ECCV 2022 | 融合全局和局部注意力的场景文字检测方法

©作者 | Hanbo Cheng
单位 | NJUST
研究方向 | 场景文字检测

论文链接:

Abstract
文章试图解决什么问题?
文章主要的贡献
-
提出了新颖的 GLASS 模块,在极端尺度变化的情况下增强了模型的性能; -
设计了一个周期的,针对旋转的损失函数(具体是正弦函数的形式),增强了模型对于任意旋转角度的 scene text 的 Spotting 性能; -
在几个数据集上 ICDAR 2015, Total-Text, TextOCR,Rotated ICDAR 2013上取得了 SOTA 的结果; 将 GLASS 模块应用到现成的 Scene Text Spotting 框架上,使得这些模型的性能得到了提升(说明来 GLASS 的泛用性)。

Methodology
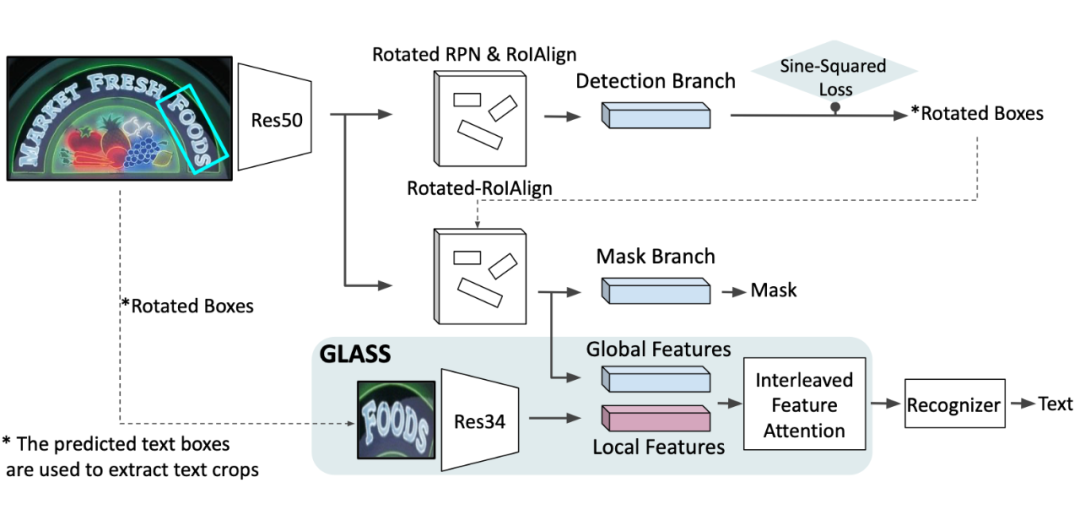
2.1 GLASS
GLASS 主要针对的分支是 recognition branch,这里是 GLASS 中的运算示意图:
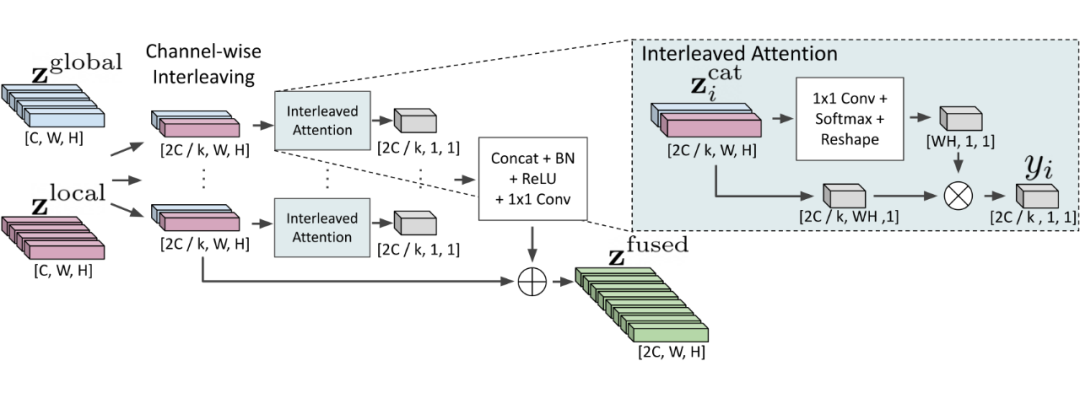
-
Global 特征来自 detection 分支(具体是 FPN feature),具体特征的采样范围仍然受 bbox 限制,但通过 FPN 各级采样,其感知域比 local feature 要大 Local 特征来自于 detection 分支生成的 bbox,因为只有一个选框,所以分辨率更高(主要针对小尺度 text)。
2.2 Global和local的融合
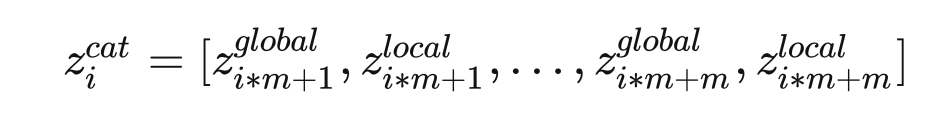
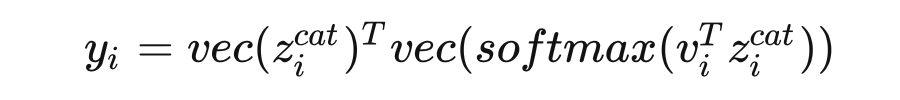
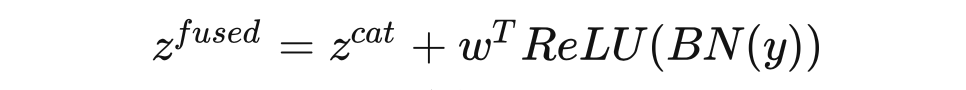
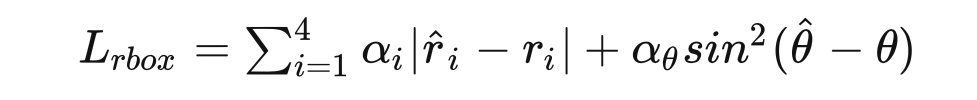
2.4 Global to Local End-to-End Text Spotting(模型总述)
整个模型的 backbone 是 ResNet50 和 FPN。 通过是哦那个 Rotated-RoIAlign,在 FPN 的各个层级上采样得到。对于 先对输入图像做 Rotated-RoIAlign,再使用 ResNet34 抽取特征得到。使用上述的 GLASS 得到融合特征 用它完成 text 的 recognition。关于 mask branch,仅仅采用了 global feature(这一点和 Mask R-CNN 的处理基本一致,应该不是文章的重点)
模型的总体优化目标:
-
:选框 loss -
:mask loss,和 mask R-CNN 一致 -
:recognition loss

