最新进展概述:澄清式提问辅助理解信息检索中的用户意图

©PaperWeekly 原创 · 作者|金金
单位|阿里巴巴研究实习生
研究方向|推荐系统
用户使用搜索引擎的过程中,通常很难用单一的查询表达复杂的信息需求。在真实应用的过程中,用户需要根据当前搜索引擎的展示结果反复修改查询词。这一过程极大地增加了用户搜索的负担,影响了用户的搜索体验。


论文标题:Asking Clarifying Questions in Open-Domain Information-Seeking Conversations
论文来源:SIGIR 2019
论文链接:https://arxiv.org/abs/1907.06554
1.1 任务流程
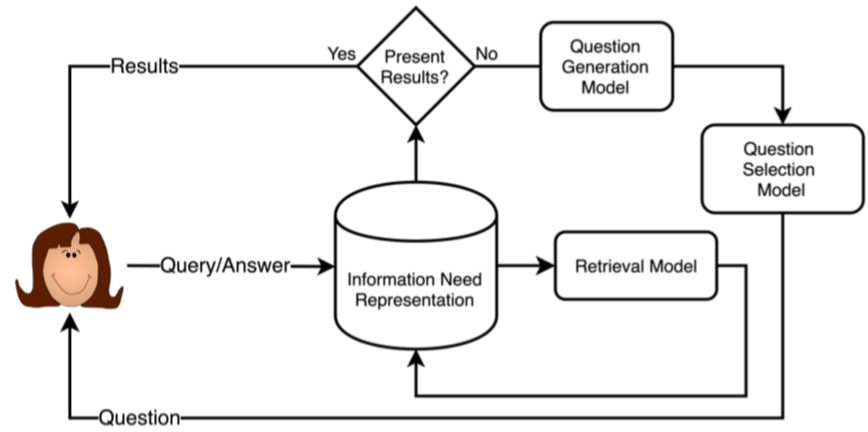
1.2 数据收集
形成查询-意图集合:作者使用 TREC Web track 09-12 中的 198 条主题作为初始查询,并将各主题分解为它包含的不同方面作为用户意图。统计信息显示,每个查询平均有 3.85 项意图,完整数据集共包含 762 项查询-意图对。
提出澄清式问题:作者邀请了多名标注人员,使其模仿对话代理的行为。标注人员根据已有的各主题包含的意图或搜索引擎自动生成的查询推荐为依据,为各查询提出澄清式问题。
-
编辑问题答案:作者邀请另一组标注人员,针对每一个澄清式问题,在给定查询和意图描述的情况下,手动编辑问题答案。
经过对无效问题的过滤,统计信息显示,完整数据集共包含 2639 条澄清式问题与 10277 项问题-答案对。
1.3 问题检索-选择模型

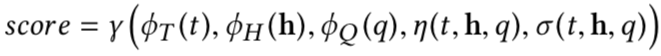


论文标题:Generating Clarifying Questions for Information Retrieval
论文来源:WWW 2020
论文链接:https://dl.acm.org/doi/pdf/10.1145/3366423.3380126
2.1 监督学习算法QLM
此后作者根据 query string, entity type of the query, the entity type for the majority aspects of the query 三类信息,补全以下模版,生成训练模型的弱监督信号:

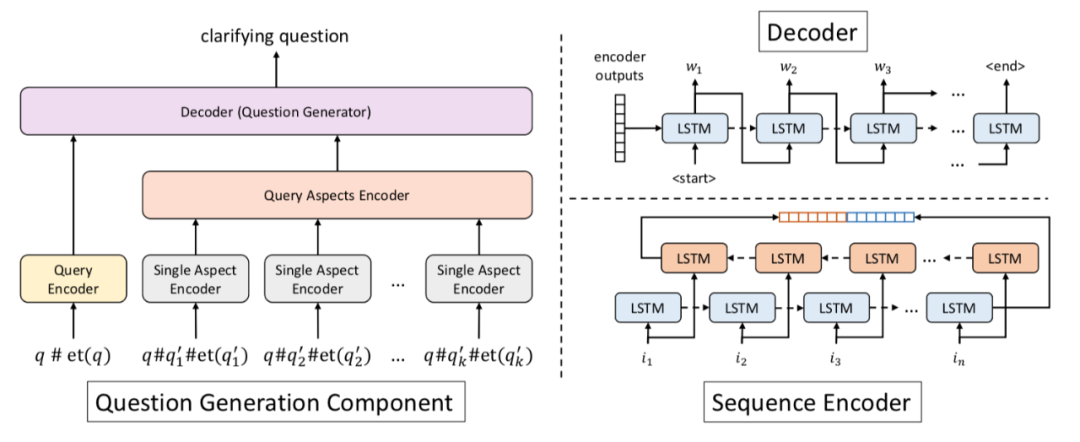
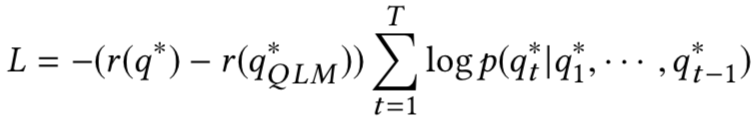
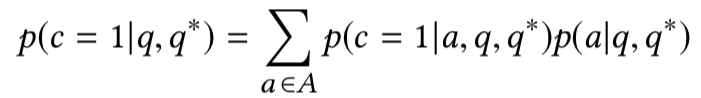
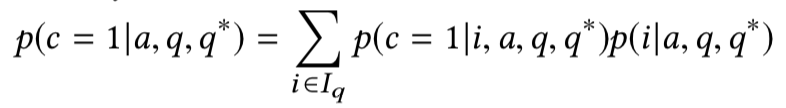
所提及的三部分概率计算方法如下:
-
:该部分仅取决于查询和意图,与提出的问题和候选答案相独立,故可使用 NCF 算法得到每一 aspect 的概率分布 替代。 -
:该部分取决于答案和意图的匹配程度,具体计算方法由两者词向量余弦相似度平均值得到。 -
:该部分使用 query text, query entity type 和 answer entity type 三部分计算,构造输入以上三者输出所有候选答案的类 word2vec 模型。具体实现候选答案和 answer entity type 可用新增查询词项 及其 entity type 替代。
作者使用人工标注数据集验证生成问题的质量,发现强化学习算法 QCM 优于监督学习算法 QLM 和模版补全算法。

