来源 | yes的练级攻略
头图 | CSDN付费下载自图虫
我们都知道 RocketMQ 和 Kafka 消息都是存在磁盘中的,那为什么消息存磁盘读写还可以这么快?有没有做了什么优化?都是存磁盘它们两者的实现之间有什么区别么?各自有什么优缺点?
![]()
存储介质-磁盘
一般而言消息中间件的消息都存储在本地文件中,因为从效率来看直接放本地文件是最快的,并且稳定性最高。毕竟要是放类似数据库等第三方存储中的话,就多一个依赖少一份安全,并且还有网络的开销。
那对于将消息存入磁盘文件来说一个流程的瓶颈就是磁盘的写入和读取。我们知道磁盘相对而言读写速度较慢,那通过磁盘作为存储介质如何实现高吞吐呢?
顺序读写
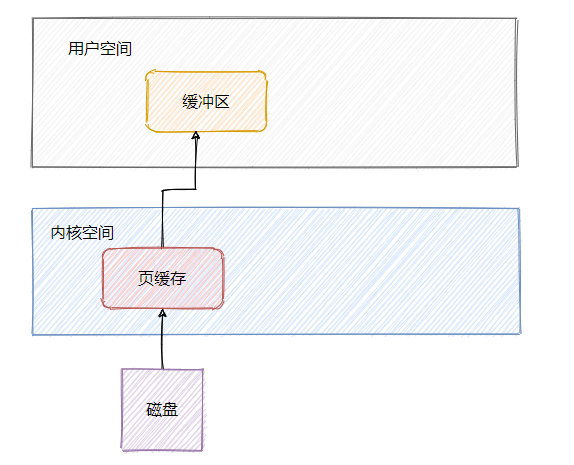
首先了解一下页缓存,页缓存是操作系统用来作为磁盘的一种缓存,减少磁盘的I/O操作。
在写入磁盘的时候其实是写入页缓存中,使得对磁盘的写入变成对内存的写入。写入的页变成脏页,然后操作系统会在合适的时候将脏页写入磁盘中。
在读取的时候如果页缓存命中则直接返回,如果页缓存 miss 则产生缺页中断,从磁盘加载数据至页缓存中,然后返回数据。
并且在读的时候会预读,根据局部性原理当读取的时候会把相邻的磁盘块读入页缓存中。在写入的时候会后写,写入的也是页缓存,这样存着可以将一些小的写入操作合并成大的写入,然后再刷盘。
而且根据磁盘的构造,顺序 I/O 的时候,磁头几乎不用换道,或者换道的时间很短。
根据网上的一些测试结果,顺序写盘的速度比随机写内存还要快。
当然这样的写入存在数据丢失的风险,例如机器突然断电,那些还未刷盘的脏页就丢失了。不过可以调用 fsync 强制刷盘,但是这样对于性能的损耗较大。
因此一般建议通过多副本机制来保证消息的可靠,而不是同步刷盘。
可以看到顺序 I/O 适应磁盘的构造,并且还有预读和后写。RocketMQ 和 Kafka 都是顺序写入和近似顺序读取。它们都采用文件追加的方式来写入消息,只能在日志文件尾部写入新的消息,老的消息无法更改。
