现在合成照片的真实感在某些程度上已经比真的还真,在这其中,
GANs(生成性对抗网络)和变分自动编码器功不可没
。
然而,对于生成模型在深层生成表征中学到了什么,以及如何由最近GANs引入的分层随机性构成逼真的图像,研究者探索的还是不够。
近日,香港中文大学教授周博磊近期分享了他们实验室在视觉生成方面的成果,并做了题为《深度生成模型中的隐藏语义》的报告,介绍了生成模型中的可解释性因子,如何去发现这些可解释因子,以及如何把发现的可解释因子应用到图像编辑应用之中。
以下是报告文字版,AI科技评论做了不改变原意的整理。
从GAN谈起
图像生成近几年进展非常迅猛,从2014年GAN被提出来开始,到2019年GAN生成的图片质量逐年上升。到近期,StyleGAN v2以及BigGAN已经可以生成跟真实图片几乎没有差异的图片。这就向我们提出了问题,即
神经网络为什么可以从大量数据中学到关于实际数据的分布,并可以生成如此真实的图片
。也就是说,我们想进一步探索生成模型到底学到了什么样的表征。
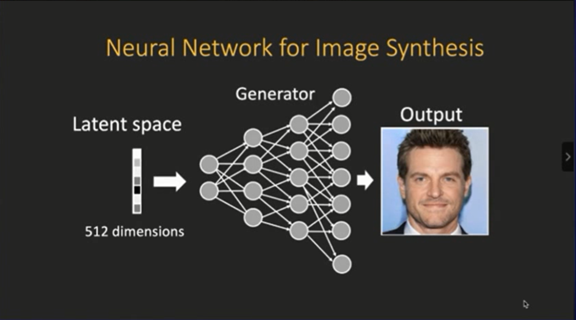
下图是一个简单的生成模型的结构,我们向生成模型输入一个噪声,这个噪声可以从一个分布里面采样,然后生成模型的神经元经过层层传递,就可以生成一张图片。
生成模型本身其实是一个卷积网络,每一层有很多的卷积神经元,通过逐渐把特征图放大,最后变成一张图片
。这里就带来一个问题:
为什么网络可以把一个完全噪声的向量变成一张图片?
下图展示了一个简单的可视化,
在隐空间里面对随机向量做一个简单的随机游走,
也就是说每一时刻对向量加上一个随机扰动。然后你可以发现,输出图片的内容会进行很大的语义变化,包括发型、人脸朝向、性别、年龄等因子,
都被包含到隐空间里面去了
。
