2小时演讲,近140页PPT,这个NeurIPS Tutorial真是超硬核的AI硬件教程
机器之心整理
参与:一鸣
NeurlPS 2019 大会正在加拿大温哥华召开中。 昨日,MIT 教授 Vivienne Sze 在大会上发表了一个关于深度神经网络加速的演讲,大会提供了视频和同步的 PPT。 通过两个小时的精彩演讲和多达 140 页的 PPT,演讲可谓是将神经网络加速这个快速发展的领域一网打尽。
近日,NeurlPS2019 大会放出了一个名为「Efficient Processing of Deep Neural Network: from Algorithms to Hardware Architectures」的演讲。该演讲主要介绍各类能够使硬件高效处理深度神经网络(DNN)计算的方法,包括在计算机视觉、语音识别、机器人等领域,而涉及到的硬件包含了从 CPU、GPU 到 FPGA 和 ASIC 等各类计算硬件。


1. 让硬件高效处理 DNN 的方法(非常多);
2. 关注包括设计 DNN 硬件处理器和 DNN 模型的评估方法;
设计 DNN 硬件处理器和 DNN 模型的方法;
研究过程中,你应当问什么样的关键问题;
3. 具体地,演讲还会讨论;
真正需要评价和对比的评估指标体系;
达成这些指标的挑战;
了解设计中需要考虑到的问题,以及可能平衡在算法性能和耗能中遇到的问题;
4. 要关注硬件推理,但包括一部分训练的内容。

深度神经网络概述;
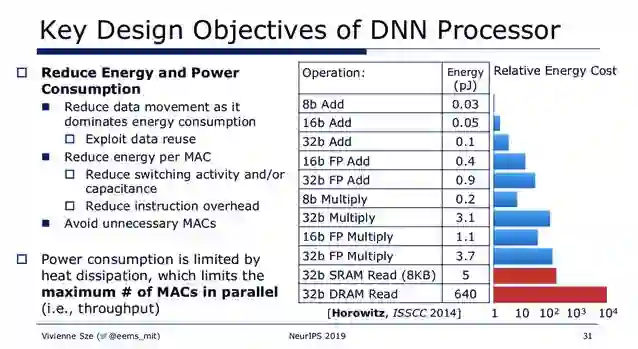
关键指标和设计目标;
设计考量:
CPU 和 GPU 平台;
专用/特殊用途平台(ASICs);
Q&A;
算法(DNN 模型)和硬件联合设计;
其他平台;
用于系统评价 DNN 处理器的工具;
从视频来看,Sze 教授十分严谨、细致地介绍了这一领域几乎所有的内容,非常适合在实际应用中需要了解各类硬件加速方法的研究者和开发者观看。机器之心对其中的主要内容进行了选编:







点击阅读原文,立即访问。
登录查看更多
相关内容
Arxiv
4+阅读 · 2018年3月30日




相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2018年3月30日