mmap-文件内存映射
从上面可知访问磁盘文件会将数据加载到页缓存中,但是页缓存属于内核空间,用户空间访问不了,因此数据还需要拷贝到用户空间缓冲区。
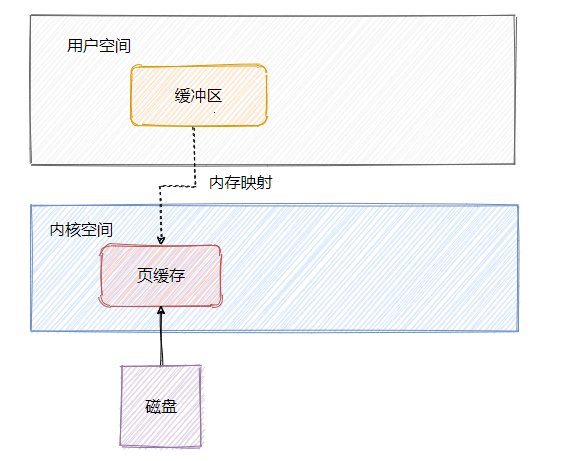
![]() 可以看到数据需要从页缓存再经过一次拷贝程序才能访问的到,因此还可以通过mmap来做一波优化,利用内存映射文件来避免拷贝。
简单的说文件映射就是将程序虚拟页面直接映射到页缓存上,这样就无需有内核态再往用户态的拷贝,而且也避免了重复数据的产生。并且也不必再通过调用read或write方法对文件进行读写,可以通过映射地址加偏移量的方式直接操作。
可以看到数据需要从页缓存再经过一次拷贝程序才能访问的到,因此还可以通过mmap来做一波优化,利用内存映射文件来避免拷贝。
简单的说文件映射就是将程序虚拟页面直接映射到页缓存上,这样就无需有内核态再往用户态的拷贝,而且也避免了重复数据的产生。并且也不必再通过调用read或write方法对文件进行读写,可以通过映射地址加偏移量的方式直接操作。
![]()
sendfile-零拷贝
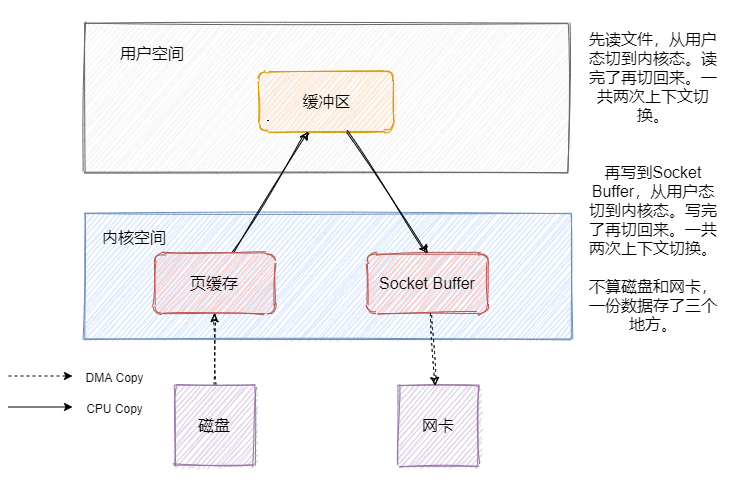
既然消息是存在磁盘中的,那消费者来拉消息的时候就得从磁盘拿。我们先来看看一般发送文件的流程是如何的。
![]() 简单说下DMA是什么,全称 Direct Memory Access ,它可以独立地直接读写系统内存,不需要 CPU 介入,像显卡、网卡之类都会用DMA。
可以看到数据其实是冗余的,那我们来看看mmap之后的发送文件流程是怎样的。
简单说下DMA是什么,全称 Direct Memory Access ,它可以独立地直接读写系统内存,不需要 CPU 介入,像显卡、网卡之类都会用DMA。
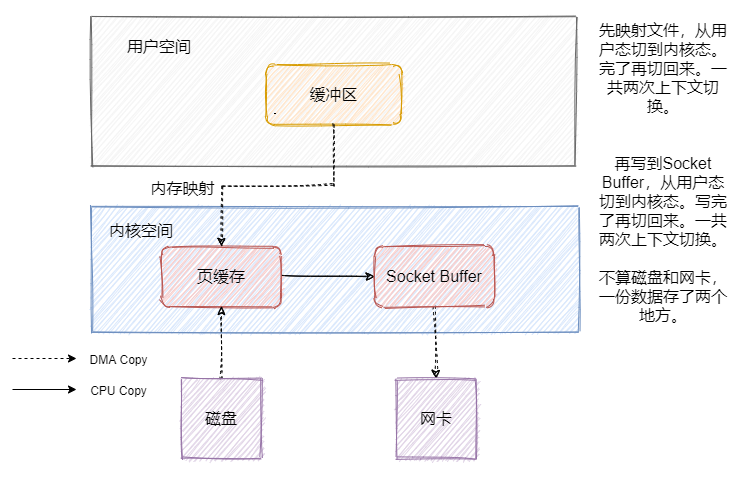