![]()
这自然而然引出一个问题,我们是不是可以在隐空间里挖掘这些可解释因子,从而可以按照意愿去控制输出图片?
可解释因子探索详解
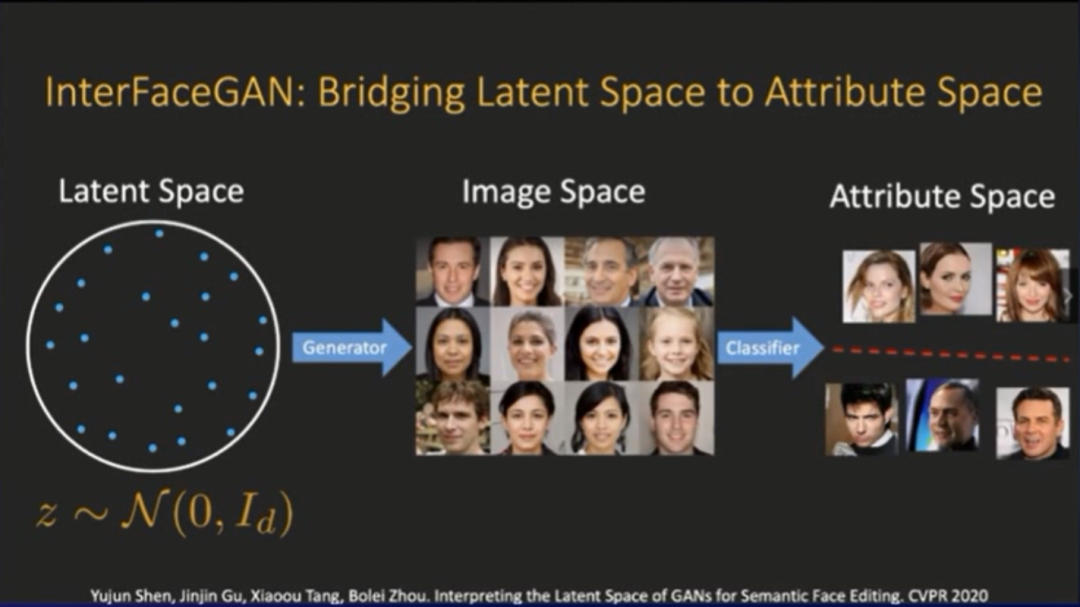
在今年CVPR2020,我们提出了一个叫InterFaceGAN的方法,这个方法就是为了在隐空间跟最后输出图片的语义空间建立联系。这个方法本身非常简单,但是很有效。
具体步骤是,
训练好了生成模型过后,就得到了一个隐空间。然后我们可以从隐空间里面进行采样,把这些采样出来的向量放到生成器之中,进行图片生成,后面可以再接一个现有的分类器,给生成的图片打上一个具体的语义标签(比如性别标签)
。
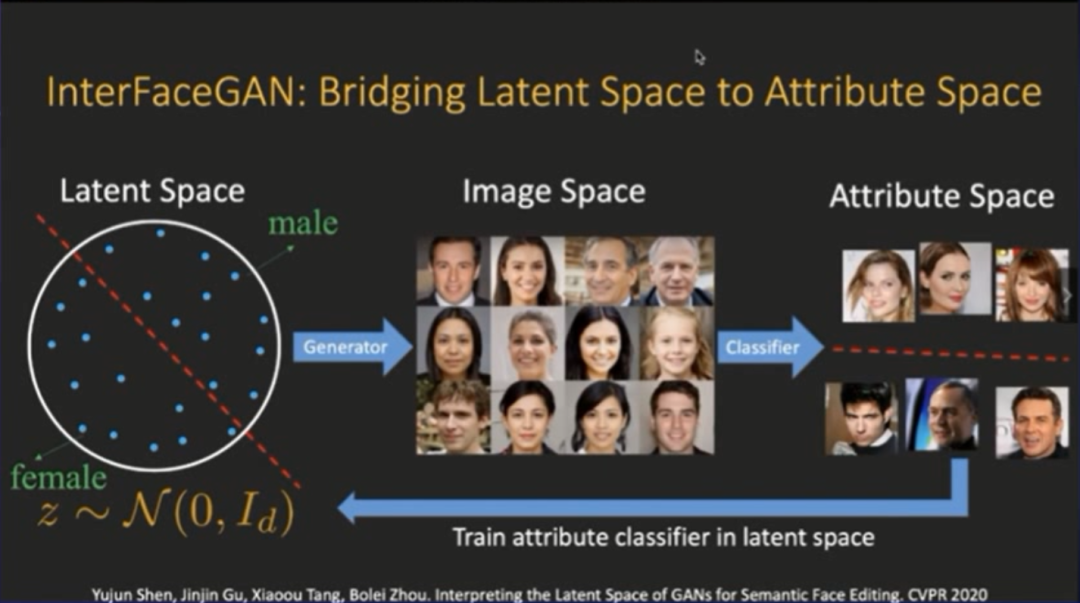
这样我们就可以把预测出来的标签当做隐空间向量的真实标签,我们进一步再回到隐空间,把预测的标签当成真实标签,然后训练一个分类器,对隐空间向量进行分类。
我们发现,
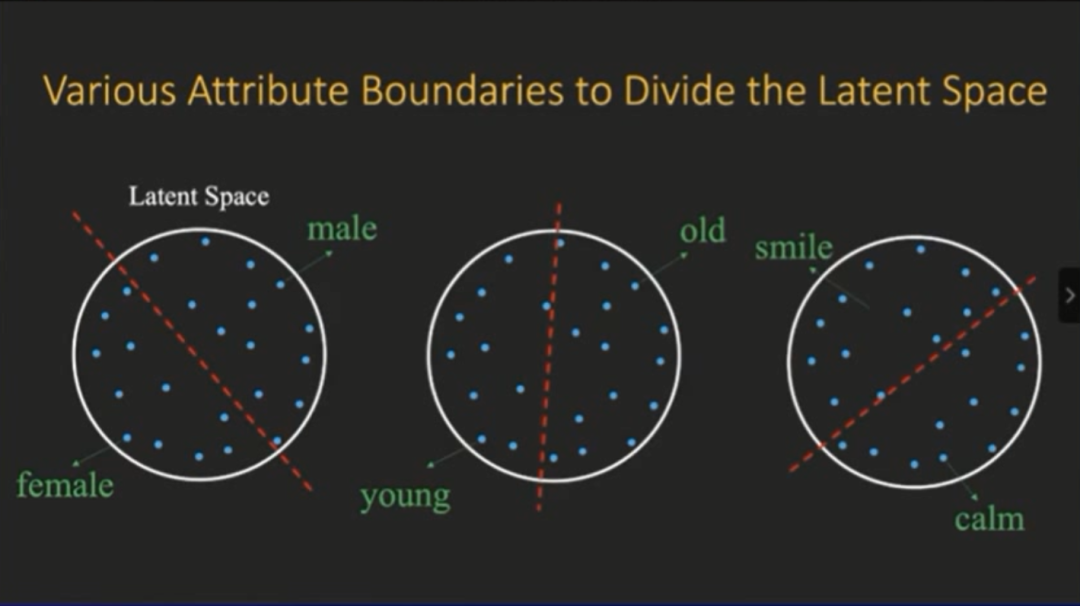
在隐空间里面,GAN其实已经把隐空间的向量变得非常解耦。只需要用一个线性分类器,就可以在隐空间里实现90%左右的二分分类准确率。
在训练了一个线性分类器后,我们就在隐空间里得到了一个子空间,这个子空间就对应了生成图片的性别。
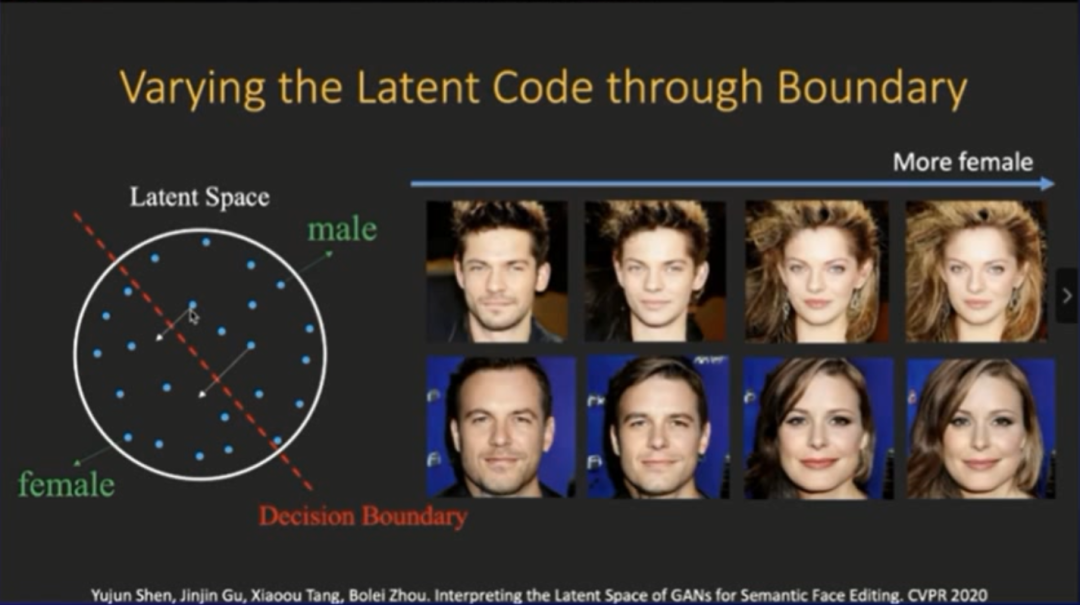
比如我们现在在隐空间里面采样两个向量点,我们可以做一个操作,把这两个向量朝着边界推。我们会发现,
图片的语义产生了非常连续的变化
。
如下图所示,右边这两张图在刚开始是男性头像,然后我们逐渐把两个向量往边界推,发现图中人物的女性特征逐渐显示出来,而且这个过程非常连续,这样我们就实现了改变性别的目的。
