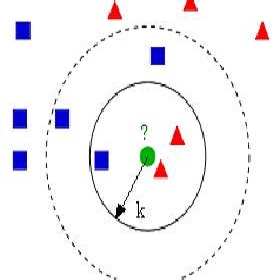
【白话机器学习】算法理论+实战之K近邻算法

1. 写在前面
如果想从事数据挖掘或者机器学习的工作,掌握常用的机器学习算法是非常有必要的,在这简单的先捋一捋, 常见的机器学习算法:
-
监督学习算法:逻辑回归,线性回归,决策树,朴素贝叶斯, K近邻,支持向量机,集成算法Adaboost等 -
无监督算法:聚类,降维,关联规则, PageRank等
为了详细的理解这些原理,曾经看过西瓜书,统计学习方法,机器学习实战等书,也听过一些机器学习的课程,但总感觉话语里比较深奥,读起来没有耐心,并且理论到处有,而实战最重要, 所以在这里想用最浅显易懂的语言写一个白话机器学习算法理论+实战系列。
个人认为,理解算法背后的idea和使用,要比看懂它的数学推导更加重要。idea会让你有一个直观的感受,从而明白算法的合理性,数学推导只是将这种合理性用更加严谨的语言表达出来而已,打个比方,一个梨很甜,用数学的语言可以表述为糖分含量90%,但只有亲自咬一口,你才能真正感觉到这个梨有多甜,也才能真正理解数学上的90%的糖分究竟是怎么样的。如果算法是个梨,本文的首要目的就是先带领大家咬一口。另外还有下面几个目的:
-
检验自己对算法的理解程度,对算法理论做一个小总结 -
能开心的学习这些算法的核心思想, 找到学习这些算法的兴趣,为深入的学习这些算法打一个基础。 -
每一节课的理论都会放一个实战案例,能够真正的做到学以致用,既可以锻炼编程能力,又可以加深算法理论的把握程度。 -
也想把之前所有的笔记和参考放在一块,方便以后查看时的方便。
学习算法的过程,获得的不应该只有算法理论,还应该有乐趣和解决实际问题的能力!
今天是白话机器学习算法理论+实战的第七篇 之K近邻算法,这应该是诸多机器学习算法中最容易理解或者操作的一个算法了吧,但是别看它简单,但是很实用的。因为它既可以用来做分类,也可以用来做回归,易于实现,无需估计参数,无需训练。当然也有一些缺点,比如计算量比较大,分析速度较慢,样本不均衡问题不太好用,也无法给出数据的内在含义,是一种懒散学习法。 当然,KNN也可以用于推荐算法,虽然现在很多推荐系统的算法会使用 TD-IDF、协同过滤、Apriori 算法,不过针对数据量不大的情况下,采用 KNN 作为推荐算法也是可行的。
这么简单,并且作用还很大的算法我们应该立刻把握住,所以这节课,我们就来学习KNN的计算原理,并且用KNN来实现一个实战案例,我们开始吧。
大纲如下:
-
如果根据打斗和接吻的次数来划分电影的类型?(我们引出KNN) -
KNN的工作原理(近朱者赤,近墨者黑) -
如何用KNN做回归?(简单介绍一下) -
用KNN实现书写数字的识别(手写数字识别可是深度学习界的Hellow world,在这里先带你认识一下)
OK, let's go!
2. K近邻算法?我们依然从一个电影的分类开始
KNN 的英文叫 K-Nearest Neighbor,应该算是数据挖掘算法中最简单的一种。虽然简单,但是很实用, 老规矩,既然白话,还是先从例子开始,让你再次体会算法来源生活。
假设有下面这几部电影,我给你统计了电影中的打斗次数、接吻次数, 当然其他的也可以统计,但是没顾得上,如下表所示: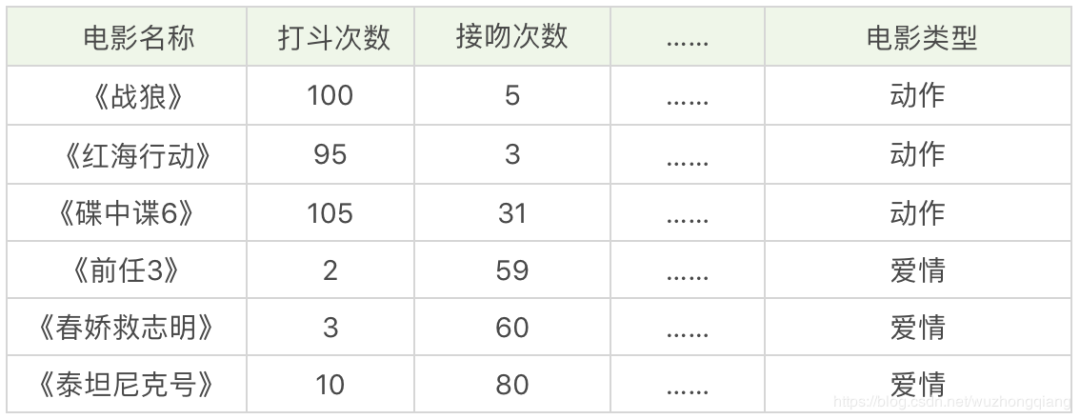
但是假设我目前有一部新电影, 叫做《速度与激情9》,我也统计了一下打斗次数和接吻次数, 这应该划分到爱情还是动作呢? 你会说,这还不简单,我直接就知道是范·迪塞尔男神主演的动作片。但是机器不知道啊, 机器可不管你男神还是女神,你得让机器明白这种分类规则,让机器去分类啊, 那你应该用什么方法呢?
