程序员硬核“年终大扫除”,清理了数据库 70GB 空间

【CSDN 编者按】春节将至,俗话说“腊月二十四,掸尘扫房子”,很多人会在腊月二十四给家里做大扫除迎新春。近年来数据呈爆发式增长,你是否和本文作者一样,常常收到数据库空间的告警呢?那来给数据库做一场“大扫除”试试看?

删除未被使用过的索引
SELECT relname, indexrelname, idx_scan, idx_tup_read, idx_tup_fetch, pg_size_pretty(pg_relation_size(indexrelname::regclass)) as sizeFROM pg_stat_all_indexesWHERE schemaname = 'public' AND indexrelname NOT LIKE 'pg_toast_%' AND idx_scan = 0 AND idx_tup_read = 0 AND idx_tup_fetch = 0ORDER BY size DESC;
-
可参考:https://www.postgresql.org/docs/current/monitoring-stats.html#MONITORING-PG-STAT-ALL-INDEXES-VIEW -
用那些有一定的时间没更新的表里唯一或主键约束的索引。这些索引看起来好像没有被使用过,但我们也不能随意处置它们。
-- Find table oid by nameSELECT oid FROM pg_class c WHERE relname = 'table_name';-- Reset counts for all indexes of tableSELECT pg_stat_reset_single_table_counters(14662536);
我们每隔一段时间执行一次上述操作来看看有没有要删除的未使用索引。