这里进一步做一个比较有意思的测试,比如说我们想看在GAN模型里面,典型的女性特征是什么样子。
下图中6个人本来是男性,我们找到了他们的中性边界,然后沿着边界一直推。你会发现6张图就从不同的帅哥变成了金发美女,而且金发美女之间也是比较类似的。这显示出了GAN自己学到女性化特征是金发碧眼、妆容比较浓。
我们可以反过来做,一开始有6张女性的图片,然后将她们往中性边界推,我们来看看GAN学到的典型男性特征是什么样子。
你会发现,
这6张金发美女的图片都变成了同一个男性,这显示出了GAN自己学到男性化特征是秃头大叔。
这样我们就可以做一系列的编辑,比如说现在有一位男性,想让自己的照片变得更酷,我们可以让照片中的人物戴上墨镜,然后有一位女性,希望自己的照片能看起来年轻一些,我们照样能实现这个需求。另外这位女性觉得拍照角度不令人满意,我们可以把侧脸照变成正脸照,如果对自己的性别也不是很满意,我们照样能实现这个需求。每一个边界其实都是一个线性的二分类器。
我们发现,
在隐空间里面,图片的质量也是一个语义子空间
。有时候GAN生成图片的质量比较差,如下图上排所示。我们可以把这些图片向着质量更好的边界推,就可以修复这些图片。
我们尽可以在隐空间里面学到其他语义相关的边界,比如脸部朝向、表情、年龄等等。
我们原本训练的是无条件的GAN,通过这种简单的线性操作,就可以得到有条件的GAN,然后根据意愿去改变图片对应的语义特征。
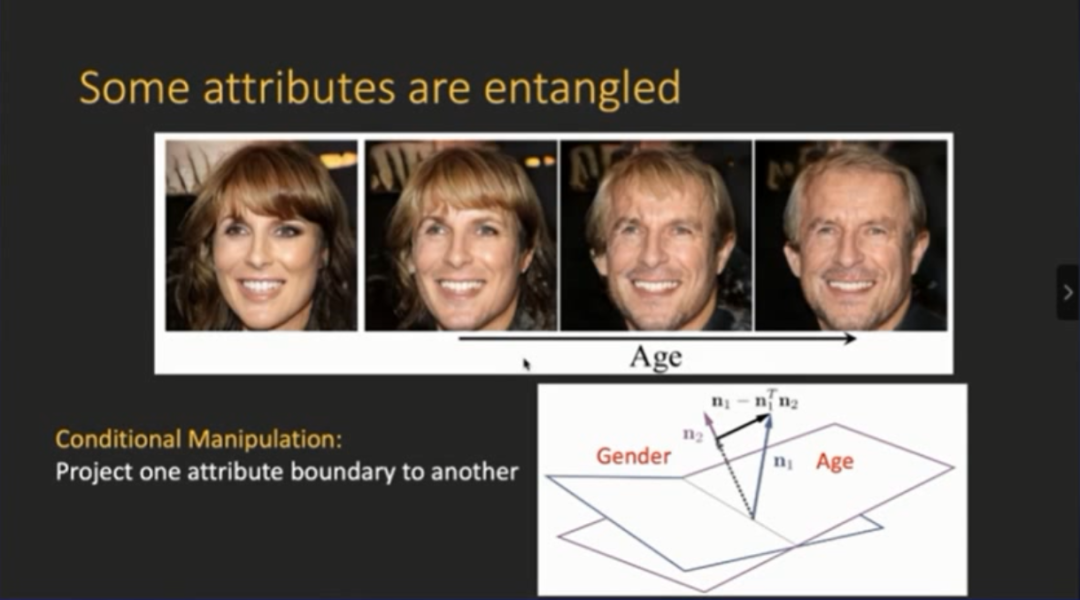
我们进一步发现,有时候有些特征之间是有关联的。比如下图,使女性的年龄变大,结果最后她的性别也发生了变化。