我们可以把打斗次数看成 X 轴,接吻次数看成 Y 轴,然后在二维的坐标轴上,对这几部电影进行标记,如下图所示。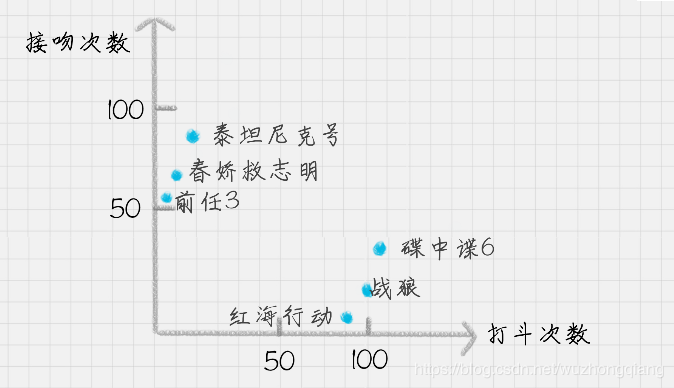
嗯嗯,这才是你教机器做的东西呢,其实这就是K近邻了啊,好理解吧,就是新的一部电影过来了,看他和哪个邻居挨得近,邻居是哪一类,它就是哪一类啦。
但是,具体还有些细节需要我们知道,下面就真的看看原理吧。
3. K近邻的工作原理
简单的一句话就可以说明KNN的工作原理“近朱者赤,近墨者黑”。
K近邻算法的过程是给定一个训练数据集,对新输入的实例,在训练数据集中找到与该实例最邻近的K个实例, 这K个实例的多数属于某个类, 就把该输入实例分为这个类。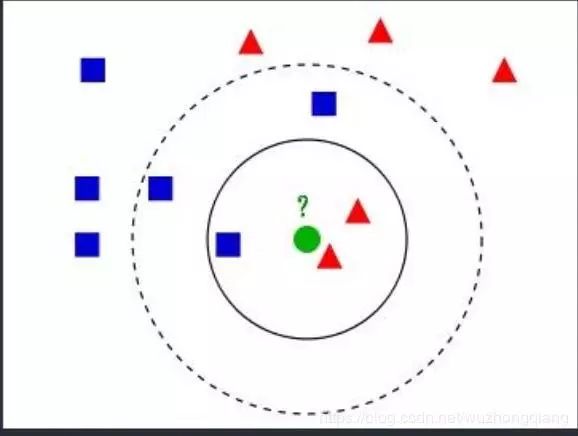
-
如果k=3, 绿色圆点的最近邻的3个点是2个红色三角和1个蓝色小正方形, 少数服从多数, 基于统计的方法,判定绿色的这个待分类点属于红色三角形一类 -
如果k=5, 绿色圆点的最近邻的5个点是2个红色三角和3个蓝色小正方形,还是少数服从多数, 基于统计的方法,判定这个待分类点属于蓝色的正方形一类
从上面例子可以看出, k近邻算法的思想非常简单, 对新来的点如何归类?【只要找到离它最近的k个实例, 哪个类别最多即可】
所以,KNN的工作原理大致分为三步:
-
计算待分类物体与其他物体之间的距离; -
统计距离最近的 K 个邻居; -
对于 K 个最近的邻居,它们属于哪个分类最多,待分类物体就属于哪一类。
但是下面就引出了2个问题:
-
怎么度量距离,锁定最近的K个邻居?(不同的度量方法可能导致K个邻居不同) -
怎么确定这个K值(K值不同,最后的结果可能不同,像上面那样)
下面就来破了这俩问题。
首先先说第二个问题, K值如何选择?