Experiment
文章在几个 benchmark 上测试了方法的表现,并且和 SOTA 模型做了比较。同时,文章也尝试将 GLASS 融合进了两个较为常见的 E2E,Scene-text spotting 网络(Mask TextSpotter v3, ABCnet v2),并测试了融合后的性能。此外又做了一些消融实验。
3.1 Comparison with SOTA
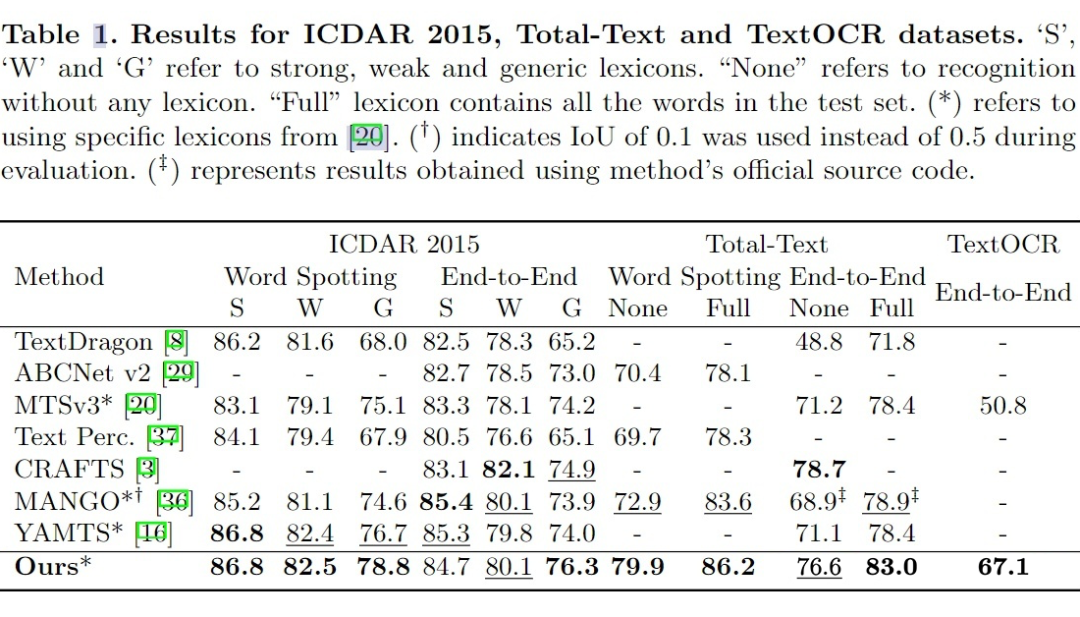
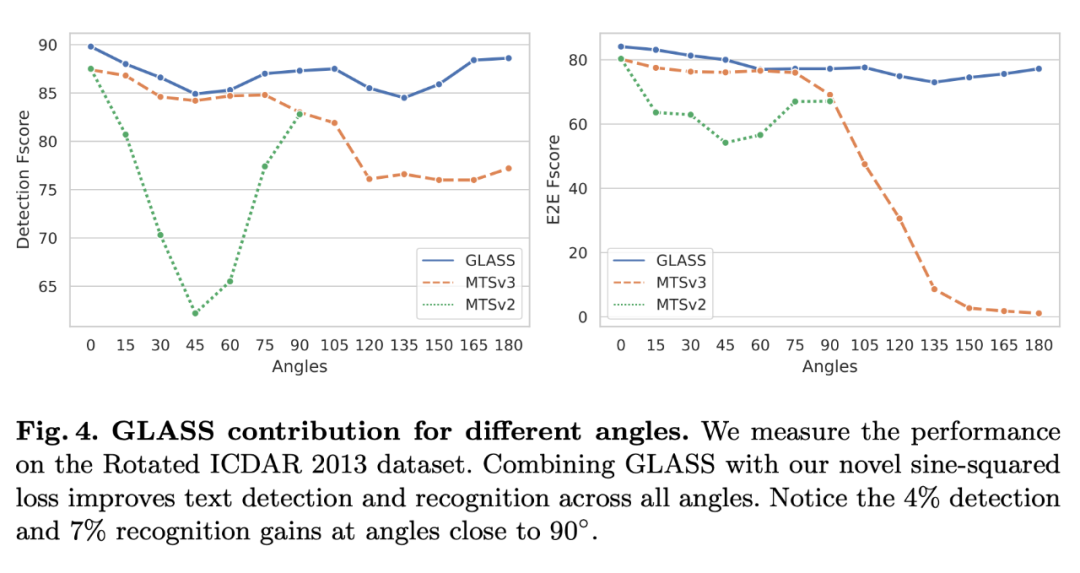
3.2 Incorporating GLASS into other methods