针对性别变化,我们提出了条件操作(conditional manipulation)的解决方案,即在得到线性分界面之后,由于两个语义(性别)都有不同的信息分界面,因此可以进行投影操作,确保投影过后消除它在另外一个语义属性上面的变化。
经过上述简单操作,得到的结果如下图所示,
随着年龄的增长,模型生成了正确的图片
。因此,性别保持不变,只改变年龄,这种条件操作产生的效果非常好。
另外,我们还有一些工作分析场景生成中存在的可解释因子。例如下图名为HiGAN的工作,就提出了一个解析场景生成里面的解释因子,找到可解释因子过后,就能改变和场景相关的一些语义特征,例如布局、风格、光照情况。
虽然能够让图片达到一些变化,但是仍然存在一个问题,即
图片的编辑都是在生成模型上面进行的
。换句话说,这些图片本质上都是从生成模型里面进行采样,然后生成。
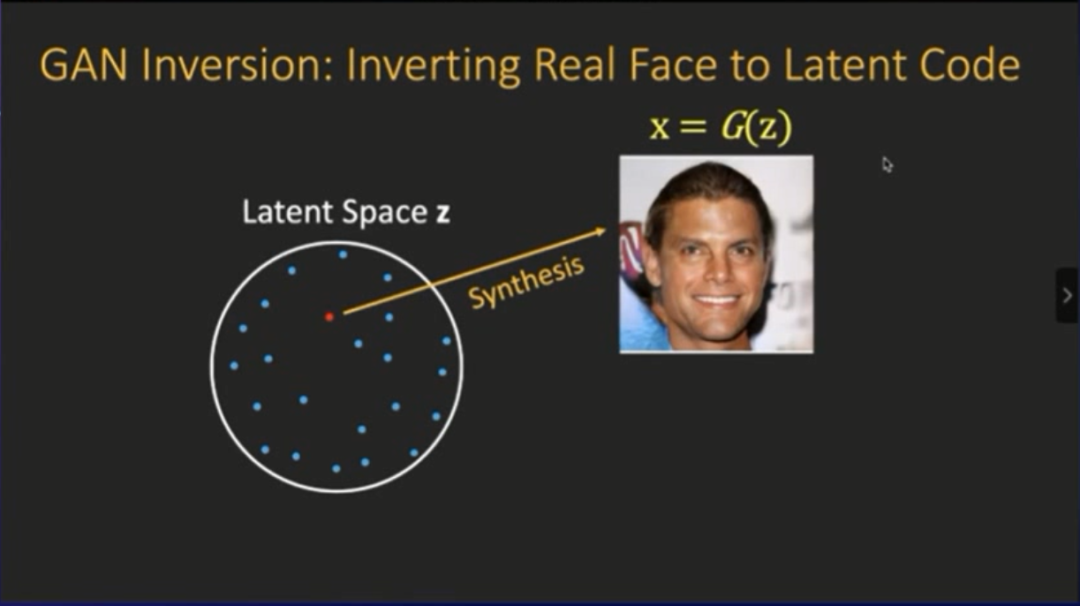
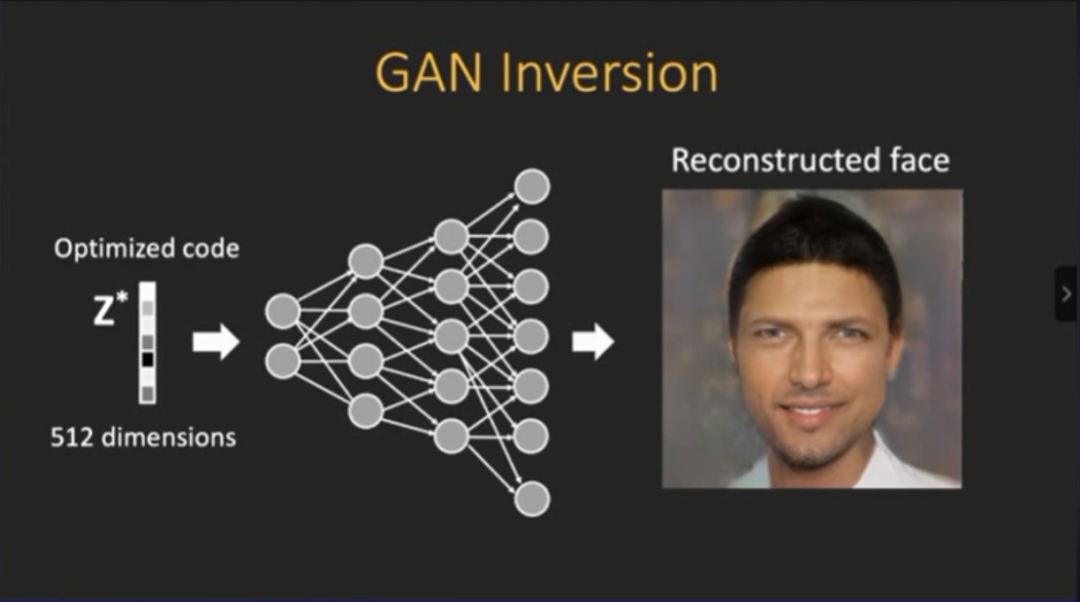
但是我们实际需要的是编辑“自己”的图片,例如下图我个人真实的照片。但这就会面临一个问题:
GAN逆映射
(GAN Inversion)
为什么有这个问题?原因是:
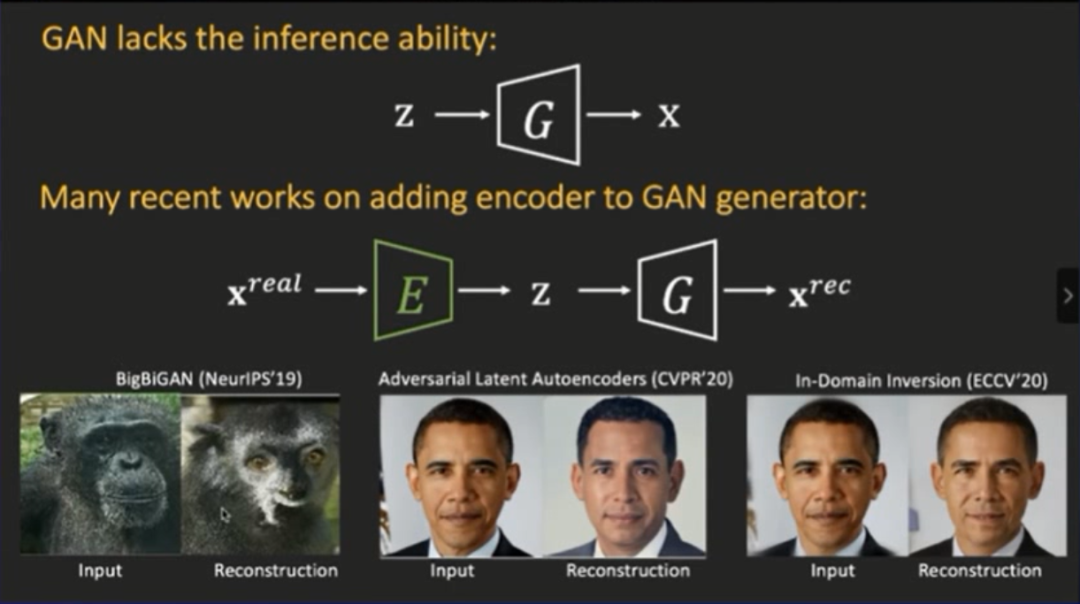
相对于VAE(自动编码器),GAN模型并没有推断的能力
。因为GAN并不能直接把图片转换成隐变量,GAN从噪声开始,并没有编码(encode)的操作,所以需要GAN逆映射:给定一张真实的图片,然后进行逆映射,从而将其返回到隐空间中。
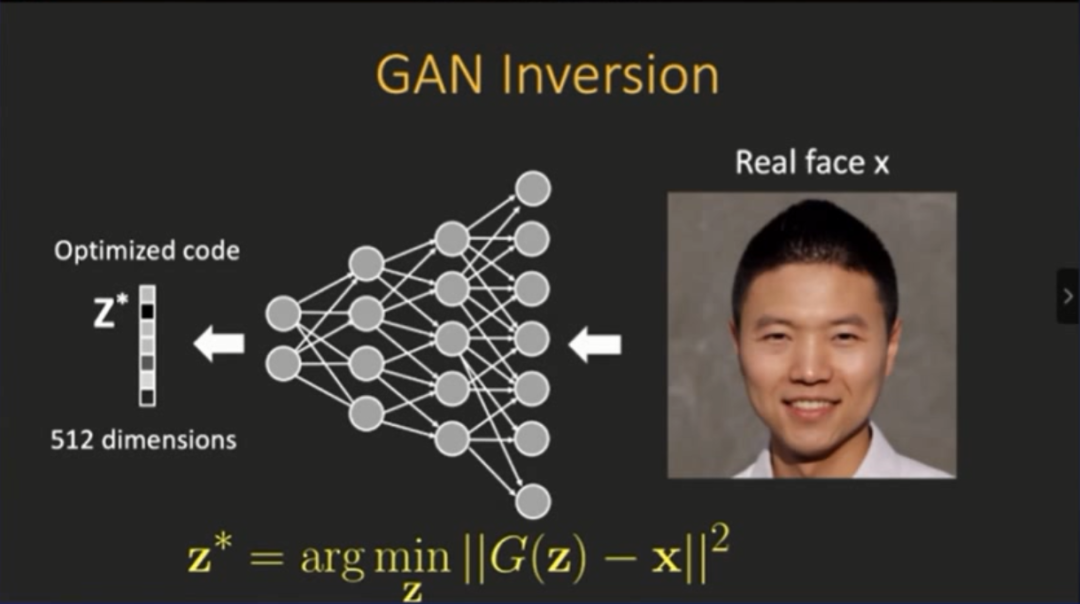
来看最简单的测试:先把图片放进去,然后用L2 损失函数进行优化,然后发现此问题非常困难,并不只是简单的求解优化问题。