你能看出整个 KNN 的分类过程,K 值的选择还是很重要的
-
如果 K 值比较小,就相当于未分类物体与它的邻居非常接近才行。这样产生的一个问题就是,如果邻居点是个噪声点,那么未分类物体的分类也会产生误差,这样 KNN 分类就会产生过拟合。就比如下面这个情况(K=1, 绿色点为分类点): 上面这种情况K=1,直接把绿色点分到橙色那一类了,但是橙色点是个噪声点啊。
-
如果 K 值比较大,相当于距离过远的点也会对未知物体的分类产生影响,虽然这种情况的好处是鲁棒性强,但是不足也很明显,会产生欠拟合情况,也就是没有把未分类物体真正分类出来。就比如下面这个情况: 上面这种情况K=N, 那么无论输入实例是什么,都将简单的预测它属于在训练实例中最多的类,这时相当于压根没有训练模型, 完全忽略训练数据实例中大量的有用信息,是不可取的。
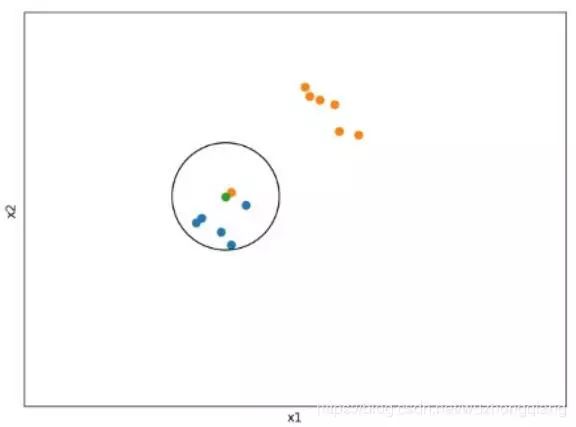 上面这种情况K=1,直接把绿色点分到橙色那一类了,但是橙色点是个噪声点啊。
上面这种情况K=1,直接把绿色点分到橙色那一类了,但是橙色点是个噪声点啊。
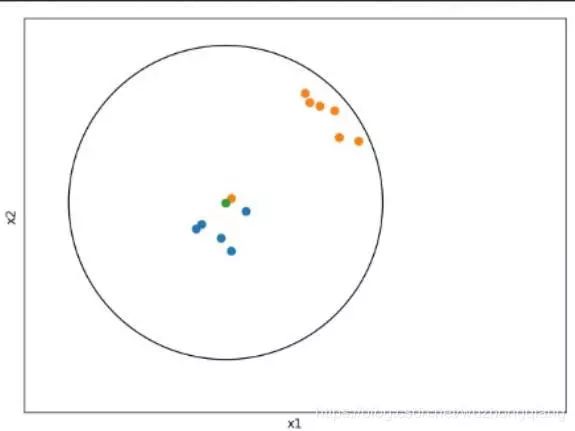 上面这种情况K=N, 那么无论输入实例是什么,都将简单的预测它属于在训练实例中最多的类,这时相当于压根没有训练模型, 完全忽略训练数据实例中大量的有用信息,是不可取的。
上面这种情况K=N, 那么无论输入实例是什么,都将简单的预测它属于在训练实例中最多的类,这时相当于压根没有训练模型, 完全忽略训练数据实例中大量的有用信息,是不可取的。
那么K值如何确定呢? 呵呵,不好意思,这个值没法事先而定,需要不断的实践,一次次的尝试。工程上,我们一般采用交叉验证的方式选取K值。
★交叉验证的思路就是,把样本集中的大部分样本作为训练集,剩余的小部分样本用于预测,来验证分类模型的准确性。所以在 KNN 算法中,我们一般会把 K 值选取在较小的范围内,同时在验证集上准确率最高的那一个最终确定作为 K 值。
”
再说第二个问题, 距离如何计算?