索引和表格
REINDEX INDEX index_name;
REINDEX INDEX CONCURRENTLY index_name;
SELECT c.relname as index_name, pg_size_pretty(pg_relation_size(c.oid))FROM pg_index i JOIN pg_class c ON i.indexrelid = c.oidWHERE -- New index built using REINDEX CONCURRENTLY c.relname LIKE '%_ccnew' -- In INVALID state AND NOT indisvalidLIMIT 10;
激活 B 树索引 Deduplication
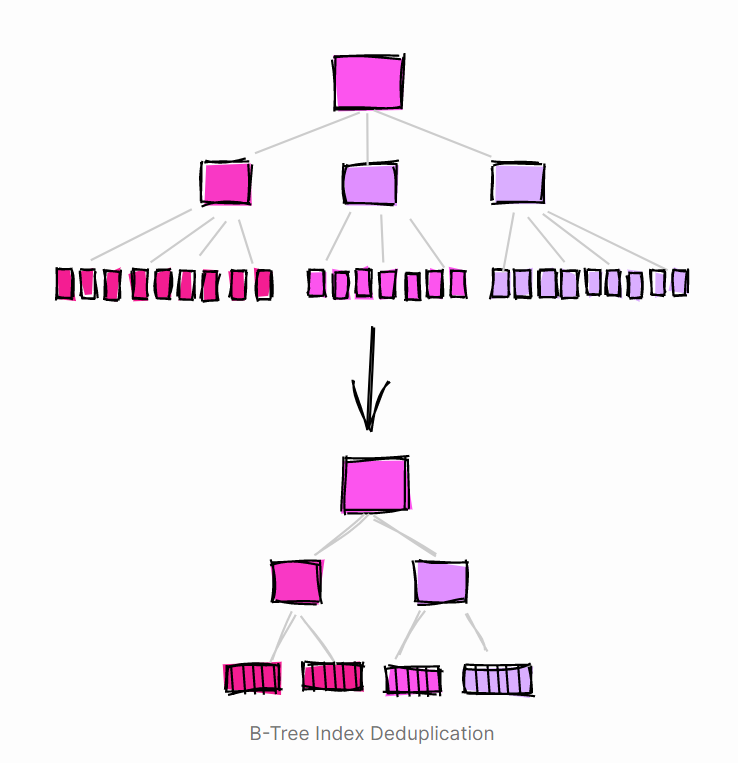
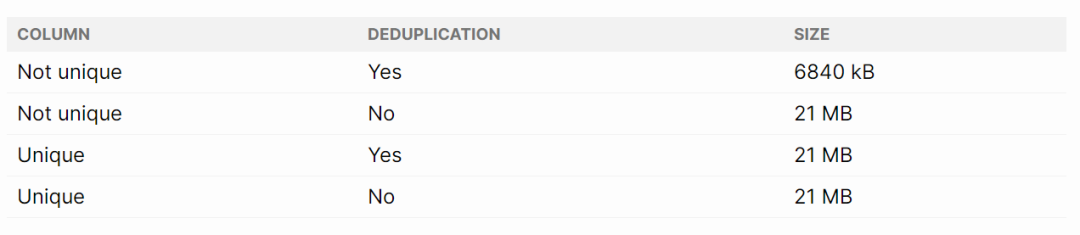
-- Activating de-deduplication for a B-Tree index, this is the default:CREATE INDEX index_name ON table_name(column_name) WITH (deduplicate_items = ON)
db=# CREATE test_btree_dedup (n_unique serial, n_not_unique integer);CREATE TABLE
db=# INSERT INTO test_btree_dedup (n_not_unique)SELECT (random() * 100)::int FROM generate_series(1, 1000000);INSERT 0 1000000
