【机器学习】机器学习特征工程最佳实践;Apache Spark的机器学习及神经网络算法和应用
千锤万凿出深山:且谈机器学习特征工程最佳实践

本文将探讨 20 项特征工程的最佳实践与启发性结论,包括指标变量、交互特征、特征表达、外部数据引入、错误分析等,希望能够帮助大家顺利踏上特征工程之旅。
作为为机器学习创建新特征的实现过程,特征工程已经成为改进预测模型的最具实效的方法之一。
获取特征难度极高、相当耗时且要求具备专业知识。“应用机器学习”在本质上其实就是在实现特征工程。
—— Andrew Ng
通过特征工程方法,你将能够提取关键信息、突出数据模式并引入你的领域专长。但由于特征工程突出的开放性,极易令实施者陷入困境。
什么是特征工程?
作为一个非正式议题,特征工程可能拥有多种潜在定义。事实上,由于机器学习流程的流动性与迭代性,我们很难为特征工程找到概念层面的惟一“正确答案”。
根据自身理解,我们将特征工程定义为“基于现有的特征创建新特征,以提升模型性能的过程”。

典型的数据科学流程可能如下所示:
项目范围设定 / 数据收集
探索性分析
数据清理
特征工程
模型训练(包括交叉验证以调整超参数)
项目交付 / 获得见解
什么不是特征工程?
上述流程意味着我们会将一些步骤明确排除在特征工程范畴之外:
我们认为 初始数据收集 并不属于特征工程。
同样的,我们认为 创建目标变量 不属于特征工程。
我们认为删除重复项、处理丢失值或者修复错误标记类并不属于特征工程,我们将这些纳入 数据清理 范畴。
我们认为 特征缩放或者归一化 不属于特征工程,因为此类步骤归属于交叉验证循环(即在你已经建立起分析基表之后)。
最后,我们认为 特征选择或者主成分分析(PCA) 并不属于特征工程。这些步骤同样归属于交叉验证循环。
再次强调,这些只是我们给出的分类意见。我们接受其他数据科学家对此提出的质疑,毕竟特征工程本身就属于一个开放性概念。

免责声明到此结束,下面让我们进一步探讨与之相关的最佳实践与启发性结论。
指标变量
特征工程的第一种类型是利用指标变量提取关键信息。
现在,有些朋友可能会问,“好的算法不是应该自行学习关键信息吗?”
这个嘛,情况并非总是如此,具体取决于你所拥有的数据量以及竞争信号的强度。你可以通过预先突出重要内容帮助算法对其给予“关注”。
来自阈值的指标变量: 我们假设你正在研究美国消费者对于酒精饮料的偏好,而当前数据集包含年龄特征 age。您可以创建一个指标变量 age>=21 以区分达到合法饮酒年龄的受试者。
来自多种特征的指标变量: 假设你正在预测房地产价格,并且已经掌握了 n_bedrooms 与n_bathrooms 两项特征。如果拥有两卧两卫的房产在出租时拥有溢价性,你就可以创建一项指标变量对其进行标记。
针对特殊事件的指标变量: 假设你正在为电子商务网站的每周销售情况建模。你可以为黑色星期五与圣诞节那两周分别创建两项指标变量。
类组指标变量: 假设你正在分析网站转换率,而当前数据集包含 traffic_source 这一分类特征。你可以通过标记“Facebook 广告”或者“谷歌广告”为 paid_traffic 创建指标变量。
交互特征
第二种特征工程类型主要是指突出两项或者多项特征之间的交互。
你是否听说过“一加一大于二”这种说法?事实上,一部分特征组合起来确实能够较单一特征带来更多信息。
具体来讲,我们可以对多项特征进行加和、减差、乘积或者除商后再寻找其中的模式。
两项特征加和: 我们假设你希望根据初步销售数据预测收入情况。你已经拥有sales_blue_pens 与 sales_black_pens 两项特征。如果你只关注总体 sales_pens,那就可以将二者相加。
两项特征之差: 假设你已经拥有 house_built_date 以及 house_purchase_date 两项特征,可以求二者之差以创建 house_age_at_purchase 特征。
两项特征乘积: 假设你正在进行价格测试,而且分别拥有特征 price 与指标变量conversion。您可以将二者相乘以创建特征 earnings。
两项特征除商: 假设你拥有一套市场营销活动数据集,其中包含 n_clicks 与n_impressions 两项特征。你可以将点击次数除以展示次数以求得 click_through_rate,并借此了解不同规模的宣传活动间的转化率对比情况。
备注:我们并不建议大家利用自动化循环为全部特征创建交互,因为这有可能会造成“特征爆炸”问题。

特征表达
接下来要谈到的特征工程类型虽然简单却影响巨大。我们将其称为特征表达。
你的数据并不一定总是理想格式。你需要考虑是否有必要通过另一种形式进行特征表达以获取有用信息。
日期与时间特征: 我们假设你拥有 purchase_datetime 特征。从中提取purchase_day_of_week 与 purchase_hour_of_day 两项特征可能会更有用。你还可以进行观察聚类以创建诸如 purchases_over_last_30_days 这类特征。
数字到分类的映射: 假设你拥有 years_in_school 特征。你可以基于它创建新的 grade 特征,并分类为“小学”、“初中”和“高中”。
稀疏类分组: 假设你拥有一个包含多个类别的特征,但样本量较小。你可以尝试对相似类进行分组,将相似的类别分到一组,然后将剩下的类划分至单一的“其他”类中。
创建虚拟变量: 根据你所选取的机器学习实现方法,你可能需要手动地将各分类特征转化为虚拟变量。请务必在稀疏类分组之后再创建虚拟变量。
外部数据
特征工程中还有一个尚未被充分利用的类型,就是外部数据的引入,实际上引入外部数据能够为性能带来一些巨大突破。
举例来说,定量对冲基金的一种研究方式就是对不同财务数据流进行分层。
亦有多种机器学习难题能够通过引入外部数据得到改善。以下为相关示例:
时间序列数据: 时间序列数据的最大优势在于,你只需要一项特征——即某种形式的日期,即可将其纳入来自其他数据集的特征。
外部 API: 如今我们可以利用大量 API 来协助创建特征。例如,微软计算机视觉 API 能够返回某一图像当中包含的人脸数量。
地理编码: 如果你已经拥有street_address、city乃至state等特征信息,则可以利用 地理编码 将其转换为latitude与longitude特征。如此一来,你就能够借助 其他数据集 计算出本地人口属性(例如 median_income_within_2_miles)等特征。
同一数据的其它来源: 我们可以通过几种方式追踪 Facebook 广告宣传活动?答案可能包括 Facebook 自身的追踪系统、Google Analytics 以及其他第三方软件。每一种来源都可能带来其他方案所无法追踪到的信息。另外,这些数据集之间的任何差别都可能包含重要信息(例如不同信息来源可能对机器人流量有不同的处理方式——选择忽略或者保留)。
错误分析(建模后)
特征工程的最后一种类型,我们称之为错误分析。错误分析应该在第一套模型训练完成之后进行。
错误分析是一项广义术语,是指对模型当中的错误分类或者高错误率观察结果加以分析,同时决定如何在下一步当中作出改进。
潜在的后续步骤包括收集更多数据、对问题进行拆分或者设计出能够解决错误的新特征。要在特征工程当中使用错误分析,我们需要搞清楚自己的模型为何未能得出正确结果。
具体方式包括:
由较大错误入手: 错误分析通常手动执行。很明显,大家没有时间对每一项观察结果进行逐一检查。我们建议从那些错误评分较高的问题入手,并寻找那些能够转换为新特征的模式。
按类别分段: 另一项技术在于拆分观察结果,并针对各个分段基于平均误差进行比较。你可以尝试为误差值最高的分段创建指标变量。
无监督聚类: 如果你在发现模式时遇到问题,则可对被错误分类的观察结果执行无监督聚类算法。我们并不建议你盲目将这些聚类视为新特征,但这确实能够有效简化模式的发现过程。请记住,我们的目标是理解为何观察结果中会出现错误分类。
询问同事或者领域内专家: 这种做法可以作为以上任一项技术的补充。如果你确定效果不佳(例如通过分段方式检验),但还不清楚具体原因,那么向领域内专家求助或许能帮上大忙。
结论
如大家所见,特征工程领域存在着诸多可能性。我们在本文中提到了 20 项最佳实践与启发性结论,但这些也不过是沧海一粟。
当你开始进行自己的实验时,请牢记以下一般性准则:
良好的特征工程应当……
可面向未来观察结果进行计算。
通常能给出直观的解释。
通过领域内专业知识或者探索性分析得出。
必须拥有预测能力。不要为了创建特征而创建特征。
切勿触及目标变量。 这对于初学者们来说是一个经常会不小心掉入的陷阱。无论你是在创建指标变量抑或是交互特征,都千万不要使用自己的目标变量。这就像是一种“欺骗”,会给大家带来极具误导性的结果。
最后,如果感觉上述内容太难,也不用过于担心。通过不断实践和积累经验,你一定会对特征工程越来越熟悉并得到更理想的结果。
机器学习实际应用中必须考虑到的9个问题
张皓 AI科技大本营

如今,机器学习变得十分诱人,它已在网页搜索、商品推荐、垃圾邮件检测、语音识别、图像识别以及自然语言处理等诸多领域发挥重要作用。和以往我们显式地通过编程告诉计算机如何进行计算不同,机器学习是一种数据驱动方法(data-driven approach)。然而,有时候机器学习像是一种"魔术",即使是给定相同的数据,一位机器学习领域专家和一位新手训练得到的结果可能相去甚远。
本文简要讨论了实际应用机器学习时九个需要注意的重要方面。
作者 | 张皓
整理 | AI科技大本营(微信ID:rgznai100)
我该选什么学习算法?
这可能是你面对一个具体应用场景想到的第一个问题。
你可能会想"机器学习里面这么多算法,究竟哪个算法最好"。很"不幸"的是,没有免费午餐定理(No Free LunchTheorem)告诉我们对于任意两个学习算法,如果其中一个在某些问题上比另一个好,那么一定存在一些问题另一个学习算法(表现会)更好。因此如果考虑所有可能问题,所有算法都一样好。
"好吧",你可能会接着想, "没有免费午餐定理假定所有问题都有相同机会发生,但我只关心对我现在面对的问题,哪个算法更好"。又很"不幸"的是,有可能你把机器学习里面所谓"十大算法"都试了一遍,然后感觉机器学习"这东西根本没用,这些算法我都试了,没一个效果好的"。前一段时间"约战比武"的话题很热,其实机器学习和练武术有点像,把太极二十四式朝对方打一遍结果对方应声倒下这是不可能的。
机器学习算法是有限的,而现实应用问题是无限的,以有限的套路应对无限的变化,一定是会存在有的问题你无法用现有的算法解决的,岂有不败之理?
因此,该选什么学习算法要和你要解决的具体问题相结合。不同的学习算法有不同的归纳偏好(inductive bias),你使用的算法的归纳偏好是否适应要解决的具体问题直接决定了学得模型的性能,有时你可能需要改造现有算法以应对你要解决的现实问题。
我该选什么目标函数?
目标函数用于刻画什么样的模型是好的,和选择学习算法一样,选什么目标函数也要和具体问题相结合。大部分的教材和文献重点在呈现算法,对目标函数和优化方法的选择通常使用缺省值。以分类问题为例,我们缺省地优化分类均等代价(cost)下的错误率。但是在你所要解决的问题中,问问自己这些问题:
l 你真正关心的是错误率吗(比如还有查准率(precision),查全率(recall)等其他指标)?
l 数据中有没有类别不平衡(class-imbalance)的现象(比如信用卡欺诈检测中,欺诈用户数远小于正常用户数)?
l 不同类型错误所造成的损失是一样的吗(比如医疗诊断中,错误地把患者诊断为健康人与错误地把健康人诊断为患者的代价截然不同)?
l 还有没有其他类型的代价(除了误分类代价外,还有测试代价,标记代价,特征(feature)代价等)?
除此之外还有其他的一些问题。这些问题存不存在,要不要考虑,该怎么考虑都是和你要处理的实际问题有关,最终体现在你的目标函数之中。
我该选什么优化方法?
“我是谁?我从哪里来?我往哪里去?”是哲学里避不开的三个问题,而“选什么算法?选什么目标函数? 选什么优化方法?”是机器学习里经常遇到的三个问题,这三者的组合就构成了一个机器学习解决方案基本框架。通常,我们使用现有的数值优化方法对目标函数进行优化,比如梯度下降(gradient descent),牛顿法等。
但是当目标函数非凸(non-convex),有多个局部极小(local minima)时,选什么优化方法会对结果产生直接影响。比如深度学习中通常目标函数有多个局部极小,使用不同的参数初始化方法(如高斯(Gaussian)随机初始化,Xavier 初始化, MSRA 初始化等),不同的优化方法(如SGD,带动量(momentum)的SGD, RMSProp, ADAM 等),或不同的学习率(learning rate)策略等,都会对结果有很大影响。
另一方面,即使目标函数是凸函数,设计合适的优化方法可能会使你的训练过程有质的飞跃。比如SVM 的优化是一个二次规划(quadratic programming)问题,可以通过调用现成的QP 软件包进行优化。然而,这个二次规划问题的大小和训练样本数成线性关系,当数据量很大时将导致巨大的开销。为了避开这个障碍,人们根据SVM 的特点设计出了SMO (sequential minimaloptimization)这样的高效优化方法。
不要偷看测试数据
我们希望学习器能从训练数据中尽可能学出适用于所有潜在样本(sample)的普遍规律,从而能很好的泛化(generalize)到新样本。为了评估模型的泛化能力,我们通常收集一部分数据作为测试集(testing set)计算测试误差用以作为泛化误差的近似。为了能得到较准的近似,我们不能在训练阶段以任何方式偷看测试数据。
一个常见错误做法是用测试数据调模型的参数。这相当于老师在考试前向学生透露考试原题,这虽然可能会使学生在这次考试中拿到高分,但这不能有效反应学生是否对这门课学的很好,获得了对所学知识举一反三的能力,得到的将是过于乐观的估计结果。调参的正确做法是从训练数据中再划分出一部分作为验证集(validation set),用训练集(training set)剩下的数据做训练,用验证集调参。
另一个常见错误是用测试数据参加训练数据预处理(data pre-processing)。通常,数据在输入给模型之前会经过一些预处理,比如减去各维的均值,除以各维的方差等。如果这个均值和方差是由训练集和测试集数据一起计算得到的,这相当于间接偷看了测试数据。
这相当于老师在考前向学生划重点,虽然比直接透露原题好一些,由于学生知道了考试范围(即测试数据分布),也会使我们得到过于乐观的估计。正确做法是只从训练数据中计算预处理所用的统计量,将这个量应用于测试集。
欠拟合/过拟合: 认准你的敌人
欠拟合(underfitting)通常是由于学习器的学习能力不足,过拟合(overfitting)通常是由于学习能力过于强大。两者都会影响模型的泛化能力,但是解决这两个问题的方法迥然不同。解决欠拟合可以通过使用更复杂的模型,增加训练轮数等。缓解过拟合可以通过使用简单模型,正则化(regularization),训练早停(early-stopping)等。欠拟合比较容易解决,而过拟合是无法彻底避免的,我们只能缓和,减小其风险。因此,问题的关键在于认准你当前的敌人是欠拟合还是过拟合。
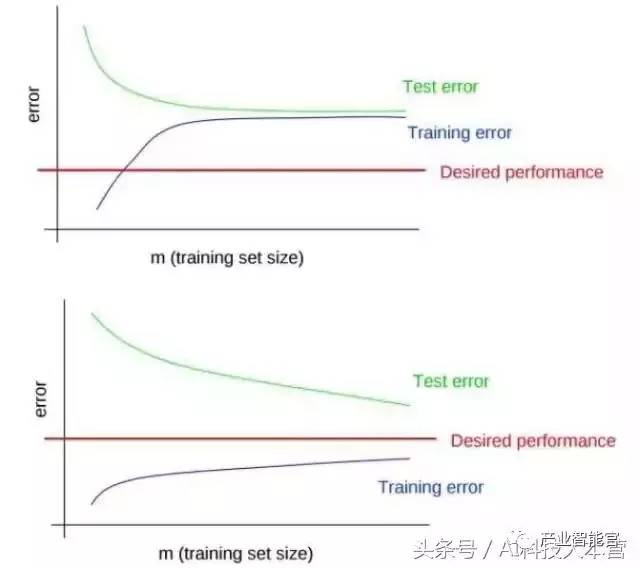
判断欠拟合或过拟合最简单直接的方法是画出学习曲线(learning curve)。过拟合的表现是: 训练误差很低(甚至为0),而测试误差很高,两者有很大的差距。而欠拟合的表现是: 训练误差和测试误差很接近,但都很高,下图是两个例子,你能看出来哪个处于过拟合,哪个处于欠拟合吗?