在 KNN 算法中,还有一个重要的计算就是关于距离的度量。两个样本点之间的距离代表了这两个样本之间的相似度。距离越大,差异性越大;距离越小,相似度越大。
度量距离有下面的五种方式:
-
欧式距离 欧氏距离是我们最常用的距离公式,也叫做欧几里得距离。在二维空间中,两点的欧式距离就是: 同理,我们也可以求得两点在n维空间中的距离:
-
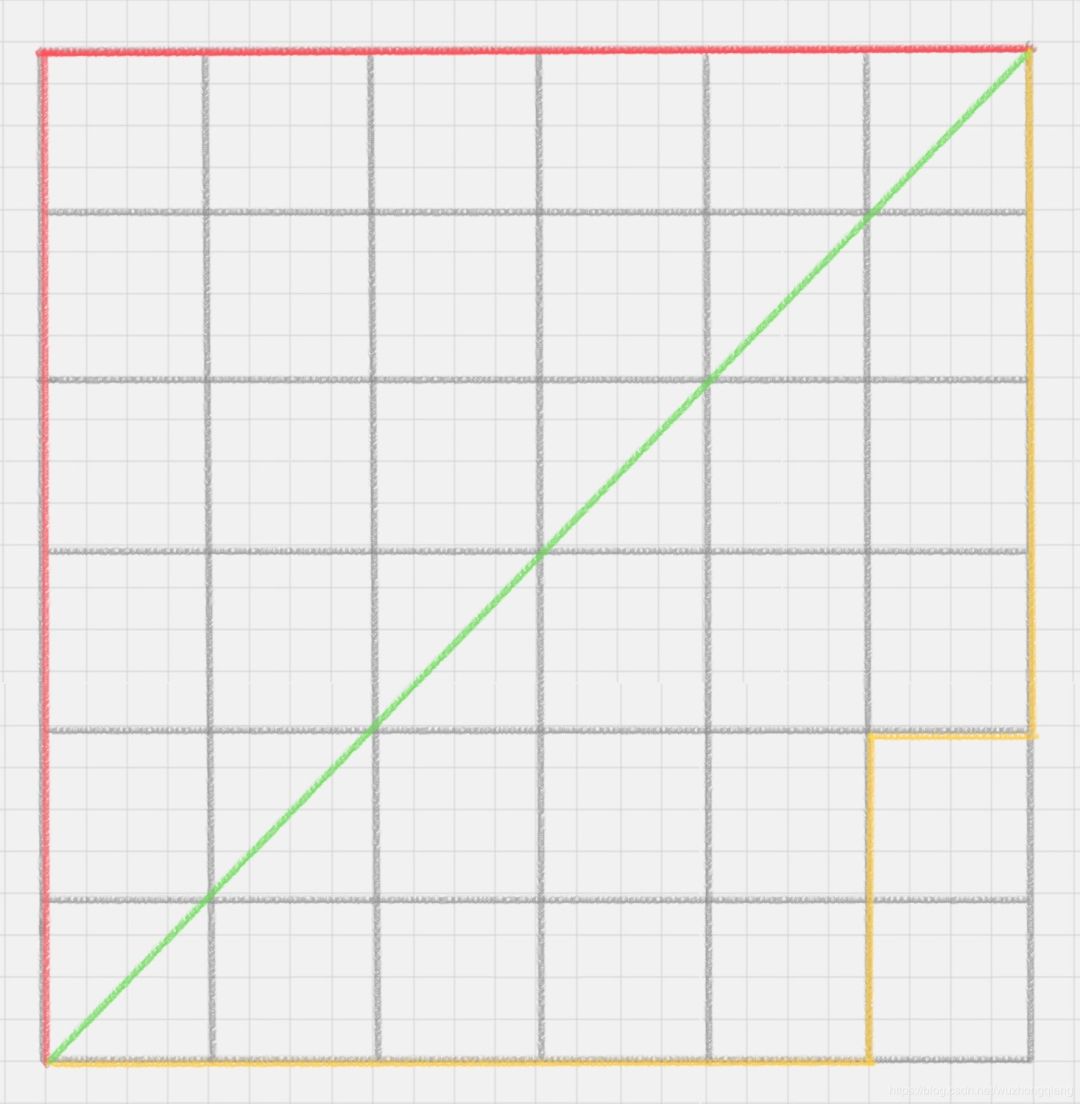
曼哈顿距离 曼哈顿距离在几何空间中用的比较多。曼哈顿距离等于两个点在坐标系上绝对轴距总和。用公式表示就是: 以下图为例,绿色的直线代表两点之间的欧式距离,而红色和黄色的线为两点的曼哈顿距离。感受一下两者的不同:
-
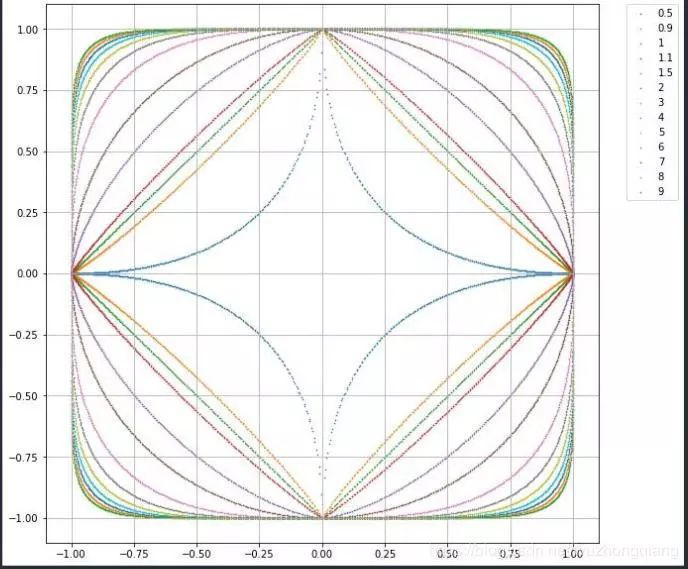
闵可夫斯基距离 闵可夫斯基距离不是一个距离,而是一组距离的定义。对于 n 维空间中的两个点 x(x1,x2,…,xn) 和 y(y1,y2,…,yn) , x 和 y 两点之间的闵可夫斯基距离为: 其中 p 代表空间的维数,当 p=1 时,就是曼哈顿距离;当 p=2 时,就是欧氏距离;当 p→∞时,就是切比雪夫距离。下面给出了不同的p值情况下,与原来Lp距离为1的点的图形,直观感受一下p值的不同,距离的变化:
-
切比雪夫距离 那么切比雪夫距离怎么计算呢?二个点之间的切比雪夫距离就是这两个点坐标数值差的绝对值的最大值,用数学表示就是:max(|x1-y1|,|x2-y2|)。 -
余弦距离 余弦距离实际上计算的是两个向量的夹角,是在方向上计算两者之间的差异,对绝对数值不敏感。在兴趣相关性比较上,角度关系比距离的绝对值更重要,因此余弦距离可以用于衡量用户对内容兴趣的区分度。比如我们用搜索引擎搜索某个关键词,它还会给你推荐其他的相关搜索,这些推荐的关键词就是采用余弦距离计算得出的。所以搜索推荐中,余弦距离会常用。
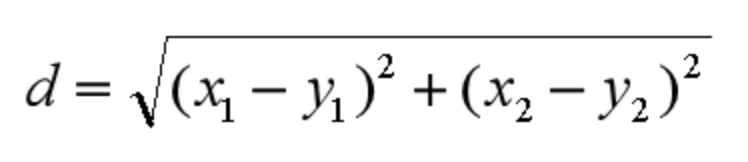 同理,我们也可以求得两点在n维空间中的距离:
同理,我们也可以求得两点在n维空间中的距离:
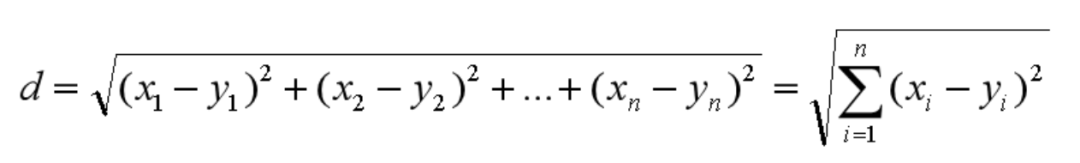
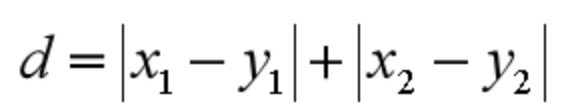 以下图为例,绿色的直线代表两点之间的欧式距离,而红色和黄色的线为两点的曼哈顿距离。感受一下两者的不同:
