成人网站PornHub爬虫分享(一天可爬取500万以上的视频)
相关阅读:
PornHubBot
源代码地址:https://github.com/xiyouMc/WebHubBot
PornHubBot项目主要是爬取全球最大成人网站PornHub的视频标题、时长、mp4链接、封面URL和具体的PornHub链接
项目爬的是PornHub.com,结构简单,速度飞快
爬取PornHub视频的速度可以达到500万/天以上。具体视个人网络情况,因为我是家庭网络,所以相对慢一点。
10个线程同时请求,可达到如上速度。若个人网络环境更好,可启动更多线程来请求,具体配置方法见 [启动前配置]
环境、架构
开发语言: Python2.7
开发环境: MacOS系统、4G内存
数据库: MongoDB
主要使用 scrapy 爬虫框架
从Cookie池和UA池中随机抽取一个加入到Spider
start_requests 根据 PorbHub 的分类,启动了5个Request,同时对五个分类进行爬取。
并支持分页爬取数据,并加入到待爬队列。
使用说明
启动前配置
安装MongoDB,并启动,不需要配置
安装Scrapy
安装Python的依赖模块:pymongo、json、requests
根据自己需要修改 Scrapy 中关于 间隔时间、启动Requests线程数等得配置
启动
python PornHub/quickstart.py
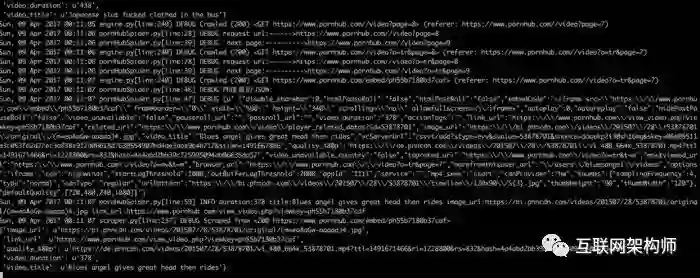
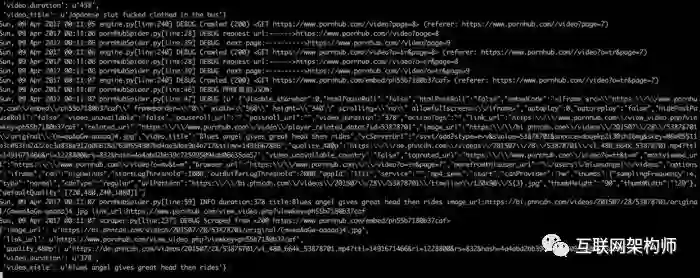
运行截图
数据库说明
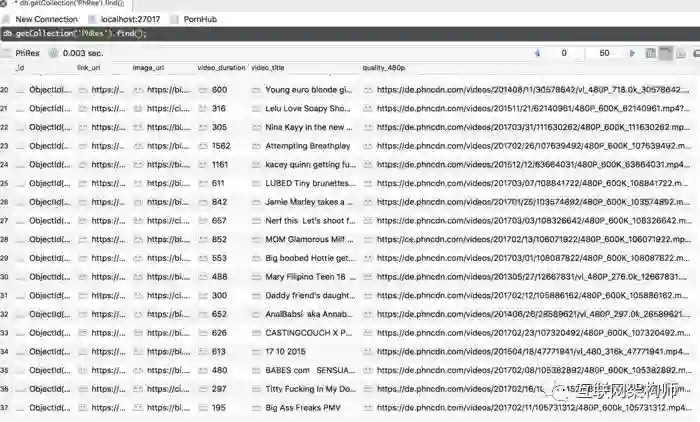
数据库中保存数据的表是 PhRes。以下是字段说明:
video_title:视频的标题,并作为唯一标识.link_url:视频调转到PornHub的链接 image_url:视频的封面链接 video_duration:视频的时长,以 s 为单位 quality_480p: 视频480p的 mp4 下载地址
链接:http://www.techug.com/post/pornhubbot.html
看完本文有收获?请转发分享给更多人
欢迎关注“互联网架构师”,我们分享最有价值的互联网技术干货文章,助力您成为有思想的全栈架构师,我们只聊互联网、只聊架构,不聊其他!打造最有价值的架构师圈子和社区。
本公众号覆盖中国主要首席架构师、高级架构师、CTO、技术总监、技术负责人等人 群。分享最有价值的架构思想和内容。打造中国互联网圈最有价值的架构师圈子。
长按下方的二维码可以快速关注我们
如想加群讨论学习,请点击右下角的“加群学习”菜单入群






