Superl-url:一款开源关键词URL采集工具
superl-url是一款开源的,并且功能强大的关键词URL采集工具,可以根据关键词,对搜索引擎内容检索结果的网址内容进行采集。
程序主要运用于安全渗透测试项目,以及批量评估各类CMS系统0DAY的影响程度,同时也是批量采集自己获取感兴趣的网站的一个小程序~~
本来几年前就写好了,没什么技术含量,没想到小伙伴的使用需求还蛮大的,不敢私藏~~
立了flag,git的star过200就一定抽时间去升级,这个flag已经实现,目前已经是4.0版本~~ 更新后就在这里发出来了。
优势介绍
1.支持多搜索引擎,很方便添加集成。(已内置了百度,搜狗,360),结构模块化,很方便进行扩展,可以无限添加。
2.开源,跨平台,使用python开发;
3.做了兼容性优化,同时支持python2和python3;
4.支持自动过滤重复内容,支持过滤标题中存在指定关键词的内容,支持过滤域名;
5.保存方式同时支持本地txt和mysql数据库;
6.从搜索引擎采集到的地址,是真实网站地址,不是像百度快照那样的三方地址;
7.多进程同时采集。每个搜索引擎都单独一个进程;
8.可灵活的通过配置文件自定义要保存的结果格式。比如只输出带参数的原始真实URL,或者只输出域名,或者同时输出标题,搜索引擎名称。
9.可自定义每页采集时间间隔,防止被屏蔽;
运行效果
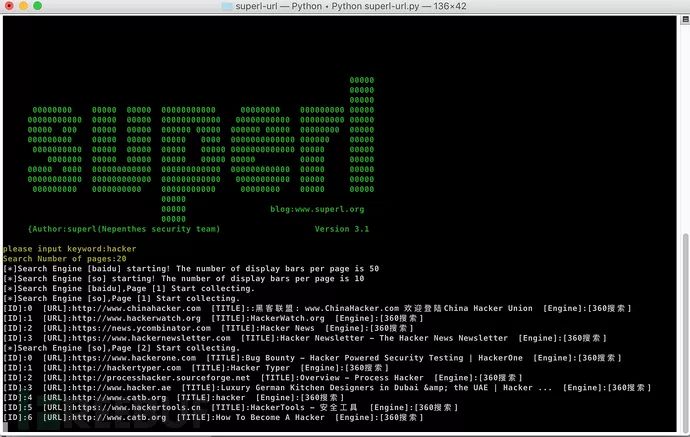
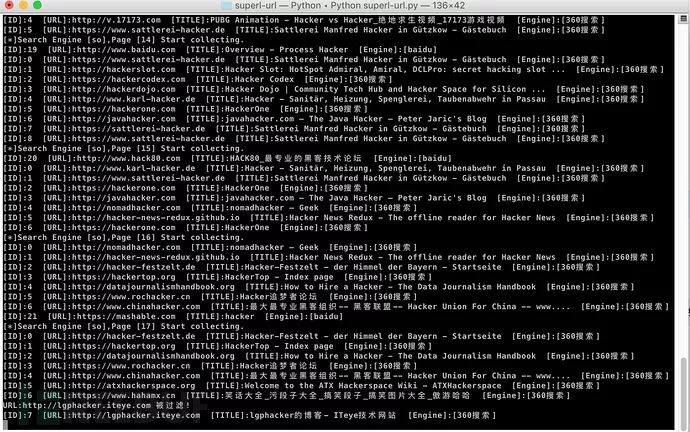
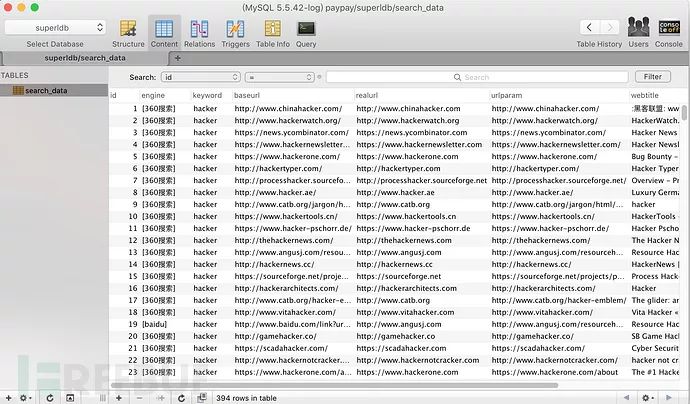
使用说明
1.安装python2或者python3运行环境;
2.如果提示没有找到库,则需要安装依赖:
如果是python3,则:
pip install ConfigParserpip install tldextract
如果是Python2,则:
pip install tldextractpip install -i https://pypi.tuna.tsinghua.edu.cn/simple configparser
3.根据自己的需要,修改根目录下的config.cfg配置文件。
配置文件说明
| 节点 | 参数 | 示例值 | 说明 |
|---|---|---|---|
| global | save_type | mysql | 保存类型,可选择file或者mysql,如果是file则保存为本地txt |
| global | sleep_time | 1 | 每次搜索处理完一页后的等待时间,防止太频繁被搜索引擎屏蔽 |
| url | url_type | realurl | 保存文件txt里面显示的url类型。realurl=真实网站地址,baseurl=原始搜索引擎地址,urlparam=带参数的真实网站地址 |
| filter | filter_status | True | 是否开启过滤器,如果开启,则过滤域名和标题都不生效 |
| filter | filter_domain | True | 是否过滤域名 |
| filter | filter_title | True | 是否过滤标题 |
| log | write_title | True | 是否显示标题 |
| log | write_name | True | 是否显示搜索引擎名称 |
| engine | baidu | True | 百度搜索引擎模块是否开启 |
| engine | sougou | True | 搜狗模块是否开启 |
| engine | so | False | 搜搜模块是否开启 (搜搜现在抓取不到了) |
| pagesize | baidu_pagesize | 50 | 每页条数 |
| pagesize | sougou_pagesize | 50 | 每页条数 |
| pagesize | so_pagesize | 10 | 每页条数 |
| mysql | host | 127.0.0.1 | 如果保存类型为Mysql,则此节点必须配置正确 |
| mysql | port | 3306 | 端口 |
| mysql | user | root | 用户名 |
| mysql | password | root | 密码 |
| mysql | database | superldb | 数据库名称 |
| mysql | table | search_data | 表名称 |
| file | save_pathdir | result | 如果保存类型为file,则这里设置的是保存的路径,当前为程序根目录的result文件夹 |
| plugin | pr | True | 预留的插件功能,暂时不支持 |
如果保存方式为Mysql,还需要执行以下sql创建表:
CREATE TABLE `search_data` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `engine` varchar(20) NOT NULL DEFAULT '', `keyword` varchar(100) NOT NULL DEFAULT '', `baseurl` varchar(255) NOT NULL DEFAULT '', `realurl` varchar(255) NOT NULL DEFAULT '', `urlparam` varchar(255) NOT NULL DEFAULT '', `webtitle` varchar(255) NOT NULL DEFAULT '', `create_time` int(10) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=MyISAM AUTO_INCREMENT=395 DEFAULT CHARSET=utf8;
项目地址:【点击底部阅读原文查看】
至于要不要再开发一个JAVA GUI版本的或者php写WEB版本的,先观望观望~
*本文作者:superl,转载请注明来自FreeBuf.COM
精彩推荐