以下图为例,绿色的直线代表两点之间的欧式距离,而红色和黄色的线为两点的曼哈顿距离。感受一下两者的不同:
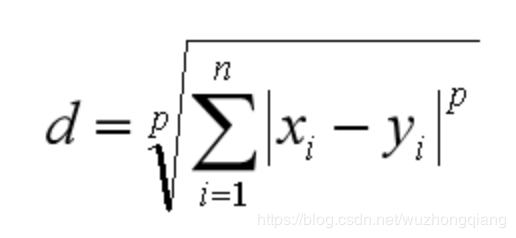 其中 p 代表空间的维数,当 p=1 时,就是曼哈顿距离;当 p=2 时,就是欧氏距离;当 p→∞时,就是切比雪夫距离。下面给出了不同的p值情况下,与原来Lp距离为1的点的图形,直观感受一下p值的不同,距离的变化:
其中 p 代表空间的维数,当 p=1 时,就是曼哈顿距离;当 p=2 时,就是欧氏距离;当 p→∞时,就是切比雪夫距离。下面给出了不同的p值情况下,与原来Lp距离为1的点的图形,直观感受一下p值的不同,距离的变化:
其中前三种距离是 KNN 中最常用的距离。
好了,解答了这个问题,也就弄明白了KNN的原理了吧。是不是想迫不及待的实战了?先别慌,还有点东西得介绍一下。
4. KD树
关于KD树的知识,我在这不会介绍太多,涉及的数学公式有点多,但得介绍一下这个东西,我们不需要对 KD 树的数学原理了解太多,你只需要知道它是一个二叉树的数据结构,方便存储 K 维空间的数据就可以了。而且在 sklearn 中,我们直接可以调用 KD 树,很方便。
其实从上文你也能看出来,KNN 的计算过程是大量计算样本点之间的距离。为了减少计算距离次数,提升 KNN 的搜索效率,人们提出了 KD 树(K-Dimensional 的缩写)。KD 树是对数据点在 K 维空间中划分的一种数据结构。在 KD 树的构造中,每个节点都是 k 维数值点的二叉树。既然是二叉树,就可以采用二叉树的增删改查操作,这样就大大提升了搜索效率。
嗯,关于KD树,就说这么多,在实战之前,再说一下,KNN如何做回归吧,毕竟后面的实战是个分类任务,之前既然说了KNN能够做回归,你可别说我撒谎。
5. KNN做回归
KNN 不仅可以做分类,还可以做回归。首先讲下什么是回归。在开头电影这个案例中,如果想要对未知电影进行类型划分,这是一个分类问题。首先看一下要分类的未知电影,离它最近的 K 部电影大多数属于哪个分类,这部电影就属于哪个分类。
如果是一部新电影,已知它是爱情片,想要知道它的打斗次数、接吻次数可能是多少,这就是一个回归问题。
那KNN如何做回归呢?
