香港中文大学博士陈恺:物体检测中的训练样本采样

嘉宾:陈恺 博士 香港中文大学
整理:Hoh Xil
出品:将门、DataFun
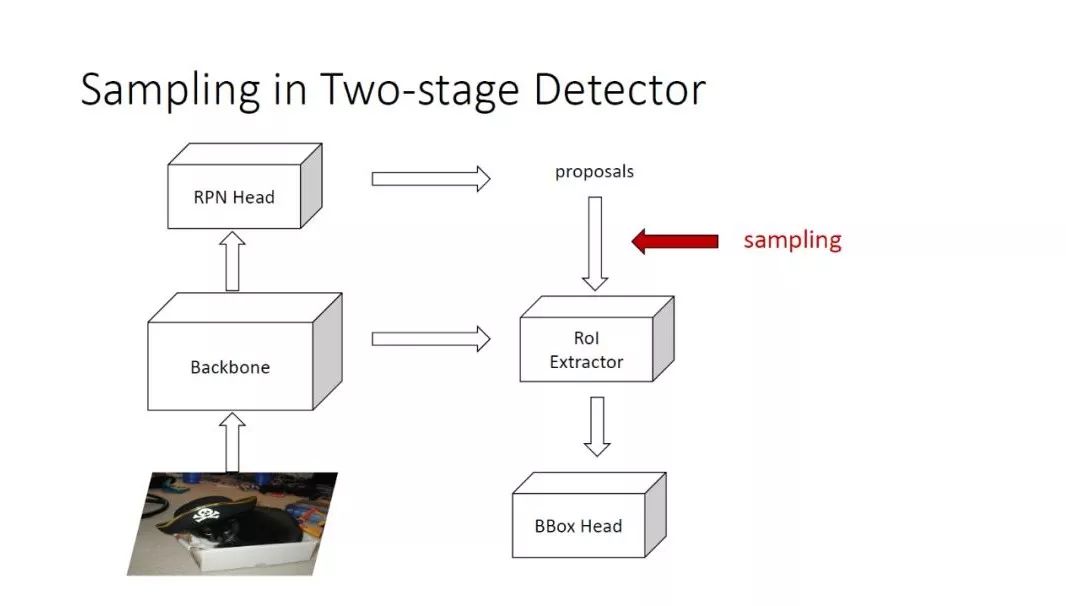
在物体检测中,用到样本采样的地方:
对于双阶段 Detector 来说,它的采样策略会发生在两个阶段,在 RPN 中会有一组采样,以及从 RPN 的 proposals 来 train BBox Head 也会发生一次采样。这里主要研究第二次的采样策略,因为 RPN 的一点点提升对最后 mAP 的影响比较小。
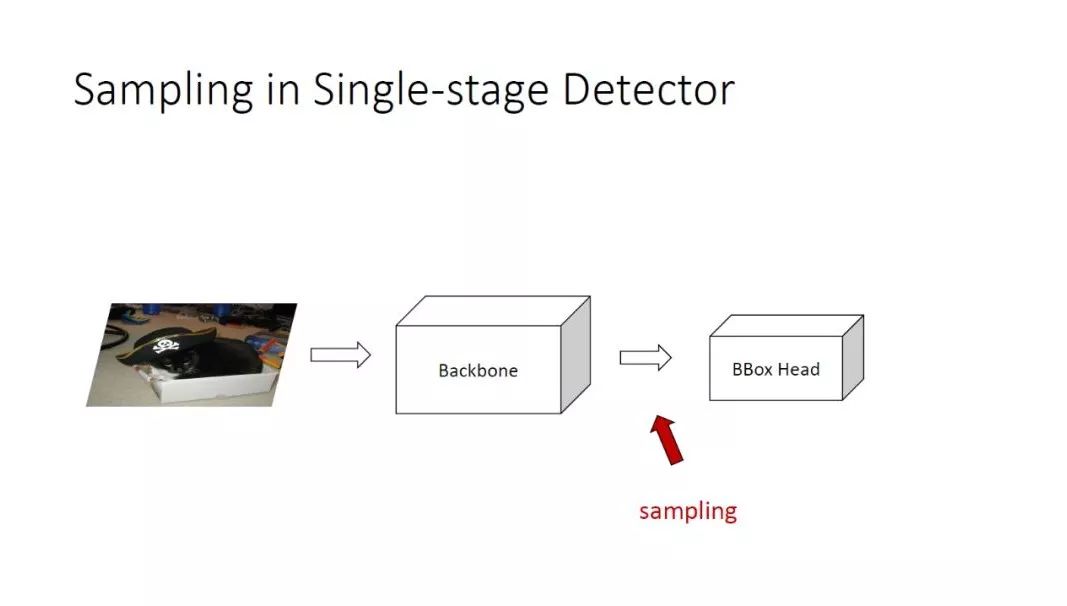
对单阶段检测器来说,它的采样就发生在从 Backbone 到 BBox Head 之间。
本次分享的目录:

本次分享主要有两个方面:
Sample inbalance,样本的不平衡性,这是我们 CVPR 2019 的一篇工作。
Sample importance,样本的重要性,这是我们最近关于物体检测的一些重新的思考。
——Sample Imbalance——

1. 负样本过多的情况:
OHEM 是一个很常用的 hard mining 方法,主要解决简单样本和困难样本之间的一个不平衡,每次在线的选择困难的样本去训练。
Focal Loss 也是在单阶段检测器中的一个改进,除了解决困难样本和简单样本不平衡之外,还解决了一些正负样本之间的不平衡。
以上两种方法的局限性:
OHKM 会带来额外的一些 cost,比如用在两阶段的检测器中,需要把所有的 ROI 全部 forward 一遍之后,才能去选择用哪些样本来进行 noise 回传,或者用来进行第二次的 forward。同时,它也对噪声比较敏感,因为每次都是选择最 hard 的 K 个样本来进行训练,如果样本中有噪声的话,会比较敏感。
-
Focal Loss 的主要问题是在 single-stage detector 中非常 work,但是在 two-stage detector 中发挥的作用十分有限,通常不会涨点,甚至会掉点。
既然 hard mining 这么有用,以上两个方法,本质上都是更加关注困难的样本:
Focal Loss 相当于是一种 soft sampling,因为它是给每个样本不同的 loss weight。
OHEM 相当于是一个 hard sampling,它的 weight 相当于是0和1。
2. IoU and Difficaulty

