2017年网页抓取:先进的Headless Chrome技巧
点击上方“CSDN”,选择“置顶公众号”
关键时刻,第一时间送达!
作者丨Martin Tapia
翻译丨不二
Headless Chrome是Chrome 浏览器的无界面形态,可以在不打开浏览器的前提下,使用所有 Chrome 支持的特性运行程序。相比于现代浏览器,Headless Chrome 更加方便测试web应用,获得网站的截图,做爬虫抓取信息等,也更加贴近浏览器环境。下面看看作者分享的使用Headless Chrome进行网页抓取的经验。
PhantomJS的研发已经停止,而Headless Chrome成了热门关注的焦点,大家都很喜欢它,包括我们。在Phantombuster公司,网页抓取是我们工作的很大一部分,现在我们广泛使用Headless Chrome。
这篇文章,将告诉你如何快速入门Headless Chrome生态系统,并展示从已经抓取数百万网页中学到的经验。
文章摘要:
1. 有很多库可以控制Chrome,可以根据自己的喜欢选择。
2. 使用Headless Chrome进行网页抓取非常简单,掌握下面的技巧之后更是如此。
3. Headless浏览器访客可以被检测到,但没人这么做。
Headless Chrome简述
Headless Chrome基于PhantomJS(QtWebKit内核)由谷歌Chrome团队开发。团队表示将专注研发这个项目,未来也会不断维护它。
这意味着对于网页抓取和自动化的需求,现在可以体会Chrome的速度和功能,因为它具备世界上使用最多的浏览器的特性:支持所有网站,支持JS引擎,还有伟大的开发者工具API。太可怕啦!
选用哪个工具控制Headless Chrome?

市面上确实有很多NodeJS库来支持Chrome新版headless模式,每一个都各有特色,我们自己的一款是NickJS。倘若没有自己的抓取库,怎么敢轻易的说自己是网页抓取专家。
还有一套C++ API和社区用其他语言发布的库,比如说基于GO语言。我们推荐使用NodeJS工具,因为它和网页解析语言一样(下面你会看到它有多便利)。
网页抓取?它不是非法的吗?
我们无意挑起无休止的争论,但不到两周前,美国一名地方法官下令允许第三方抓取领英(LinkedIn)公众档案。目前为止这只是初步的法令,诉讼仍会继续进行,领英肯定会反对,但尽管放心,我们会密切关注情况,因为这篇文章里谈论了很多关于领英的内容。
无论如何作为一篇技术性的文章,我们不会深入探究特定的抓取操作的合法性问题,我们应该始终努力去尊重目标网站的ToS。而对你在这篇文章中所学到的造成任何损害概不负责。
目前为止学到的很酷的东西
下面列出的一些技巧,我们每天几乎都在使用。代码示例采用NickJS抓取库,但它们很容易被其他Headless Chrome工具改写,重要的是分享概念。
把cookies放回cookie jar
使用功能齐全的浏览器抓取会让人安心,无需担心CORS、会话、cookie、CSRF和其他web问题。
但有时登录表单变得非常强硬,唯一的解决方案是恢复以前保存的会话cookie。当察觉故障时,有些网站会发送电子邮件或短信。我们就没有时间这么做,只是使用已设置好的会话cookie打开页面。
领英有一个很好的例子,设置li_atcookie能保证抓取机器访问他们的社交网络(请记住:注意尊重目标网站Tos)。
await nick.setCookie({
name: "li_at",
value: "a session cookie value copied from your DevTools",
domain: "www.linkedin.com"
})
相信像领英这样的网站不会用一个有效的会话cookie来阻止一个真实的浏览器访问。这么做相当有风险,因为错误的信息会引发愤怒用户的大量支持请求。
jQuery不会让你失望
我们学到了一件重要的事,那就是通过jQuery从网页提取数据真是太容易了。现在回想起来,这是显而易见的。网站提供了一个高度结构化的、可查询的、包含数据元素的树(它被称为DOM),而jQuery是非常高效的DOM查询库。所以为什么不用它来抓取呢?这个技巧会屡试不爽。
很多网站都已经使用了jQuery,所以只需在页面中添加几行就可以得到数据。
await tab.open("news.ycombinator.com")
await tab.untilVisible("#hnmain") // Make sure we have loaded the page
await tab.inject("https://code.jquery.com/jquery-3.2.1.min.js") // We're going to use jQuery to scrape
const hackerNewsLinks = await tab.evaluate((arg, callback) => {
// Here we're in the page context. It's like being in your browser's inspector tool
const data = []
$(".athing").each((index, element) => {
data.push({
title: $(element).find(".storylink").text(),
url: $(element).find(".storylink").attr("href")
})
})
callback(null, data)
})
印度、俄罗斯和巴基斯坦屏蔽机器人的做法有什么共同之处?