可以看到数据其实是冗余的,那我们来看看mmap之后的发送文件流程是怎样的。
![]() 可以看到上下文切换的次数没有变化,但是数据少拷贝一份,这和我们上文提到的mmap能达到的效果是一样的。
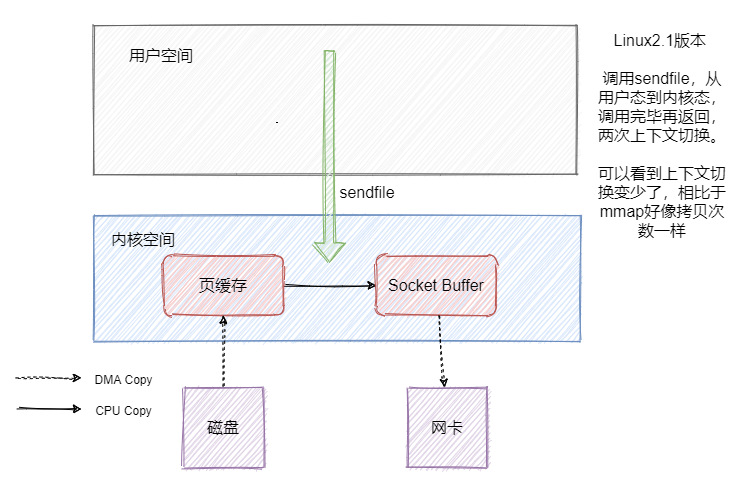
但是数据还是冗余了一份,这不是可以直接把数据从页缓存拷贝到网卡不就好了嘛?sendfile就有这个功效。我们先来看看Linux2.1版本中的sendfile。
可以看到上下文切换的次数没有变化,但是数据少拷贝一份,这和我们上文提到的mmap能达到的效果是一样的。
但是数据还是冗余了一份,这不是可以直接把数据从页缓存拷贝到网卡不就好了嘛?sendfile就有这个功效。我们先来看看Linux2.1版本中的sendfile。
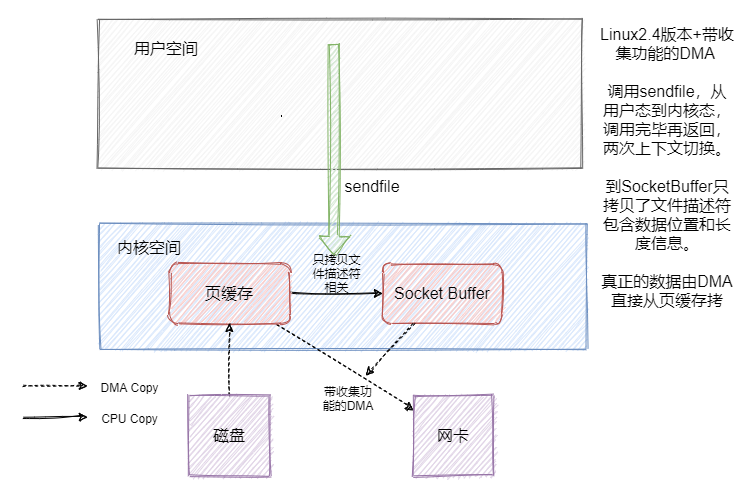
![]() 因为就一个系统调用就满足了发送的需求,相比 read + write 或者 mmap + write 上下文切换肯定是少了的,但是好像数据还是有冗余啊。是的,因此 Linux2.4 版本的 sendfile + 带 「分散-收集(Scatter-gather)」的DMA。实现了真正的无冗余。
因为就一个系统调用就满足了发送的需求,相比 read + write 或者 mmap + write 上下文切换肯定是少了的,但是好像数据还是有冗余啊。是的,因此 Linux2.4 版本的 sendfile + 带 「分散-收集(Scatter-gather)」的DMA。实现了真正的无冗余。
![]() 这就是我们常说的零拷贝,在 Java 中FileChannal.transferTo()底层用的就是sendfile。
接下来我们看看以上说的几点在 RocketMQ 和 Kafka中是如何应用的。
这就是我们常说的零拷贝,在 Java 中FileChannal.transferTo()底层用的就是sendfile。