那么有没有一种更简单的办法来模拟 hard mining 这个过程,我们的 Motivation 就是说,我们首先会探究 IoU 和样本困难性之间的关系。对于一个训练样本来说,ground truth IoU 和它的困难度之间是否有什么联系。
我们通过实验发现:一些高 IoU 的负样本是比较困难的负样本。
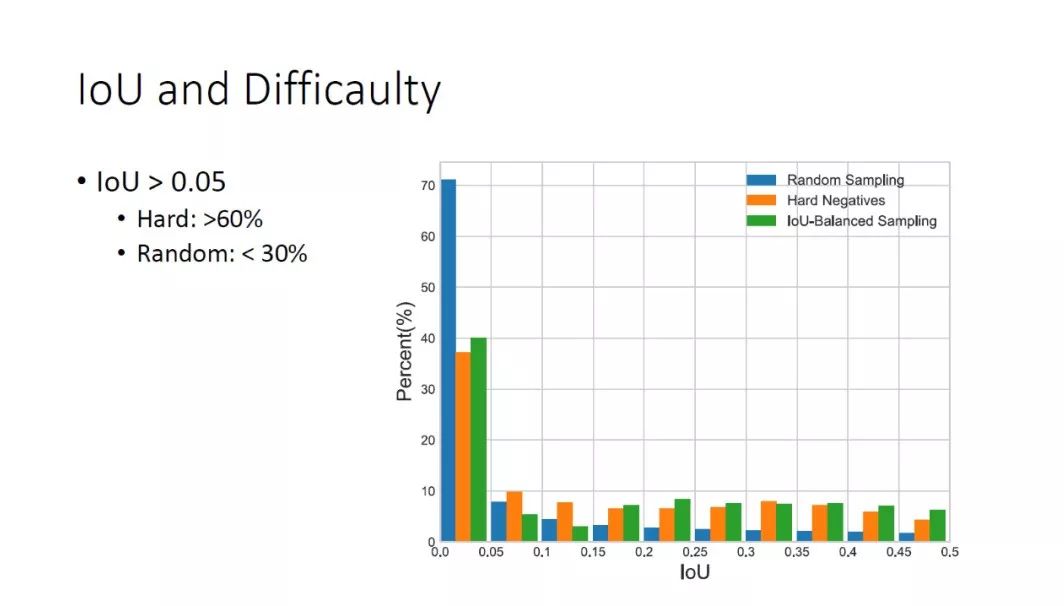
我们做了一个直方图的统计,蓝色为随机采样,橙色为 hardnegatives,如果以 IoU0.05 为界,我们发现在困难样本中 IoU>0.05 的占了60%,但是在随机采样中,IoU>0.05 的不到30%。这说明通常困难样本中的 IoU 会比较高,但是随机采样的时候很难采到高 IoU 的样本。所以,IoU 可以作为困难度的一个表征。既然 IoU 和样本的困难度之间有正相关性,是不是可以不用把所有的样本都 Forward 一遍,再按 loss 来排序,来得到困难样本。我们就可以直接通过 IoU 来估计哪些是困难样本,这样可以大大的减少时间的消耗。
3. IoU-balanced Negative Sampling

据此,我们提出了 Iou-balanced NegativeSampling,方法非常简单,假设整张图只有 N 个 sample 负样本:
第一步,把 IoU 的区间均匀的分成 K 个区间
第二步,在每个区间我们会 sample N/K 个 bboxes
当然,存在一种可能:某个区间,特别是高 IoU 的区间并没有那么多框可以 sample,这样我们在进行这次 sample 之后,如果还有不足的样本,我们会从所有的负样本中再随机的补上。
4. Instance-balanced Positive Sampling

