从工具到社区,美图秀秀大规模性能优化实践
导读:本文由演讲整理而成。美图秀秀社区自上线以来已经有近一年时间,不管是秀秀海量的用户还是图片社区特有的形态都给性能优化提出了巨大的挑战。本文将会结合这一年内我们遇到的具体案例和大家分享下美图秀秀社区在性能优化方面的探索和实践,希望能给大家带来一定的借鉴意义。

美图秀秀社区现状和挑战
众所众知,美图秀秀是一款被广泛使用的工具产品,从 2008 年发布以来,十年间 MAU 早已经过亿,是拍照修图领域的 No1 。在 2018 年 8 月份的时候,美图发布了“美和社交”战略,美图秀秀作为先驱产品也从工具开始往图片社区转型,自全量开发以来的非常短的时间里,秀秀社区用户量级迅速增长,用户登录率超过 50% 。
伴随着秀秀社区用户的急速增长,也给我们技术团队的工作带来了很大的挑战:
1. 相比于其它发布不到一年的产品,秀秀社区在流量上是超出其他产品的。秀秀社区依托于工具存在,尤其在节假日或者周末的时候,大家拍照、修图、逛社区,这些都会带来不小的流量。
2. 秀秀社区还处于快速发展的阶段,这对于我们的挑战就是产品迭代快。大量的产品需求,频繁地变更,导致我们没有大块的时间做系统的性能优化,我们做性能优化的过程就好像给一个时速 100 码的汽车换轮胎,需要团队深厚的技术积累和持续的耐心。
3. 美图公司在这些年技术上有很多的积累。这些积累被快速应用到了社区产品中,比如推荐,广告,它们以独立服务的方式被秀秀社区所依赖,这些服务也会影响秀秀社区的性能。
面临这些挑战,秀秀社区是如何来做性能优化的呢?在此之前我们需要先明确一下性能优化的核心关注点是什么。
性能优化关注点
先来看下秀秀社区的一个简化版的架构图(图一)。从图中可以看到,秀秀社区的服务端按照业务做了垂直的服务拆分形成了独立的服务层,服务层之下会依赖数据库等资源还有一些第三方的服务。除此之外,由于图片社区的产品特性,客户端还深度依赖于云存储,CDN 和图片云处理系统。那么当我们考虑性能优化的时候,我们不应该仅仅局限在服务端优化,还需要关注从端上开始完整的调用链条的性能。
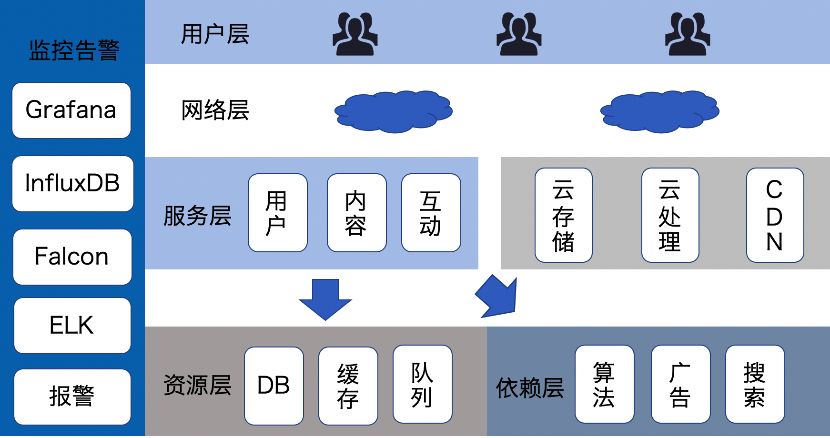
图一秀秀社区的一个简化版的架构图
因此,在秀秀社区优化的过程中,我们始终秉持的一个理念是:站在终端用户的角度来优化用户的使用体验。在用户使用你的App过程中,无论是卡顿、白屏还是错误都是不能有的,所有的技术上的优化都需要全局考虑,服务端优化是其中很小的一部分,我们需要考虑用户终端网络情况,考虑如何更快的展示图片,甚至需要考虑如何监控客户端的卡顿。这些都是需要联合客户端、服务端、运维,甚至产品一起来完成性能优化,这是一个多个团队协作的事情。
基于上述考虑点,我们需要对用户使用体验做评估,这样可以帮助我们找到系统中存在的问题以及量化优化之后的效果。一般来说,性能评估会有两个招数:
1. 通过一体化监控可以帮助我们了解已经存在的性能问题;
2. 通过全链路压测,帮我们了解流量翻了几倍之后的性能瓶颈,同时也可以帮助我们验证性能优化效果。
这两个手段在大厂都会有自己的解决方案,我这边主要来介绍一下秀秀社区这边的考虑。
一体化监控
谈到监控系统,一般的处理方式是通过报表反应服务端的性能指标情况,帮助我们发现性能问题。但是很多时候我们会发现,服务端接口的性能比较平稳,但却存在因为 DNS 解析、建立连接或者客户端卡顿导致用户的使用体验很差的情况,这个仅仅靠服务端的监控是无法感知的,所以我们更需要考虑的是端到端的监控。
我们的监控系统在设计上涵盖了从端上用户发起请求开始,到服务端业务处理,到资源层的数据响应这个完整的链路,这需要一系列的监控系统才能完成,我们称之为一体化监控体系。这一套监控体系主要有客户端监控和应用监控,辅以基础监控、资源监控、容器监控以及链路监控。通过这套从用户终端到操作系统的立体监控体系,可以帮助我们监控端到端的性能情况。
客户端监控
客户端监控– Hubble
我们自研了一套客户端监控体系,番号为「 Hubble 」(哈勃),期望可以像哈勃望远镜一样精确监控系统性能。使用 Hubble 会给我们带来三个方面的好处:
1. 真实地反馈用户的使用体验:Hubble 的所有的监控数据源均来自客户端的用户访问数据实时上报,能够准确的,真实的,实时的反应用户操作。
2. 它是性能优化的指向标:当做业务架构改造、服务性能优化、网络优化等任何优化行为时,Hubble 可以反馈用户性能数据,引导业务正向优化接口性能、可用性等指标。
3. 帮助我们监控 CDN 链路质量:之前的 CDN 的监控严重依赖 CDN 厂商,存在的问题是 CDN 无法从端上获取到全链路的监控数据,有些时候端上到 CDN 的链路出了问题, CDN 厂商是感知不到的,而 Hubble 弥补了这方面的缺陷,除此之外还可以通过告警机制督促 CDN 及时优化调整问题线路。
Hubble 的架构设计
由于 Hubble 主要关注的是用户网络情况,所以在设计之初,考虑到中国复杂的网络环境,我们主要选取了地区+运营商的维度来帮助我们做数据分析,从而确定性能瓶颈。它的优势主要体现在两个方面:
1. 出现局部故障的时候,通过地区+运营商的组合数据可以直接查出哪个地区可能出现问题,这对于我们做问题排查尤为重要;
2. 在调整 CDN 配置的时候,可以辅助做数据支撑,比如我们需要让某一地区用户不走 CDN 直接回源,可以使用 Hubble 来观察对于用户的使用体验的影响,帮助我们找到用户体验和成本的平衡点。
除此之外,我们还可以从客户端平台、域名和网络类型维度来聚合数据。有了这些维度之后,我们需要确定 Hubble 监控的指标:请求量、错误率和耗时情况。维度和指标就共同构成了我们的 Hubble 监控系统。
特别注意的是,上面提到的耗时是端到端的完整耗时,而不仅仅是服务端的耗时。为了方便针对耗时做针对性的优化,我们先把这个耗时做拆解和细化:
1. 首先,由于客户端线程切换或者异步队列的延迟,在建立连接之前我们有一个等待的时间;
2. 接下来需要做域名解析, TCP 握手建立连接,而我们是 HTTPS 服务,所以还要加上一个 SSL 认证的过程;
3. 这个时候,才会真正发起对接口的请求,而后等待服务端处理,我们会收到第一个响应包,也就是首包的时间;
4. 最后,还有依据响应包的大小接收所有数据的时间。
以上就是一次完整请求的过程。了解这个之后,我们可以针对请求耗时中的每个步骤做针对性优化。
Hubble 监控能让我们清晰的看到客户端的整体性能情况以及响应时间的详细数据。Hubble 的整体实现架构不是很复杂,如下图二所示。
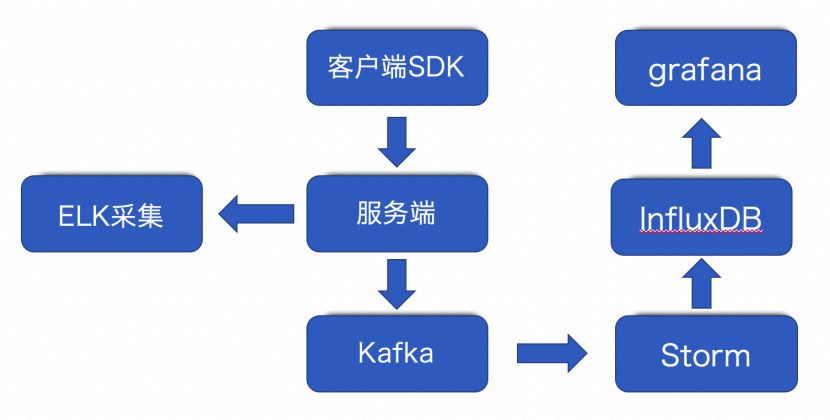
图二Hubble架构图
如图二所示,我们在端上植入一个 SDK 采样客户端网络请求,每 1 分钟按照定制的格式上报到服务端,服务端将原始数据写入 ELK 用作备份,同时将数据写入 Kafka ,之后有 Storm 处理程序对原始数据做聚合处理并且写入 InfluxDB ;最后就可以在 grafana 上展示了。有了 Hubble ,我们就相当于多了一双眼睛,任何调整和优化都有数据做支撑。
应用监控
除了客户端监控,重点要关注的还有应用监控,我们在做应用监控之前,首先考虑服务端关注的性能指标,我们参考了从谷歌的”四个黄金指标“衍生的 RED 指标体系,吞吐量( Request Rate )、错误率( ErrorRate )和响应时间( Duration )。先来看下影响这些指标的内在因素和外部因素。
内在因素:对于 Java 应用来说主要是 GC 暂停,也可能是一些锁的阻塞或者是线程池的异步队列堆积。
外部因素:主要是依赖的存储资源还有服务的影响,还有就是内网地波动以及容器宿主机的性能。
那么我们在做服务端监控的时候,如何展示这些指标和因素的关键数据,来帮助我们来发现问题和分析问题就显得尤为重要。基于此,我们将服务端需要监控的数据拆解为四个部分,分别是访问量趋势数据、资源 profile数据、JVM 数据和线程池数据。
访问量趋势数据
访问量趋势数据是用来展示系统整体的性能情况。如上文所说,我们在服务端的指标上需要关注吞吐量、错误率和响应时间,访问量趋势数据能完全展示这些性能数据。
1. 在吞吐量上,我们除了需要展示整体数据以外还需要展示慢请求比例;
2. 在响应时间上,我们关注的是平均响应时间,但是在只有少量慢请求的情况下,我们很难从平均响应时间上看出问题,所以还需要知道某一个响应时间区间的比例是多少,也就是响应时间的分布情况;
3. 在错误率上,我们需要对错误做分类,这个分类是由业务来决定的,比如说认证的错误率上升可能影响不大,但是如果有些破坏性的错误比例上升了,我们就要关心一下是否是业务出问题了。
这些数据我们可以从 tomcat 和 lb 的 access log 以及业务的日志中获得。当我们从访问量趋势发现有性能问题后,我们需要怎么排查呢?下面要说的几张报表可以帮助我们定位问题。