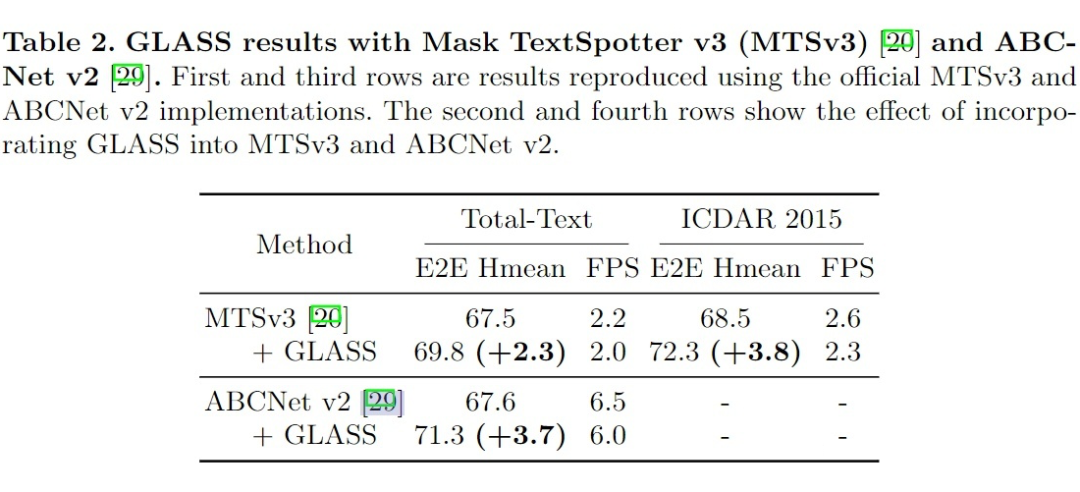
3.3 消融实验
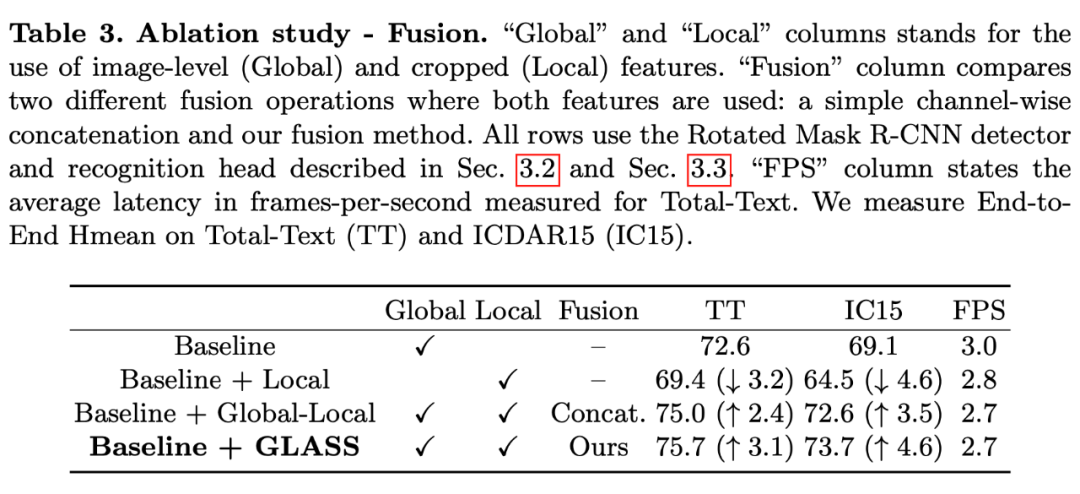
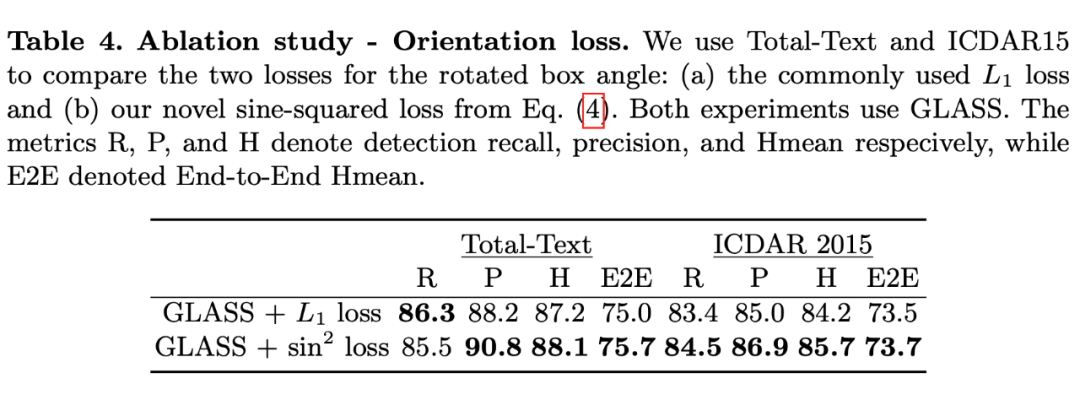
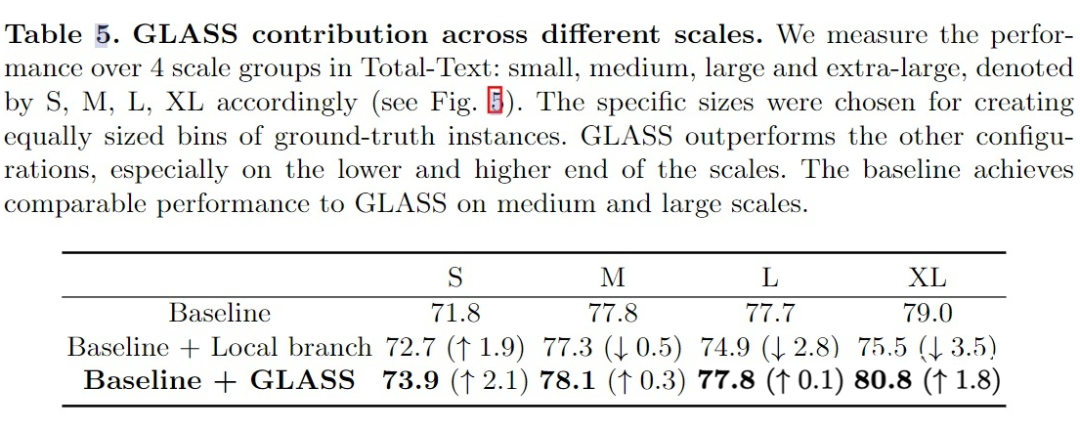


Rethink

-
针对第一个问题:我认为主要还是尺度的问题,以及卷积感知域的问题。字符本身的尺度相较于单词的尺度太小。或许可以采用类似 ViT 的一些方法(让我想到了 SwinSpotter 那篇文章),利用 transformer 可以将两个较远的像素点产生联系的特性处理这个问题。但这个问题显然更加复杂,因为两个相隔较远的字符,去判断他们属于一个 word,似乎需要一些先验知识的支持。 关于不规则字体:之前读过一篇基于知识图谱,通过 scene-text 完成 img captioning 任务的文章(knowledge Mining with SceneText for Fine-Grained Recognition),或许图片也可以反作用于文字,比如说这个 Flower(第二行第三个),似乎根据图片可以做一些 inference。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧


