7 papers | ML因果关系论文获Judea Pearl点赞;华为云端网络压缩新技术
本周的论文既有关于细粒度神经架构搜索和机器学习因果关系的研究,也有能够提升图像识别的对抗样本和编辑嵌入图像的框架 Image2StyleGAN++
Fine-Grained Neural Architecture Search
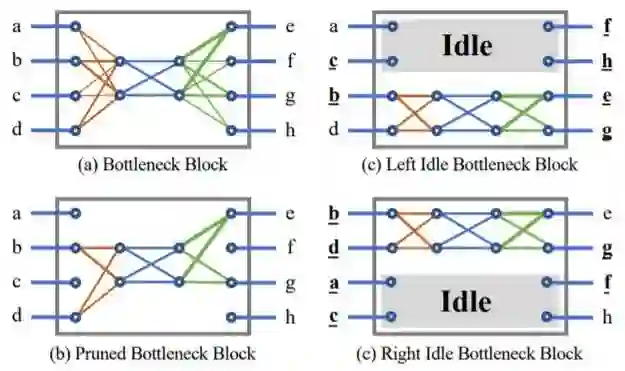
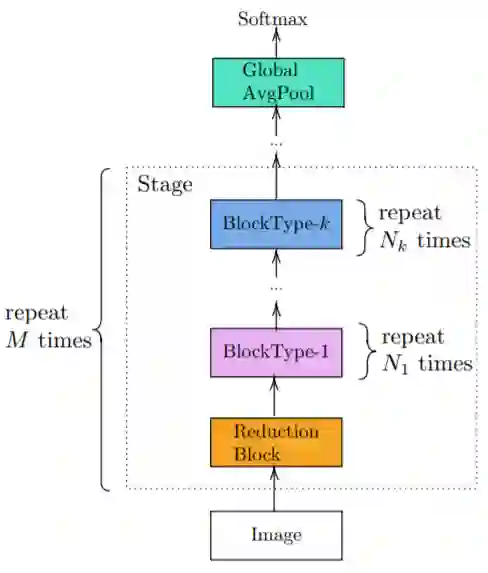
Hybrid Composition with IdleBlock: More Efficient Networks for Image Recognition
Causality for Machine Learning
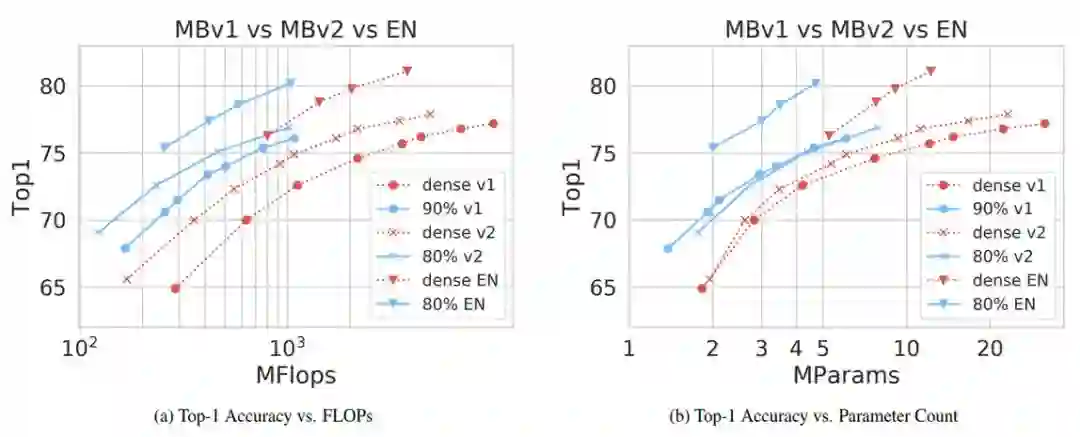
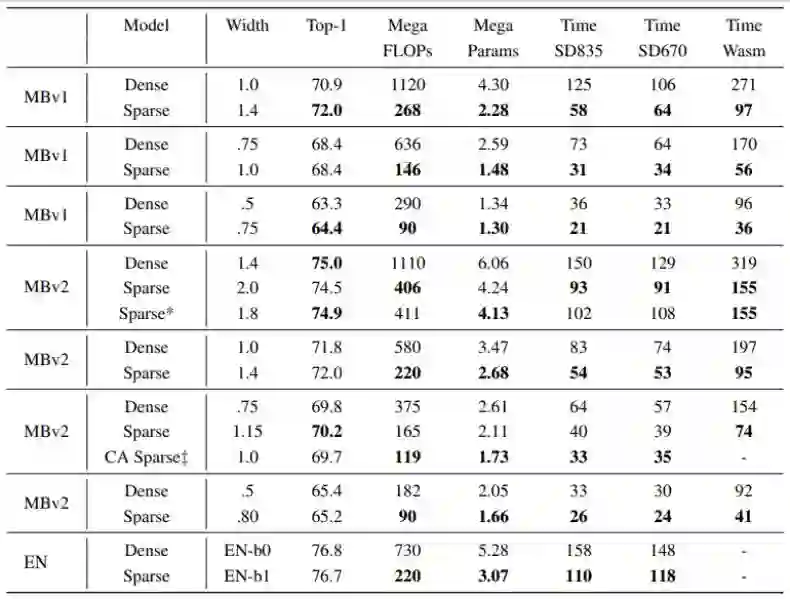
Fast Sparse ConvNets
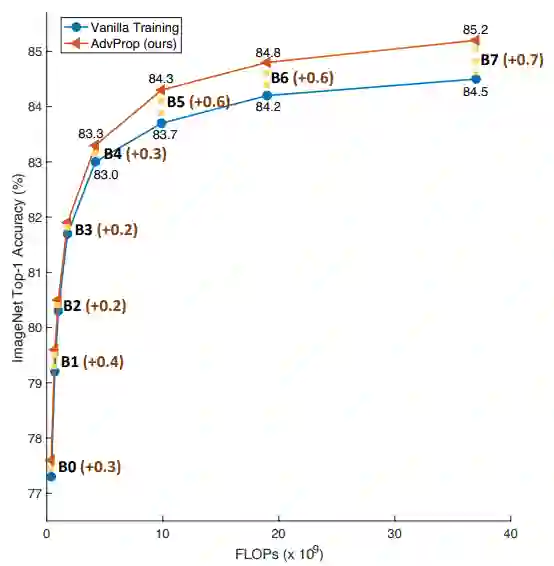
Adversarial Examples Improve Image Recognition
Positive-Unlabeled Compression on the Cloud
Image2StyleGAN++: How to Edit the Embedded Images?
作者:Heewon Kim、Seokil Hong、Bohyung Han、Heesoo Myeong、Kyoung Mu Lee
论文地址:https://arxiv.org/abs/1911.07478v1
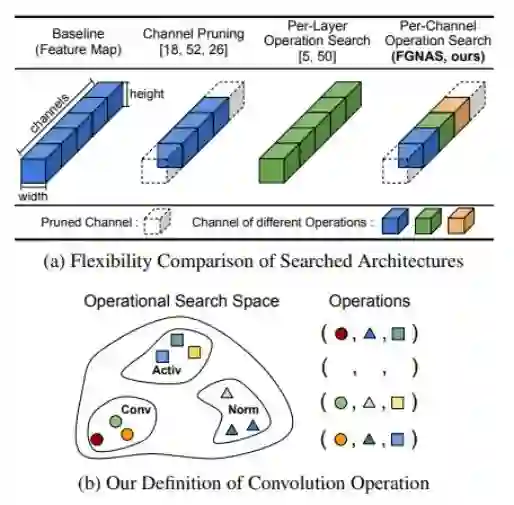

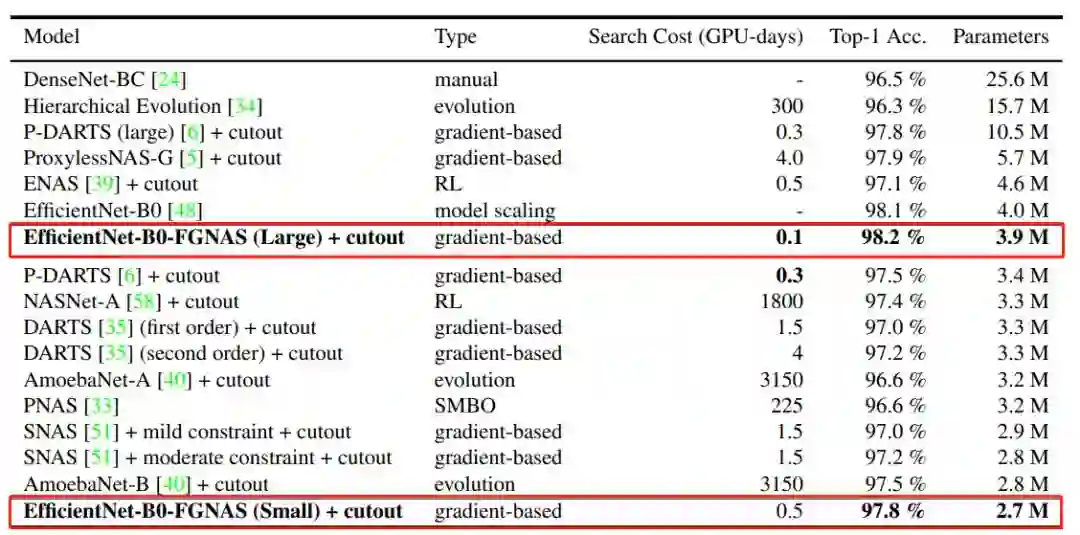
作者:Bing Xu、Andrew Tulloch、Yunpeng Chen、Xiaomeng Yang、Lin Qiao
论文链接:https://arxiv.org/pdf/1911.08609.pdf
作者:Bernhard Schölkopf
论文链接:https://arxiv.org/abs/1911.10500
作者:Erich Elsen、Marat Dukhan、Trevor Gale、Karen Simonyan
论文链接:https://arxiv.org/abs/1911.09723v1
作者:Cihang Xie、Mingxing Tan、Boqing Gong、Jiang Wang、Alan Yuille、Quoc V. Le
论文地址:https://arxiv.org/pdf/1911.09665v1.pdf
实现地址:https://github.com/tensorflow/tpu/tree/ master/models/official/efficientnet

作者:Yixing Xu、Yunhe Wang、Hanting Chen、Kai Han、Chunjing Xu、Dacheng Tao、Chang Xu
论文地址:https://arxiv.org/pdf/1909.09757.pdf
作者:Rameen Abdal、Yipeng Qin、Peter Wonka
论文链接:https://arxiv.org/pdf/1911.11544.pdf