资源 profile 数据
首先是资源 profile 数据。在我们日常的排查问题时,比较常见的情况是依赖的资源或者服务出现响应时间上的波动,这时我们需要知道具体哪个端口、哪个实例或者哪个服务出了问题,这就是我们的资源profile 数据。
当我们需要对资源客户端和微服务客户端进行改造时,在调用后端资源和服务的时候打印 profile 日志,并且把这些日志数据发送给监控系统,经过聚合之后就形成了资源 profile 数据。
Profile 报表目前主要用来检测数据库、缓存和第三方服务的响应情况,它是我们排查性能问题的利器,可以很方便的定位是哪种资源的哪个接口或者哪个 URL 出了问题,然后再做定向的排查。
JVM数据
下一个要说的是监控 JVM 信息的报表。我们知道由于对于内存的过度使用,高并发或者参数配置不当,会导致应用频繁的触发 GC ,带来 stop the world 的暂停,同时也会抢占 CPU 资源,影响整体的吞吐量。所以我们需要监控整体内存的大小、每个内存区的大小以及GC 停顿的间隔和时间。
有了这份动态数据之后,我们还可以对JVM 的参数做一些针对性的优化。比如在我们的业务模型下,我们的内存可以设置为多少、 GC 算法要使用什么等等,从而保证我们 GC 停顿时间控制在可接受的范围之内,进而达到性能优化的目的。
线程池数据
最后我们对线程池也做了监控。我们使用线程池的目的是并发执行任务,减少响应时间,但是如果线程池中线程数设置不合理,或者是任务执行时间较长,就会造成线程池中活跃线程数大量增长,线程池内的队列中任务堆积,阻塞新提交任务的执行,尤其是针对 tomcat 线程池的监控,一旦出现堆积,结果将是毁灭性的。因此,我们会定期的打印线程池的活跃线程数和任务堆积数。
除了通过一体化监控相关指标,发现和定位问题,压测也是我们做性能问题排查的重要方法。
全链路压测
美图秀秀做全链路压测有三个目的:
1. 通过全链路压测帮助我们发现潜在的性能瓶颈,在流量达到一定量级的时候,哪些服务或者组件会先出问题,这样我们可以做出一些预案来应对;
2. 压测也可以为我们做容量评估提供数据支撑,这不仅仅是需要部署多少个 pod ,也可以让我们知道当到达性能上限的时候,CPU 使用率是多少,内存阈值要设置成多少;
3. 在压测的时候做预案演练,因为压测一般会安排在流量低峰期进行,这样我们可以降级一些服务来验证预案效果,且尽量减少对线上用户的影响。
全链路压测的实现
美图秀秀的压测平台在设计上也是参考了其他大厂的成熟做法。其实现图如图三。
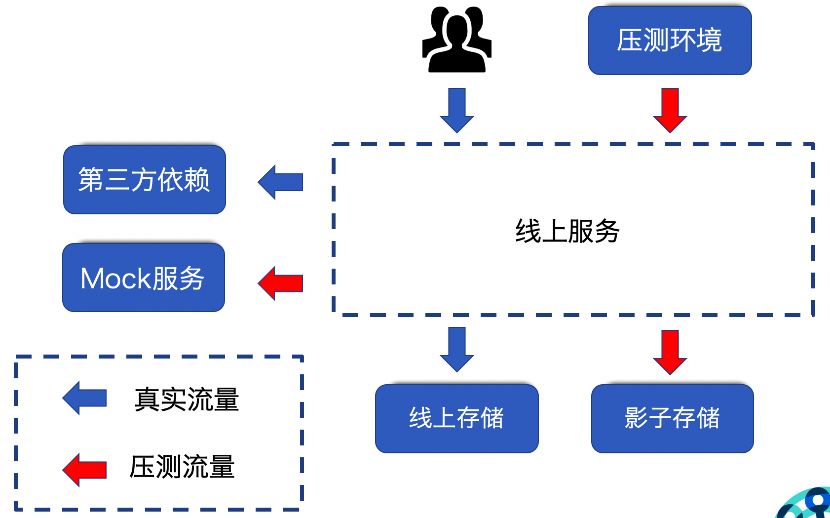
图三秀秀压测平台实现图
1. 首先我们会将线上的流量拷贝存储起来并且对压测流量打上标记。这么做的原因是我们需要对压测流量做一些特殊的处理,比如一些对于曝光数据比较敏感的服务如广告服务,推荐服务,我们是不能将压测的流量直接打过去的;
2. 另外也要屏蔽压测对于大盘的统计的影响,我们会包装一些 Mock 服务来模拟真实的系统;