接下来我们看看以上说的几点在 RocketMQ 和 Kafka中是如何应用的。
![]()
RocketMQ 和 Kafka 的应用
RocketMQ
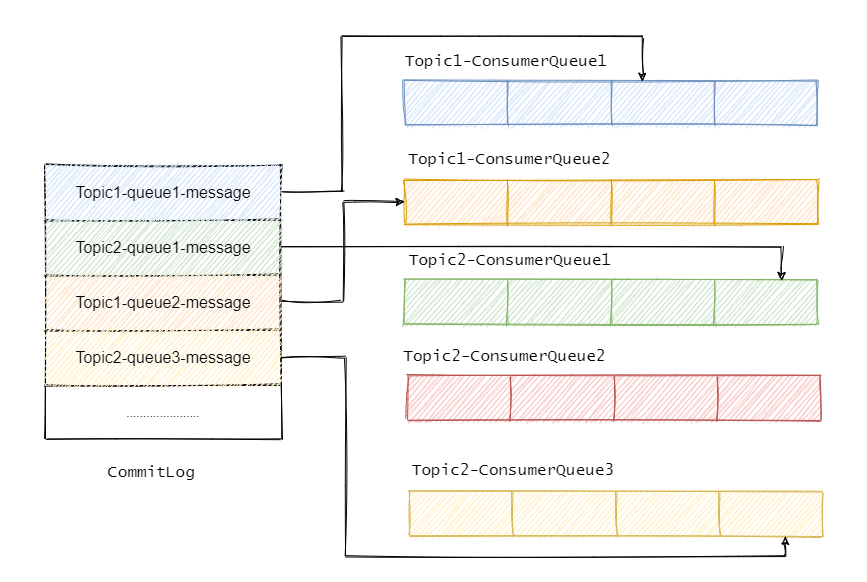
采用Topic混合追加方式,即一个 CommitLog 文件中会包含分给此 Broker 的所有消息,不论消息属于哪个 Topic 的哪个 Queue 。
![]() 所以所有的消息过来都是顺序追加写入到 CommitLog 中,并且建立消息对应的 CosumerQueue ,然后消费者是通过 CosumerQueue 得到消息的真实物理地址再去 CommitLog 获取消息的。可以将 CosumerQueue 理解为消息的索引。
在 RocketMQ 中不论是 CommitLog 还是 CosumerQueue 都采用了 mmap。
所以所有的消息过来都是顺序追加写入到 CommitLog 中,并且建立消息对应的 CosumerQueue ,然后消费者是通过 CosumerQueue 得到消息的真实物理地址再去 CommitLog 获取消息的。可以将 CosumerQueue 理解为消息的索引。
在 RocketMQ 中不论是 CommitLog 还是 CosumerQueue 都采用了 mmap。
![]() 在发消息的时候默认用的是将数据拷贝到堆内存中,然后再发送。我们来看下代码。
在发消息的时候默认用的是将数据拷贝到堆内存中,然后再发送。我们来看下代码。
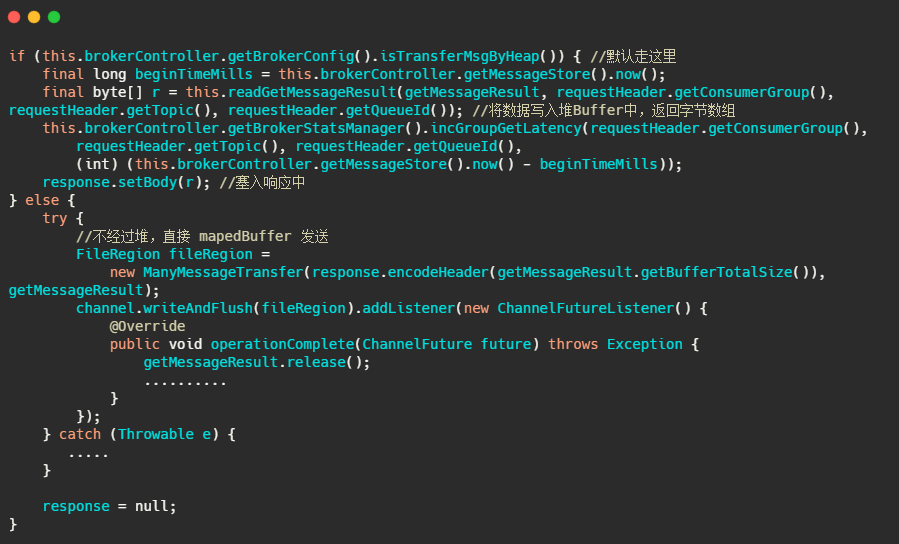
![]() 可以看到这个配置 transferMsgByHeap 默认是 true ,那我们再看消费者拉消息时候的代码。
可以看到这个配置 transferMsgByHeap 默认是 true ,那我们再看消费者拉消息时候的代码。