上图是一个效果,也就是进行简单的优化操作之后,得到的一个优化编码(code),然后我们将其放回生成器当中去,结果如下图所示,它生成了一个“不像我”的人脸。
将这张图片和之前图片进行对比,有趣的发现是,这两张图片在细节和纹理上面“对得上”,但是整体表现有差异,出现这种问题的原因可能与初始化有关。
然后我用不同的初始化操作进行了测试,结果是依然没有生成非常完美的图片,更多生成的还是“西方人脸”。因此这便证明了
生成器自身存在偏见,原因在于数据
,因为我们训练模型的时候用的都是celebrate HQ此类的数据集,其包含的大部分都是欧洲人的面部图片。
除了数据,算法偏见也是原因之一,如何探索数据和算法中存在的偏见,也是现在AI的热点。因此我们便想着如何重建模型,然后避免这种偏见。
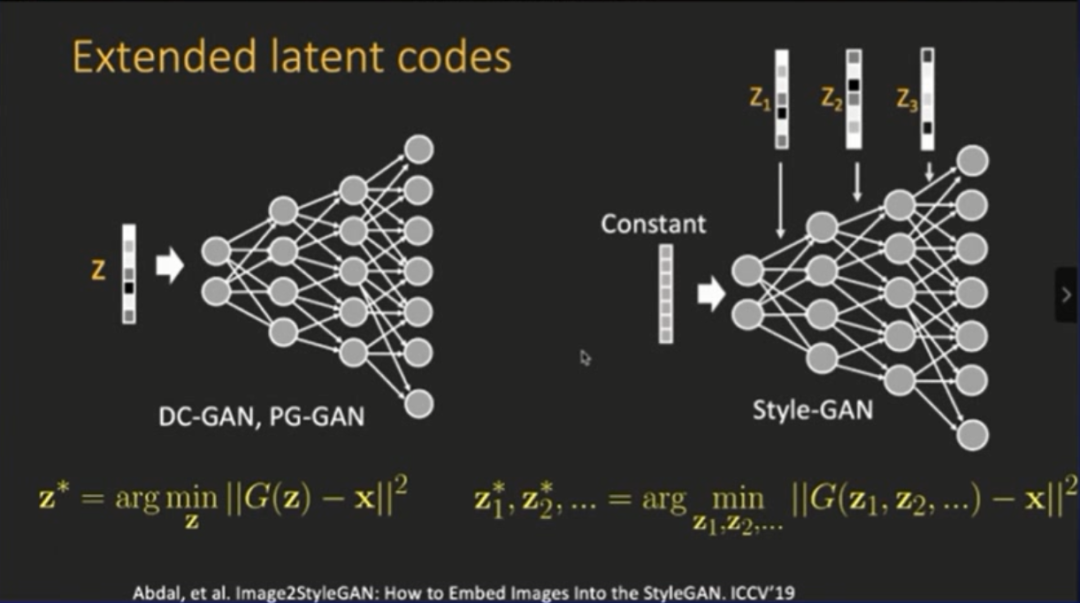
我们进行的操作和Style GAN模型里面的操作类似,相对于之前的 DCGAN跟PGGAN,它是使用了多维度的隐变量,每一层里面都引入了一个隐变量,然后同时呈现多个层次的隐变量,如此便能重建。
这样会使得向量空间里面编码的信息非常多。例如重建的隐空间的数据维度只有512,现在每一层都有了变量,那么就是512X层数,比如说有14层,那就是512X14层,向量相当于大了14倍。
其实,这种直接优化不同层的隐变量的方法,是去年ICCV提出的Image2StyleGAN的方法。我们也对这种方法进行了测试:进行14X512维的隐空间优化之后,就可以比较好的把图片进行重建。
但我们又发现一个问题:训练过程好像是单纯在“过拟合”一张图片。由于生成器“只见过”人脸,因此我们用非人脸图片进行了测试,例如把猫、卧室的图片放进去,仍然有比较好的结果。
为什么人脸生成器可以把一个非人脸的图片“完美”重建出来?我们进一步进行了测试,发现