把这种方法也推广到正样本的 sampling 中,正样本如果通过 IoU 是比较困难,所以我们希望做一些 balanced sampling,一个自然的想法是根据正样本属于哪个 ground truths 来做 sampling。
如果整张图中有 N 个 groundtruths 的话,samples N 个正样本,那么在 K 个 ground truths 附近,每个 ground truth 旁边 sample N/K 个正样本,同样,如果最后数量达不到要求,会用随机采样的框来补上。
上述的两种办法都是在所有的正负样本的框,但是没有做进一步 Forward 的时候。所以,这两个 sampling 相比于 random sampling 没有任何的成本,可以认为在训练的时候跟 random sampling 的 baseline 的耗时是完全一样的。
5. Examples
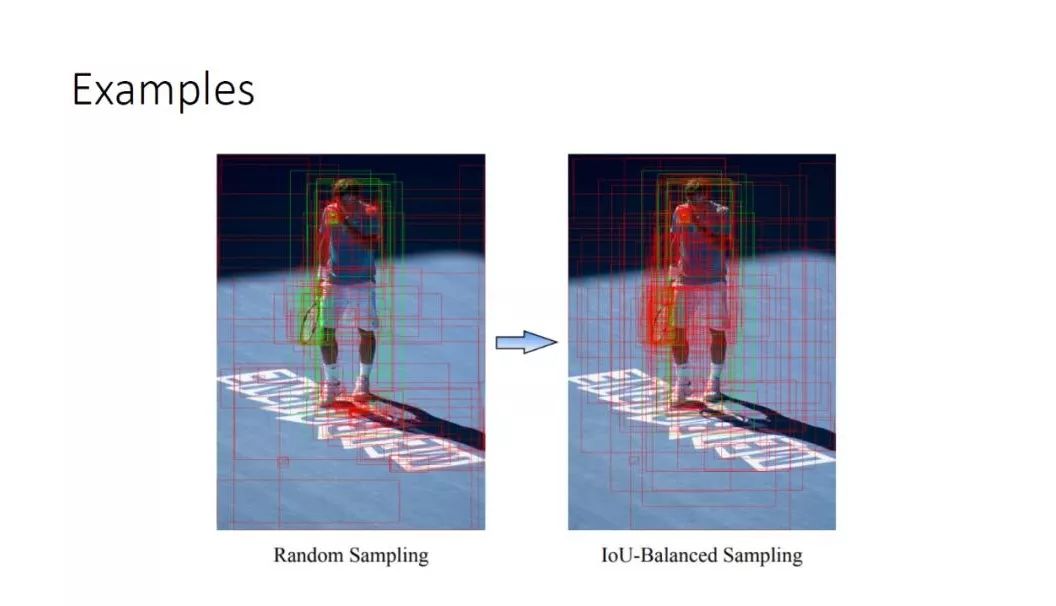
这里有一个直观的显示,如果用 random sampling 的话可以看左图,经常会 sample 到一些非常简单的负样本,如空白的地面,就是一个纯 bad ground。如果我们用 IoU-Balanced Sampling,可以看到更多的负样本会集中在物体的周围,这些通常是比较困难的样本,同时可以看到,对于正样本在不同的 ground truth 之间的分布变得更均衡。
6. Result
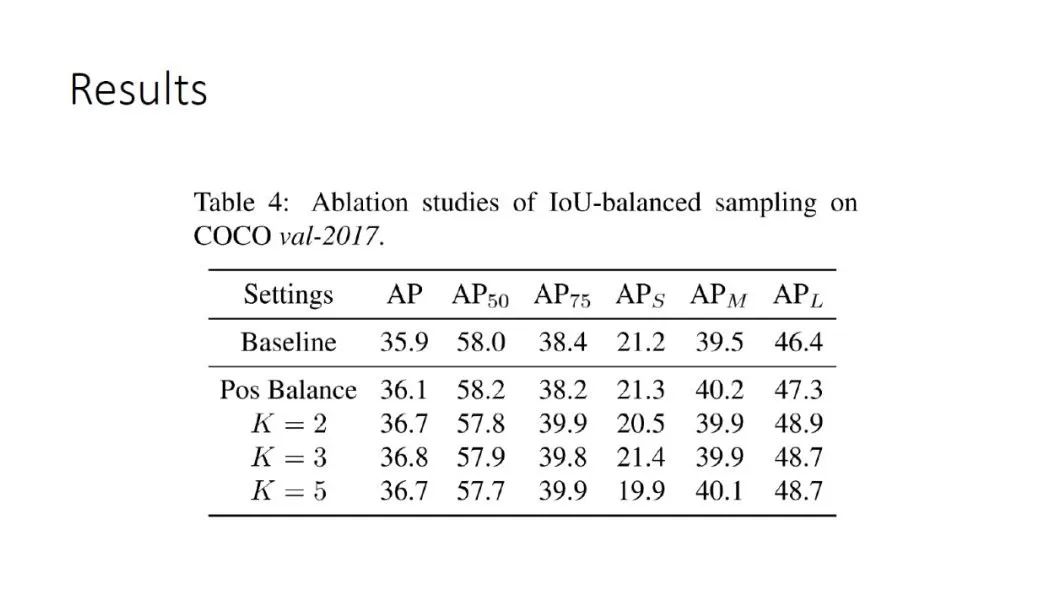
通过一个简单的 sampling 改进,可以把最后的结果从 baseline 就是 random sampling 的35.9提升到 IoU-balanced sampling 的36.8,大概是0.9个点,虽然这个点相比于一些方法来说不是很多,但这篇 paper 讲了3个部分,这只是其中一个部分,而且对速度没有任何负面的影响,所以把它作为一个涨点的 trick 还是不错的。
简单总结下,通过用 IoU 来作为 hard mining 的估计,从而提出根据 IoU 来做一个 balanced sampling,最后达到的效果比 hard mining 要好,主要原因是比 hard mining 更加鲁棒,因为 hard mining 只看最难的样本,而 IoU balanced sampling 除了关注最难的样本,也会关注一些其它的样本,所以会更加鲁棒。
——Sample importance——

这些困难的样本是不是对于检测器来说是最重要的样本?
一直以来我们是把它当做理所当然的事情。因为 hard mining 从分类问题以来就一直被大家证明确实是 work 的,通常 hard mining 都能够提升分类器的性能。这里还引出另外一个问题,我们现在做的是 detection,那么和 classification 分类的目标是否是完全一致的,假定我有一个框,如果能够 train 出更好的分类器,是不是意味着检测性能更高?这是一个值得思考的问题。
所以,在第二篇 paper 中,对这个问题进行了思考。
1. Observations

首先是一些观察得到的结论:
样本不应该被看作是独立的,也不应该被看成是同等重要的。如图,绿色的虚线框是 ground truth,是一只黑色猫咪,黄色的框和红色的框都是正样本,因为它们的 IoU 都是大于0.5的,是不是说只要分类的 loss 越小,检测的 mAP 越高呢?
其实不是的,我们来看下左边和右边的对比:
4个框都给了很高的分数,意味着对于左图分类的 loss 是很小的,而且可以认为分类准确率是100%,对于右图给了黄色框一个比较高的分数,但是其他框的分数都比较低,然后左上角的红色框给了0.13的分数,那么意味着可能有其它的一些类有更高的分数,可能会分错。且右图的 loss 明显比左图的 loss 大,是不是右图检测性能比左侧低呢?应该是相反的,因为我们可以看到黄色框跟 ground truth 的 IoU 是最大的,检测并不是追求要把所有的正样本都分的很对,最终的目标是找到最好的那个框,然后给它一个很高的 score。

通过观察得到的结论:
分类的准确率跟检测的准确率没有必然的关系
对于一个检测器,如果能够给每个物体周围给一个框一个非常高的 score,这个框通常就是比较准的框,然后能够保证所有的物体都被 cover 到,那么这个检测器就应该是一个好的检测器,所以它跟分类的评价是不一样的,分类要求所有样本的平均性能尽可能高。
检测通常有两个分支,一个是分类的分支,一个是回归或者定位的分支,这两个分支是相互关联的。
What samples are important?基于这些发现,对于检测来说,到底哪些是重要的样本?我们从正样本和负样本来分别讨论:
① A revisit to mAP