![]() 可以看到 RocketMQ 默认把消息拷贝到堆内 Buffer 中,再塞到响应体里面发送。但是可以通过参数配置不经过堆,不过也并没有用到真正的零拷贝,而是通过mapedBuffer 发送到 SocketBuffer 。
所以 RocketMQ 用了顺序写盘、mmap。并没有用到 sendfile ,还有一步页缓存到 SocketBuffer 的拷贝。
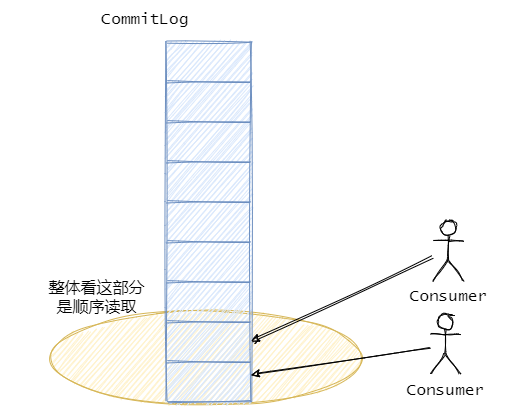
然后拉消息的时候严格的说对于 CommitLog 来说读取是随机的,因为 CommitLog 的消息是混合的存储的,但是从整体上看,消息还是从 CommitLog 顺序读的,都是从旧数据到新数据有序的读取。并且一般而言消息存进去马上就会被消费,因此消息这时候应该还在页缓存中,所以不需要读盘。
可以看到 RocketMQ 默认把消息拷贝到堆内 Buffer 中,再塞到响应体里面发送。但是可以通过参数配置不经过堆,不过也并没有用到真正的零拷贝,而是通过mapedBuffer 发送到 SocketBuffer 。
所以 RocketMQ 用了顺序写盘、mmap。并没有用到 sendfile ,还有一步页缓存到 SocketBuffer 的拷贝。
然后拉消息的时候严格的说对于 CommitLog 来说读取是随机的,因为 CommitLog 的消息是混合的存储的,但是从整体上看,消息还是从 CommitLog 顺序读的,都是从旧数据到新数据有序的读取。并且一般而言消息存进去马上就会被消费,因此消息这时候应该还在页缓存中,所以不需要读盘。
![]() 而且我们在上面提到,页缓存会定时刷盘,这刷盘不可控,并且内存是有限的,会有swap等情况。
而且mmap其实只是做了映射,当真正读取页面的时候产生缺页中断,才会将数据真正加载到内存中,这对于消息队列来说可能会产生监控上的毛刺。
因此 RocketMQ 做了一些优化,有:文件预分配和文件预热。
而且我们在上面提到,页缓存会定时刷盘,这刷盘不可控,并且内存是有限的,会有swap等情况。
而且mmap其实只是做了映射,当真正读取页面的时候产生缺页中断,才会将数据真正加载到内存中,这对于消息队列来说可能会产生监控上的毛刺。
因此 RocketMQ 做了一些优化,有:文件预分配和文件预热。
文件预分配
CommitLog 的大小默认是1G,当超过大小限制的时候需要准备新的文件,而 RocketMQ 就起了一个后台线程 AllocateMappedFileService,不断的处理 AllocateRequest,AllocateRequest其实就是预分配的请求,会提前准备好下一个文件的分配,防止在消息写入的过程中分配文件,产生抖动。
文件预热
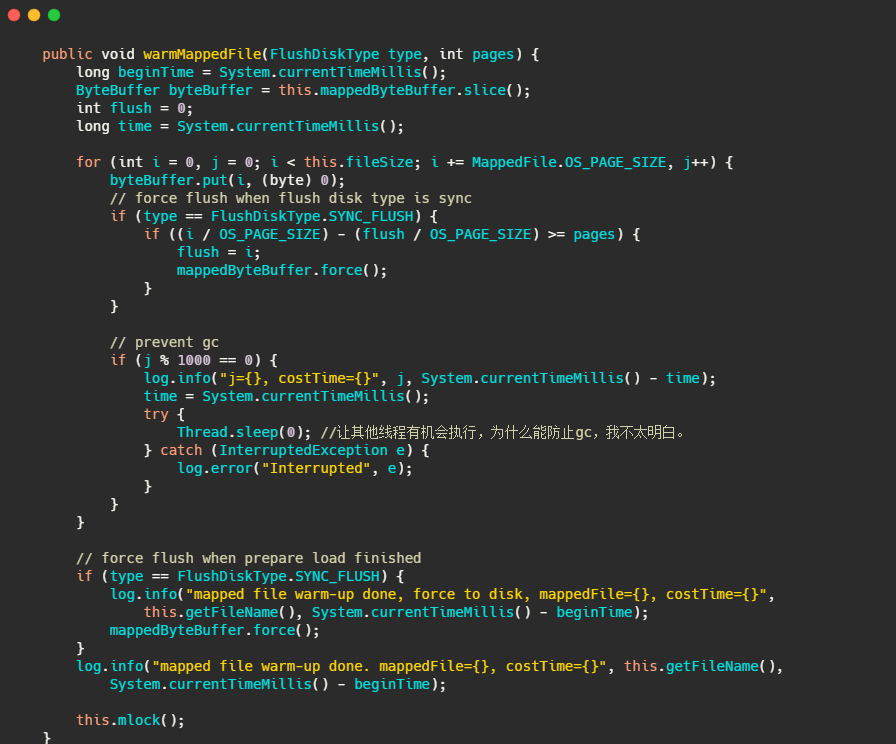
有一个warmMappedFile方法,它会把当前映射的文件,每一页遍历多去,写入一个0字节,然后再调用mlock 和 madvise(MADV_WILLNEED)。
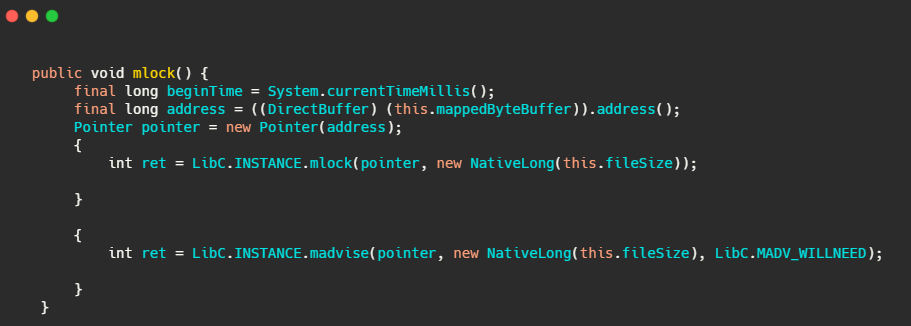
![]() 我们再来看下this.mlock,内部其实就是调用了mlock 和madvise(MADV_WILLNEED)。
我们再来看下this.mlock,内部其实就是调用了mlock 和madvise(MADV_WILLNEED)。
![]() mlock:可以将进程使用的部分或者全部的地址空间锁定在物理内存中,防止其被交换到swap空间。
madvise:给操作系统建议,说这文件在不久的将来要访问的,因此,提前读几页可能是个好主意。
mlock:可以将进程使用的部分或者全部的地址空间锁定在物理内存中,防止其被交换到swap空间。
madvise:给操作系统建议,说这文件在不久的将来要访问的,因此,提前读几页可能是个好主意。
RocketMQ 小结
