人类一败涂地?DeepMind推出Agent57,在所有雅达利游戏上超越人类玩家
机器之心编辑部
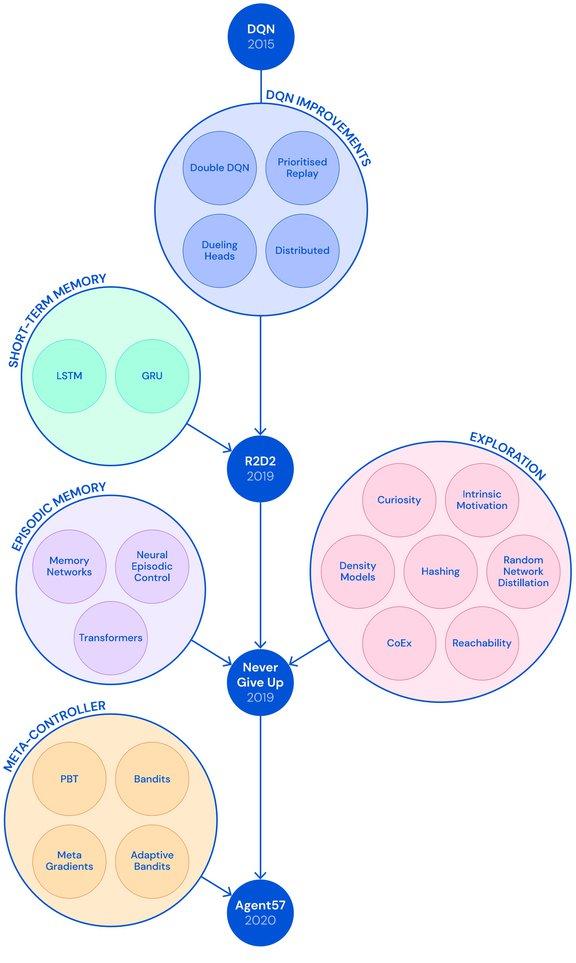
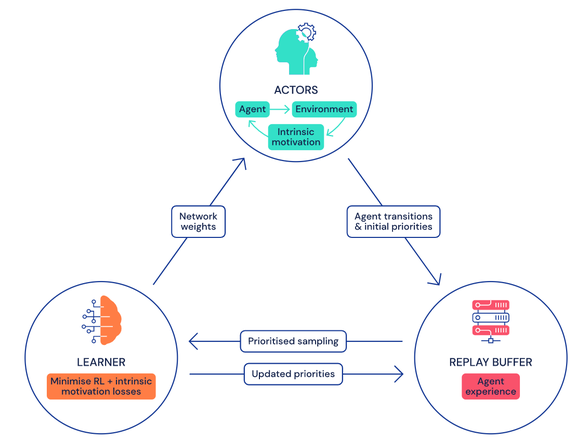
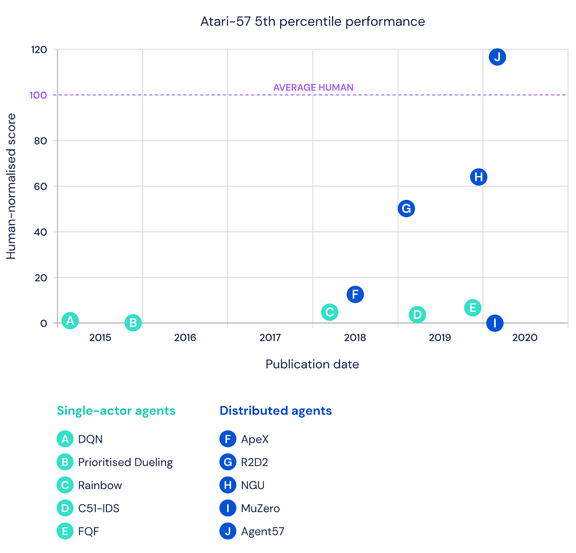
让单个智能体完成尽可能多的任务是 DeepMind 一直以来的研究目标,也被该公司视为迈向通用人工智能的必经之路。去年,DeepMind 推出的 MuZero 在 51 款雅达利游戏中实现了超越人类的表现。时隔数月,DeepMind 在这一方向上更进一步,在 57 款雅达利游戏中全面超越人类,在这一领域尚属首次。
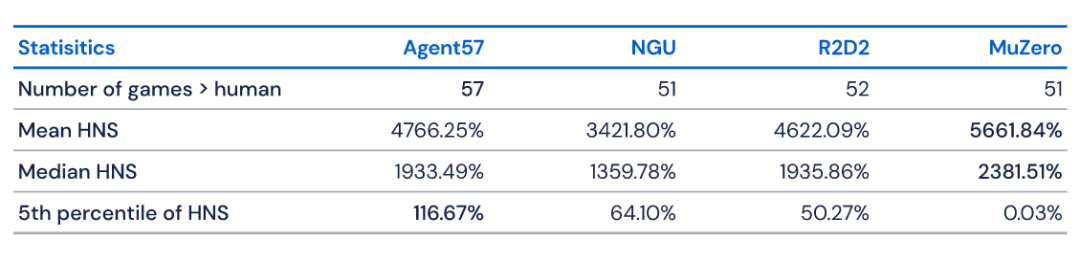
https://venturebeat.com/2020/03/31/deepminds-agent57-beats-humans-at-57-classic-atari-games/
登录查看更多
相关内容
专知会员服务
48+阅读 · 2019年12月24日
专知会员服务
13+阅读 · 2019年11月26日
Arxiv
16+阅读 · 2019年12月16日
Arxiv
40+阅读 · 2019年6月4日
Arxiv
8+阅读 · 2019年3月4日



相关VIP内容
专知会员服务
48+阅读 · 2019年12月24日
专知会员服务
13+阅读 · 2019年11月26日
相关资讯
相关论文
Arxiv
16+阅读 · 2019年12月16日
Arxiv
40+阅读 · 2019年6月4日
Arxiv
8+阅读 · 2019年3月4日