机器智能+人类智能
经过前面这几部分你可能已经意识到了,机器学习不是把数据扔给机器然后自己可以撒手不管。机器学习不是"空手套白狼",如果我们对问题/数据认识的越深刻,我们越容易找到归纳假设与之匹配的学习算法,学习算法也越容易学到数据背后的潜在规律。
数据中特征的好坏直接影响学习算法的性能。如果数据之间相互独立并且与数据的标记有很好的相关性,学习过程将相对容易。但很多情况下,你手中数据的原始特征并没有这么好的性质,特征和标记之间是一个非常复杂的映射关系。这时候机器智能需要人类智能的配合,我们需要从原始数据中构造合适的特征。这个过程叫做特征工程(featureengineering),这通常需要领域知识和你对这个问题的认识。
你可能会想"既然机器学习可以学到从数据的表示到标记的映射,那么我们能不能让机器自动地从数据的原始特征中学习到合适的表示呢",表示学习(representation learning)就专门研究这方面的内容。
深度学习的最大优点就在于其表示学习能力,通过很多层的堆叠,深度神经网络可以对输入数据进行逐层加工,从而把初始的,与输出目标关系不密切的表示转化为与输出目标关系密切的表示。这样将低层表示转化为高层表示后,用"简单模型"即可完成复杂的学习任务。因此,深度学习才能在计算机视觉,自然语言处理,语音识别这样数据的原始表示和数据的合适表示相差很大的任务上大放异彩。
高维"灾难"
经过上一节你可能会想“既然特征工程这么重要,那我就把想到的所有的特征组合都作为数据的特征不就好了吗”。这么做的结果会使特征维数增加,一方面会增加存储和计算开销,更重要的是,它会招来机器学习担忧的另一头猛兽: 维数灾难(curse ofdimensionality)。
由于你能拿到手中的训练数据是有限的,当维数增加时,输入空间(input space)的大小随维数指数级增加,训练数据占整个数据空间的比例将急剧下降,这将导致模型的泛化变得更困难。在高维空间中,样本数据将变得十分稀疏,许多的相似性度量在高维都会失效。
比如下图中,最左边的是原图,右边三张图看上去差别很大,但和原图都有着相同的欧氏距离。
解决维数灾难的一个重要途径是降维(dimension reduction),即通过一些手段将原始高维空间数据转变为一个低维子空间,在这个子空间中样本密度大幅提高,距离计算也更容易。特征选择(feature selection)和低维投影(如PCA)是用来处理高维数据的两大主流技术。
数据!数据!
看了前面各部分的讨论可能你已经有点受不了了:“机器学习没有通式通法,要根据任务具体情况具体分析;要小心翼翼,不能偷看测试数据,要设法避免过拟合和欠拟合;特征工程很重要,但是特征又不能太多...哦天呐!这太麻烦了! 有没有什么能提升性能直截了当的方法啊!”。有!那就是收集更多的数据。通常情况下,你有很多的数据,但是学习算法一般和你设计出了很好的学习算法但手中数据不足相比,前者效果会更好。这是因为收集更多的数据是缓解过拟合最直接有效的方法。
收集更多的数据通常有下面两种办法:一种方法是收集更多的真实数据,这是最直接有效的方法。但有时收集数据很昂贵,或者我们拿到的是第二手数据,数据就这么多。这就需要另一个方法:从现有数据中生成更多数据,用生成的"伪造"数据当作更多的真实数据进行训练。这个过程叫做数据扩充(data augmentation)。以图像数据做分类任务为例,把图像水平翻转,移动一定位置,旋转一定角度,或做一点色彩变化等,这些操作通常都不会影响这幅图像对应的标记。并且你可以尝试这些操作的组合,理论上讲,你可以通过这些组合得到无穷多的训练样本。
在收集/生成数据过程中一个要注意的关键问题是:确保你的数据服从同一分布。这比如说老师教了学生一学期的英语结果期末考试却是考俄语,虽然英语和俄语在语言学上有一定的相似性,但是这给学习过程增加了很多困难。迁移学习(transfer learning)旨在研究数据分布变化情况下的学习算法的泛化能力,但如果你的目的不是做迁移学习方面的科学研究,建议你确保你的训练和测试数据服从同一分布,这会使问题简单许多。
集成学习:以柔克刚
面对大多数的任务,集成学习应当是你的必备招式。集成学习的目的在于结合多个弱学习器的优点构成一个强学习器,“三个臭皮匠,顶个诸葛亮”讲的就是这个道理。在各种机器学习/数据挖掘竞赛中,那些取得冠军的队伍通常会使用集成学习,有的甚至用成百上千个个体学习器来做集成。通常我们面对一个实际问题时会训练得到多个学习器,然后使用模型选择(model selection)方法来选择一个最优的学习器。而集成学习则相当于把这些学习器都利用起来,因此,集成学习的实际计算开销并不比使用单一学习器大很多。
目前的集成学习方法大致可以分为两大类:
以Boosting 为代表的集成学习方法中每个个体学习器相互有强依赖关系,必须序列化生成;
以Bagging 为代表的集成学习方法中每个个体学习器不存在强依赖关系,可以并行化生成。
而从偏差-方差分解(bias-variancedecomposition)的角度看, Boosting 主要关注降低偏差,而Bagging 主要关注降低方差。欠拟合/过拟合这两个敌人是不是又一次出现在你眼前了呢?
参考文献
[1]. Domingos, Pedro. "A few useful things to know about machine learning."
Communications of the ACM 55.10 (2012): 78-87.
[2]. Glorot, Xavier, and Yoshua Bengio. "Understanding the difficulty of training
deep feedforward neural networks." Aistats. Vol. 9. 2010.
[3]. He, Kaiming, et al. "Delving deep into rectifiers: Surpassing human-level
performance on imagenet classification." Proceedings of the IEEE international
conference on computer vision. 2015.
[4]. Kingma, Diederik, and Jimmy Ba. "Adam: A method for stochastic
optimization." arXiv preprint arXiv:1412.6980 (2014).
[5]. Li, Fei-Fei, Andrej Karpathy, and Justin Johnson. CS231n: Convolutional
Neural Networks for Visual Recognition. Stanford. 2016.
[6]. Lin, Hsuan-Tien. Machine Learning Foundations. National Taiwan University.
[7]. Lin, Hsuan-Tien. Machine Learning Techniques. National Taiwan University.
[8]. Murphy, Kevin P. Machine learning: a probabilistic perspective. MIT press,
2012.
[9]. Ng, Andrew. Machine learning yearning. Draft, 2016.
[10]. Ng, Andrew. CS229: Machine Learning. Stanford.
[11]. Platt, John. "Sequential minimal optimization: A fast algorithm for training
support vector machines." (1998).
[12]. Tieleman, Tijmen, and Geoffrey Hinton. "Lecture 6.5-rmsprop: Divide the
gradient by a running average of its recent magnitude." COURSERA: Neural
networks for machine learning 4.2 (2012).
[13]. Wei, Xiu-Shen. Must Know Tips/Tricks in Deep Neural Networks.
http://lamda.nju.edu.cn/weixs/project/CNNTricks/CNNTricks.html.
[14]. Wolpert, David H. "The lack of a priori distinctions between learning
algorithms." Neural computation 8.7 (1996): 1341-1390.
[15]. Wolpert, David H., and William G. Macready. No free lunch theorems for
search. Vol. 10. Technical Report SFI-TR-95-02-010, Santa Fe Institute, 1995.
[16]. Zhou, Zhi-Hua. Ensemble methods: foundations and algorithms. CRC
press, 2012.
[17]. Zhou, Zhi-Hua. "Learnware: on the future of machine learning." Frontiers
of Computer Science 10.4 (2016): 589-590.
[18]. 周志华著. 机器学习, 北京: 清华大学出版社, 2016 年1 月.