顺序写盘,整体来看是顺序读盘,并且使用了 mmap,不是真正的零拷贝。又因为页缓存的不确定性和 mmap 惰性加载(访问时缺页中断才会真正加载数据),用了文件预先分配和文件预热即每页写入一个0字节,然后再调用mlock 和madvise(MADV_WILLNEED)。
Kafka
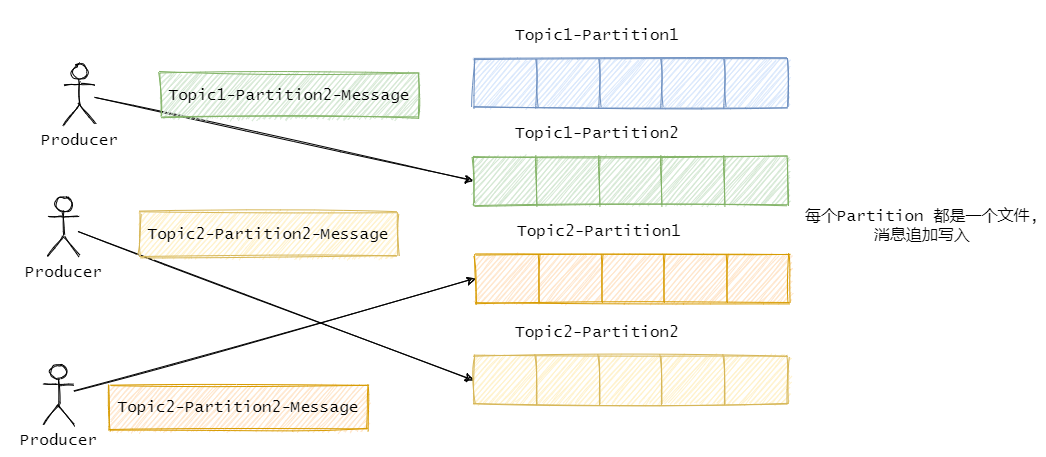
Kafka 的日志存储和 RocketMQ 不一样,它是一个分区一个文件。
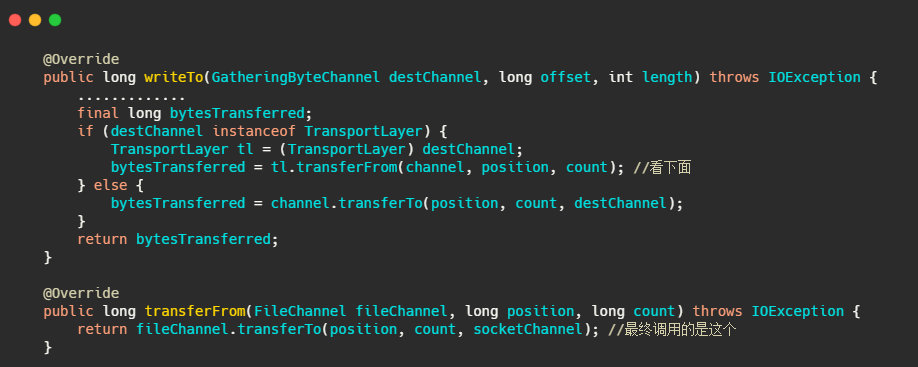
![]() Kafka 的消息写入对于单分区来说也是顺序写,如果分区不多的话从整体上看也算顺序写,它的日志文件并没有用到 mmap,而索引文件用了 mmap。但发消息 Kafka 用到了零拷贝。
对于消息的写入来说 mmap 其实没什么用,因为消息是从网络中来。而对于发消息来说 sendfile 对比 mmap+write 我觉得效率更高,因为少了一次页缓存到 SocketBuffer 中的拷贝。
来看下Kafka发消息的源码,最终调用的是 FileChannel.transferTo,底层就是 sendfile。
Kafka 的消息写入对于单分区来说也是顺序写,如果分区不多的话从整体上看也算顺序写,它的日志文件并没有用到 mmap,而索引文件用了 mmap。但发消息 Kafka 用到了零拷贝。
对于消息的写入来说 mmap 其实没什么用,因为消息是从网络中来。而对于发消息来说 sendfile 对比 mmap+write 我觉得效率更高,因为少了一次页缓存到 SocketBuffer 中的拷贝。
来看下Kafka发消息的源码,最终调用的是 FileChannel.transferTo,底层就是 sendfile。
![]() 从 Kafka 源码中我没看到有类似于 RocketMQ的 mlock 等操作,我觉得原因是首先日志也没用到 mmap,然后 swap 其实可以通过 Linux 系统参数 vm.swappiness 来调节,这里建议设置为1,而不是0。