db=# CREATE INDEX ix1 ON test_btree_dedup (n_unique) WITH (deduplicate_items = OFF);CREATE INDEX
db=# CREATE INDEX ix2 ON test_btree_dedup (n_unique) WITH (deduplicate_items = ON);CREATE INDEX
db=# CREATE INDEX ix3 ON test_btree_dedup (n_not_unique) WITH (deduplicate_items = OFF);CREATE INDEX
db=# CREATE INDEX ix4 ON test_btree_dedup (n_not_unique) WITH (deduplicate_items = ON);CREATE INDEX
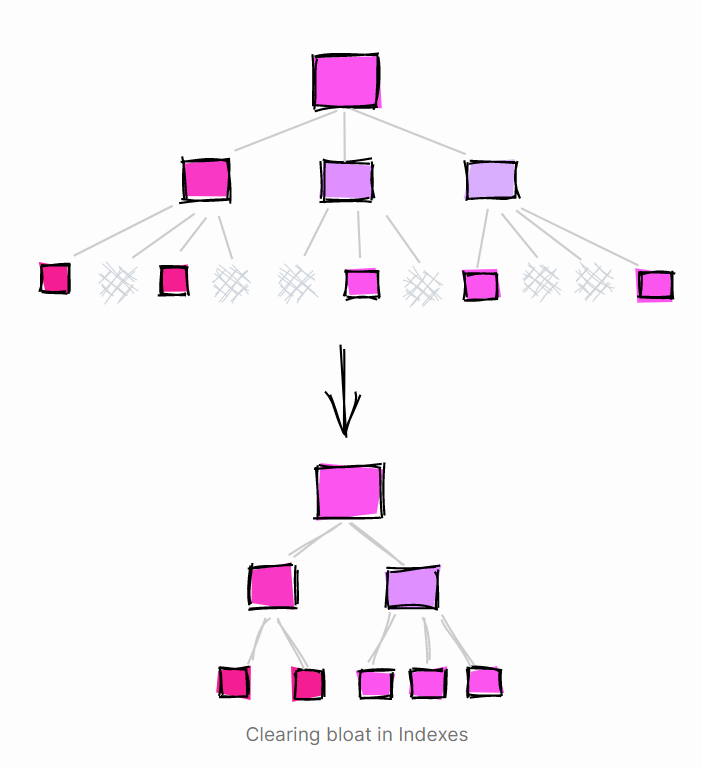
清除表中的 Bloat
-
重新创建表:如上所述,使用这种方法通常需要大量的开发工作,尤其是在重建正在使用表的情况下。 -
清理表:PostgreSQL 提供 VACUUM FULL 命令回收表中死元组占用的空间的方法(https://www.postgresql.org/docs/current/sql-vacuum.html)
-- Will lock the tableVACUUM FULL table_name;
使用 pg_repack
CREATE EXTENSION pg_repack;
$ pg_repack -k --table table_name db_name
-
所需的存储量大约为要重建表的容量:该扩展会创建另一个表来将数据复制到该表,因此它需要的附加存储量约为表及其索引的大小。 -
可能需要手动清理:如果 rebuild 过程失败或手动停止,可能会留下一些东向西,需手动清理。

