
炼丹手册 | 神经网络训练tricks总结
作者 | Anticoder
来源 | 知乎
下面介绍一些值得注意的部分,有些简单解释原理,具体细节不能面面俱到,请参考专业文章。
-
网络 结构,如一对一,固定窗口,数据维度粒度,MLP,RNN或者CNN等 -
非线性选择,sigmoid,tanh,ReLU,或者一些变体,一般tanh比sigmoid效果好一点(简单说明下,两者很类似,tanh是rescaled的sigmoid,sigmoid输出都为正数,根据BP规则,某层的神经元的权重的梯度的符号和后层误差的一样,也就是说,如果后一层的误差为正,则这一层的权重全部都要降低,如果为负,则这一层梯度全部为负,权重全部增加,权重要么都增加,要么都减少,这明显是有问题的;tanh是以0为对称中心的,这会消除在权重更新时的系统偏差导致的偏向性。当然这是启发式的,并不是说tanh一定比sigmoid的好),ReLU也是很好的选择,最大的好处是,当tanh和sigmoid饱和时都会有梯度消失的问题,ReLU就不会有这个问题,而且计算简单,当然它会产生dead neurons,下面会具体说。 -
Gradient Check,如果你觉得网络feedforward没什么问题,那么GC可以保证BP的过程没什么bug。值得提的是,如果feedforward有问题,但是得到的误差是差不多的,GC也会感觉是对的。大多情况GC可帮你找到很多问题!步骤如下:

那如果GC失败,可能网络某些部分有问题,也有可能整个网络都有问题了!你也不知道哪出错了,那怎么办呢?构建一个可视化过程监控每一个环节,这可以让你清楚知道你的网络的每一地方是否有问题!!这里还有一个trick,先构建一个简单的任务(比如你做MNIST数字识别,你可以先识别0和1,如果成功可以再加入更多识别数字);然后从简单到复杂逐步来检测你的model,看哪里有问题。举个例子吧,先用固定的data通过单层softmax看feedforward效果,然后BP效果,然后增加单层单个neuron unit看效果;增加一层多个;增加bias。。。。。直到构建出最终的样子,系统化的检测每一步!
参数初始化也是重要滴!其主要考虑点在于你的激活函数的取值范围和梯度较大的范围!隐层的bias一般初始化为0就可以;输出层的bias可以考虑用reverse activation of mean targets或者mean targets(很直观对不对) weights初始化一般较小的随机数,比如Uniform,Gaussion

优化算法,一般用mini-batch SGD,绝对不要用full batch gradient(慢)。一般情况下,大数据集用2nd order batch method比如L-BFGS较好,但是会有大量额外计算2nd过程;小数据集,L-BFGS或共轭梯度较好。(Large-batch L-BFGS extends the reach of L-BFGSLe et al. ICML 2001)
mini-batch好处主要有:可以用矩阵计算加速并行;引入的随机性可以避免困在局部最优值;并行化计算多个梯度等。在此基础上一些改进也是很有效的(因为SGD真的敏感),比如Momentum,他的意图就是在原先的跟新基础上增加一点摩擦力,有点向加速度对速度的作用,如果多次更新梯度都往一个方向,说明这个方向是对的,这时候增加跟新的步长,突然有一个方向,只会较少影响原来的方向,因为可以较少的数据带来的误差。当你使用momentum时可以适当减小global learning rate