作者github地址
https://github.com/HaoMood/
基于Apache Spark的机器学习及神经网络算法和应用
中国大数据
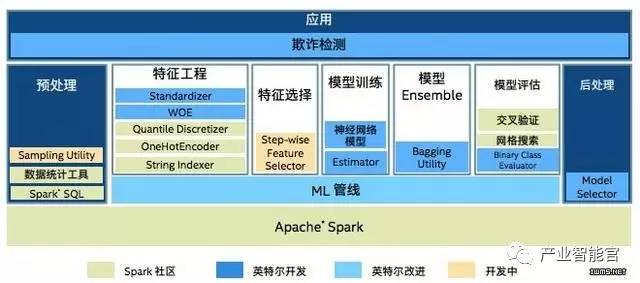
使用高级分析算法(如大规模机器学习、图形分析和统计建模等)来发现和探索数据是当前流行的思路,在IDF16技术课堂上,英特尔公司软件开发工程师王以恒分享了《基于Apache Spark的机器学习及神经网络算法和应用》的课程,介绍了大规模分布式机器学习在欺诈检测、用户行为预测(稀疏逻辑回归)中的实际应用,以及英特尔在LDA、Word2Vec、CNN、稀疏KMeans和参数服务器等方面的一些支持或优化工作。
当前的机器学习/深度学习库很多,用Spark支撑分布式机器学习和深度神经网络,主要是基于两点考虑:
大数据平台的统一性。因为随着Spark特性,分析团队越来越喜欢用Spark作为大数据平台,而机器学习/深度学习也离不开大数据。
其他的一些框架(主要是深度学习框架,如Caffe)对多机并行支持不好。
在某顶级支付公司的端到端大数据解决方案中,英特尔开发的Standardizer、WOE、神经网络模型、Estimator、Bagging Utility等都被应用,并且ML管线也由英特尔改进。
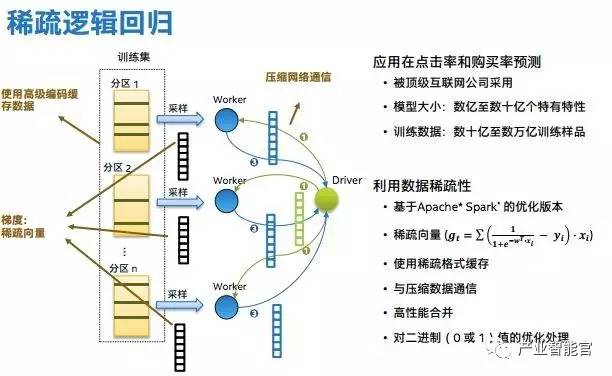
稀疏逻辑回归主要解决了网络和内存瓶颈的问题,因为大规模学习,每次迭代广播至每个Worker的的权重和每个任务发送的梯度都是双精度向量,非常巨大。英特尔利用数据稀疏性,使用高级编码缓存数据(使用稀疏格式缓存),压缩数据通信,并对二进制值优化处理,最后得到的梯度是稀疏向量。
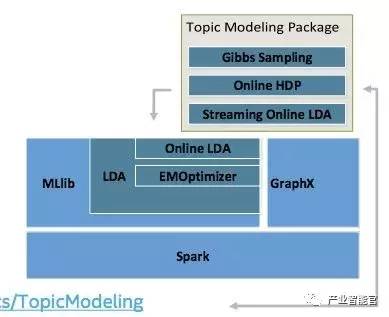
基于Apache Spark的大规模主题模型正在开发中(https://github.com/intel-analytics/TopicModeling)。
Spark上的分布式神经网络,Driver广播权重和偏差到每个Worker,这与稀疏逻辑回归有类似之处,英特尔将神经网络与经过优化的英特尔数学核心函数库(支持英特尔架构加速)集成。
面向Spark的参数服务器的工作,包括数据模型、支持的操作、同步模型、容错、集成GraphX等,通过可变参数作为系统上的补充,实现更好的性能和容错性,相当于将两个架构仅仅做系统整合(Yarn之上)。由于模型并行的复杂性,英特尔团队目前也还没有考虑模型并行的工作。

《哈佛商业评论》:人工智能商业之路的现状、潜力、风险与局限
250多年来,经济增长的根本动力一直是技术创新。其中最重要的是经济学家所谓的通用技术——包括蒸汽机、电力和内燃机。每一个都催化了互补创新和机遇的浪潮。例如,内燃机汽车、卡车、飞机、链锯和割草机,以及大型零售商、购物中心、交叉码头仓库、新供应链等。像沃尔玛Walmart、UPS和Uber等公司都找到了利用技术来创造可赢利的新业务模式的方法。
我们这个时代最重要的通用技术是人工智能(AI),尤其是机器学习(ML)——也就是说,机器有能力不断提高性能,而无需人工解释如何完成它所提供的所有任务。在过去的几年里,机器学习变得更加有效和广泛。我们现在可以构建学习如何自己执行任务的系统。
为什么这是一件大事呢?有两个原因。
首先,人类知晓的事物比我们能表述出来的要多得多:我们无法确切地解释我们如何能够做很多事情。在应用机器学习的方法之前,由于这方面的缺陷意味着我们无法使很多任务自动化。现在我们可以了。
其次,机器学习系统通常是优秀的学习者。他们可以在广泛的活动中实现超人的表现,包括检测欺诈和诊断疾病。这类优秀的数字学习者正在被部署到整个经济中,他们的影响将是深远的。
在商业领域,AI将对早期通用技术的规模产生革命性的影响。尽管它已经在世界各地数千家公司中使用,但还有大量的机会还在等待被发掘。随着制造业、零售业、交通、金融、医疗、法律、广告、保险、娱乐、教育、以及几乎所有其他行业都正在利用机器学习技术来转变其核心流程和商业模式,AI的影响将在未来十年被放大。现在的瓶颈在于管理、实施和业务畅象。
然而,与其他许多新技术一样,人们对AI也产生了许多不切实际的期望。我们看到很多创业公司的BP中开始加入很多关于机器学习、神经网络和其他形式的技术,虽然这和实际功能没有什么联系。例如,把一个约会网站包装成AI在背后支持的并不会让它变得更有效,但在融资上却可能会有很大帮助。本文希望抛开围绕在AI周围的噪声,来向大家展示AI的真正潜力、它的实际意义,以及AI实际应用中的障碍。
今天AI可以做什么?
AI这个词是在1955年由达特茅斯大学的数学教授John McCarthy提出的,他在次年组织了这个主题的开创性会议。从那以后,或许是由于这个令人回味名字的原因,这个领域的发展远远超过了人们的想象。1957年,经济学家 Herbert Simon 预言计算机将在10年内击败人类(实际上花了40年)。1967年,认知科学家Marvin Minsky说,“在一代人的时间内,人工智能的问题将得到极大的解决。” Simon和Minsky都是智力巨人,但显然他们都错了。
我们先来看看AI已经在做什么,以及这个领域的进展有多快。最大的进展来自于两大领域:感知(perception)和认知(cognition)。在前一类中,最前沿的进展大部分是和语音相关的。语音识别还没有达到完美,但现在有数百万人已经在使用它们了——想想Siri、Alexa和Google Assistant。你现在正在阅读的这篇文章最初是由我们口述给计算机的,已经比我们自己打字更快了。斯坦福大学计算机科学家James Landay和他的同事进行的一项研究发现,语音识别的速度大约是手机上打字速度的三倍。语音识别的错误率已经从过去的8.5%,下降到4.9%了。令人惊讶的是,这种实质性的进步并非在过去10年,而是从2016年夏天开始。
图像识别领域的进展也让人惊叹。你可能已经注意到,Facebook和其他app现在已经能从你上传的图片中识别出你的朋友,并提示你用他们的名字来标记他们。在你的智能手机上运行的app可以识别任何野生鸟类。图像识别甚至取代了公司门禁卡。自动驾驶汽车中所使用的视觉系统,在识别一个行人的时候,通常会在30帧中出现一次错误(在这些系统中,相机记录大约每秒30帧);而现在,它们的错误频率要少于1千万帧。ImageNet这个大型数据库中识别图像的错误率,已经从2010年的30%下降到了2016年的4%。
近年来,随着大规模深度神经网络的使用,AI领域的进展日新月异。当然,目前基于机器学习的视觉系统还远远没有完美无缺——但即使是人也不是无所不能的嘛。
AI领域第二类的主要进步是集中在认知和问题解决方向。机器已经打败了最优秀的(人类)扑克玩家和围棋选手——虽然原来专家们预测至少还要再过十年。谷歌的DeepMind团队使用了机器学习系统来提高数据中心的冷却效率提升了15%。像Paypal这样注重网络安全的公司也正在用AI来检测恶意软件。由IBM技术支撑的系统使得新加坡一家保险公司的索赔过程进入了自动化。数十家公司正在使用机器学习来帮助进行金融交易决策,而且越来越多的信贷决定是在AI帮助下做出的。亚马逊采用机器学习来优化库存,并提升给客户的产品推荐。Infinite Analytics公司开发了一个机器学习系统来预测用户是否会点击某个特定的广告,为一家全球消费包装产品公司的在线广告位置进行了优化。另一个开发的系统帮助巴西的一家在线零售商改进客户的搜索和发现过程。第一个系统将广告的ROI提升了三倍,而第二个系统使得年收入增加了1.25亿美元。