对于一个新电影 X(就假设《速度与激情》,我男神演的动作片吧)。我们要预测它的某个属性值,比如打斗次数,具体特征属性和数值如下所示。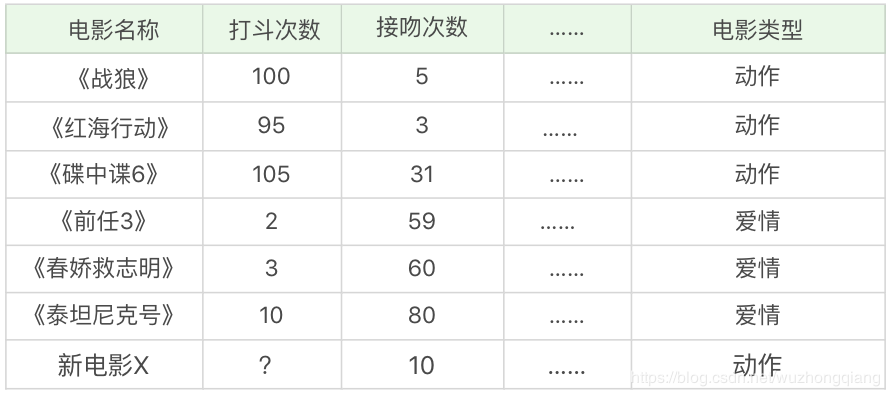
好了,这就是KNN了,没有什么特别要交代的了,下面实战吧。
6. KNN:如何对手写数字进行识别?
还是老规矩,先看看通过sklearn用这个工具。
6.1 如何在sklearn中使用KNN?
在 Python 的 sklearn 工具包中有 KNN 算法。KNN 既可以做分类器,也可以做回归。
-
如果是做分类,你需要引用:from sklearn.neihbors import KNeighborsClassifier -
如果是回归, 需要引用:from sklearn.neighbors import KNeighborsRegressor
如何在sklearn中创建KNN分类器呢?
★KNeighborsClassifier(n_neighbors=5, weights='uniform', algorithm='auto', leaf_size=30), 看一下这几个参数:
n_neighbors:即 KNN 中的 K 值,代表的是邻居的数量。K 值如果比较小,会造成过拟合。如果 K 值比较大,无法将未知物体分类出来。一般我们使用默认值 5。 weights:是用来确定邻居的权重,有三种方式: ★”
weights=uniform,代表所有邻居的权重相同; weights=distance,代表权重是距离的倒数,即与距离成反比; 自定义函数,你可以自定义不同距离所对应的权重。大部分情况下不需要自己定义函数。
algorithm:用来规定计算邻居的方法,它有四种方式: ★”
algorithm=auto,根据数据的情况自动选择适合的算法,默认情况选择 auto; algorithm=kd_tree,也叫作 KD 树,是多维空间的数据结构,方便对关键数据进行检索,不过 KD 树适用于维度少的情况,一般维数不超过 20,如果维数大于 20 之后,效率反而会下降; algorithm=ball_tree,也叫作球树,它和 KD 树一样都是多维空间的数据结果,不同于 KD 树,球树更适用于维度大的情况; algorithm=brute,也叫作暴力搜索,它和 KD 树不同的地方是在于采用的是线性扫描,而不是通过构造树结构进行快速检索。当训练集大的时候,效率很低。 ”
4.leaf_size:代表构造 KD 树或球树时的叶子数,默认是 30,调整 leaf_size 会影响到树的构造和搜索速度。
创建完 KNN 分类器之后,我们就可以输入训练集对它进行训练,这里我们使用 fit() 函数,传入训练集中的样本特征矩阵和分类标识,会自动得到训练好的 KNN 分类器。然后可以使用 predict() 函数来对结果进行预测,这里传入测试集的特征矩阵,可以得到测试集的预测分类结果。
6.2 如何在sklearn中使用KNN?