学习率,跑过神经网络的都知道这个影响还蛮大。一般就是要么选用固定的lr,要么随着训练让lr逐步变小
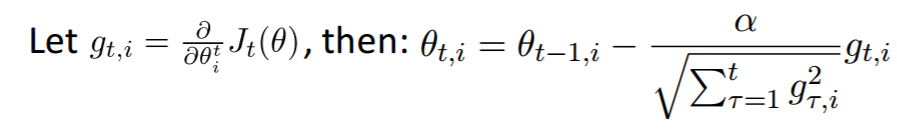
-
看看你的模型有没有能力过拟合!(training error vs. validation error)
如果没有,想办法让它过拟合!(r u kidding?! 哈哈),一般而言,当参数多于training数据时,模型是有能力记住数据的,总归先保证模型的能力么。
如果过拟合了,那么就可以进一步优化啦,一般深度学习breakthrough的方法都是来自于更好的regularization method,解决过拟合很多方法在此就不多论述了。比如减小模型(layers, units);L1,L2正则(weight decay);early stop(按照数据集大小,每隔一段epoch(比如小数据集每隔5epoch,大的每隔(1/3epoch))保存模型,最后选择validation error 最小的模型);sparsity constraints on hidden activation;Dropout;data augumentation (CNN 一些变化不变性要注意)等。
-
scale控制特征的重要性:大scale的output特征产生更大的error;大的scale的input的特征可以主导网络对此特征更敏感,产生大的update -
一些特征本来取值范围很小需要格外注意,避免产生NaNs -
就算没有标准化你的网络可以训练的话,那可能前几层也是做类似的事情,无形增加了网络的复杂程度 -
通常都是把所有inputs的特征独立地按同样的规则标准化,如果对任务有特殊需求,某些特征可以特别对待
-
需要注意的是,你需要理解你设定的error的意义,就算训练过程error在不断减少,也需要来和真实的error比较,虽然training error减少了,但是可能还不够,真实世界中需要更小的error,说明模型学习的还不够 -
当在training过程中work后,再去看在validation集上的效果 -
在更新网络结构前,最好确保每一个环节都有“监控”,不要盲目做无用功
-
神经网络假设数据的分布空间是连续的 -
减少数据表示多样性带来的误差;间接减少了网络前几层做没必要的“等同”映射带来的复杂度
-
一方面缓解过拟合,另一方面引入的随机性,可以平缓训练过程,加速训练过程,处理outliers -
Dropout可以看做ensemble,特征采样,相当于bagging很多子网络;训练过程中动态扩展拥有类似variation的输入数据集。(在单层网络中,类似折中Naiive bayes(所有特征权重独立)和logistic regression(所有特征之间有关系); -
一般对于越复杂的大规模网络,Dropout效果越好,是一个强regularizer! -
最好的防止over-fitting就是有大量不重复数据
如果可以容忍训练时间过长,最好开始使用尽量小的batch size(16,8,1)
-
大的batch size需要更多的epoch来达到较好的水平 -
原因1:帮助训练过程中跳出local minima -
原因2:使训练进入较为平缓的local minima,提高泛化性
-
一般数据中的outliers会产生大的error,进而大的gradient,得到大的weight update,会使最优的lr比较难找 -
预处理好数据(去除outliers),lr设定好一般无需clipping -
如果error explode,那么加gradient clipping只是暂时缓解,原因还是数据有问题
-
激活只是一个映射,理论上都可以 -
如果输出没有error明显也不行,那就没有gradient,模型也学不到什么 -
一般用tanh,产生一个问题就是梯度在-1或1附近非常小,神经元饱和学习很慢,容易产生梯度消息,模型产生更多接近-1或1的值
-
使用ReLU时需要给参数加一点噪声,打破完全对称避免0梯度,甚至给biases加噪声 -
相对而言对于sigmoid,因为其在0值附近最敏感,梯度最大,初始化全为0就可以啦 -
任何关于梯度的操作,比如clipping, rounding, max/min都可能产生类似的问题 -
ReLU相对Sigmoid优点:单侧抑制;宽阔的兴奋边界;稀疏激活性;解决梯度消失
-
太小:信号传递逐渐缩小难以产生作用 -
太大:信号传递逐渐放大导致发散和失效 -
比较流行的有 'he', 'lecun', 'Xavier'(让权重满足0均值,2/(输入节点数+输出节点数)) -