3. 最后对于上行流量,我们会把压测产生的数据写入到单独的影子存储里面,以达到隔离的目的。
在压测的过程中我们会逐步地增加流量,并且时刻关注系统监控指标,一旦响应时间有比较大的波动就立刻终止压测,排查问题原因,在问题解决后,再进行新一轮的压测。如此反复,直到到达目标的吞吐量为止。
我们通过一体化监控和全链路压测这两种手段来帮助我们评估端到端系统性能,不仅能帮我们找到优化的方向,也可以帮助我们验证优化的效果。下文中我将给大家具体介绍下美图秀秀社区做的一些优化的实践。
美图秀秀性能优化实践
秀秀作为一个社区,流量最大也是最重要的页面就是首页,这相当于微博的信息流。而我们从点开首页到首页完全渲染,时间分为两个大部分:一个是服务端接口的响应时间;另一个是图片加载的时间,这是由秀秀社区的产品特性决定的。我们对这两部份时间分别做细化,选取几个关键点来做重点的说明,这几个点分别是 DNS 解析优化、图片传输优化以及服务端接口响应时间优化。
DNS解析优化
先来说下DNS 的优化。最初我们从两个途径发现 DNS 解析存在可优化的空间,一个是部分用户反馈客户端错误,一个是从 Hubble 监控中发现 DNS 时间存在毛刺。
我们知道,在做 DNS 解析的时候,我们先会查询运营商的 LocalDns ,如果 LocalDns 没有缓存,会从 root dns 开始做逐级递归查询直至从权威DNS 查询到结果为止,并且会在运营商的 LocalDns 上缓存起来。但是这会有几个问题:
· 一旦 LocalDns 缓存失效,我们就需要请求公网 DNS 服务器做域名解析,在网络波动的情况下查询性能上会有尖刺;
· LocalDns 这个东西是很不靠谱的,有些小的运营商为了节省流量,会把一些域名解析到内网的内容缓存服务器上,甚至会解析到广告或者钓鱼网站上,出现域名劫持的情况;
· 有些运营商它自己不去解析域名,而是把解析请求转发到别的运营商上,这就出现解析的 IP 和请求源来自不同的运营商,导致流量跨网。
在业界针对上述的问题是有成熟的第三方解决方案,就是 HttpDns 。HttpDns 绕过了 LocalDns 这个原罪直接访问 Http DNS Server ,也就能避免了这几个问题。但是即使是使用了 HttpDns ,从 Hubble 监控来看平均的 DNS 时间也要 200-300ms ,所以我们要考虑一种方式可以尽量减少 DNS 的解析时间。
我们内部有一套解决这个问题的方案,番号为FastDNS ,它其实是一个客户端 SDK ,在组件中我们可以通过代码或者服务端下发的方式指定一些域名,在 SDK 启动的时候异步的预先做解析,并且把解析结果写入到一个LRU 缓存里面, SDK 每隔一段时间会定期地对LRU 缓存中的 IP 信息做健康检查,如果检查失败就会从缓存中去掉。在本地网络环境发生变化的时候,也会清空缓存来保证缓存数据的正确性。