首先讨论下正样本,我们先回顾下 mAP ( Mean Average Precision ) 的计算:平均 Precision 的意思是在不同 recall 下的 Precision 平均值,mean 代表不同的 class,对于 COCO 来说,前面还有一个 mean,代表的是 IoU 的阈值,会从0.5~0.95,每隔0.05取一个。
Precision 是 TruePositive 的数量比上 detector 框的数量,所以 Precision 是用来描述给定一组框中正确的部分占所给框的比例。
Recall 是 TruePositive 的数量比上 ground truth 的数目,是用来衡量有多少 ground truth object 被检测出来了。
所以我们在计算 mAP 的时候,会画一条 Precision-Recall 曲线。
这里很重要的标准是什么样的样本会看成 true Positive,有两个指标:
IoU>θ ( IoU 的阈值 ),比如对于 COCO 来说,这里的 θ 会是0.5~0.95等间隔取的一个数。
没有重复的检测,如果这个框是 true Positive,意味着周围没有一个分数更高的框。
从 mAP 的计算过程中,我们可以看到:
对于每个 ground truth 在它周围 IoU 最高的框对它来说是最重要的。因为 IoU 最高的框如果分的准确,那么它就会是一个 true Positive,且在阈值很高的情况下也会是一个 true Positive。
对所有的 ground truth 来说,IoU 越高的框越重要。因为最终会把所有的框按照 score 排序,分数从高到底来算 true Positive,如果 IoU 最大的框,它的分数是最高的,意味着不管在什么阈值下面,它将是第一个 truePositive。但是,如果 IoU 最大的那个框分数较低,那么在比较低的阈值下面它是一个 true Positive,随着阈值逐渐提高它就会变成一个 false Positive,会对最后的 mAP 产生比较大的影响。
② A revisit to False Positives

对于负样本,我们比较关注的是 False Positive,也就是负样本被错分为正样本。一张图中会有很多的负样本,但并不是错分成了正样本就会变成 False Positive,因为在得到最终结果之前,有一步 NMS,如果有离的比较近的框,最终只会保留一个框。如果它是负样本而且分数分错了,就是分数比较高,那么就会成为一个 False Positive。但同样也是一个负样本,在它周围被它抑制掉了,那么对最终的结果是没有影响的。
这里就得出两个结论:
第一条:局部来看,分数最高的框是最重要的,因为它在 NMS 时不会被抑制,会最终保留下来成为一个 False Positive,进而降低最终的 mAP。(补充下,这里的 score 指的是,如果是 COCO 这种80类的分类,最终输出是81个XX的分数,第0个向量代表 bad ground,这里的 score 代表的是从第1个XX到第81个XX,也就是非 bad ground 这类的 Score 的最大值。)
第二条:全局来看,分数越高的负样本越重要。因为计算 mAP 时,分数会从高到低排序,遇到的第一个分数最高的 False Positive,会降低 Precision,相当于把曲线向下拉,而且向下拉的起点会比其他的 False Positive 要早,所以最终结果会下降比较多。
2. Prime Sample

在回顾了正负样本之后,我们提出了 Prime Sample,对物体检测最终 mAP 有更大影响的框。仍然以这张图为例,这里有两个框,一个是黄色的框,一个是红色的框。红色框的 ground truth IoU 是0.58,score 是0.38;然后黄色的框 IoU 和 score 会比较高。对于 hard mining 来说,红色的框很明显是一个困难的样本,传统 hard mining 方法会更加倾向于给红色的框更大的 weight 或者把红色框 weight 作为1,然后其他简单的框作为0。但是对于 Prime Sample 来说,黄色的框 IoU 更大,所以黄色的框是我们的 Prime Sample,虽然它的 score 比较高,loss 比较小,但它应该是更被我们重视的。
那么,该如何定量的衡量一个 Sample 的重要性呢?
3. Hierarchical Local Rank (HLR)

我们提出了 Hierarchical Local Rank 的 mytrick:
这个 mytrick 是用来对一个 mini-batch 中的正负样本重要性进行排序的指标。
这里 HLR 是基于最终框的位置来衡量的。如在两阶段的检测器中,RPN 出来的框会被 regress 一次,然后得到最终的框。我们并不是基于 RPN 的框来衡量重要性,而是基于 RPN 的框 regress 之后再衡量它的重要性。这是因为上面的分析都是基于 mAP 的分析,mAP 都是基于最终的结果,所以 HLR 也是基于最终回归之后的框。
对于正负样本我们提出了不同的 HLR,对于正样本我们提出了 IoU-HLR,对于负样本提出了 Score-HLR 作为重要性的度量。
① Why mot IoU/Score?