重建过程完全是在“过拟合”
。
具体操作过程是:我们把之前InterfaceGAN的操作的方法(改变隐空间)以及latent code进行应用,然后在小布什的人脸图片上面进行操作,例如加上微笑,加上眼镜,能发现此效果都非常差,这就说明重构图片的时候完全是在“过拟合”。
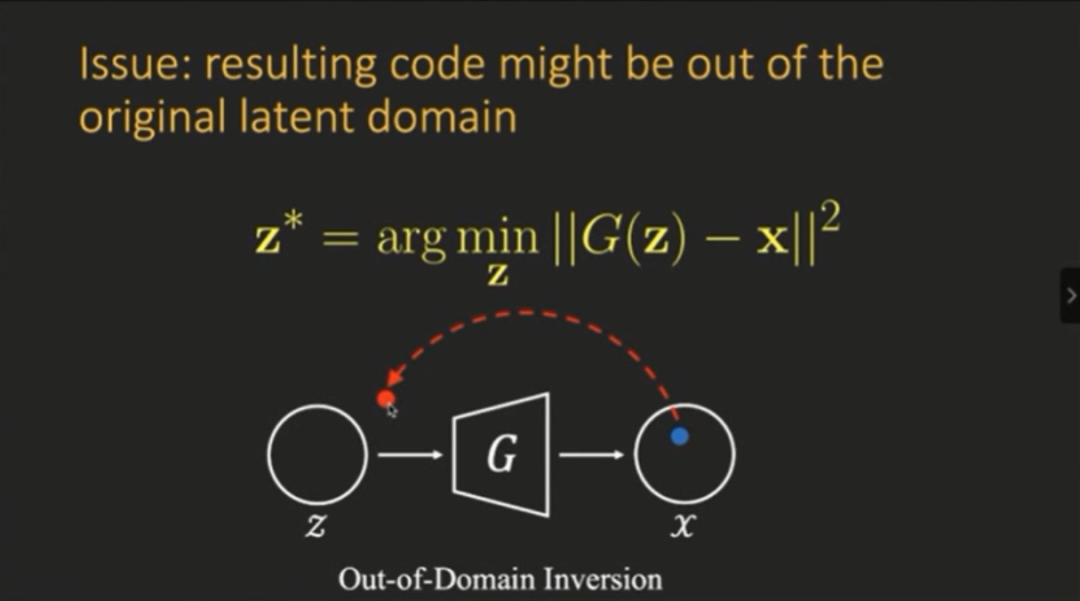
其实,输入图片,逆映射出来的latent code并没有语义性质,因此并不具有可编辑性。这是因为存在领域外(out of domain)的问题,也就是说我们解优化问题的时候,其实并没有任何约束,有可能它并没有回到原始的隐空间。
另外有一部分工作是为了增强GAN的推断能力,引入了一些编码器。换句话说,就是得到生成器之后,强行训练编码器,从而达到高效重建图片的结果。类似的工作,例如Bigbigan,虽然它能够把输入图片重构出来,但效果并不好。因为此方法本身并不是以重建效果好的图片为目标,它是为了构建特征学习的过程。
今年CVPR有一篇讲述ALA的方法,它是在架构前面加上了自动编码器,然后相对可以得到一个比较好的重建,但是其标识(identity)还是不能保留。
然后我们最近在ECCV上的一个工作是改进了编码器,重建效果自然非常棒。但是仔细观察,生成的图片和原始的图片也不是同一个人,所以他编码器重建的再好,其实也没办法保证百分之一百进行重建。
所以我们提出了一个把两者结合的方法,
把编码器当成一种约束
(constraint),也就是编码器约束优化(encoder constraint optimization)。
以前求解优化问题的时候,只是单纯进行优化。现在的操作是:
先生成图片,然后重新编码回去,最后将图片的latent code进行重建。