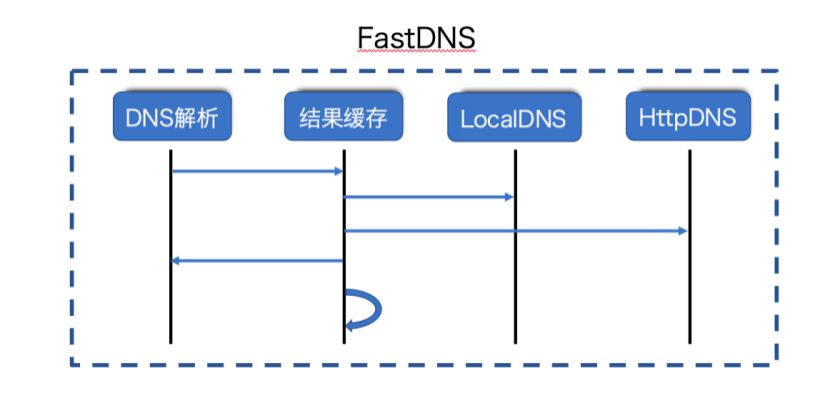
图四
这个异步解析有两种策略,一种是走 LocalDns ,另一种是走 HttpDns 。这个策略的选择是服务端来下发的,我们目前统一走 LocalDns ,如果解析失败、超时或者不符合预期的话会走 HttpDns 解析。
当然,我们可以指定某个域名优先走 HttpDns ,但是HttpDns 解析出来的结果也可能不符合预期,我们需要一些容错的机制保证,我们在对IP 地址做健康检查的时候,如果发现解析 IP 地址不合格,就会标记这个域名,如果域名被多次标记 HttpDns 解析错误的话,我们会把这个域名降级为 LocalDns 解析
引入 FastDNS 之后,经过测试验证平均耗时大概减少 50% ,最大耗时可以控制在 200ms 之内,而传统的 LocalDns 方式最大 DNS 解析时间会到1秒以上。从 Hubble 监控来看,平均Http时间减少了80-100ms。
图片传输优化
说完了DNS 解析优化,再来分享下我们在图片传输优化方面做的一些事情,这主要包括以下三个方面:
1. 融合调度;
2. 图片大小的优化;
3. 在端上做一些预加载的策略。
我将着重和大家分享一下融合调度和图片大小优化方面我们的一些经验。
先来看看融合调度,也是我们内部自研的系统名叫Chaos 。在接入融合系统前,我们图片只能配置一个CDN 的地址,当这家 CDN 出现故障时我们只能在接到报障之后手动地切换,这样会延长故障的时间,也有损用户体验。于是我们考虑是否可以给同一张图片接入多家CDN 地址,并且在故障的时候做到自动切换呢?这就是融合调度系统在做的事情。
下面是融合调度系统的流程示意图,从图中我们可以看出融合调度系统主要由三部分组成:SDK 、服务端和 MeituDNS 。
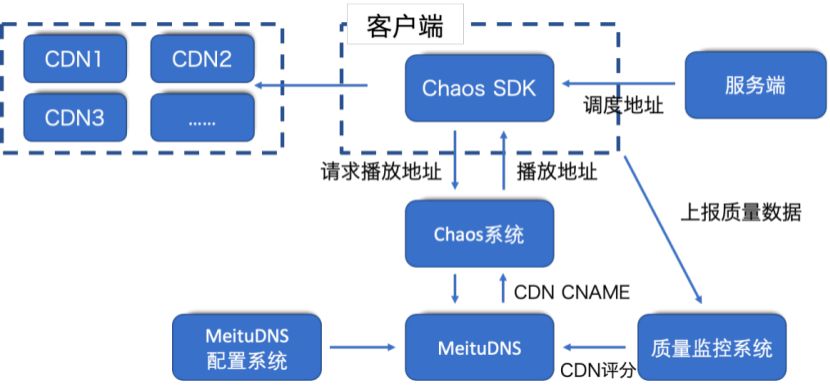
图五融合调度整体实现图
当服务端在下发图片地址的时候,会生成一个调度的地址,端上的融合调度SDK 会把这个调度地址发送给融合调度服务端,融合调度服务端把它转换成真正的资源地址之后会请求 MeituDNS 来得到 DNS CNAME 。这里我们可以为一个域名配置多个 DNS CNAME 。同时我们会有一个质量监控平台给 CDN 打分,这个打分的数据来自于客户端对于 CDN 质量的真实上报,比如说响应时间情况以及错误发生数据。有了打分数据融合调度系统就可以决策我们优先使用哪一个 CDN 或者每一个 CDN 的流量分配比例是什么样的,端上也就可以知道该从哪一个 CDN 获取数据。
接入融合调度系统之后,我们从单一CDN 地址变成了动态使用的多 CDN 地址,提升了图片下载的容错率和用户的使用体验。
但是这个无法缩短图片下载的时间,如果要缩短下载时间,需要考虑如何减小图片的大小,同时还需要考虑图片质量,我们不能以过度地损失图片的质量来换取图片大小地减少,这样会造成图片的失真。考虑到图片的打开时间,我们还要保证更快的编解码速率。
