近期必读的5篇顶会CVPR 2021【视觉目标检测】相关论文和代码
1. Towards Open World Object Detection
作者:K J Joseph, Salman Khan, Fahad Shahbaz Khan, Vineeth N Balasubramanian
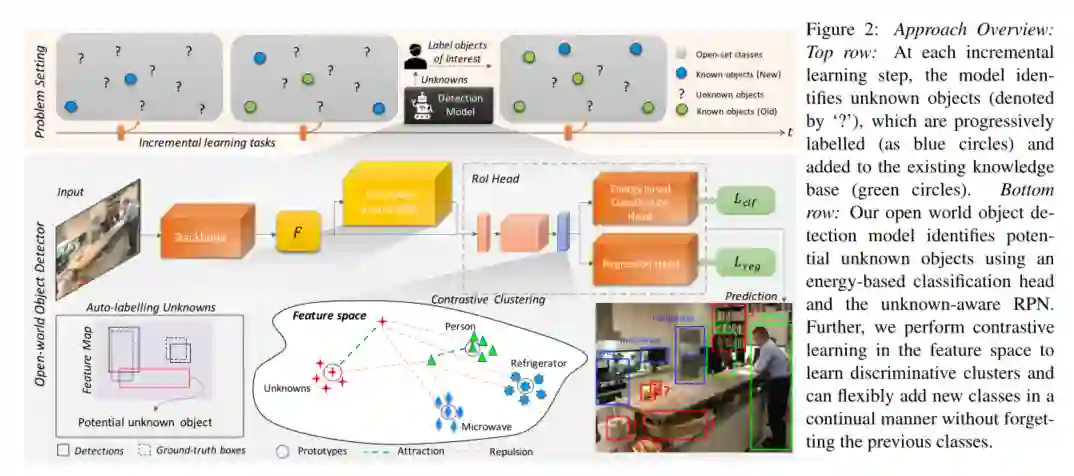
摘要:人类具有识别其环境中未知目标实例的本能。当相应的知识最终可用时,对这些未知实例的内在好奇心有助于学习它们。这促使我们提出了一个新颖的计算机视觉问题:“开放世界目标检测”,该模型的任务是:1)在没有明确监督的情况下将尚未引入该目标的目标识别为“未知”,以及2)当逐渐接收到相应的标签时,逐步学习这些已识别的未知类别,而不会忘记先前学习的类别。我们提出了问题,引入了强大的评价准则并提供了一种新颖的解决方案,我们称之为ORE:基于对比聚类和基于能量的未知标识的开放世界目标检测器。我们的实验评估和消去实验研究分析了ORE在实现开放世界目标方面的功效。作为一个有趣的副产品,我们发现识别和表征未知实例有助于减少增量目标检测设置中的混乱,在此方法中,我们无需任何方法上的努力即可获得最先进的性能。我们希望我们的工作将吸引对这个新发现的但至关重要的研究方向的进一步研究。
代码:
https://github.com/JosephKJ/OWOD
网址:
https://arxiv.org/abs/2103.02603
2. General Instance Distillation for Object Detection
作者:Xing Dai, Zeren Jiang, Zhao Wu, Yiping Bao, Zhicheng Wang, Si Liu, Erjin Zhou
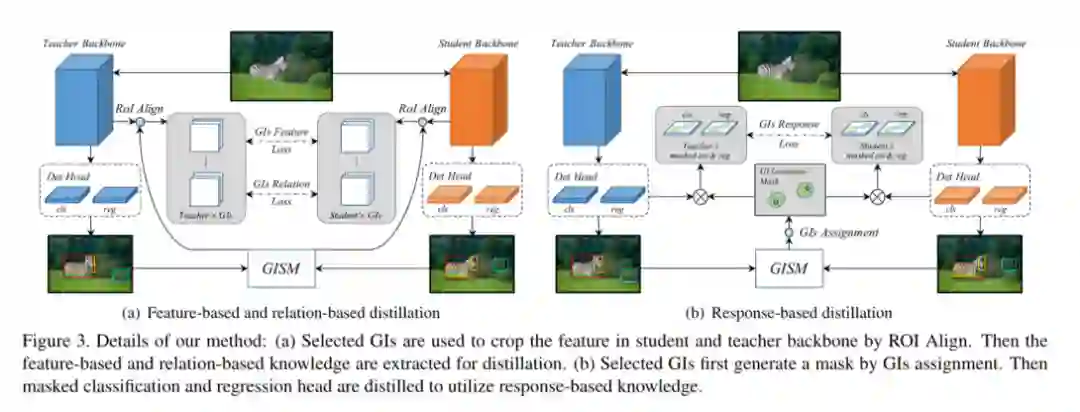
摘要:近年来,知识蒸馏已被证明是模型压缩的有效解决方案。这种方法可以使轻量级的学生模型获得从繁琐的教师模型中提取的知识。但是,先前的蒸馏检测方法对于不同的检测框架具有较弱的概括性,并且严重依赖ground truth (GT),而忽略了实例之间有价值的关系信息。因此,我们提出了一种新的基于区分性实例检测任务的蒸馏方法,该方法不考虑GT区分出的正例或负例,这称为一般实例蒸馏(GID)。我们的方法包含一个通用实例选择模块(GISM),以充分利用基于特征的,基于关系的和基于响应的知识进行蒸馏。广泛的结果表明,在各种检测框架下,学生模型可显着提高AP的表现,甚至优于教师模型。具体来说,在Reconet上使用ResNet-50的RetinaNet在COCO数据集上具有GID的mAP达到了39.1%,比基线的36.2%超出了2.9%,甚至比具有38.1%的AP的基于ResNet-101的教师模型更好。