用户交互行为分析

论文标题:Analyzing and Learning from User Interactions for Search Clarification
论文来源:SIGIR 2020
论文链接:https://arxiv.org/abs/2006.00166
3.1 交互行为分析
作者使用上文提及的第二篇论文中提到的问题生成方法,在真实的搜索环境中生成澄清式问题,总结了以下因素对用户参与澄清式问题的影响:
问题生成模版:更具体的问题会有更多的用户参与;
候选答案数量:候选答案超过2个后用户参与程度变化不大;
答案选择的分布:问题答案点击分布的熵最大或中等水平时,用户参与程度最高;
查询长度:查询较长时,用户参与程度较高;
查询类型:自然语言问题类的查询,用户常参与澄清式问题;
-
历史点击数据:被点击的 URL 数量和点击分布的熵越大时,用户参与程度越高。
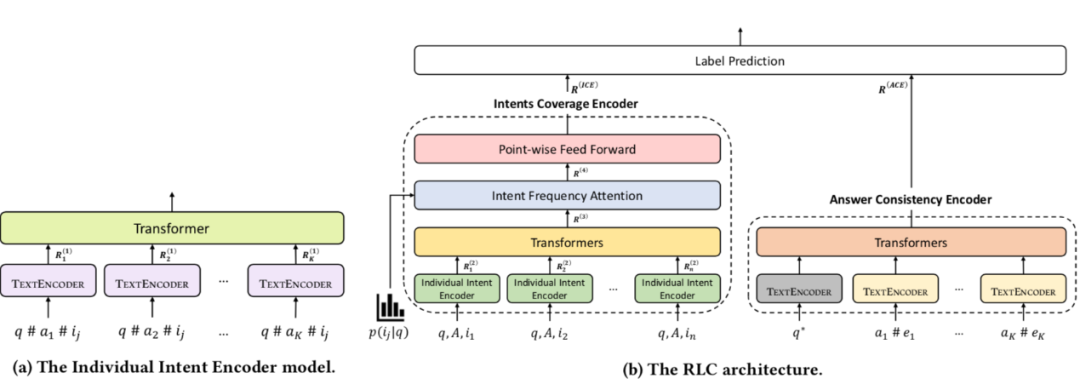
3.2 问题选择模型
作者在此基础上,提出了查询-问题表示生成模型,从而根据当前查询选择澄清式问题。


