AI性能暴涨7倍,AMD昨夜发布Instinct MI100新卡,英伟达也祭出百亿亿次超算时代神器

新智元报道
新智元报道
来源:外媒
编辑:QJP
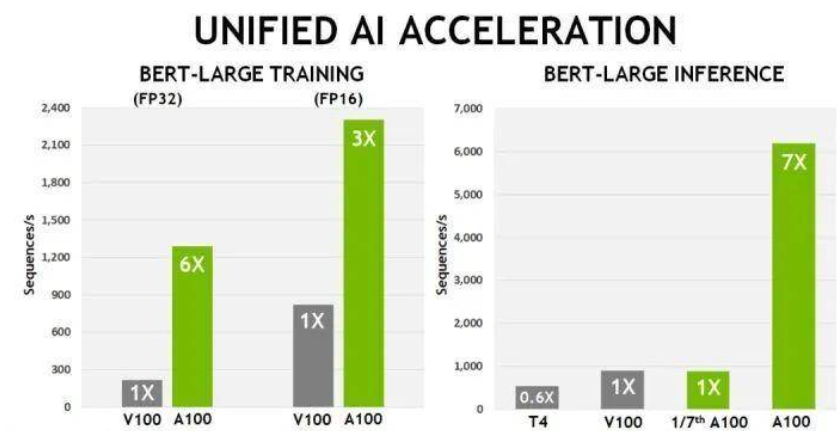
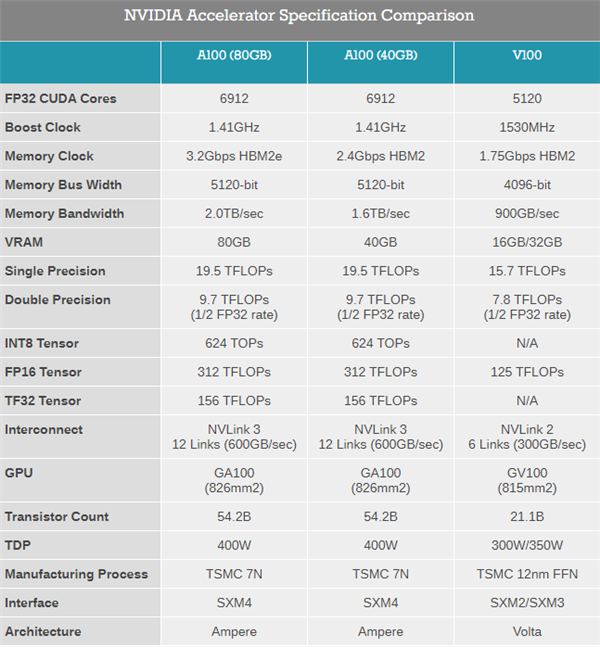
【新智元导读】AMD于昨晚正式发布了首款基于全新CDNA架构的Instinct MI100 GPU以及配套的ROCm 4.0生态系统,而英伟达也不甘示弱,于今日发布了 A100 80GB GPU,将支持NVIDIA HGX AI 超级计算平台,内存比上一代提升一倍,能够为研究人员和工程师们提供空前的速度和性能,助力实现新一轮AI和科学技术突破。
AMD 推出 Instinct MI100芯片,AI性能暴涨7倍
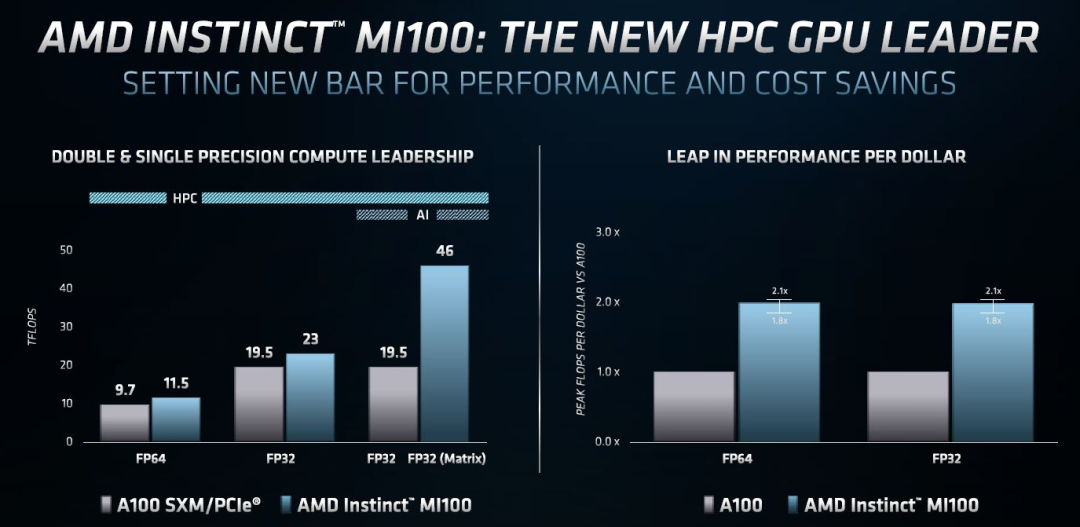





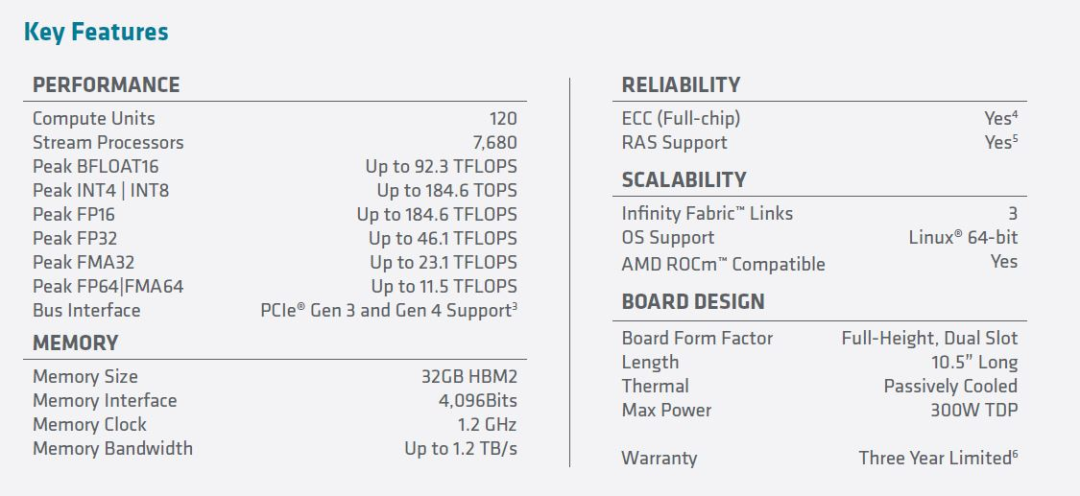


英伟达 A100 80GB新卡,与AMD新品正面刚





登录查看更多
相关内容

Arxiv
0+阅读 · 2021年2月2日





相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2021年2月2日