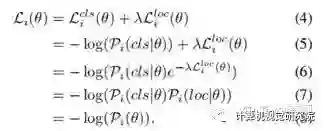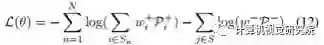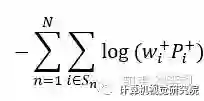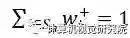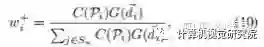![]()
首先,从idea上讲,AutoAssign将label assignment完全做成端到端地(或者实际上是dynamic soft的),并且仅使用了最小先验(仅正样本的candidate location在gt框内部),的确算的上是一篇重量级并很general的作品。
其次,这也是一篇可以预见的paper,具体可以参见Jianfeng Wang(也就是本文二作)在知乎上的回答
如何评价zhangshifeng最新的讨论anchor based/ free的论文?www.zhihu.com在该回答中,Jianfeng犀利地指出ATSS虽然利用统计量“动态”分配了正负样本,但这实际上是一种伪动态,因为样本的分配方式在数据集和网络配置完成之后其实是固定的,并不会随着训练过程而产生更好地调整和变化。正如Jianfeng所说,“有很多个项目,模型本身是一模一样的,但因为数据resolution不同,ground-truth的size不同,每个项目拿过来都要重新调anchor或者调分层参数,不仅是研究员和工程师的精力成本,也是自动化的障碍,在学术上还是更好解scale问题的阻碍;这个事,能不能训练的时候自己就学了?”,于是就有了这篇AutoAssign。
接下来我们深入地理解一下AutoAssign是怎么操作的。
从理念上来讲,AutoAssign跳出了此前object detection所广泛遵循的两个paradigm:
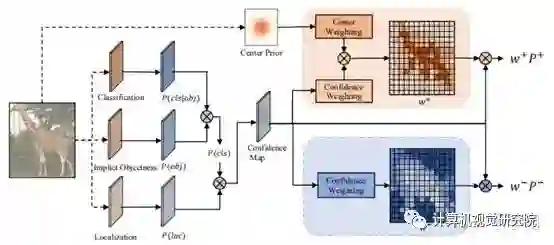
1. 非正即负的assign方式和监督原则。相反,AutoAssign认为每个location众生平等(这里包括FPN各个level),每个location都有正样本属性和负样本属性(即体现在原文中的w+ 和w-)。也就是说,在优化的过程中,有些样本会同时受到来自它为正样本的监督和负样本的监督,两者利用w+和w-来平衡配比。当然,有一点可以提前rule掉,就是不在任何ground-truth box里的location其正样本属性 w+ 必然为0,也就是那些position必然是background。
2. 分开优化classification和regression。相反,AutoAssign利用(4)-(8)式子将两者进行联合,一方面可以更好地简化表示统一优化,另一方面在协助生成正样本置信度(即w+)的时候可以综合考虑分类和定位的情况。
![]()
从技术细节上来讲,建议直接从公式(12)入手去看。
![]()
先看右半边部分,这个比较好理解,就是每个FPN level的每个location,都拥有负样本属性,由w-来决定强弱,把这个loss算上(当然是用Focal Loss处理的)。w-由后文再说。
再看左边部分,这块理解透其实有点难度。如果和右边对称的来看,一种比较直观的表达式应该长这样:
![]()
注意,这里其实也会遍历所有的location,只是那些不在gt box里面的location对应的w+必然为0了。这个表达式其实和论文中使用的(12)式有一些区别,虽然原论文做了一些解释:“To ensure at least one location matches object n, we use weighted sum of all positive weights to get the final positive confidence.”翻译过来的意思是要保证每个gt必须有至少一个location去match上,但以个人浅见,从操作上来讲上式和(12)并没有该解释的区别。原因是w+的计算(后文会说)必然保证了对一个gt的求和为1,即
![]()
,w+始终会存在一定的正值的,一定会有match的那个。个人觉得可能的一个原因之一可能与优化存在一定的关系,因为的确会存在某些w+的数值非常接近0,那么-log(0*p)单独优化可能会炸掉,所以不如每个gt的都加在一起放log里面。
这个里面顺带提到一点比较有意思的地方是AutoAssign这个框架优雅地处理掉了重叠框的地方(如果我理解没错的话)。原来FCOS里面处理重叠框的话对于location会选择面积小的那个gt去match,这显然太handcraft了。而这里我不需要管你重叠不重叠,我就每个gt框各自算就行,反正到时候不同gt框对应的w+会慢慢学习慢慢演化出来重叠区域的location究竟归属为哪个。
w- 手工设计了一个基于max IoU的函数,简单来说,一个location的负样本程度与它动态预测出来框和所有gt框里面最大的IoU相关,越小越接近于负样本。比较直观~