为什么不直接用 IoU 或者 Score 来衡量呢?以上图为例,这里有两个人(2个 ground truth),有5个正样本{A,B,C,D,E},根据之前对正样本的分析,D 这个框 cover 的这个人的 IoU 是最高,而且比另外一个人 IoU 最高的框的 IoU 还要高,所以在这个5个框中 D 应该是最重要的框,它的 IoU 是0.92,如果这个框从0.92下降到0.81,是不是意味着它的重要性下降了?其实不是,它仍然是这张图中最重要的框,这说明 IoU 或者 Score 绝对的数值并不重要,重要的是在一个 mining batch 中他们的排序关系,这就是为什么不直接用 IoU/Score 作为重要性的度量,而要提出 HLR 这个概念。
② IoU Local Rank
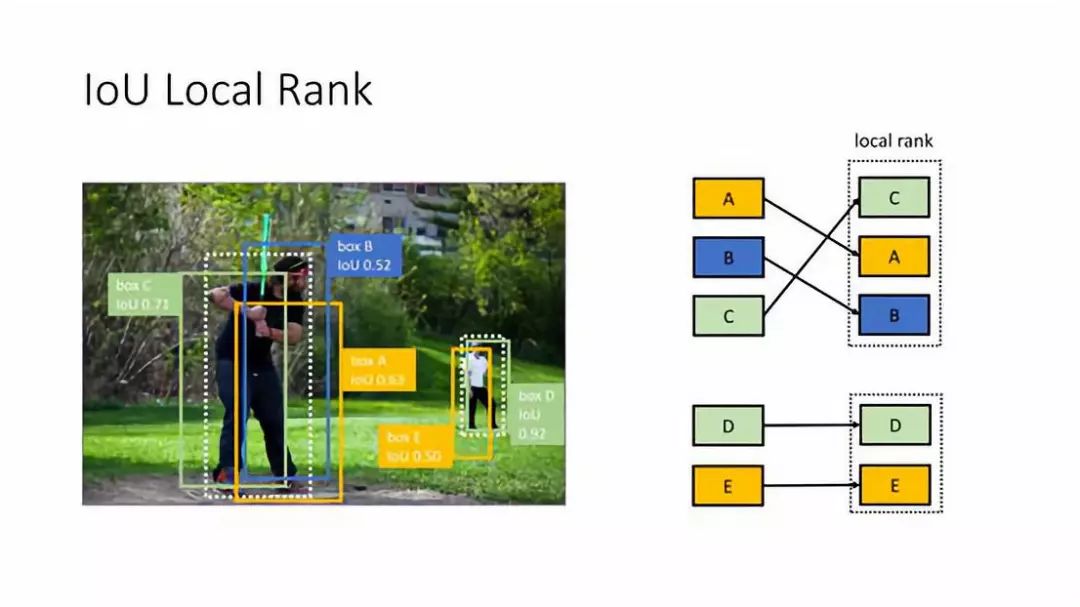
第一步:会先计算 Local Rank ( 这里都是以正样本为例 ),仍然有{A,B,C,D,E}5个正样本,对于 A,B,C 来说它们 cover 的是同一个人,所以它们是一组,然后 D 和 E 是一组,在每一组中,按它们的 IoU 进行排序,经过排序之后是 C>A>B,D>E,这样我们就得到了一个局部的排序,针对每个 ground truth 附近的框的排序。
③ IoU Hierarchical Local Rank
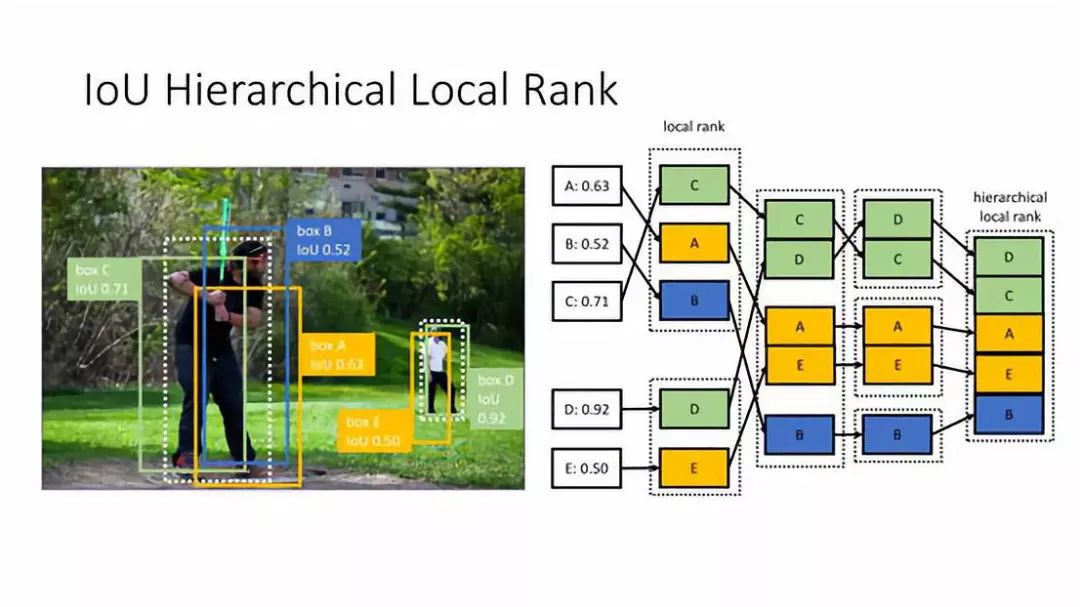
第二步:把每一组的 TOP 1 拿出来进行排序,比如 ABC 中的 TOP 1 是 C,DE 中的 TOP 1 是 D,把 C 和 D 拿出来做一个排序,然后把 TOP 2 A 和 E 也拿出来做一个排序,同样 TOP 3 也做一个排序,这样我们就得到了一个 Hierarchical Local Rank,最终得到的排序是 DCAEB。假设这张图中有 K 个 ground truth,TOP K 代表每一个 ground truth 周围 IoU 最大的框,接下来 K 个元素代表每个 ground truth TOP 2 IoU 的框。这就保证了分别跟之前对 mAP 进行分析时的两条结论相对应。第一条是对于每个样本 IoU 高的会排在前面,第二条是对于不同的 ground truth IoU 高的会排在前面。所以最终得到的 HierarchicalLocal Rank 刚好符合之前对正样本重要性的分析。
④ Score Hierarchical Local Rank