综合上述几方面的考量,我们的思路是综合评估不同的图片编码格式,达到提升码率的目的。
我们备选的图片格式有几种:JPEG 、 WebP 和 HEIF 。试验的方法如下,我们从秀秀平台选取热度 Top500 的图像集合,分别用 HEIF ,libwebp 、 MozJPEG 、libjpeg-turbo等编码器对图片做编码,以 SSIM 来评估图片失真情况,考察图片压缩性能,也就是输出图片码率大小。通过实验表明,在低分辨率下,HEIF 相对于 WebP 平均大约节省 20% 的码率,相比于 JPEG 节省50%,而随着源图分辨率增加, HEIF 的优势越来越明显,码率节省呈上升趋势。另一方面,考虑到用户查看图片的体验,我们也需要考虑解码速率。经过测试,在 iOS 平台下,HEIF 在解码速率上无论硬解还是软解都会优于 WebP ,但在安卓平台下,HEIF 的软解效率不佳,只有Android P 系统下的部分机型才支持对 HEIF 图片格式做硬解,所以安卓平台目前还是用WebP。
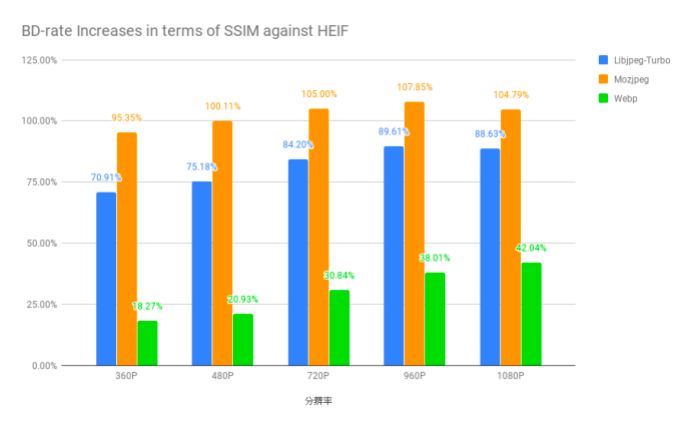
图六
目前秀秀社区在 iOS 上推进 HEIF 格式的图片,这样相较WebP 大约可节省 20% 的图片下载带宽。不过有得必有失,HEIF 在编码效率上相比 WebP 和 JPEG相差较远,编码时间大约是 JPEG 的 45 倍,是 WebP 的 12 倍,因此,我们采用了异步的方式来对图片做 HEIF 编码。
服务端优化
在说服务端优化之前,先来看图七。这个是在 2015 年 3 月份 Rebel Labs 做的调研报告中的一张结论图。
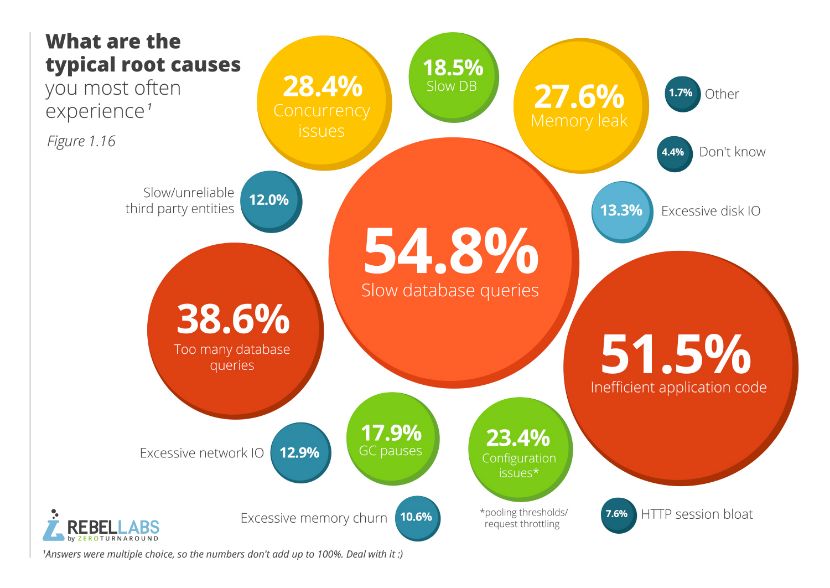
图七
从图七中不难看出,日常工作中遇到的性能问题中,因为数据库慢查询占54.8% ,不高效的代码占到 51.5% ,而我们经常提到的 GC 问题只占 17.9%,IO 问题也只占 13% 。通过此图告诉我们在分析问题的时候一定要避免盲目,通过一些排查方法来帮助我们找到问题的根本原因,这会让我们的优化事半功倍。
我们常用的排查性能问题的方法有下面几个:
· 其一是使用一些工具,我们一些常用的工具有这么几类,一类是通过类似xxstat 、xxtop 了解整体资源负载情况;第二类是通过例如 Perf,DTrace 等对 CPU 做 profile 的;最后是通过一些Java特有的工具来分析内存情况以及线程情况,如 jmc 、jstat 、jmap ;
· 其二我们还有一些日志,主要是业务日志还有 trace 日志,系统日志,GC 的日志也需要保留;
· 最后就是之前提到的监控,我们从监控上可以看到很多信息,有些简单的问题可以从监控数据中直接得到结论。
真实案例剖析
