。我们可以对数组进行逻辑操作,例如:and、or、xor。
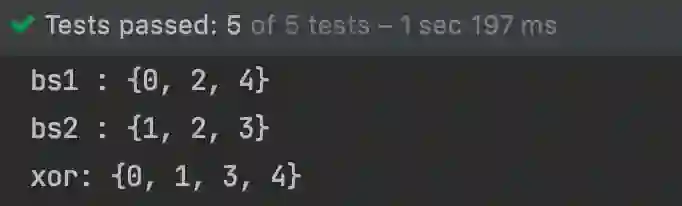
比方说,有两个 bit 的数组, 我们想对它们执行 xor 操作。为了做到这一点,我们需要创建两个 BitSet 的实例,并在实例中插入样例元素,如下所示。最后,对其中一个 BitSet 实例调用 xor 方法,并将第二个 BitSet 实例作为参数。
BitSet bs1 = new BitSet();bs1.set(0);bs1.set(2);bs1.set(4);System.out.println("bs1 : " + bs1);BitSet bs2 = new BitSet();bs2.set(1);bs2.set(2);bs2.set(3);System.out.println("bs2 : " + bs2);bs2.xor(bs1);System.out.println("xor: " + bs2);
如下是运行上述代码的结果:
最后,我们介绍本文最后一个有趣的 Java 特性。和其他一些样例一样,它也是 Java Concurrent 包的元素,被称为 Phaser。它与更知名的 CountDownLatch 相当相似。然而,它提供了一些额外的功能。它允许我们设置在继续执行之前需要等待的线程的动态数量。在 Phaser 中,已定义数量的线程需要在进入下一步执行之前在屏障上等待。得益于此,我们可以协调多个阶段的执行。
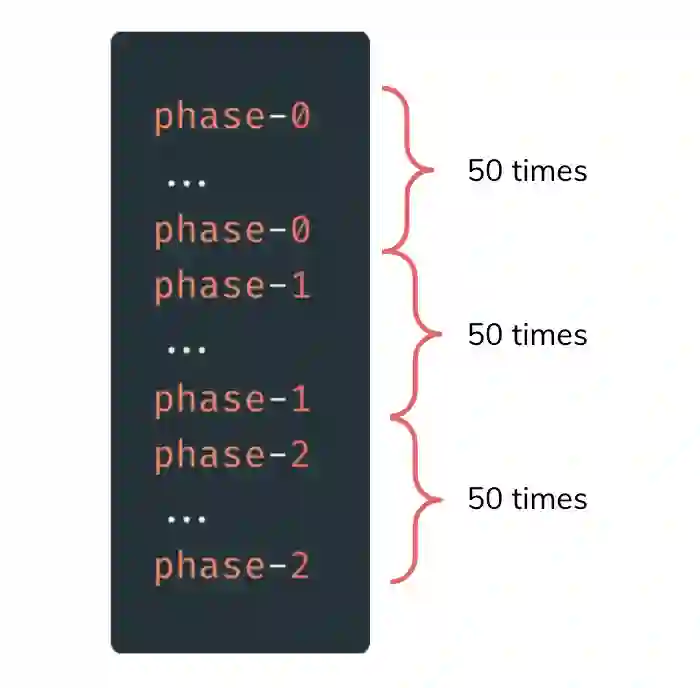
在下面的例子中,我们设置了一个具有 50 个线程的屏障,在进入下一个执行阶段之前,需要到达该屏障。然后,我们创建一个线程,在 Phaser 实例上调用 arriveAndAwaitAdvance() 方法。它会一直阻塞线程,直到所有的 50 个线程都到达屏障。然后,它进入 phase-1,同样会再次调用 arriveAndAwaitAdvance() 方法。
Phaser phaser = new Phaser(50);Runnable r = () -> {System.out.println("phase-0");phaser.arriveAndAwaitAdvance();System.out.println("phase-1");phaser.arriveAndAwaitAdvance();System.out.println("phase-2");phaser.arriveAndDeregister();};ExecutorService executor = Executors.newFixedThreadPool(50);for (int i = 0; i < 50; i++) {executor.submit(r);}
如下是执行上述代码的结果:
原文链接:
https://piotrminkowski.com/2022/01/05/useful-unknown-java-features/

你也「在看」吗?👇





