编辑 | 陈彩娴
论文标题:
Self-training Improves Pre-training for Natural Language Understanding
论文作者:
Jingfei Du, Edouard Grave, Beliz Gunel, Vishrav Chaudhary, Onur Celebi, Michael Auli, Ves Stoyanov, Alexis Conneau
论文链接:
https://arxiv.org/abs/2010.02194
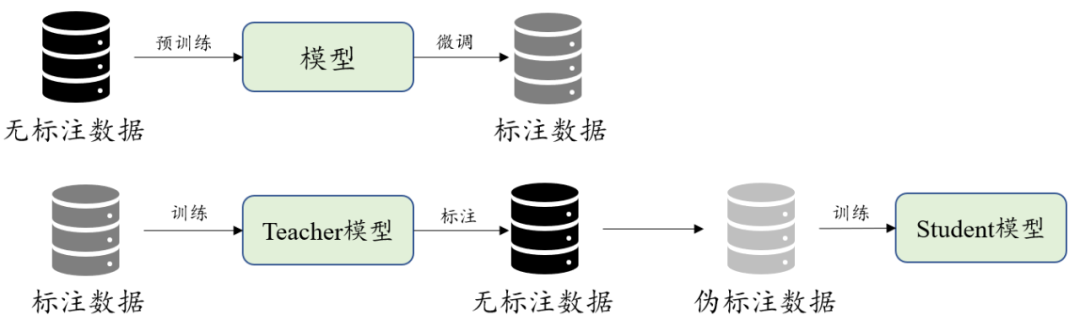
自训练与预训练
预训练(Pre-training)从广义上来讲,是指先在较大规模的数据上对模型训练一波,然后再在具体的下游任务数据中微调。大多数情况下,预训练的含义都比较狭窄:在大规模无标注语料上,用自监督的方式训练模型。这里的自监督方法一般指的是语言模型 。
除了预训练之外,我们还经常在图像领域看到它的一个兄弟,自训练(Self-training) 。自训练是说有一个Teacher模型
和一个Student模型
,首先在标注数据上训练
,然后用它对大规模无标注数据进行标注,把得到的结果当做伪标注数据去训练
。
显然,预训练和自训练都用到了大规模无标注的数据,只是二者的处理过程不同。而且,其中非常重要的一点是,预训练始终对针对一个模型进行操作,而自训练却用到了两个模型,前者是直接从无标注数据中学习,而后者是间接地从数据中学习。它们的区别可以用下图表示:
那么,一个自然的问题是: 这两个方法可以结合起来达到更好的效果吗? 本文给出了答案: 当然可以!
首先预训练一个模型,然后把这个模型在标注数据上训练后当做
,再用它去标注另外一批无标注数据,把得到的伪标注数据用来训练
,最后在推理测试的时候使用
即可。
从这个过程中可以发现,预训练是为了更好地自训练,自训练是为了更好地训练
,二者结合,缺一不可。
结合自训练与预训练,比单纯的预训练取得了大幅度的效果提升;
为了使伪标注数据更加契合下游的具体任务,提出了SentAugment,一种特定领域的数据抽取方法,减少通用语料造成的噪声干扰;
在知识蒸馏和小样本学习任务上也取得了突出的结果,证明自训练+预训练的优越性。
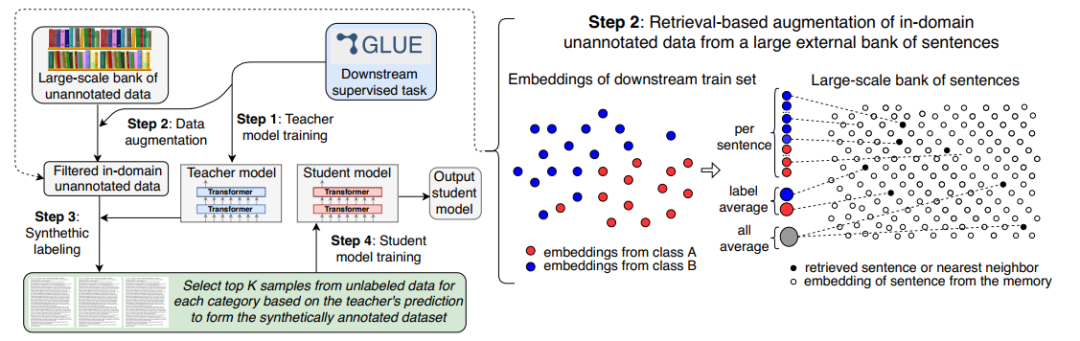
自训练处理流程
本文所提出的方法可以用下面的图表示,大体分为四步:
将一个预训练模型(本文使用RoBERTa_Large)在标注数据上训练,作为教师模型
;
其中的1,3,4步都是确定的
, 所以我们重点关注如何使用
从海量通用语料库
中抽取出领域相关的语料
。
通用语料库D
来自Common-Crawl,直接把文档切分为句子,然后以句子为基本单位进行数据提取。
本文使用句子编码方法,用一个编码向量去表示每一个句子。这个句子编码器在多个复述(Paraphrase)数据集上训练,并且还使用了BERT的掩码语言模型在多语言语料上训练,之后就可以用于编码每个句子,得到各自对应的特征向量。在后文中,我们默认使用Transformer编码器。
句子编码只能表示通用语料库
中每个句子
的含义,还不能区分哪些句子是符合领域要求的,这就需要用一个特殊的任务编码,作为查询条件去表示我们想要的句子是怎样的,也就是说,只需要计算句子编码和任务编码的余弦值,就知道这个句子是不是符合要求。为此,考虑三种任务编码:
All-Average: 将训练
所用的所有句子编码平均起来作为任务编码;
Label-Average: 将训练
所用的每个类别的所有句子编码平均起来作为各个类别的任务编码;
Per-Sentence: 将训练
所用的每个句子都作为一个单独的任务编码。
在获取任务编码后,就可以把它(们)作为询问,根据余弦值大小,从通用语料库中抽取相关的句子,这可以减少通用语料对下游特定任务的噪声干扰。对于每个类别,只抽取Top-K个句子,并且对提取的句子,还要满足
能取得较高的置信度。
提取了相关领域的数据后,用
对其中每一个句子
预测它的标签是什么:
,得到其软标签或者one-hot硬标签,这取决于训练
的方法是什么。但无论如何,到此为止我们都得到了一个伪标注数据库
。
在得到伪标注语料
后,就可以用它去训练
了。为此,我们考虑三种训练方法:
自训练(Self-Training) :将另一个预训练的RoBERTa_Large作为
,使用one-hot硬标签在
上训练;
知识蒸馏(Knowledge-Distillation) :将一个预训练的RoBERTa_Small作为
,使用软标签在
上训练;
少样本学习(Few-Shot):训练
所使用的标注数据是少样本,伪标注语料的大小是标注数据的2~3个数量级,
是RoBERTa_Large,使用one-hot硬标签在
上训练。
根据上述训练
的不同方法,我们依次来探究在不同训练设置下,自训练是否能进一步提高预训练的效果。数据集包括SST-2,SST-3,CR,IMP,TREC,CoNLL2002,
除了最后一个是命名实体识别任务之外,其他都是分类任务。
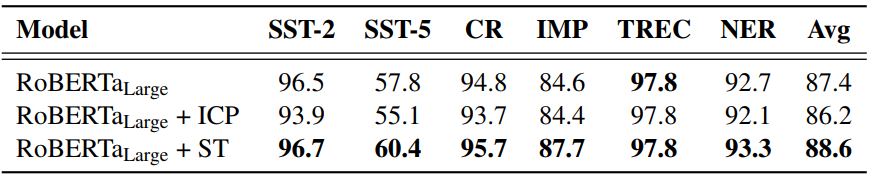
下图是在自训练设置下的实验结果,ICP是In-domain Continued Pretraining,即直接在