答案就是利用验证码解决服务器验证。你可以几美元买到上千个验证码,通常产生验证码不到30秒。但晚上的时候,因为没有人,所以一般比较贵。
一个简单的谷歌搜索将提供多个api来解决任何类型的验证码问题,包括获取谷歌最新的recaptcha验证码(2美元1000个)。
将抓取机器连接到这些服务就如发出HTTP请求一样简单,现在机器人是人类了。
在我们的平台上,用户很容易解决他们需要的验证码问题。我们的巴斯特图书馆可以调用多个解决服务器验证:
if (await tab.isVisible(".captchaImage")) {
// Get the URL of the generated CAPTCHA image
// Note that we could also get its base64-encoded value and solve it too
const captchaImageLink = await tab.evaluate((arg, callback) => {
callback(null, $(".captchaImage").attr("src"))
})
// Make a call to a CAPTCHA solving service
const captchaAnswer = await buster.solveCaptchaImage(captchaImageLink)
// Fill the form with our solution
await tab.fill(".captchaForm", { "captcha-answer": captchaAnswer }, { submit: true })
}
等待的是DOM元素,而不是固定的时间
经常看到抓取初学者让他们的机器人在打开一个页面或点击一个按钮后等待5到10秒——他们想要确定他们所做的动作有时间产生效果。
但这不是应该做的。我们的3步理论适用于任何抓取场景:应该等待的是想要操作的特定DOM元素。它更快、更清晰,如果出了问题,会得到更准确的错误提示。
await tab.open("https://www.facebook.com/phbuster/posts/676836339178597")
// await Promise.delay(5000) // DON'T DO THIS!
await tab.waitUntilVisible(".permalinkPost .UFILikeLink")
// You can now safely click the "Like" button...
await tab.click(".permalinkPost .UFILikeLink")
在某些情况下,可能的确有必要伪造人为的延迟。可以使用
await Promise.delay(2000 + Math.random() * 3000)
糊弄过去。
MongoDB
我们发现MongoDB很适合大部分的抓取工作,它有一套优秀的JS API和Mongoose ORM。考虑到当使用Headless Chrome时已经处于NodeJS环境中,为什么不采用它呢?
JSON-LD 和微数据开发
有时网页抓取并不需要理解DOM,而是要找到正确的“导出”按钮。记住这一点可以节省了不少时间。
严谨的说有些网站会比其他网站容易一些,以Macys.com为例,他们所有的产品页面都以JSON-LD形式的产品数据显示在DOM中。可以说到它们的任何一个产品页面然后运行。
JSON.parse(document . queryselector(" # productSEOData "). innertext)
将得到一个可以插入MongoDB很好的数据对象,没有真正抓取的必要!