假设内存真的不足,设置为 0 的话,在内存耗尽的情况下,又不能 swap,则会突然中止某些进程。设置个 1,起码还能拖一下,如果有良好的监控手段,还能给个机会发现一下,不至于突然中止。
从 Kafka 源码中我没看到有类似于 RocketMQ的 mlock 等操作,我觉得原因是首先日志也没用到 mmap,然后 swap 其实可以通过 Linux 系统参数 vm.swappiness 来调节,这里建议设置为1,而不是0。
假设内存真的不足,设置为 0 的话,在内存耗尽的情况下,又不能 swap,则会突然中止某些进程。设置个 1,起码还能拖一下,如果有良好的监控手段,还能给个机会发现一下,不至于突然中止。
RocketMQ & Kafka 对比
首先都是顺序写入,不过 RocketMQ 是把消息都存一个文件中,而 Kafka 是一个分区一个文件。
每个分区一个文件在迁移或者数据复制层面上来说更加得灵活。
但是分区多了的话,写入需要频繁的在多个文件之间来回切换,对于每个文件来说是顺序写入的,但是从全局看其实算随机写入,并且读取的时候也是一样,算随机读。而就一个文件的 RocketMQ 就没这个问题。
从发送消息来说 RocketMQ 用到了 mmap + write 的方式,并且通过预热来减少大文件 mmap 因为缺页中断产生的性能问题。而 Kafka 则用了 sendfile,相对而言我觉得 kafka 发送的效率更高,因为少了一次页缓存到 SocketBuffer 中的拷贝。
![]()
最后
这篇文章中间写 RocketMQ 卡壳了,源码还是不太熟,有点绕。多亏丁威大佬的点拨。不然我就陷入了死胡同出不来了。
最后再推荐下丁威大佬和周继锋大佬的《RocketMQ技术内幕:RocketMQ架构设计与实现原理》,对 RocketMQ 有兴趣的同学可以看看。