对于负样本来说,选择的就是 Score 的 Hierarchical Local Rank,这也是基于之前对负样本的分析,它的方式基本和正样本一样,把 IoU 换成 Score。
唯一不同的地方是,对于正样本来说天生的可以分成不同的 group,因为正样本都是和某个 ground truth IoU 大于一个阈值,很自然的按照不同的 ground truth 对正样本进行分组,这样就可以形成一些 local groups,但是对于负样本来说,并不是每个负样本属于某个 groundtruth,因为负样本不存在 ground truth,它可以在某个 ground truth旁边,也可以在一些纯的背景上。所以在做负样本的排序之前,会做一遍 NMS,获得一些 groups,就是哪些负样本是靠的比较近的、聚在一起的,从而可以执行和正样本相同的过程。
⑤ Sample distribution
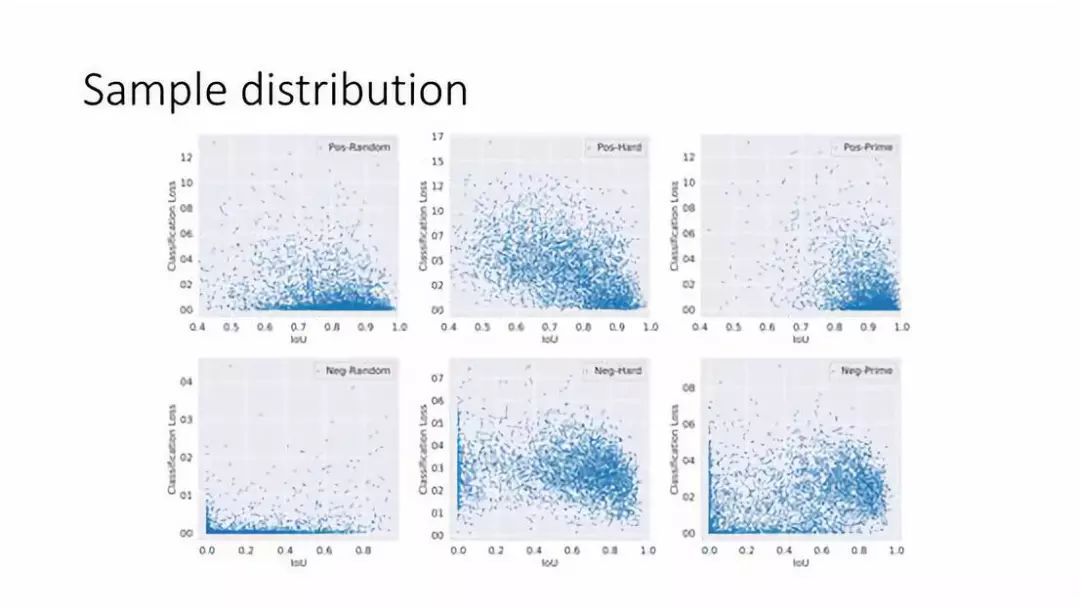
可以看下 Prime Sample 跟 hard Sample 以及 random Sample 之间分布有什么不一样。上面三张为正样本,下面三张为负样本。纵轴为分类的 loss,越小代表样本越简单,越大代表越难;横轴为 IoU。
对于正样本来说:可以看到 random Sample IoU 的分布从0.4到1之间都有分布,且 Loss 通常都是比较小的;对于 hard Sample 来讲,分布明显不一样更加偏上,样本确实比较难,且 IoU 从小到大分布比较均匀些,相比于 random Sample 在 IoU 比较小的区间分布会比较多一点;对于 Prime Sample 来说,基本集中在右下角,IoU 比较高同时 Loss 比较小的样本,所以 Prime Sample 和 hard Sample 某种意义上讲是有一定冲突的。
对于负样本来说:random Sample 的 loss 比较小,也有非常多的小 IoU,比如 IoU=0 的部分;对于 hard Sample 来说,一个非常明显的区别是 IoU 靠右了,对于难的样本来说 IoU 通常较高,这和上篇 paper 的结论是吻合的,同时 loss 也变得偏高;对于 Prime Sample 来说,跟 hard samp 相比多了很多 loss 比较小的 Sample,如 loss=0 的地方分布也有一点小小的聚集,但同时也有一些比较难的 Sample,Prime Sample 是整个样本空间中分布最广的,也就是 IoU 会从小到大,Loss 也会从小到大。
从中我们可以看出 Prime Sample 跟 hard Sample 以及 random Sample 是三种不一样的分布。
⑥ Analysis
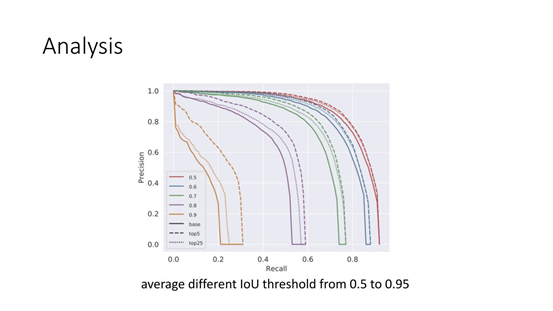
这里做了简单的分析,如果我们提高 IoU 的 HLR,提高某一部分 Sample 分类的 Score,就是分类的准确率,那么最终的 mAP 会如何变化。图中,实线是 baseline,比较短的虚线是提高 top 25 的 IoU HLR 的 Sample 分类的 Score,比较长的虚线是只提高 top 5 的 IoU HLR 的 Sample,当然我们会保证这两种情况下 loss 的减小程度是一样的,也就是说这两种分类器的分类性能是相当的。我们可以看到只是提高 top5 的 IoU HLR 样本分类的准确率,mAP 的涨幅会超过 top 25 ( 可以看成比较平均的提高 ),就是说聚集在小部分 Sample 上做提高,比平均的提高分类器的分类性能对 detection 这个任务来说是更加有效的。
4. PrIme Sample Attention (PISA)