网络请求拦截
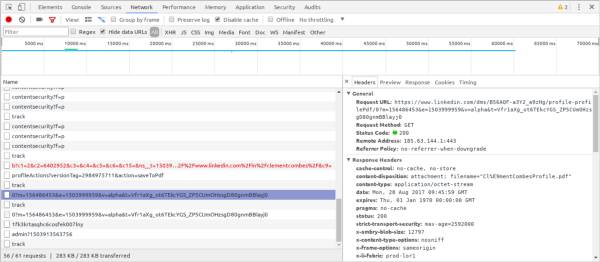
因为使用的是DevTools API,所以编写的代码具有使用Chrome的DevTools的等效功能。这意味着产生的机器人可以拦截、检查甚至修改或中止任何网络请求。
通过从LinkedIn下载PDF格式的简历来测试网络请求拦截。从配置文件中单击“Save to PDF”按钮触发XHR,其中响应内容为PDF文件,这是一种拦截文件并将其写入磁盘的方法。
let cvRequestId = null
tab.driver.client.Network.responseReceived((e) => {
if (e.type === "XHR" && e.response.url.indexOf("profile-profilePdf/") > 0) {
cvRequestId = e.requestId
}
})
tab.driver.client.Network.loadingFinished((e) => {
if (e.requestId === cvRequestId) {
tab.driver.client.Network.getResponseBody({ requestId: cvRequestId }, (err, cv) => {
require("fs").writeFileSync("linkedin-cv.pdf", Buffer.from(cv.body, (cv.base64Encoded ? 'base64' : 'utf8')))
})
}
})
值得一提的是DevTools协议正在迅速发展,现在有一种方法可以使用Page.setDownloadBehavior()设置下载传入文件的方式和路径。我们还没有测试它,但看起来很有前途!
广告拦截
const nick = new Nick({
loadImages: false,
whitelist: [
/.*\.aspx/,
/.*axd.*/,
/.*\.html.*/,
/.*\.js.*/
],
blacklist: [
/.*fsispin360\.js/,
/.*fsitouchzoom\.js/,
/.*\.ashx.*/,
/.*google.*/
]
})
同样可以通过屏蔽不必要的请求来加速抓取,分析、广告和图片是典型的屏蔽目标。然而,谨记它会让机器人变得不那么像人(例如,如果屏蔽了所有的图片,领英就不会正确响应页面请求——不确定这是否是故意的)。
在NickJS中用户可以指定一个白名单和一个包含正则表达式或字符串的黑名单。白名单特别强大,但如果不小心的话,很容易让目标网站崩溃。
DevTools协议也有Network.setBlockedURLs(),它使用带有通配符的字符串数组作为输入。
更重要的是,新版本的Chrome将带有谷歌自带的“广告拦截器”——它更像是一个广告“过滤器”。协议已经有一个端点叫做Page.setAdBlockingEnabled()。
这就是我们说的技巧!
Headless Chrome检测
最近发表的一篇文章列举了多种方法来检测Headless Chrome访问者,也有可能检测PhantomJS。那些方法描述了从基本的User-Agent字符串比较到更复杂的诸如触发错误和检查堆栈跟踪的技术。
在愤怒的管理员和巧妙的机器人制造商之间,这基本上是一个加大版的猫捉老鼠游戏。但从未见过这些方法在官方实施。在技术上是可以检测到自动访问者,但谁会愿意面对潜在的错误消息呢?对于大型的网站来说尤其有风险。
如果你知道那些网站有这些检测功能,请告诉我们!
结束语
抓取从来没有这么容易过,有了我们最新的工具和技术,它甚至可以成为我们开发人员愉快而有趣的活动。
顺便说一下,我们从Franciskim.co“我不需要臭烘烘的API”文章中受到了启发,非常感谢!另外,关于了解怎样开始使用木偶的详细说明,请点击这里。
在下一篇文章中,将写到关于“bot mitigation”的工具,比如Distill Networks,讲述HTTP代理和IP地址分配的美妙世界。
在Phantombuster.com上有我们的抓取和自动化平台 NickJS.org库。有兴趣的话还可以了解我们的3个抓取步骤的理论信息。