![]()
为了保证竞争和合理的数值范围,有一个类似softmax的操作,因为本来一个gt框里面就只有一部分真正地落在物体上的,那么这些位置就很可能对应了那些较大的w+值。(10)式子中包含C(P)和G(d)两个部分,其中C(P)比较好理解:
![]()
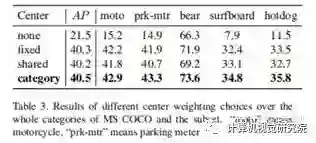
与(8)式正相关,也就是说我分类得分高、框预测的准的location拥有较大的w+值的概率就会高;这其实是一种强者恒强的逻辑,这个逻辑在自适应选择正负样本的设定下会存在一个冷启动的问题:如果一开始我一个坏的location恰巧分类和框回归的都还不错,那么它的w+就会很高,也就是说它的权重就会较大,监督训练对它的关照就会不断增大,这样就导致有一些好的location完全没有机会翻盘,让网络学成了一个过拟合的模样。为了能够让好的location翻盘,论文作者引入了G(d)这么一项,这其实是一个经验引入,因为大家都知道,大部分情况下,框的中心通常都是质量较高的正样本的首选(FCOS的assign正样本策略就是如此),所以作者为每个大类学习了一个公共的gaussian prior,它的形状基本上都是从物体的大致中心区域往外渐渐变弱。有了这一项可学习先验的引入,那些更有潜力的好的location就有翻盘的机会。不过,这个可学习的先验的确有一个一眼就能看出来的致命缺陷,就是它仅与类别有关,可能会造成对旋转的不match。就举论文中的一幅图来说:
![]()
由于冲浪板通常是长长的,所以冲浪板这个类学习到的prior变成了一个合理的椭圆。然鹅,这个椭圆只是固定左右向的,如果一个斜着的(其实图中就有一个)、甚至是竖着的冲浪板,可能就不是特别合理。当然,从ablation study来看,这个先验有没有是一个巨大的区别,但是否要根据category每个都学一个,还是说就固定一个,可能区别的确相差不太大(0.2左右的AP差别),所以上面那个concern可能也就没那么重要了?
![]()
虽然论文没提,但从经验上来讲,训练的时候w+和w-似乎都需要detach掉。
![]()
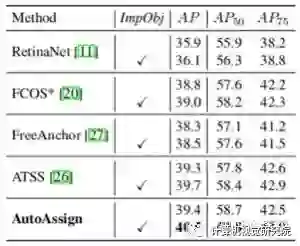
除了Implict Objectness,其他基本都cover了。这个分支原论文的说法是“To suppress false positives from the inferior locations”,也就是说用一个隐式的前景背景二分类对分类预测做一个乘性叠加。注意这个分支是没有额外监督的(也没法有),就是单纯地去scale一下分类的预测。比较意外的是,这个分支带来的作用非常的大,尤其对AutoAssign来说,见下表:
![]()
换句话说,没有这个分支,AutoAssign可能也就刚刚到ATSS的性能。关于这个ImpObj分支,作者没有做特别深入的讨论,就个人目前较浅的理解来看有如下几方面值得思考:
(1) 如果检测的类别只有1类,也就是说只有前景和背景,那么这个分支还需要么?如果答案是是,那么它就应该还扮演其他的功能。
(2) 可能有什么其他功能么?有一种可能性是类似FCOS和ATSS中的centerness这个质量预测分支,注意,在测试的时候,centerness是与分类score相乘的,这个操作与这里是非常接近的。
可视化部分,多个weights的结果还是非常reasonable的:
![]()
例如,confidence weight的确在合适的FPN stage、以及物体的主要部位形成了较高的weight,并不是无脑地assign在物体框的中心区域。
最后,总结一下AutoAssign:
AutoAssign成功地首次完成了端到端的动态label assignment,我们也能够看到作者团队为了能够让这个idea work的确付出了非常艰辛和充分的努力。相信这个工作也是能够启发非常多的更加深入的探讨和新的idea。另外,最后再总结一些发现的问题,供大家参考和探讨:
1) 重叠框的问题是否的确如我分析所说,被优雅地解决掉了?
2) 训练的时候是否有一些变量需要detach掉?比如w+, w- 么?
3) ImpObj分支是否有更深入的理解?
源码:https://link.zhihu.com/?target=https%3A//github.com/open-mmlab/mmdetection/blob/master/configs/gfl/README.md
转至知乎,感谢知乎李翔的分享!
✄-----------------------------------
如果想加入我们“
计算机视觉研究院
”,请扫二维码加入我们。我们会按照你的需求将你拉入对应的学习群!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”
研究
“。之后我们会针对相应领域分享实践过程,让大家真正体会
摆脱理论
的真实场景,培养爱动手编程爱动脑思考的习惯!