接下来讲下我们的方法:PrIme Sample Attention ( PISA ),它的目的是为了在分类器训练的时候,更加的关注 Prime Sample,主要分为两个部分:
Importance-based Sample Reweighting,就是说给 PrimeSample 更大的 loss weight,给那些不重要的 Sample 更小的 weight。
Classification-Aware Regression Loss,跟 Motivation 第二条比较类似,Classification 和 Regression 并不是完全独立的,他们是互相耦合的。
① Importance-based SampleReweighting(ISR)
首先看下如果做 ISR,对于正/负样本来说,首先都得到 HLR,然后把它映射成一个 loss weight,中间会有一个 importance value,因为一个 rank 是一个整数。
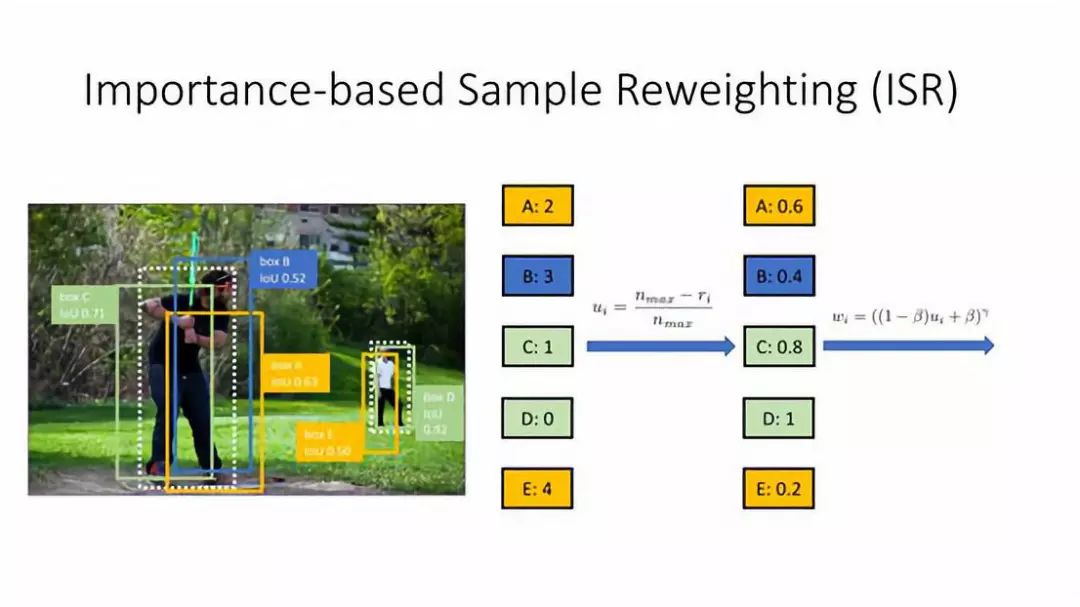
第一步:把0,1,2,3,4这种排序通过线性函数 ( nmax-ri )/nmax 变成一个小数,ri 就是它的 rank,nmax 是每一类中最大的样本数。把它变成一个从0到1的实数之后,用一个指数函数把它转换成一个 loss weight 就是 wi。
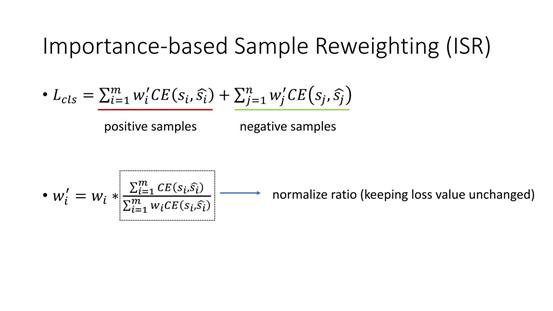
如果重写一些分类的 loss,如上面的公式 Lcls,如果是传统分类的 loss 就是 random Sample 往下,分类的 loss 是没有 wi' 和 wj' 的,之所以分了 i 和 j 是为了区分正样本和负样本,里面的 loss 还是用的 Positive,对每个 Sample 都给它一个 wi' 或者wj' 这么一个 loss weight,wi' 或者 wj' 是通过上面得到的 wi 做了一个归一化,因为如果随便加了一个 loss weight,最后总的 loss 的数值变化可能会比较大,为了消除其它因素的影响,就会保证在加了 loss weight 之后,loss 的数值跟不加它是一样的,所以就乘了一个归一化的项。
② Classification-Aware Regression Loss
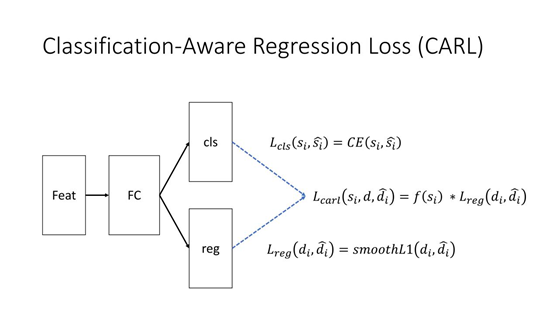
基于我们的思考分类和回归这两个 branch 不是完全独立的,而是耦合的。传统来说,一般对于检测器会有一个分类的分支和一个回归的分支,分类的分支会有一个 cross entropy loss,回归的分支大部分会用一个 smoothL1 的 loss,那么如何把这两支融合起来呢?很简单,我们会再加一个 classifification-awareregression loss,就是 carl,这个 loss 会把分类的 Score 经过一个函数的映射 ( 这个函数跟刚才 Sample reweight 指数函数形式完全一样的 ),跟原始的 regression loss 相乘,这就是 classifification-awareregression loss,为什么叫 classifification-aware ,因为这个 regression loss 是把分类的 Score 乘了上去,这里的 si 是指正样本 label 分类的 Score。

我来看下是否能达到更加关注 Prime Sample 的目的。上图为 CARL 的详细形式,跟 Sample reweighting 基本是一样的,vi 相当于刚刚 si,上张图中的 si 没有做任何的 detach 操作,所以在优化 CARl 这个 loss 的时候,梯度会回传到 si 上面,那么在计算偏导的时候,比如让 CARL loss 对 si 求一个偏导其实跟 regression loss 是一个正相关的关系,也就是说 regression loss 越大,那么对 si 的导数就越大,如果 regression loss 越小,对 si 的导数就越小。这里的导数或者梯度意味着 Score 会受到抑制,因为在优化的时候,在下一轮,会让 si 尽量的小,所以加了这一项之后,所有的样本分数在优化的时候都会倾向于变小,来减小这个 loss。这个减小的程度是跟 regression loss 成正相关关系的,关于梯度的详细推导,在 paper 中有一个附录,感兴趣的同学可以看一下。
这里的 regression loss 是 Sample importance 的一个估计。因为实际的 Sampleimportance 是 IoU 的 HLR,Loss 越小只会说明回归越准,那么它的 IoU 可能会越大,IoU 的 HLR 会近似的越大,所以这里说它是 Sample importance 的一个近似,但我们发现这种近似 work 的很好。所及加了 CARL 之后,就会通过让那些不重要的 Sample 的 Score 抑制的更厉害,Prime Sample 的 Score 抑制会比较轻,这样就更加 Focus 在 Prime Sample,让不重要的 Sample 受到忽视。
5. 实验结果
① Comparison with Random and Hard
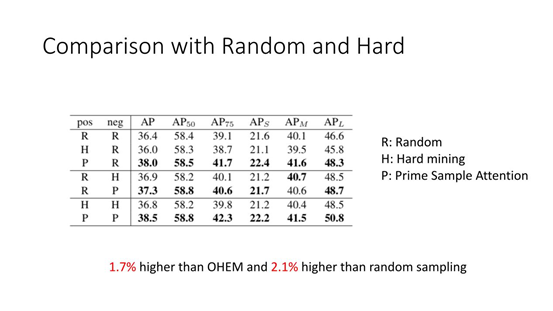
这是在 COCO 公开测试集上的对比,这里分别对正样本和负样本采用了不同的策略,如果正负样本都用 Prime Sample Attention,会比都用 OHEM 高1.7%,会比 random sampling 高2.1%。
② Results on COCO test-dev
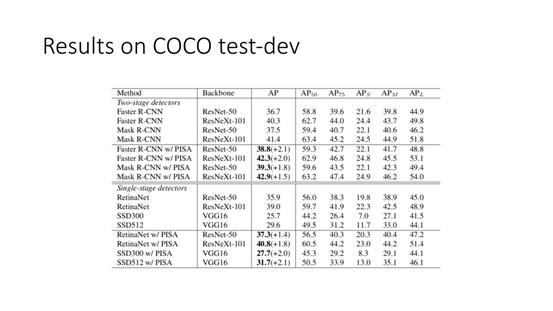
我们也在 COCO test-dev 上跑了不同的 model。我们发现 PISA 这个方法在各个模型上差不多都有2个点的提升;并且对 model 的 size 并不是很敏感。
6. Examples
这里是一些简单的可视化例子:

