各刷五大数据集新高,创新工场两篇论文入选 ACL 2020




研究背景

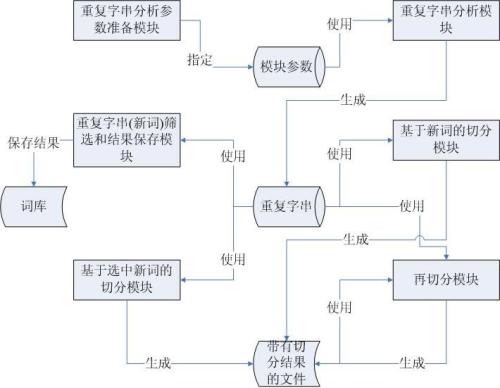
中文分词和词性标注任务技术难点

解决方法
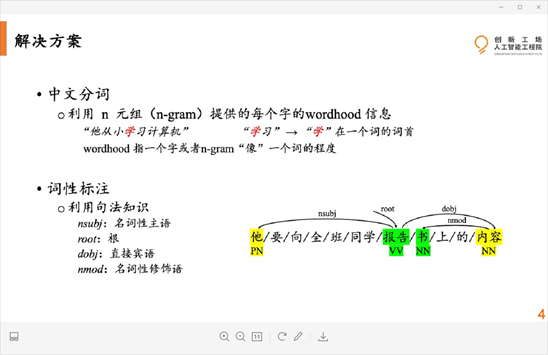
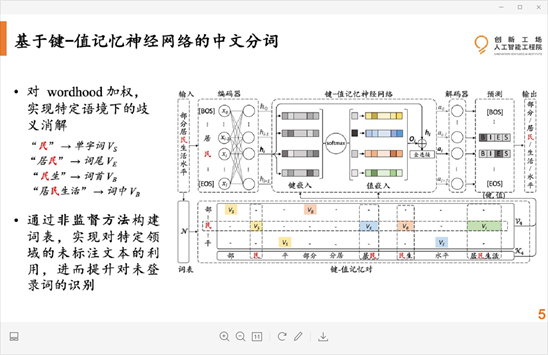
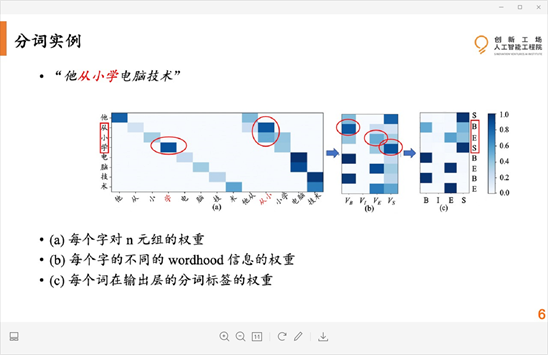
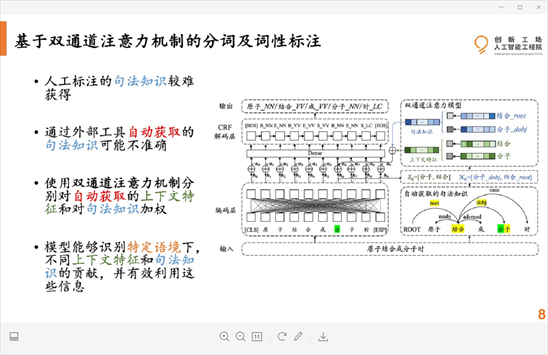

实验结果
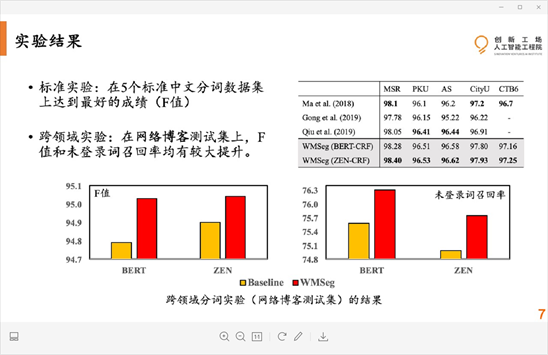
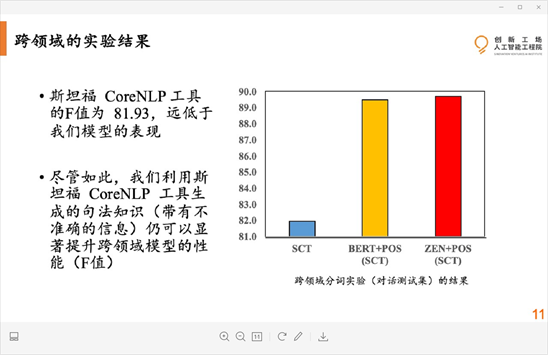
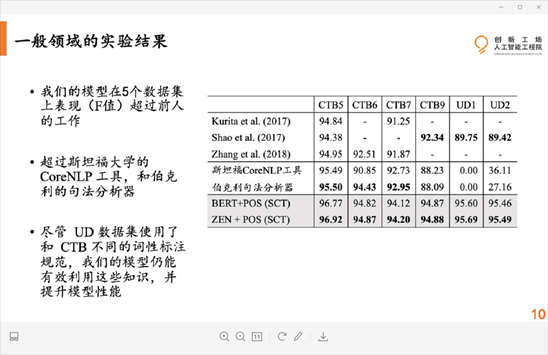
技术创新总结



登录查看更多
相关内容

专知会员服务
48+阅读 · 2019年10月21日
Arxiv
7+阅读 · 2018年5月21日
Arxiv
3+阅读 · 2018年5月2日



相关VIP内容
专知会员服务
48+阅读 · 2019年10月21日
相关资讯
相关论文
Arxiv
7+阅读 · 2018年5月21日
Arxiv
3+阅读 · 2018年5月2日