网址:
https://arxiv.org/abs/2103.02340
3. Multiple Instance Active Learning for Object Detection
作者:Tianning Yuan, Fang Wan, Mengying Fu, Jianzhuang Liu, Songcen Xu, Xiangyang Ji, Qixiang Ye
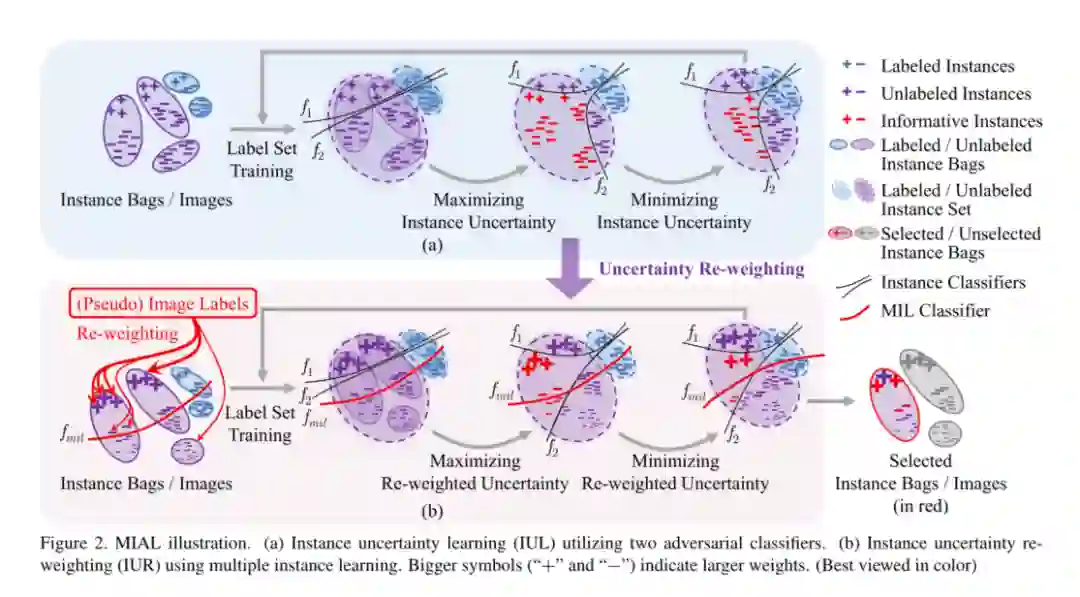
摘要:尽管主动学习(active learning)在图像识别方面取得了长足的进步,但仍然缺乏为目标检测任务设置的实例级主动学习方法。在本文中,我们提出了多实例主动学习(MIAL),通过观察实例级别的不确定性来选择信息量最大的图像进行检测器训练。MIAL定义了实例不确定性学习模块,该模块利用在标记集上训练的两个对抗性实例分类器的差异来预测未标记集的实例不确定性。MIAL将未标记的图像视为实例包,并将图像中的特征锚视为实例,并通过以多实例学习(MIL)方式对实例重新加权来估计图像不确定性。迭代实例不确定性学习和重新加权有助于抑制嘈杂的实例,以弥合实例不确定性和图像级不确定性之间的差距。实验证明,MIAL为实例级的主动学习设置了坚实的基准。在常用的目标检测数据集上,MIAL具有明显的优势,优于最新方法,尤其是在标记集很小的情况下。
代码:
https://github.com/yuantn/MIAL
4. There is More than Meets the Eye: Self-Supervised Multi-Object Detection and Tracking with Sound by Distilling Multimodal Knowledge
作者:Francisco Rivera Valverde, Juana Valeria Hurtado, Abhinav Valada