我们在损失函数项中添加了约束,使得重建出来的latent code尽可能分布在原始的领域(domain)。我们把这个方法称为领域内逆映射(in domain inversion),因为有了正则项的存在,就使得重建出来的编码受到约束,因此便能更好的保留原始语义空间或隐空间的语义特性。
所以,我们ECCV上面的一项工作提出了GAN逆映射的方法,与Image2styleGAN进行对比之后,发现重构效果是相差无几,区别在于
我们使用InterfaceGAN之后,添加约束的优化能够极大改进其语义特征
。例如在进行改变小布什的年龄、增加微笑、戴上眼镜等等操作之后,都比image2StyleGAN直接优化的效果要好。
可解释因子的应用
以下动图是一个简单的 demo,对模型输入的图片都是真实的人脸,通过在隐空间里进行重构,可以对这些图片进行比较真实的编辑。
然后可以进行插入操作,如下动图所示,可以生成一个渐变的人脸图片。即可以调整不同人脸的语义特征,从而实现从一个人脸到另一个人脸的生成过程。
根据上述方法,我们实现了一个有趣的应用:
语义传播
(semantic diffusion),大致意思如下图所示:横轴是背景,可以看到有很多背景图片,现在有一张前景的图片,我们需要操作的是把Yann LeCun的正脸“贴”到背景图片上去。
直接复制粘贴不太现实,于是我们把直接把图片放进模型的优化过程中,让前脸重构,让背景自由浮动,从而达到兼容的效果。这是一个非常逼真的传播(diffusion)过程,其本质是
前脸的信息逐渐传播到背景
。
我们另一个工作是探索
图片处理
的应用,例如用GAN 逆映射进行上色、超分、去噪等操作。把训练好的GAN当做图片的先验,然后整合到过程中去,会起到四两拨千斤的效果,还能够填充缺失的区域信息。