上预训练而不使用
预测得到的标签,ST是Self-Training自训练。
可以看到,尽管都是在相关领域的数据
上训练,ICP由于没有使用
的预测标签,反而使得效果下降(-1.2),而ST则能进一步提升预训练模型的效果(+1.2)。
这说明 没有伪标注数据,单纯的预训练不能很好地实现领域知识迁移,还要借助标注数据。
少样本学习与知识蒸馏
下图是少样本学习的实验结果。可以看到,领域内自训练可以大幅提升少样本场景下的效果。
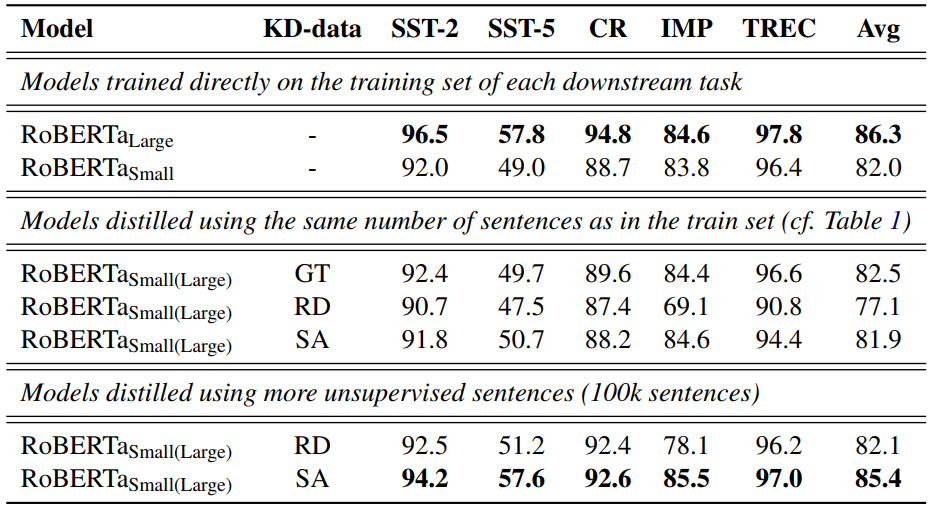
下图是知识蒸馏的实验结果。GT表示用真值(Ground-Truth)数据,RD是用随机(Random)数据,SA(SentAugment)是用本文的方法得到的数据。
在和训练集一样大的情况下,GT和SA都显著超过了RD,但如果再额外增加100K句子,SA甚至能逼近有监督学习RoBERTa_Large的结果,并且参数量是它的十分之一。
这说明, 对知识蒸馏来说,自训练带来的数据增广也是很重要的。
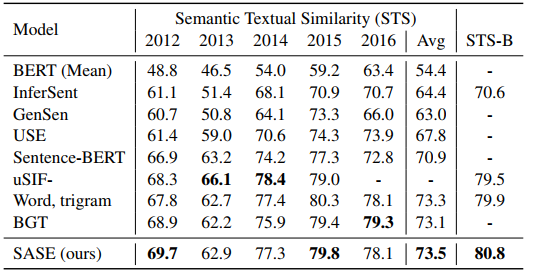
前面我们提到我们默认使用的是Transformer去编码句子,那么不同的编码器会有怎样的影响呢?下图是不同编码器在STS数据集上的实验结果。
总的来说,单纯使用BERT得到的句子编码效果最差,而使用Trigram甚至能得到很好的结果,这说明了复述与多语言掩码语言模型任务对于训练句子编码是很有帮助的。
一个例子
最后我们来看看从
中抽取的句子是怎样的,如下图所示。如果是用Per-Sentence,那么抽取的句子就基本上是询问的转述;如果是用Label-Average,抽取的句子就符合该类别。
基于句子编码与任务编码的抽取方法有能力得到满足条件的句子。
小结
本文研究了预训练模型上的自训练带来的效果增益。使用自训练学习框架,模型能够从海量通用语料中抽取出相关领域的句子,然后使用教师模型预测标签得到伪标注数据,最后再去训练学生模型。无论是自训练本身,还是知识蒸馏、少样本学习,预训练+自训练都能取得显著的效果提升。
值得注意的是,本文的核心其实是如何从海量通用语料中提取满足条件的语料,也即提出的SentAugment方法。在过去一年内,开放领域问答(Open-Domain Question Answering)大量使用了这种方法取提取问题的相关段落,并取得了成功。
这些工作表明:
基于句子编码的语料提取、标注,是数据增广的有效手段,可以进一步用在自然语言生成任务,如机器翻译、摘要生成等任务上,这也是我们之前经常强调的一个重要方向。
点击阅读原文,直达ICLR小组~