PISA 根据之前的分析,主要解决两个问题:
第一个,False Positive 会更少,我们可以从图中看出来。
第二个,对于每个 ground truth 周围非常准的 Sample,Score 会偏高,这个也可以从图中看出来。

这里也是一个 Sample。
接下来讲下再加入 Prime Sample Attention 之后,它是如何 work 的,这里分别看下 ISR 和 CARL 对 classification scores 的影响.
7. How ISR affects classification scores?
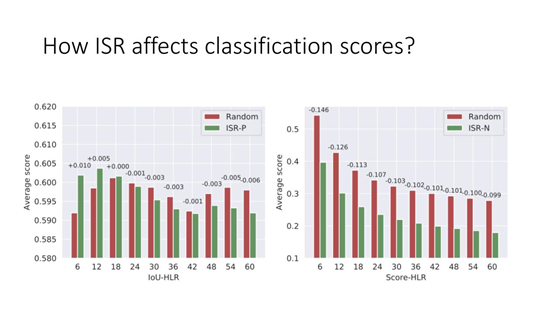
首先研究下 ISR,这里的 ISR-P 和 ISR-N 分别表示正样本和负样本的 Sample Reweighting。
左图表示正样本的 ISR,根据 IoU-HLR 给不同的 weight,在最终的结果中,IoU HLR 越小,排序结果越靠前的 Sample 的 Score 相对 random 来说是增长的,但是排的靠后的 Sample 的 Score 是在降低的,这和我们的期望非常符合,尽量突出 Prime Sample,而抑制不重要的样本。
右图对于负样本来说,Score 越低说明负样本分的越好,Score-HLR 越靠前的样本降幅越大,对靠后的样本,降幅会稍微少一些。
8. How does CARL affect classification scores?
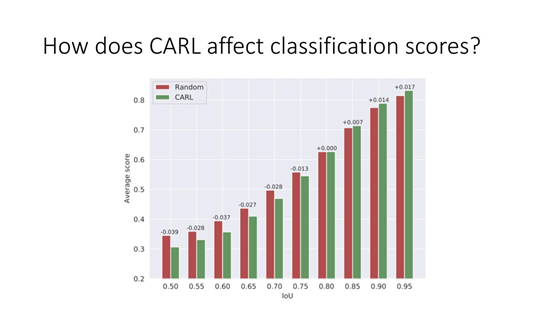
如上图,对于 IoU 比较大的样本,分类的 score 会变高,对于 IoU 比较小的样本 Score 是会降低的,这样就更加的拉开了 Prime Sample 和不重要的 Sample 的距离。
9. Postive samples
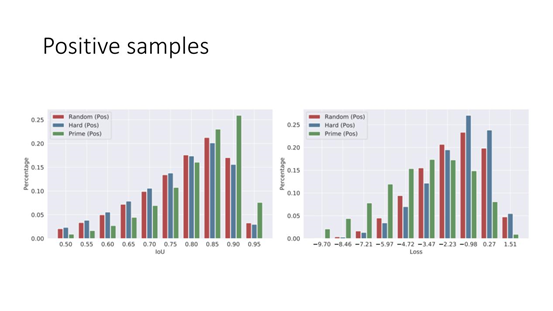
对正样本来说,最后的结果 IoU 比较高的部分是更受关注的,且对应的 loss 会比较小。
10. Negative samples
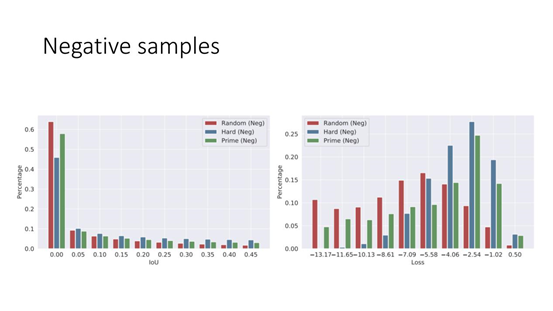
负样本来看,random sampling 是 loss 小,IoU 也小;Hard sample 是 loss 大,IoU 也大;Prime sample 刚好在二者之间。这说明对于负样本来说,Prime Sample 相当于 Random Sampling 和 Hard Sample 的中间态。
——总结——
Sample Imbalance,IoU-balanced Negative Sampling 和 Instance-balanced Positive Sampling,在不带来 overhead 的情况下,有接近1个点的提升。
Sample importance,我们重新思考了什么样的 sample 才是重要的 sample,也思考了分类任务和检测任务的区别,提出了 Prime Sample 的概念,来对检测器的训练进行优化。
致谢:
以上就是分享的所有内容,谢谢大家。
——END——
文章推荐:
DataFun:
专注于大数据、人工智能领域的知识分享平台。

一个「在看」,一段时光!👇