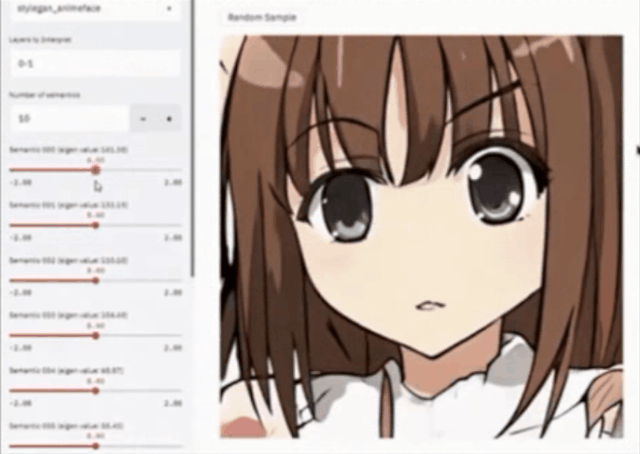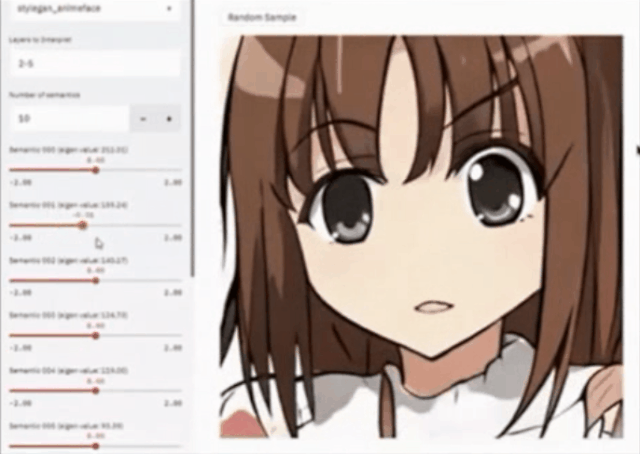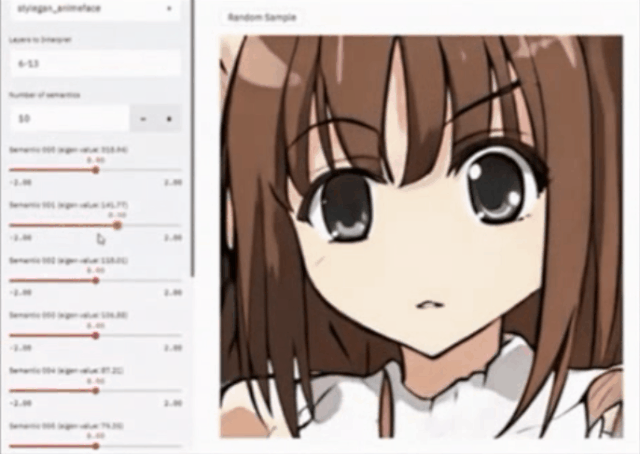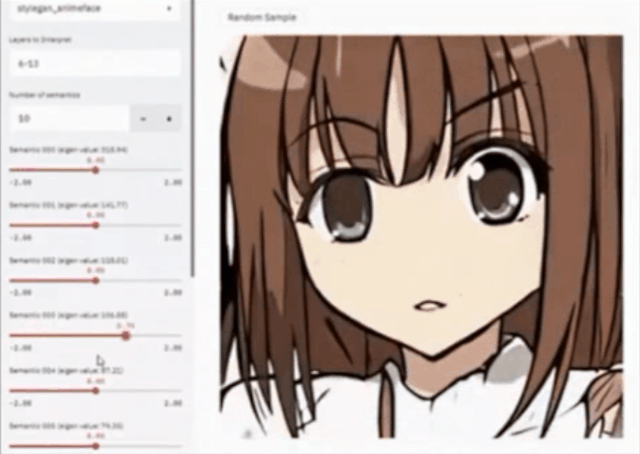
还可以通过非监督的方法寻找隐空间里面可控的因子,例如将其应用在卡通图片上面。下图(左)就是一个简单的交互页面,它本来只是生成一个卡通图片,我们可以通过改变它不同的语义特征、脸型、笔触的大小、嘴巴的大小、眼睛的大小等等进行非常有意思的改变。这相当于把InterfaceGAN的方法用到了非监督的领域。
大多数情况下,训练的图片,例如油画、国画或者一些卡通图片,其实并没有标签,那么如何非监督的去寻找可解释因子?这也是一个比较任何重要的问题。
https://genforce.github.io/
在10月1日头条《秋天的第一本AI书:周志华亲作森林书&贾扬清力荐天池书 | 赠书》留言区留言,谈一谈你对这两本书的看法或有关的学习、竞赛等经历。
AI 科技评论将会在留言区选出15名读者,送出《阿里云天池大赛赛题解析——机器学习篇》10本,《集成学习:基础与算法》5本,每人最多获得其中一本。
活动规则:
1. 在留言区留言,留言点赞最高的前 15 位读者将获得赠书,活动结束后,中奖读者将按照点赞排名由高到低的顺序优先挑选两本书中的其中一本,获得赠书的读者请添加AI科技评论官方微信(aitechreview)。
2. 留言内容会有筛选,例如“选我上去”等内容将不会被筛选,亦不会中奖。
3. 本活动时间为2020年10月1日 - 2020年10月8日(23:00),活动推送内仅允许中奖一次。
![]()
点击阅读原文,直达NeurIPS小组~