下面介绍一个真实的案例,在案例中可以看下我们是如何使用上面的方法来分析和优化性能问题的。2019 年年初秀秀的流量增长很快,我们发现系统在重启的时候性能衰减很厉害,慢请求比例会达到 10% ,这极大的影响用户的使用体验,并且也给后台系统的稳定性埋下了炸弹,所以我们需要来集中精力解决它。首先,通过查看报表我们发现三个异常的情况:
1. memcached、 Redis 、 MySQL 以及依赖服务的响应时间都有所波动;
2. CPU 使用率上升一倍;
3. Safepoint 造成的 STW 频率大幅上升,从每秒两次上升到每秒20次。
经过分析判断,发现依赖服务和资源的时间波动和Safepoint 的频率上涨有关,于是我们先去解决这个问题。
首先我们在压测环境下复现了这个问题,并且在启动参数中增加打印详细安全点信息的日志。在重启后我们发现日志中出现大量撤销偏向锁类型的安全点日志。众所周知,偏向锁的目的是在无竞争或者低竞争下,某一个线程获得了锁之后,消除这个线程锁重入的开销,偏向于同一个线程再次获得锁。但是当系统竞争激烈时,其它线程尝试获得锁,持有偏向锁的线程会撤销偏向锁,这是需要等待所有线程到达全局安全点的,所以会造成系统暂停的情况。我们通过增加不启动偏向锁的参数,使得问题有了很大地缓解。
但是CPU 使用率上涨一倍的问题并没有得到解决,我们通过给压测环境增压后慢请求再次出现,这个时候报表上的表现有两个:新区 GC 的停顿时间从 20ms 上涨到 100ms , CPU 使用率上涨了一倍。
我们尝试通过分析 GC 日志和调整参数来降低新区 GC 的停顿时间,但都无功而返。那是否是因为CPU 使用率上升导致的 GC 线程无法抢占到 CPU 的时间,从而导致 GC 的响应时间增长呢?于是,我们在重启的时候对CPU 做 profile ,果然发现 JIT 线程占用了大量的 CPU 资源。我们知道JVM 在启动的时候是按照解释方式来执行的,在应用运行一段时间之后,才会对字节码做 C1 和 C2 编译,提高热点代码的执行性能。所以我们的解决方案是预热,在容器重启之后先只放 10% 的流量,在低负载的情况下让系统完成热点代码的编译,然后再放全量。多次尝试并且试验后,可以看到收效还是非常明显的。慢请求比例从原先的 10% 下降到 0.5% 以下。
从这个案例我们也可以看到性能优化另外两点:一个是性能问题的原因可能是多方面的,需要不断的追究根本原因;另一个是压测环境真的非常重要,它可以帮助我们复现问题,也可以验证性能优化的结果。
总结
通过秀秀社区化过程中性能优化的具体实践,可以总结成三句话,希望对你有所帮助:
一、 性能的优化目标是关注用户体验,我们做的事情都要从终端用户角度出发;
二、 一体化监控和全链路压测可以帮忙我们发现性能问题,验证优化效果;
三、 性能优化是一个系统工程,需要后端,前端,架构, SRE 等多个团队共同协作完成。
参考阅读:
技术原创及架构实践文章,欢迎通过公众号菜单「联系我们」进行投稿。转载请注明来自高可用架构「ArchNotes」微信公众号及包含以下二维码。
高可用架构
改变互联网的构建方式
长按二维码 关注「高可用架构」公众号