摘要:目标固有的声音属性可以提供有价值的线索,以学习丰富的表示形式来进行目标检测和跟踪。此外,可以通过仅监视环境中的声音来利用视频中视听事件的共现来在图像上定位目标。到目前为止,这仅在摄像机静止且用于单个目标检测的情况下才可行。此外,这些方法的鲁棒性受到限制,因为它们主要依赖于高度易受光照和天气变化影响的RGB图像。在这项工作中,我们提出了一种新颖的自监督的MM-DistillNet框架,该框架由多名教师组成,这些教师利用RGB,深度和热图像等多种模式,同时利用互补线索和提炼知识到单个音频学生网络中。我们提出了新的MTA损失函数,该函数有助于以自监督的方式从多模态教师中提取信息。此外,我们为有声读物的学生提出了一种新颖的自监督的前置任务,使我们不必依赖劳动强度大的人工注释。我们引入了一个大型多模态数据集,其中包含113,000多个时间同步的RGB,深度,热和音频模态帧。大量实验表明,我们的方法优于最新方法,同时能够在推理甚至移动过程中仅使用声音来检测多个目标。

网址:
https://arxiv.org/abs/2103.01353
5. Semantic Relation Reasoning for Shot-Stable Few-Shot Object Detection
作者:Chenchen Zhu, Fangyi Chen, Uzair Ahmed, Marios Savvides
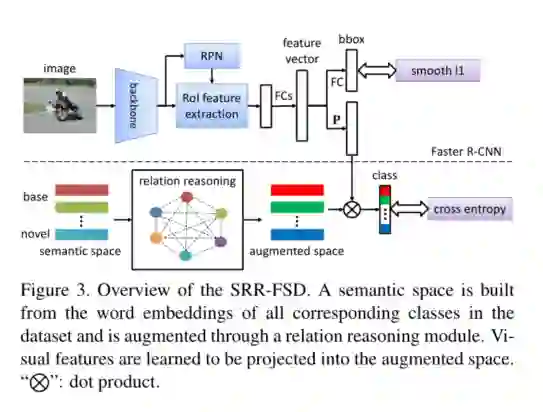
摘要:由于真实世界数据固有的长尾分布,少样本目标检测是当前非常需要研究的问题。它的性能在很大程度上受到新的类别数据匮乏的影响。但是,无论数据可用性如何,新颖类和基类之间的语义关系都是恒定的。在这项工作中,我们研究将这种语义关系与视觉信息一起使用,并将显式关系推理引入新颖目标检测的学习中。具体来说,我们通过从大型语料库中学到的语义嵌入来表示每个类的概念。检测要求将目标的图像表示投影到此嵌入空间中。我们发现如果仅仅使用启发式知识图谱作为原始嵌入是远远不够的,提出使用一种动态关系图来扩展原始嵌入向量。因此,我们提出的SRR-FSD的少样本检测器对于新目标的变化能够保持稳定的性能。实验表明,SRR-FSD可以在higher shots下获得还不错的结果,更重要地是,在较低的explicit shots和implicit shots的情况下,SRR-FSD的性能也要好得多。
网址:
https://arxiv.org/abs/2103.01903
请关注专知公众号(点击上方蓝色专知关注)
后台回复“CVPR2021OD” 就可以获取《5篇顶会CVPR 2021视觉目标检测(Object Detection)相关论文》的pdf下载链接~