手写数字数据集是个非常有名的用于图像识别的数据集。数字识别的过程就是将这些图片与分类结果 0-9 一一对应起来。完整的手写数字数据集 MNIST 里面包括了 60000 个训练样本,以及 10000 个测试样本。如果你学习深度学习的话,MNIST 基本上是你接触的第一个数据集。
我们用 sklearn 自带的手写数字数据集做 KNN 分类,你可以把这个数据集理解成一个简版的 MNIST 数据集,它只包括了 1797 幅数字图像,每幅图像大小是 8*8 像素。
还是先划分一下流程: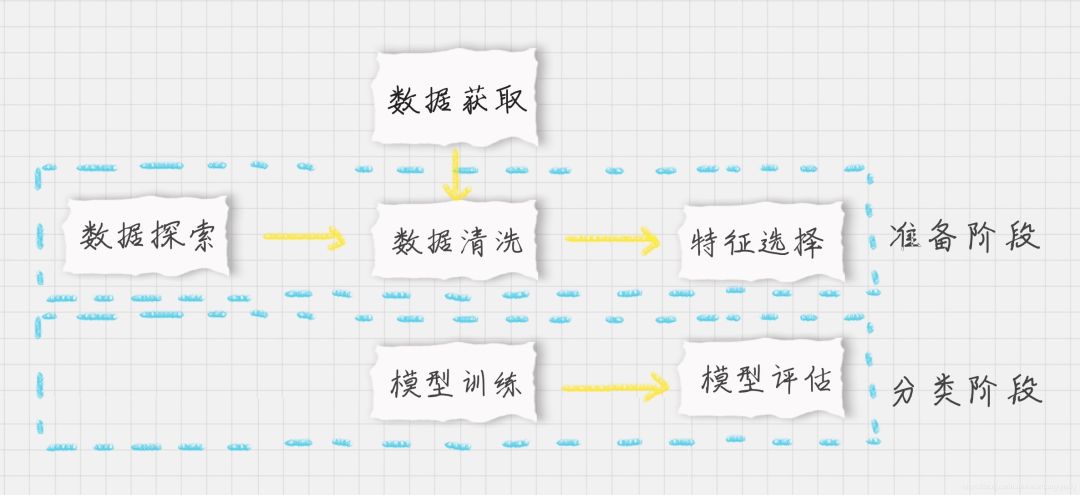
-
数据加载:我们可以直接从 sklearn 中加载自带的手写数字数据集; -
准备阶段:在这个阶段中,我们需要对数据集有个初步的了解,比如样本的个数、图像长什么样、识别结果是怎样的。你可以通过可视化的方式来查看图像的呈现。通过数据规范化可以让数据都在同一个数量级的维度。另外,因为训练集是图像,每幅图像是个 8*8 的矩阵,我们不需要对它进行特征选择,将全部的图像数据作为特征值矩阵即可; -
分类阶段:通过训练可以得到分类器,然后用测试集进行准确率的计算。
好了,下面我们开始吧:
-
首先,导入包,这里导入了很多算法包,是因为既然这次项目比较简单,都那么我们就对比一下之前的几种方法,看看效果。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.naive_bayes import MultinomialNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.metrics import accuracy_score
-
加载数据集并探索
# 加载数据
digits = load_digits()
data = digits.data
# 数据探索
print(data.shape)
# 查看第一幅图像
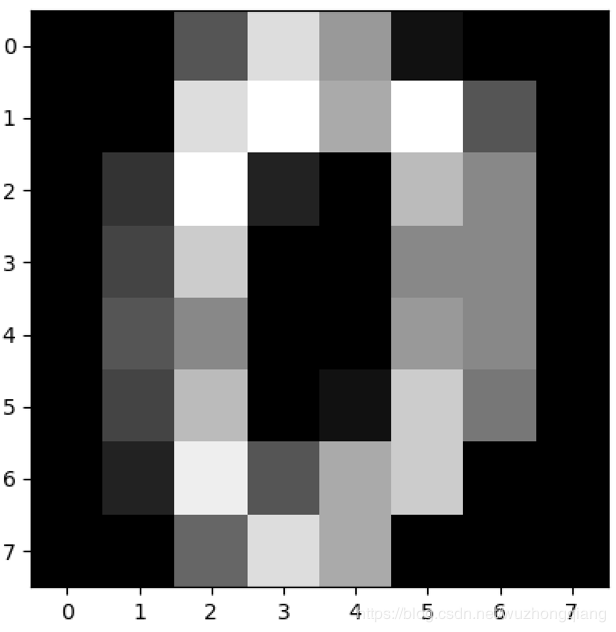
print(digits.images[0])
# 第一幅图像代表的数字含义
print(digits.target[0])
# 将第一幅图像显示出来
plt.gray()
plt.imshow(digits.images[0])
plt.show()
# 结果如下:
(1797, 64)
[[ 0. 0. 5. 13. 9. 1. 0. 0.]
[ 0. 0. 13. 15. 10. 15. 5. 0.]
[ 0. 3. 15. 2. 0. 11. 8. 0.]
[ 0. 4. 12. 0. 0. 8. 8. 0.]