论文标题:Guided Transformer: Leveraging Multiple External Sources for Representation Learning in Conversational Search
论文来源:SIGIR 2020
论文链接:https://arxiv.org/abs/2006.07548
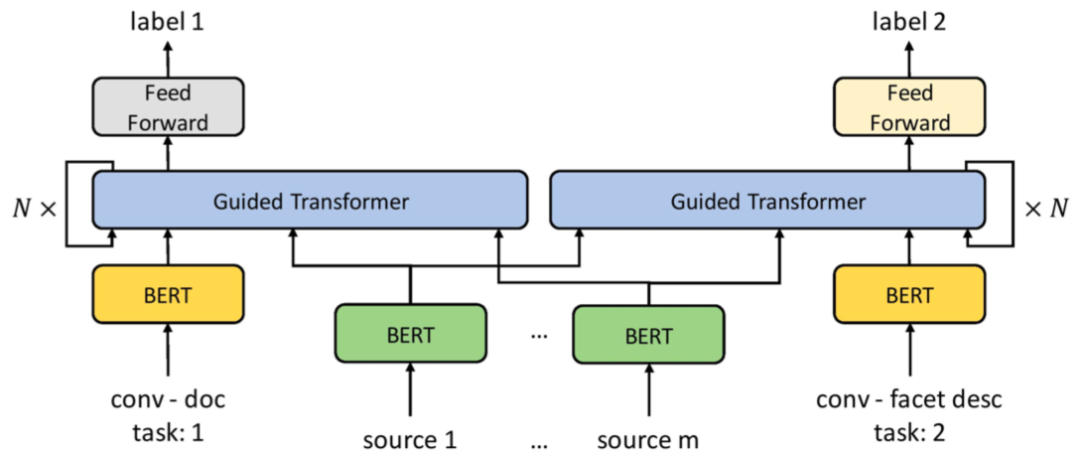
本文发表于 SIGIR 2020,提出了一种基于 Transformer 的多任务多资源框架,用于解决下一问题预测和文档排序任务。
具体来说,作者利用两种类型的外部 source(即伪相关反馈获得的文本和澄清式问答记录),结合查询与目标文本/问题,输入 BERT 和 Guided Transformer 模型,生成相关性表示信号,预测目标问题的被选择概率或目标文本的相关性标签。
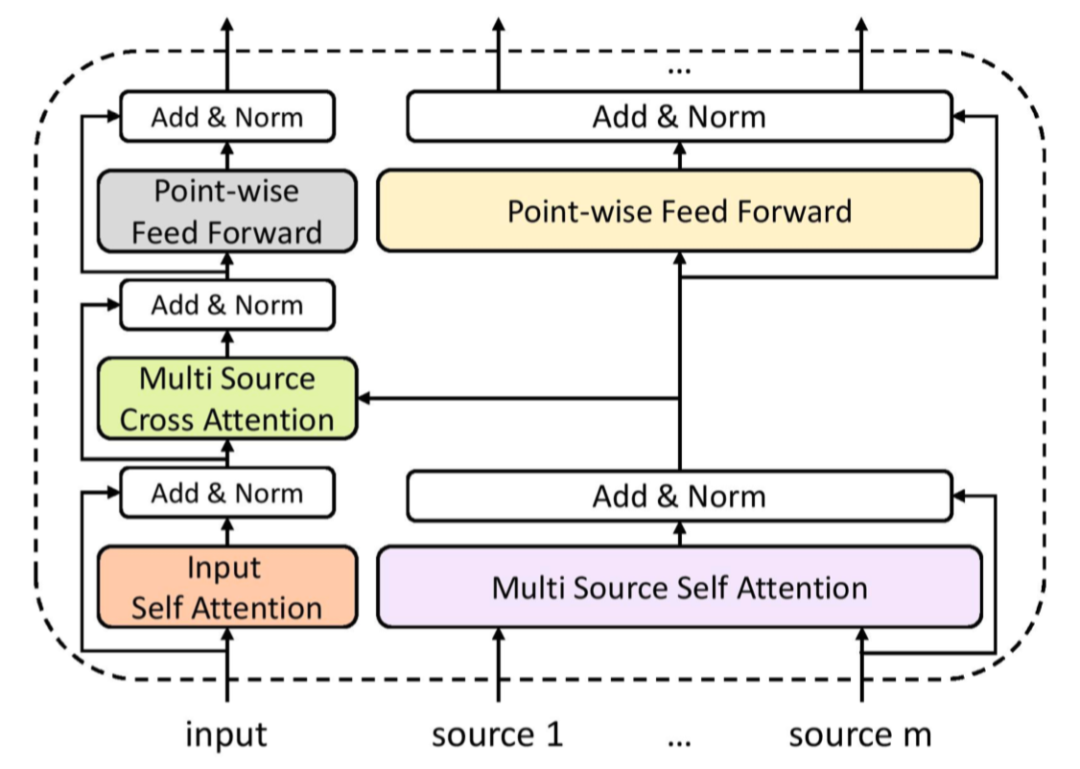
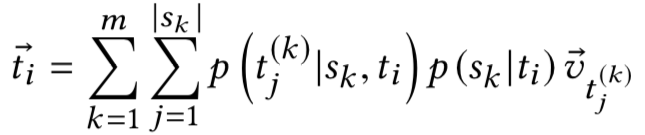
4.2 多资源多任务学习框架
具体来说,该框架将查询、澄清式问答和目标文本拼接输入 BERT 模型(输入形式:[CLS] query tokens [SEP] clarifying question tokens [SEP] user response tokens [SEP] document tokens [SEP]),并通过多层 Guided Transformer layer,将 [CLS] token 作为相关性表示信号,预测最终标签。

更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。