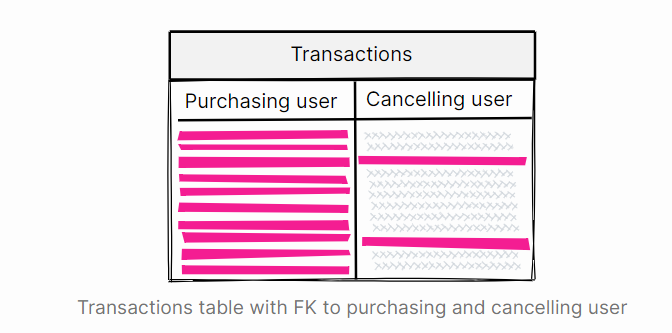
CREATE INDEX transaction_cancelled_by_ix ON transactions(cancelled_by_user_id);
DROP INDEX transaction_cancelled_by_ix;
CREATE INDEX transaction_cancelled_by_part_ix ON transactions(cancelled_by_user_id)WHERE cancelled_by_user_id IS NOT NULL;

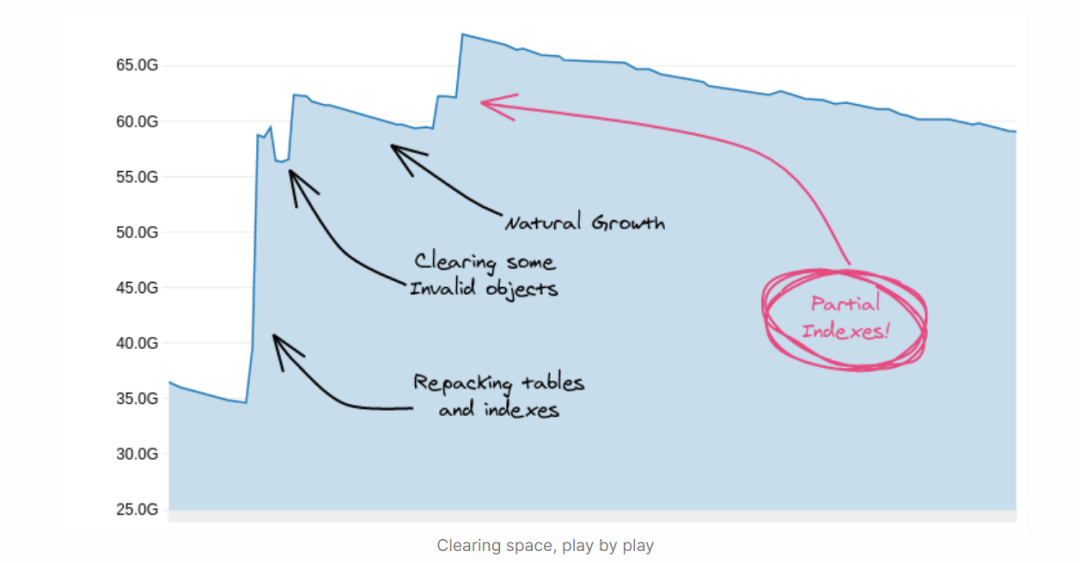
利用部分索引
-- Find indexed columns with high null_fracSELECT c.oid, c.relname AS index, pg_size_pretty(pg_relation_size(c.oid)) AS index_size, i.indisunique AS unique, a.attname AS indexed_column, CASE s.null_frac WHEN 0 THEN '' ELSE to_char(s.null_frac * 100, '999.00%') END AS null_frac, pg_size_pretty((pg_relation_size(c.oid) * s.null_frac)::bigint) AS expected_saving -- Uncomment to include the index definition --, ixs.indexdef
FROM pg_class c JOIN pg_index i ON i.indexrelid = c.oid JOIN pg_attribute a ON a.attrelid = c.oid JOIN pg_class c_table ON c_table.oid = i.indrelid JOIN pg_indexes ixs ON c.relname = ixs.indexname LEFT JOIN pg_stats s ON s.tablename = c_table.relname AND a.attname = s.attname
WHERE -- Primary key cannot be partial NOT i.indisprimary
-- Exclude already partial indexes AND i.indpred IS NULL
-- Exclude composite indexes AND array_length(i.indkey, 1) = 1
-- Larger than 10MB AND pg_relation_size(c.oid) > 10 * 1024 ^ 2
ORDER BY pg_relation_size(c.oid) * s.null_frac DESC;
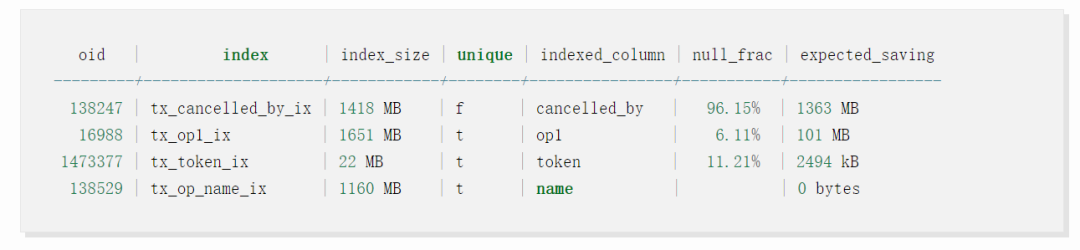
-
tx_cancelled_by_ix 是具有许多空值的大型索引:此处潜力巨大! -
tx_op_1_ix 是大索引,几乎没有空值:潜力不大 -
tx_token_ix 是带有少量空值的小索引:不管它 -
tx_op_name_ix 是没有空值的大索引:没啥用