[ 0. 5. 8. 0. 0. 9. 8. 0.]
[ 0. 4. 11. 0. 1. 12. 7. 0.]
[ 0. 2. 14. 5. 10. 12. 0. 0.]
[ 0. 0. 6. 13. 10. 0. 0. 0.]]
0
-
分割数据集并规范化 klearn 自带的手写数字数据集一共包括了 1797 个样本,每幅图像都是 8*8 像素的矩阵。因为并没有专门的测试集,所以我们需要对数据集做划分,划分成训练集和测试集。因为 KNN 算法和距离定义相关,我们需要对数据进行规范化处理,采用 Z-Score 规范化,代码如下:
# 分割数据,将25%的数据作为测试集,其余作为训练集(你也可以指定其他比例的数据作为训练集)
train_x, test_x, train_y, test_y = train_test_split(data1, target1, test_size=0.25)
# 采用z-score规范化
ss = StandardScaler()
train_ss_scaled = ss.fit_transform(train_x)
test_ss_scaled = ss.transform(test_x)
# 采用0-1归一化
mm = MinMaxScaler()
train_mm_scaled = mm.fit_transform(train_x)
test_mm_scaled = mm.transform(test_x)
这里之所以用了0-1归一化,是因为多项式朴素贝叶斯分类这个模型,传入的数据不能有负数。因为 Z-Score 会将数值规范化为一个标准的正态分布,即均值为 0,方差为 1,数值会包含负数。因此我们需要采用 Min-Max 规范化,将数据规范化到[0,1]范围内。
-
建立模型,并进行比较:这里构造五个分类器, 分别是K近邻,SVM, 多项式朴素贝叶斯, 决策树模型, AdaBoost模型。并分别看看他们的效果
PS: 注意, 在做多项式朴素贝叶斯的时候,传入的数据不能有负数,由于Z-Score会将值归一化一个标准的正态分布,会包含负数,所以不能有这个,采用MinMax归一化到[0-1]范围即可。
models = {}
models['knn'] = KNeighborsClassifier()
models['svm'] = SVC()
models['bayes'] = MultinomialNB()
models['tree'] = DecisionTreeClassifier()
models['ada'] = AdaBoostClassifier(base_estimator=models['tree'], learning_rate=0.1)
for model_key in models.keys():
if model_key == 'knn' or model_key == 'svm' or model_key == 'ada':
model = models[model_key]
model.fit(train_ss_scaled, train_y)
predict = model.predict(test_ss_scaled)
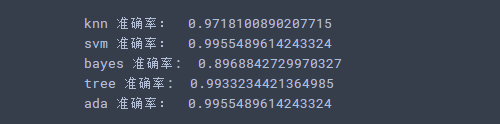
print(model_key, "准确率:", accuracy_score(test_y, predict))
else:
model = models[model_key]
model.fit(train_mm_scaled, train_y)
predict = model.predict(test_mm_scaled)
print(model_key, "准确率: ", accuracy_score(test_y, predict))
输出结果: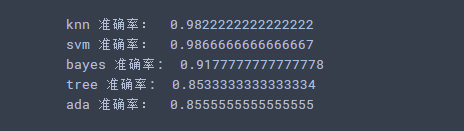
data1 = np.vstack((data, data, data))
target1 = np.hstack((target, target, target))
变成了5000多张数据,然后再进行测试,结果就是AdaBoost和tree的效果提升了,甚至可以和SVM效果媲美了:
7. 总结
好了,到这里就基本结束了,KNN不算太难,所以篇幅可能少了一些,但KNN还是挺好用的一个算法, 下面简单的总结一下:
首先,就是通过电影分类的例子,体会了一下什么是KNN,然后写了一下KNN的工作原理,主要问题就是K值怎么选取?距离怎么衡量?
然后,两个小插曲KD树和KNN做回归。
最后就是手写数字识别的实战,这个当然也比较简单,然后就是对比了这几个算法的效果。KNN在里面表现不错,SVM算法处理这种问题还是不错,样本较多的时候,集成的方式还是占据一定的优势。在这个过程中你应该对数据探索、数据可视化、数据规范化、模型训练和结果评估的使用过程有了一定的体会。在数据量不大的情况下,使用 sklearn 还是方便的。
参考:
-
http://note.youdao.com/noteshare?id=e753340eab85bb24b34ee45812b47ea1&sub=FE026DF879B7400F8DB196C8DE931238 -
http://note.youdao.com/noteshare?id=7ac08cc7ebdde0854ac3281923aeb5c0&sub=8072C6A29A3D4B00BB5316FFF676C1E2 -
http://note.youdao.com/noteshare?id=3e2f7f6d1147058dd4ca93bf03d0c338&sub=1686C728DD194617BDA9DFFF60049421
推荐阅读
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。
![]()