biases一般初始化为0就可以 -
每一层初始化都很重要
-
所以的优化方法在浅层也有用,如果效果不好,绝对不是深度不够 -
训练和预测过程随着网络加深变慢
-
考虑真实变量有多少信息量需要传递,然后再稍微增加一点(考虑dropout;冗余表达;估计的余地) -
分类任务:初始尝试5-10倍类别个数 -
回归任务:初始尝试2-3倍输入/输出特征数 -
这里直觉很重要 -
最终影响其实不大,只是训练过程比较慢,多尝试
-
多分类一般用softmax,在小于0范围内梯度很小,加一个log可以改善此问题 -
避免MSE导致的学习速率下降,学习速率受输出误差控制(自己推一下就知道了)
-
对于SGD需要对学习率,Momentum,Nesterov等进行复杂调参 -
值得一提是神经网络很多局部最优解都可能达到较好的效果,而全局最优解反而是容易过拟合的解
-
pooling或卷积尺寸和步长不一样,增加数据多样性 -
data augumentation,避免过拟合,提高泛化,加噪声扰动 -
weight regularization -
SGD使用decay的训练方法 -
最后使用pooling(avgpooling)代替全连接,减少参数量 -
maxpooling代替avgpooling,避免avgpooling带来的模糊化效果 -
2个3x3代替一个5x5等,减少参数,增加非线性映射,使CNN对特征学习能力强 -
3x3,2x2窗口 -
预训练方法等 -
数据预处理后(PCA,ZCA)喂给模型 -
输出结果窗口ensemble -
中间节点作为辅助输出节点,相当于模型融合,同时增加反向传播的梯度信号,提供了额外的正则化 -
1x1卷积,跨通道组织信息,提高网络表达,可对输出降维,低成本,性价比高,增加非线性映射,符合Hebbian原理 -
NIN增加网络对不同尺度的适应性,类似Multi-Scale思想 -
Factorization into small convolution,7x7用1x7和7x1代替,节约参数,增加非线性映射 -
BN减少Internal Covariance Shift问题,提高学习速度,减少过拟合,可以取消dropout,增大学习率,减轻正则,减少光学畸变的数据增强 -
模型遇到退化问题考虑shortcut结构,增加深度 -
等等
-
一般用LSTM结构防止BPTT的梯度消失,GRU拥有更少的参数,可以优先考虑 -
预处理细节,padding,序列长度设定,罕见词语处理等 -
一般语言模型的数据量一定要非常大 -
Gradient Clipping -
Seq2Seq结构考虑attention,前提数据量大 -
序列模型考虑性能优良的CNN+gate结构 -
一般生成模型可以参考GAN,VAE,产生随机变量 -
RL的框架结合 -
数据量少考虑简单的MLP -
预测采用层级结构降低训练复杂度 -
设计采样方法,增加模型收敛速度 -
增加多级shortcut结构
[1]CS224D Lecture 6:https://youtu.be/l0k-30FNua8
[2]Debugging Neural Networks:https://stackoverflow.com/questions/41488279/neural-network-always-predicts-the-same-class/41493375
[3]A Practical Guide to Training Restricted Boltzmann Machines:https://www.cs.toronto.edu/~hinton/absps/guideTR.pdf
[4]My Neural Network isn't working! What should I do?:http://theorangeduck.com/page/neural-network-not-working
[5]Neural Network and Deep Learning:http://neuralnetworksanddeeplearning.com
[6]TensorFlow实战

推荐阅读

登录查看更多
相关内容

Arxiv
3+阅读 · 2019年3月27日
Arxiv
10+阅读 · 2018年3月27日
Arxiv
5+阅读 · 2018年1月7日


相关VIP内容
相关资讯
相关论文
Arxiv
3+阅读 · 2019年3月27日
Arxiv
10+阅读 · 2018年3月27日
Arxiv
5+阅读 · 2018年1月7日