机器学习系统不仅在许多应用中取代了旧有的算法,而且在许多曾经被人类做得最好的任务上也占尽先机。尽管这些系统并不完美,但它们的错误率已经表现比人类更好了。语音识别,即使在嘈杂的环境中,现在也几乎等同于人类的表现。这为改变人们的工作和经济带来了巨大的新可能性。一旦基于AI的系统在给定的任务中超过人类的表现,它们就更有可能迅速传播。例如,Aptonomy和Sanbot,这两家分别是无人机和机器人的制造商,他们正在使用改进的视觉系统来自动化大部分保安人员的工作。软件公司Affectiva使用它们来识别诸如快乐、惊讶和焦点小组的愤怒等情绪。Enlitic是几家利用AI来识别医疗影像,进而帮助诊断癌症的深度学习的初创公司之一。
这些成果都令人印象深刻,但是基于AI的系统的适用性仍然相当狭窄。例如,既然AI在拥有数百万图片的ImageNet数据库上表现出色,也并不总能在现实环境中取得同样的成功。因为在现实世界里,光线条件、角度、图像分辨率和背景可能会非常不同。更重要的是,如果人类完成了一项任务,我们会很自然地假设此人在相关任务中具有一定的能力。但是,机器学习系统是被训练来完成特定的任务,因此通常他们的知识不会泛化。我们离那些能在不同领域展现通用智力的机器还非常遥远。
理解机器学习
要理解机器学习,最重要的一点是它代表了一种从根本上与以往不同的创建软件的方法:机器从示例中学习,而不是明确地为特定的结果编程。这是一个重大突破。在过去50年的大部分时间里,信息技术的进步和它的应用都集中在编纂现有的知识和程序,并将它们嵌入到机器中。实际上,术语“coding”表示将知识从开发人员的头脑中转移到机器能够理解和执行的形式的艰苦过程。这种方法有一个根本的问题:我们所有的知识都是隐性的,这意味着我们无法完全解释它。我们几乎不可能写出能让另一个人学会骑自行车或认出朋友脸的指令。
换句话说,我们知道的比我们能讲出来的东西要多。这个事实非常重要,它被称为:Polanyi悖论。Polanyi悖论不仅限制了我们能告诉别人的东西,而且对我们赋予机器智能的能力是一个根本性的限制。很长一段时间,这限制了机器在经济中能够有效发挥作用的活动。
机器学习正在克服这些限制。在第二个机器时代的第二次浪潮中,由人类制造的机器正在从例子中学习,并利用结构化的反馈来解决他们自己的问题,如Polanyi经典的识别人脸的问题。
机器学习的不同风格
人工智能和机器学习有许多种方式,但近年来的大多数成功都是在一个类别:监督学习系统。在这里,机器被给予了很多正确答案的例子。这个过程几乎总是涉及从一组输入X,到一组输出Y的映射。例如,输入可能是各种动物的图片,正确的输出可能是这些动物的标签:狗,猫,马。输入也可以是声音录音的波形,输出可以是文字:“是的”,“不”,“你好”,“再见”。
成功的系统通常使用一组数据的训练集,有成千上万甚至上百万个例子,每一个都被贴上正确的答案。然后,可以放任系统去看新的示例。如果训练进行得很好,系统将会以很高的准确度来预测答案。
推动这种成功的算法依赖于一种叫做深度学习的方法,这种方法使用神经网络。深度学习算法比早期的机器学习算法有很大的优势:它们可以更好地利用更大的数据集。随着训练数据中的示例数量的增加,旧系统将会得到改进,但这只是在一定程度上,在此之后,额外的数据不会带来更好的预测。根据AI巨头之一的Andrew Ng,深度神经网络似乎并没有达到这样的水平:更多的数据会带来更好的预测。一些非常大的系统通过使用3600万个例子或更多。当然,处理非常大的数据集需要越来越多的处理能力,这是非常大的系统经常在超级计算机或专门的计算机架构上运行的原因之一。
不论你是在何种场景下拥有很多关于行为的数据并试图预测结果,都有可能用到监督学习系统。亚马逊负责消费者业务的Jeff Wilke说,监督学习系统基本上取代了用于向客户提供个性化推荐的基于记忆的过滤算法。在其他情况下,建立库存水平和优化供应链的经典算法已经被基于机器学习的更高效和健壮的系统所取代。摩根大通推出了一套审查商业贷款合同的系统,过去以贷款计36万小时的工作现在可以在几秒钟内完成。监督学习系统现在被用于诊断皮肤癌。这些只是一些例子。
给一个数据体贴上标签,用它来训练一个受监督的学习者是相当简单的;这就是为什么监督的机器学习系统比没有监督的系统更常见,至少现在是这样。无人监督的学习系统寻求独立学习。我们人类是优秀的没有监督的学习者:我们掌握了我们对世界的大部分知识(例如如何认识一棵树),很少或没有标记的数据。但是要开发一个成功的机器学习系统是非常困难的。
如果我们有朝一日建立了稳健的无人监督学习机器,将会打开一扇新世界的大门。这些机器可以用新的方式来研究复杂的问题,以帮助我们在自己还没意识到之前,就发现了其中的传播模式,比如疾病的传播,市场上的证券价格变动,顾客的购买行为等。为此,Facebook的人工智能研究主管、纽约大学教授Yann LeCun将监督学习系统生动的比作蛋糕上的糖霜,无监督学习则是蛋糕本身。
在这个领域内另一个小众但发展快速的领域是强化学习(reinforcement learning)。这种方法嵌入到已经掌握了Atari技能的视频游戏和棋类游戏的系统中。它还有助于优化数据中心的电力使用情况,并为股票市场制定交易策略。Kindred使用机器创建的机器人能够识别和分类他们从未遇到过的对象,加快了在配送中心对消费品进行“挑选和放置”的过程。
在强化学习系统中,程序员指定系统的当前状态和目标,列出允许的操作,并描述约束每个动作的结果的环境元素。使用允许的操作,系统必须弄清楚如何尽可能接近目标。当人类能够明确目标但却不知道如何达到目标时,这些系统就能正常工作。例如,微软利用强化学习,通过“奖励”这个系统来为MSN.com的新闻故事选择标题,当更多的访问者点击链接时,这个系统会得到更高的分数。该系统试图根据设计者给出的规则来最大化其分数。当然,这意味着一个强化学习系统将对你明确奖励的目标进行优化,但这也有可能并不是你真正关心的目标(如终身客户价值),因此正确明确目标和明确的目标是至关重要的。
让机器学习工作起来
对于希望将机器学习尽快应用起来的公司来说,有三个好消息。首先,人工智能技术正在迅速蔓延。世界上仍然没有足够的数据科学家和机器学习专家,但是对他们的需求正在被在线教育资源和大学所满足。其中最好的,包括Udacity、Coursera和fast.ai。人工智能已经不仅仅是一个书上的概念,已经可以让聪明的、有潜力的学生们达到能够创建工业级的机器学习算法部署的目的。除了培训自己的员工之外,感兴趣的公司还可以使用在线人才平台,如Upwork、Topcoder和Kaggle,来寻找具有可验证的专业知识的机器学习专家。
第二个可喜的发展是,现代人工智能的必要算法和硬件可以根据需要购买或租用。谷歌、亚马逊、微软、Salesforce和其他公司正在通过云计算提供强大的机器学习基础设施。这些竞争对手之间的激烈竞争意味着,那些想尝试或部署机器学习算法的公司将会看到越来越多的功能随着时间的推移而不断降价。
最后一个甚至仍有可能被低估的好消息是,有效使用机器学习算法所需要的数据可能没有你想象的那么多。大多数机器学习系统的性能提高,因为它们有更多的数据。所以拥有的数据越多,胜出的可能越大,这在逻辑上是行得通的。如果“赢”的意思是“在全球市场上主导某一应用领域,例如广告定位或语音识别”,那确实没毛病。但如果将“成功”定义为显著提高性能,那么获得足够的数据其实是非常容易的。
例如,Udacity联合创始人Sebastian Thrun注意到,他的一些销售人员在回答聊天室的入站问题时,比其他人更有效。Thrun和他的研究生Zayd Enam意识到他们的聊天室日志实际上是一组标记的训练数据——这正是监督学习系统需要的。导致销售的交互作用被标记为成功,所有其他的都被标记为失败。Zayd利用这些数据来预测成功销售人员在回答一些非常常见的问题时可能给出的答案,然后与其他销售人员分享这些预测,以推动他们更好的表现。经过1000次的培训,销售人员的工作效率提高了54%,并且一次能服务两倍的顾客。
AI初创公司WorkFusion采用了类似的方法。它与其他公司合作,将更高的自动化水平引入后台流程,例如支付国际发票和在金融机构之间进行大型交易。这些过程还没有自动化的原因是它们很复杂,相关的信息并不总是每次都以同样的方式呈现——我们怎么知道他们在说什么货币,并且有必要进行一些解释和判断。WorkFusion的软件在人们工作时观察他们的一举一动,并将其作为训练数据用于分类的认知任务:“这张发票是美元的,这个是日元。这是欧元……一旦系统对其分类有足够的信心,它就会接管整个过程。
机器学习在三个层次上驱动变化:工作任务和职位、业务流程和业务模型。工作和职业被重塑的一个例子是使用机器视觉系统来识别潜在的癌症细胞——释放放射科医生以专注于真正的关键病例,与病人沟通,和与其他医生协调。影响业务流程的一个例子是,在引入机器人和基于机器学习的优化算法之后,重新设计了Amazon实现中心的工作流和布局。类似地,业务模型需要再优化,以利用可以智能化地推荐音乐或电影的机器学习系统。与其在消费者选择的基础上销售歌曲,一个更好的模式可能会为一个个性化的电台提供订阅服务,这样可以预测并播放特定顾客喜欢的音乐,即使这个人以前从未听过。
但要注意的是,机器学习系统是无法完全代替这个职位、流程或业务模型的。大多数情况下,它们是对人类活动的补充,使他们的工作变得更有价值。对于新的劳动分工来说,最有效的规则很少是“把所有的任务交给机器”。相反,如果一个过程的成功完成需要10个步骤,其中一个或两个步骤可能会自动完成,而其余的则会变得更有价值。例如,Udacity的聊天室销售支持系统并没有试图构建一个能够接管所有对话的机器人;相反,它向销售人员提供了如何提高性能的建议。人类仍在掌控中,但变得更加有效和高效。这种方法通常比设计能够完成人类所有操作的机器更可行。它通常会带来更好的、更令人满意的工作,最终为客户带来更好的体验。
设计和实施新的技术、人类技能和资本资产组合,以满足客户的需求需要大规模的创意和计划。这就是一个机器不擅长的任务。这就使得企业家或商务经理成为了社会最具回报价值的工作之一。
风险和局限
第二个机器时代的第二波浪潮带来了新的风险。特别是,机器学习系统通常具有较低的“可解释性”,这意味着人类很难弄清楚系统是如何做出决定的。深层神经网络可能有几亿的连接,每一个都贡献了一点点的最终决定。因此,这些系统的预测往往会抵制简单而清晰的解释。与人类不同,机器还不是很好的故事讲述者。他们不能总是给出一个理由,说明为什么某个特定的申请人被录用或被拒绝了,或者推荐了一种特殊的药物。具有讽刺意味的是,即使我们已经开始克服Polanyi的悖论,我们也面临着另一个版本:机器知道的比它们能告诉我们的更多。
这将带来三个风险。首先,机器可能有隐藏的偏见,不是来自设计者的任何意图,而是来自提供给系统的数据。举个例子,如果一个系统了解到哪些求职者在面试中使用了过去招聘人员所做的一系列决定来接受面试,那么它可能会无意中学会将他们的种族、性别、种族或其他偏见延续下去。此外,这些偏差可能不会作为一个明确的规则出现,而是被考虑到成千上万个因素之间的微妙交互中。
第二个风险是,与传统的基于显式逻辑规则的系统不同,神经网络系统处理的是统计学上的真理,而不是真实的事实。这可能会使证明系统在所有情况下,尤其是在没有在培训数据中表示的情况下工作很难,甚至不可能。缺乏可验证性对于任务型的应用场景是一个问题,例如控制核电站,或者涉及生死抉择。
第三,当机器学习系统确实出现错误时,几乎不可避免地会出现错误诊断和纠正错误。导致解决方案的底层结构可能是难以想象的复杂,如果系统被培训的条件发生变化,那么解决方案可能会远远不够理想。
尽管所有这些风险都是真实的,但适当的标 准不是为了定义完美,而是最好的选择。毕竟,我们人类也有偏见、犯错误,并且很难如实解释我们是如何做出一个特定的决定的。基于机器的系统的优点是,它们可以随着时间的推移得到改进,并在提供相同数据时给出一致的答案。
这是否意味着人工智能和机器学习能做到一切事情?感知和认知涵盖了大量的领域——从驾驶汽车到预测销售,再到决定雇佣谁或提拔谁。我们相信,人工智能在大多数或所有领域的性能将很快达到超人水平。那么什么是AI和ML做不到的呢?
我们有时会听到“人工智能永远不会擅长评估感性、狡诈、善变的人类,它太死板、太没人情味了”等类似的抱怨。但我们不以为然。像Affectiva这样的机器学习系统,在以声音或面部表情为基础来辨别一个人的情绪状态时,已经达到或超越了人类的表现。其他系统可以推断出,即使是世界上最好的扑克玩家也能在令人惊讶的复杂游戏中击败他们。准确地阅读人们是一件很微妙的工作,但这不是魔法。它需要感知和认知——确切地说,现在的机器学习是强大的,并且一直变得更强大。
讨论人工智能的极限可以从毕加索对计算机的观察出发:“但它们是无用的,只能给你答案。”它们当然不是一无是处,正如机器学习最近的胜利所彰显的那样,但毕加索的观察仍然提供了参考。电脑是用来回答问题的装置,而不是用来造问题的。这意味着企业家、创业者、科学家、创造者和更多的人,他们都要想,下一步要解决的问题是什么,或者有什么新领域要探索,这将是至关重要的。
同样,被动地评估一个人的精神状态和积极努力去改变它,两者之间有着巨大的差异。机器学习系统在前者上表现惊人,但后者要想赶超人类需要进步的空间还很大。我们人类是一个非常社会化的物种,我们不是机器,最擅长利用诸如同情、自豪感、团结和羞耻等社会驱动力来说服、激励和感染彼此。2014年,TED大会和XPrize基金会宣布设置一个奖项以期待,“第一个人工智能来到这个舞台,给一段同样富有感染力的TED演讲,让观众起立为其鼓掌”。估计这个奖项很快就要被捧回家了。
我们认为,在这个超级强大的人工智能的新时代里,人类智慧的最大和最重要的机遇在于两个领域的交叉点:找出下一步要解决的问题,并说服许多人去解决问题,并广泛应用。这是对领导力的一个很好的定义,在第二个机器时代,领导力变得更加重要。
在头脑和机器之间划分工作的现状很快就会瓦解。与那些愿意并且能够把机器学习放在适当的地方,并能找出如何有效地将其功能与人类的能力集成起来的竞争对手相比,故步自封的公司将很快发现自己会出去前所未有的劣势和被动中。
商业世界的构造变革时代已经开始,由技术进步带来。就像蒸汽动力和电力一样,它本身也无法获得新技术,甚至无法进入顶尖技术人员,将赢家和输家区分开来。相反,它是那些思想开放的创新者,能够看到过去的现状,并设想出截然不同的方法,并且有足够的悟性把它们放在合适的位置。机器学习的最大遗产之一可能是创造新一代的商业领袖。
在我们看来,人工智能,尤其是机器学习,是我们这个时代最重要的通用技术。这些创新对商业和经济的影响不仅反映在他们的直接贡献上,也体现在他们能够支持和鼓励互补创新的能力上。通过更好的视觉系统、语音识别、智能问题解决以及机器学习带来的许多其他功能,新产品和新工艺正在成为可能。
一些专家甚至走得更远。现在负责丰田研究机构的Gil Pratt将目前的人工智能技术与5亿年前的寒武纪大爆发相比较,那就是诞生了各种各样的新生命形式。就像现在一样,关键的新功能之一就是视觉。当动物第一次获得这种能力时,它允许它们更有效地探索环境;这就催化了物种数量的大量增加,包括捕食者和猎物,以及被填满的生态龛的范围。今天,我们还希望看到各种各样的新产品、服务、流程和组织形式,以及大量的物种灭绝。当然也会有一些骤然失败和意想不到的成功。
虽然很难准确预测哪些公司会在新环境中占据主导地位,但一般原则是明确的:最灵活、适应性强的公司和执行力将会发展壮大。在AI驱动的时代,任何对趋势敏感且能快速反应的团队都更应该抓住这次好机会。因此,成功的策略是愿意尝试并快速学习。如果职业经理人们没有在机器学习领域增加实验,他们就没有在做他们的工作。未来十年,人工智能不会取代管理人员,但使用人工智能的经理将取代那些不使用人工智能的人。
2017年,机器学习将在这四大行业得到全面应用
资本实验室
作者:张珂
【导读】机器学习、人工智能、商业智能充斥着我们的眼球,各种与数据沾边的初创企业都宣称利用AI技术云云,特别是一些与消费领域相关的初创企业,因其行业所处的数据量与获取渠道的制约,注定了大部分企业的AI只能是相对初级的产品或应用。
作为人工智能的核心技术,如果说过去几年的机器学习应用更多是企业测试性的行动,2017年可以说是机器学习的元年。在本年度,我们将看到机器学习与自动驾驶、制造、金融、零售等行业产生更为紧密的融合,并开始实现大规模的商业应用。
为了支持产业转型,在2017年,我们将看到机器学习巨大的变化将来自硬件升级而不是软件,2017年也将是硬件开始赶超软件的一年。不管你有没有做好准备,不管你是乐观还是悲观,我们都将成为人类社会发生巨变的见证者。
本文原作者Nick Ismail,原文发表于information-age,编译时对文中涉及机器学习应用的4个行业分别增加了相关案例及解读。
在过去几年中,机器学习已经成为科技行业的大趋势。作为更易应用的人工智能,机器学习更多是完成某一项任务,而不是直接编程。
目前,基础设施的快速发展,已经能够支持机器学习快速和有效的应用。2017年,将会有越多越多的企业将机器学习视为企业技术核心,并从试点运行扩大到全面商业化应用。
在2016年,各行业都有机器学习的不少测试案例,也有许多关于机器学习的初创企业被科技巨头收购。作为机器学习的一个分支,通过生成高效算法来构建高水平数据模型的深度学习也成为技术发展的主流。
2017年将成为机器学习技术影响人类世界的元年,机器学习开始进入商业化阶段。
1.自动驾驶
在消费领域,我们看到最多的机器学习应用,莫过于无人驾驶技术。许多无人驾驶汽车还处在测试阶段,在公共道路上实现完全自动驾驶的想法还处在起步阶段。
当自动驾驶汽车在公路上行驶时,必须能够实时响应周围的情况,这一点至关重要。这意味着通过传感器获取的所有信息必须在汽车中完成处理,而不是提交服务器或云端来进行分析,否则即使是非常短的时间,也可能造成不可挽回的损失。
因此,机器学习将是汽车数字基础设施的核心,使它能够从观察到的环境条件中进行学习。对于这些数据,一个特别有趣的应用是映射——汽车需要能够自动响应现实世界的周围环境,以更新地图。因此,每辆车都必须生成自己的导航网络。

自动驾驶已经成为近两年传统车企与科技公司争夺的热点领域,大众、本田、丰田、福特、通用、博世等传统车企或零部件企业通过自主研发或合作等方式,开发自动驾驶汽车;高通、三星、英特尔等公司通过开发自主驾驶芯片来抢占自动驾驶领域的一席之地;谷歌、特斯拉、亚马逊、微软等科技巨头更是通过技术优势提前布局自动驾驶。
在我国,自动驾驶更是提到了国家战略的高度,全国各地纷纷启动无人驾驶汽车示范区项目。4月19日,百度开放自动驾驶平台,帮助汽车行业及自动驾驶领域的合作伙伴快速搭建属于自己的完整的自动驾驶系统。
2.制造业
与自动驾驶汽车一样,随着物联网的发展,制造业企业可以从安置在生产线各环节的传感器收集大量的生产数据。
然而,这些数据并没有被充分利用。随着从复杂系统收集到众多参数的数据,数据分析变成了一项艰巨的任务。机器学习在制造业中的最大应用将是异常检测。

据统计,到2030年,全球的淡水需求预计将超过供应近40%。为协助各企业实现净零水循环使用的目标,美国水处理公司Ecolab(艺康集团)正通过包括Azure和Dynamics CRM Online在内的微软云平台帮助全球企业实现可持续运营。
与全球各地数以千计传感器相连的云平台能收集实时用水数据,并通过机器学习和商业智能分析全球各地的生产用水运营解决方案,不仅提高效率,还能降低水、能源消耗及运营成本。
尽管在这个领域之前已经进行过一些分析尝试,2017年将会有更多机器学习通过监督学习和建模来预测风险和失败。
2017年,机器学习也将推动工业自动化的实现,通过观察生产线和数据流来学习,并能够精确优化生产过程,降低生产成本,加快生产周期,从而节省人工分析数据的时间成本和资金成本。

天机智能作为深圳长盈精密的全资子公司,通过自动化改造,帮助公司提升生产工艺装备的自动化和智能化水平。该公司用机器取代了90%的劳动力,生产率提高了80%,产品缺陷率也显著减少了2.5倍。目前,工厂只有60名工人检测和管理生产线,以及维护计算机系统。
3.金融业
金融行业以其拥有的大量数据而闻名——从交易数据到客户数据,以及两者之间的所有数据。未来,这一数据会越来越多,而金融机构也越来越希望能够充分利用它们所拥有的海量数据。迄今为止,金融机构已经使用各种统计分析工具进行大量的分析,但对海量数据的实时分析与排序仍然是一项挑战。
2016年,金融业内已经有很多部署机器学习的讨论和试点行动。可以预计,2017年将成为金融业大规模应用机器学习的元年。金融机构将越来越多地依靠机器学习来挖掘新的商机,为客户提供个性化服务,乃至预防银行诈骗。
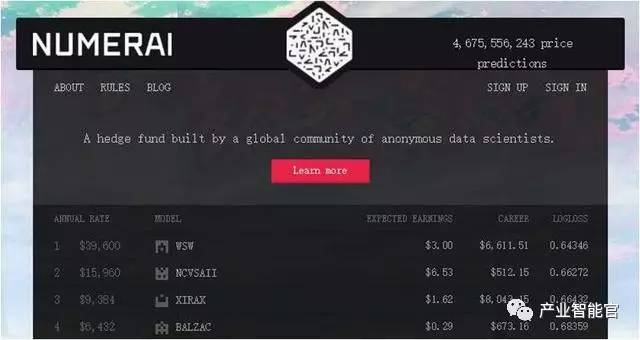
美国创业公司Numerai是一家以众包模式结合人工智能技术的对冲基金,通过人工智能技术,可以避免传统程序化交易因无法根据实时发生的市场变动调整算法,造成资产损失的风险。自2015年底建立以来,已经有数千人参与了其机器学习模型的建设,并收到近47亿次股票价格预测。
另外,老牌金融巨头也正在积极部署机器学习技术,例如全球最大的财富管理机构——瑞士银行(UBS)正在尝试利用面部识别,通过观察客户对不同投资标的呈现的面部表情来帮助他们进行投资。
从2017年1月起,日本保险公司Fukoku Mutual Life Insurance使用IBM的人工智能 “Watson Explorer”替换了34名人身保险索赔人员。该系统通过自动扫描医院记录和其他文件,了解人身伤害、病人病史等数据,帮助保险公司更快地进行保险赔付分析。另外三家日本保险公司也正在测试利用人工智能系统来实现自动化工作。
目前,投资组合管理公司使用传统方式来获取相关数据,如利润率分析、自由现金流、回报率、成长曲线、定价分析。除了可以完成上述分析外,机器学习还可以帮助搜索社交媒体、网站和其它来源,分析非结构化的数据,以获得更多的数据输入,帮助人们制定更好的决策。
4.零售业
在线推荐技术已经变得越来越复杂。在2017年,诸如引入社交网络推荐等更多的数据源,在线推荐的数据将会更加详实、更加细分化。
例如,如果你曾在线浏览猫粮的信息,那么你可能会看到与猫相关产品的推荐广告。在未来一年,电商网站将通过更多的购买趋势和客户数据,为你提供更加个性化、更精准的推荐信息。
虽然电子商务已经经历了部署机器学习的早期阶段,但在2017年,最激动人心的事情之一,就是该技术将用于线下实体店的购物。
零售商将能够在消费者进入商店时分析消费者的行为和动作,用于帮助消费者找到合适的商品和适当的优惠。通过视频分析,零售商将能够分析消费者正在查看哪些商品,甚至是商品包装上的某个部分,无论是价格、功能还是图片。通过分析这些消费者购买数据,可以为零售商提供消费者最可能购买的商品的最佳建议。
利用传感器、物联网、虚拟现实和增强现实、可穿戴技术,不只是为消费者提供更方便快捷的购物体验,而是基于各种新技术背后的AI数据分析,为零售商发现更深层次的消费洞察。
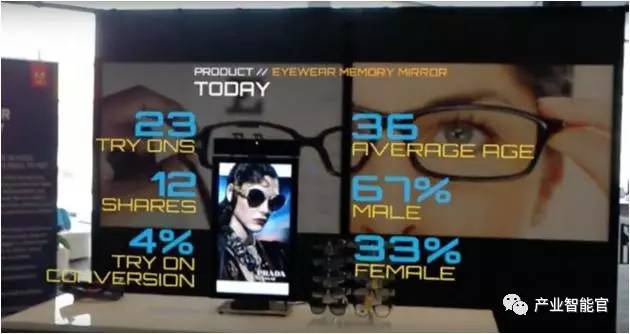
Adobe公司正在与微软合作研发增强现实在零售环境中的可视化应用,将可视化数据分析展现在HoloLens上,商家可以看到店面人流量、消费者消费行为等数据,使商家的营销活动更具精准性。
为了支持产业转型,在2017年,我们将看到机器学习巨大的变化将来自硬件升级而不是软件。
为了满足机器学习所需要的分析速度,机器学习处理正越来越多地从云计算转向边缘计算,那些时间紧迫的信息处理将越来越即时。
此外,我们将看到越来越多的投资会集中在多核技术和并行计算上,而这将进一步提高机器学习的速度。在更广泛的机器学习技术部署方面,2017年,将是硬件开始赶超软件的一年,例如,增强GPU技术以及混合系统(如CPU + FPGA)。
机器学习正开始改变我们的工作与生活,而它在行业中的应用才具有真正的革命性。随着机器人在企业IT和业务流程中越来越多的应用,企业将很快把机器学习作为核心业务处理和自动化决策的核心。
随着基础设施的快速发展和有效的机器学习应用,2017将是机器学习从企业试点走向全面应用的关键一年。

新一代技术+商业操作系统:
AI-CPS OS
在新一代技术+商业操作系统(AI-CPS OS:云计算+大数据+物联网+区块链+人工智能)分支用来的今天,企业领导者必须了解如何将“技术”全面渗入整个公司、产品等“商业”场景中,利用AI-CPS OS形成数字化力量,实现行业的重新布局、企业的重新构建和自我的焕然新生,在行业、企业和自身三个层面勇立鳌头。
数字化力量与行业、企业及个人三个层面的交叉,形成了领导力模式,使数字化融入到领导者所在企业与领导方式的核心位置。
分辨率革命:这种力量能够使人在更加真实、细致的层面观察与感知现实世界和数字化世界正在发生的一切,进而理解和更加精细地进行产品控制、事件控制和结果控制。
复合不确定性:数字化变更颠覆和改变了领导者曾经仰仗的思维方式、结构和实践经验,其结果就是形成了复合不确定性这种颠覆性力量。主要的不确定性蕴含于三个领域:技术、文化、制度。
边界模糊化:数字世界与现实世界的不断融合成CPS不仅让人们所知行业的核心产品、经济学定理和可能性都产生了变化,还模糊了不同行业间的界限。这种效应正在向生态系统、企业、客户、产品快速蔓延。
领导者无法依靠某种单一战略方法来应对多维度的数字化变革。随着变革范围不断扩大,一切都几乎变得不确定,即使是最精明的领导者也可能失去方向。面对新一代技术+商业操作系统(AI-CPS OS:云计算+大数据+物联网+区块链+人工智能)颠覆性的数字化力量,领导者必须在行业、企业与个人这三个层面都保持领先地位。
如果不能在上述三个层面保持领先,领导力将会不断弱化并难以维继:
重新进行行业布局:你的世界观要怎样改变才算足够?你必须对行业典范进行怎样的反思?
重新构建你的企业:你的企业需要做出什么样的变化?你准备如何重新定义你的公司?
重新打造新的自己:你需要成为怎样的人?要重塑自己并在数字化时代保有领先地位,你必须如何去做?
子曰:“君子和而不同,小人同而不和。” 《论语·子路》
云计算、大数据、物联网、区块链和 人工智能,像君子一般融合,一起体现科技就是生产力。
如果说上一次哥伦布地理大发现,拓展的是人类的物理空间。那么这一次地理大发现,拓展的就是人们的数字空间。
在数学空间,建立新的商业文明,从而发现新的创富模式,为人类社会带来新的财富空间。
云计算,大数据、物联网和区块链,是进入这个数字空间的船,而人工智能就是那船上的帆,哥伦布之帆!
人工智能通过三个方式激发经济增长:
创造虚拟劳动力,承担需要适应性和敏捷性的复杂任务,即“智能自动化”,以区别于传统的自动化解决方案;
对现有劳动力和实物资产进行有利的补充和提升,提高资本效率;
人工智能的普及,将推动多行业的相关创新,开辟崭新的经济增长空间。
新一代信息技术(云计算、大数据、物联网、区块链和人工智能)的商业化落地进度远不及技术其本身的革新来得迅猛,究其原因,技术供应商(乙方)不明确自己的技术可服务于谁,传统企业机构(甲方)不懂如何有效利用新一代信息技术创新商业模式和提升效率。
“产业智能官”,通过甲、乙方价值巨大的云计算、大数据、物联网、区块链和人工智能的论文、研究报告和商业合作项目,面向企业CEO、CDO、CTO和CIO,服务新一代信息技术输出者和新一代信息技术消费者。
助力新一代信息技术公司寻找最有价值的潜在传统客户与商业化落地路径,帮助传统企业选择与开发适合自己的新一代信息技术产品和技术方案,消除新一代信息技术公司与传统企业之间的信息不对称,推动云计算、大数据、物联网、区块链和人工智能的商业化浪潮。
给决策制定者和商业领袖的建议:
超越自动化,开启新创新模式:利用具有自主学习和自我控制能力的动态机器智能,为企业创造新商机;
迎接新一代信息技术,迎接人工智能:无缝整合人类智慧与机器智能,重新
评估未来的知识和技能类型;
制定道德规范:切实为人工智能生态系统制定道德准则,并在智能机器的开
发过程中确定更加明晰的标准和最佳实践;
重视再分配效应:对人工智能可能带来的冲击做好准备,制定战略帮助面临
较高失业风险的人群;
开发人工智能型企业所需新能力:员工团队需要积极掌握判断、沟通及想象力和创造力等人类所特有的重要能力。对于中国企业来说,创造兼具包容性和多样性的文化也非常重要。
新一代技术+商业操作系统(AI-CPS OS:云计算+大数据+物联网+区块链+人工智能)作为新一轮产业变革的核心驱动力,将进一步释放历次科技革命和产业变革积蓄的巨大能量,并创造新的强大引擎。
重构生产、分配、交换、消费等经济活动各环节,形成从宏观到微观各领域的智能化新需求,催生新技术、新产品、新产业、新业态、新模式。引发经济结构重大变革,深刻改变人类生产生活方式和思维模式,实现社会生产力的整体跃升。
新一代技术+商业操作系统(AI-CPS OS:云计算+大数据+物联网+区块链+人工智能)正在经历从“概念”到“落地”,最终实现“大范围规模化应用,深刻改变人类生活”的过程。
产业智能官 AI-CPS
用新一代技术+商业操作系统(AI-CPS OS:云计算+大数据+物联网+区块链+人工智能),在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的认知计算和机器智能;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。


长按上方二维码关注微信公众号: AI-CPS,更多信息回复:
新技术:“云计算”、“大数据”、“物联网”、“区块链”、“人工智能”;新产业:“智能制造”、“智能驾驶”、“智能金融”、“智能城市”、“智能零售”;新模式:“案例分析”、“研究报告”、“商业模式”、“供应链金融”、“财富空间”。
本文系“产业智能官”(公众号ID:AI-CPS)收集整理,转载请注明出处!
版权声明:由产业智能官(公众号ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源。部分文章推送时未能与原作者取得联系。若涉及版权问题,烦请原作者联系我们,与您共同协商解决。联系、投稿邮箱:erp_vip@hotmail.com