Django ORM 迁移
防止隐式创建外键索引
from django.db import modelsfrom django.contrib.auth.models import User
class Transaction(models.Model): # ... cancelled_by_user = models.ForeignKey( to=User, null=True, on_delete=models.CASCADE, )
from django.db import modelsfrom django.contrib.auth.models import User
class Transaction(models.Model): # ... cancelled_by_user = models.ForeignKey( to=User, null=True, on_delete=models.CASCADE, db_index=False, )
class Meta: indexes = ( models.Index( fields=('cancelled_by_user_id', ), name='%(class_name)s_cancelled_by_part_ix', condition=Q(cancelled_by_user_id__isnull=False), ), )
将现有的完整索引迁移到部分索引
-
用部分索引替换完整索引 :如上所示,调整相关的 Django 模型并用部分索引替换完整索引。Django 生成的迁移将首先禁用 FK 约束(如果该字段是外键),则删除现有的完整索引并创建新的部分索引。执行此迁移可能会导致停机和性能下降,我们实际上不会运行它。 -
手动创建部分索引: 使用 Django 的./manage.py sqlmigrate 实用程序生成用于迁移的脚本,仅提取 CREATE INDEX 语句并进行调整以创建索引 CONCURRENTLY,并在数据库中手动创建索引。由于没删除完整索引,因此查询仍可以使用它们,在这个过程中不影响性能。在 Django 迁移中同时创建索引,我们建议最好手动进行。 -
重置完整索引统计信息计数器 :为了确保删除完整索引的安全性,我们首先要确保正在使用新的部分索引。为了跟踪它们的使用,我们使用重置完整索引的计数器 pg_stat_reset_single_table_counters(<full index oid>)。 -
显示器使用部分索引 :重置统计信息后,我们监测 pg_stat_all_indexes表中的 idx_scan,idx_tup_read、idx_tup_fetch,来观察整体查询性能和部分索引使用情况。 -
删除完整索引: 一旦使用了部分索引,就删除完整索引。这是检查部分索引和完全索引大小的好方法,以便确定要释放多少存储空间。 -
伪造 Django 迁移 :一旦数据库状态有效地与模型状态同步,我们就使用伪造迁移./manage.py migrate --fake。伪造迁移时,Django 会将迁移注册为已执行,但实际上不会执行任何操作。当需要更好地控制迁移过程时,这种情况很有用。请注意,在没有停机时间考虑的其他环境,Django 迁移将正常执行,并全部索引将替换为部分索引。
-
删除未使用的索引 -
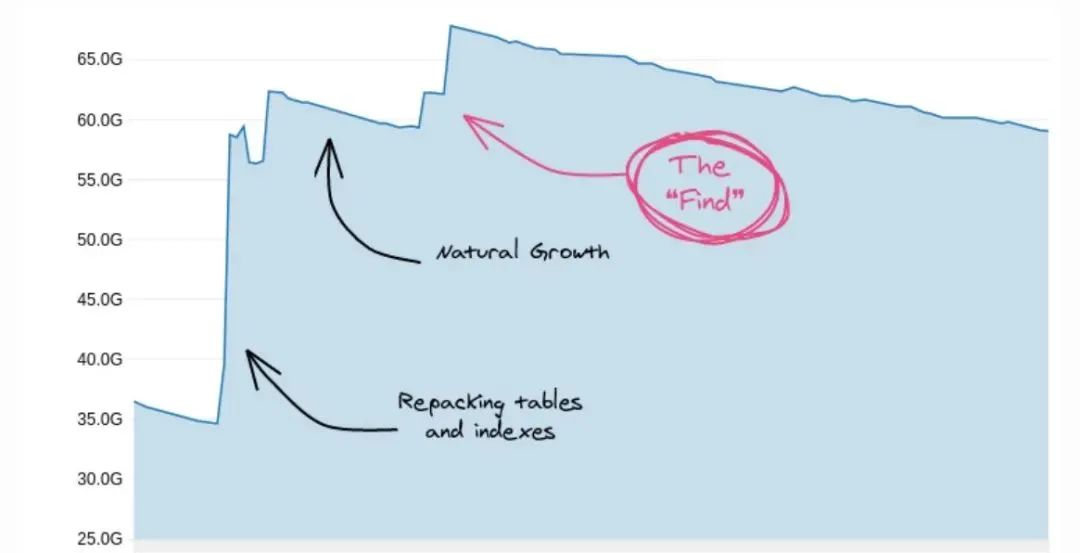
重新打包表和索引(在可能的情况下激活 B 树重复数据删除) -
利用部分索引仅对必要内容进行索引

程序员如何避免陷入“内卷”、选择什么技术最有前景,中国开发者现状与技术趋势究竟是什么样?快来参与「2020 中国开发者大调查」,更有丰富奖品送不停!

☞任正非就注册姚安娜商标道歉;人人影视字幕组因盗版被查;JIRA、Confluence 等产品本月停售本地化版本 | 极客头条
☞三年已投 1000 亿打造的达摩院,何以仗剑走天涯?


登录查看更多
相关内容

Pacific Graphics是亚洲图形协会的旗舰会议。作为一个非常成功的会议系列,太平洋图形公司为太平洋沿岸以及世界各地的研究人员,开发人员,从业人员提供了一个高级论坛,以介绍和讨论计算机图形学及相关领域的新问题,解决方案和技术。太平洋图形会议的目的是召集来自各个领域的研究人员,以展示他们的最新成果,开展合作并为研究领域的发展做出贡献。会议将包括定期的论文讨论会,进行中的讨论会,教程以及由与计算机图形学和交互系统相关的所有领域的国际知名演讲者的演讲。
官网地址:http://dblp.uni-trier.de/db/conf/pg/index.html
相关主题




相关VIP内容
相关资讯
相关论文