开域聊天机器人技术介绍(未来篇:下)

书接上文:“开域聊天机器人技术介绍(未来篇:上)” 。
Facebook Blender
Blender这组人最近几年在开域聊天方向持续做了很多改进工作,他们的努力和信念还是挺让我感动的。Blender这个名字取得好,因为这篇论文基本是同一组人最近两年内很多相关工作的融合,个人觉得还是夹带了一些没必要放进来的私货的。下图可以看到他们提出的聊天机器人在不断逼近人类的水平(纵坐标是机器聊的比人好的百分比,所以人的聊天水平对应纵坐标50)。
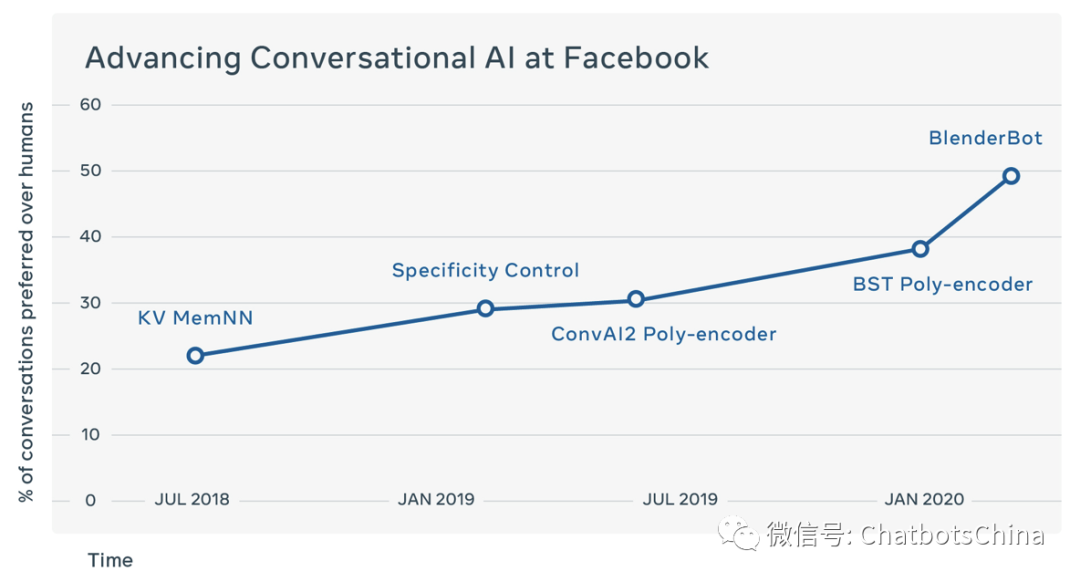
我们先介绍Blender论文 “Recipes for building an open-domain chatbot” 中尝试的三个模型,然后介绍训练使用的数据集,以及各方面的效果评估等。
三个模型
模型一:检索模型(Retriever)
检索模型,顾名思义,就是从候选集中选取最合适的句子作为机器人当前的答复。具体打分/排序模型使用了作者在论文 “Poly-encoders: Transformer Architectures and Pre-training Strategies for Fast and Accurate Multi-sentence Scoring” 中提出的 Poly-encoder 模型,结构如下。可以把 poly-encoder 理解成对 Siamese 结构的一种改进。BERT中原始的打分方式是把context和response拼接起来一起送进BERT的,但这种做法非常耗时。作者认为 context 是由前面几轮对话拼接得到的,一般比response更长不少,所以 poly-encoder 中使用了 m 个向量对其进行表示。
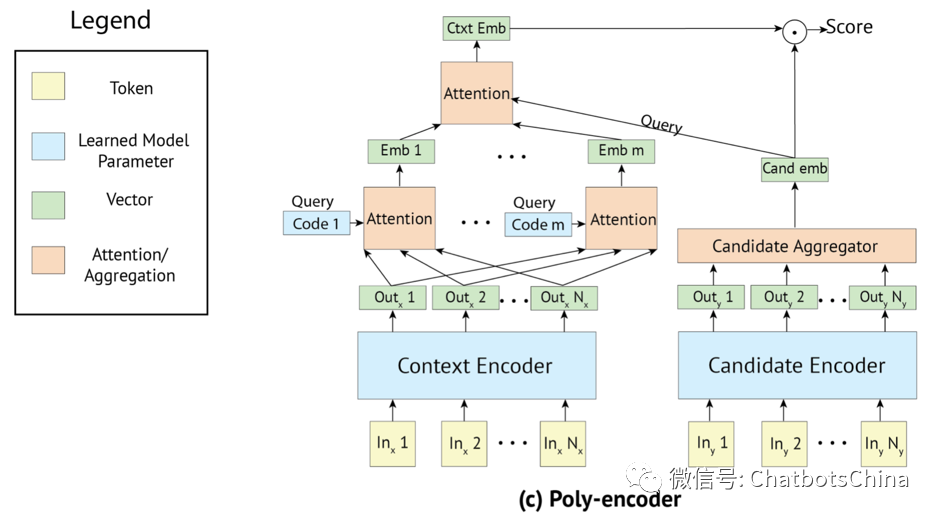
作者的实验表明 m 越大效果越好,当然模型打分也越耗时。在很多数据集上 poly-encoder 能获得比 Siamese 结构好不少的结果,甚至和BERT原始的拼接方法排序精度差不多。
检索模型训练时的目标函数是 InfoNCE,其中负样本来自同一个batch下随机选取的其他样本:
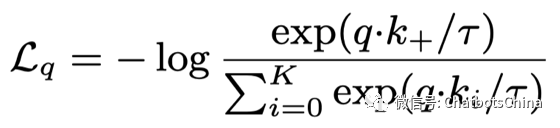
在做推断时,候选回复来自于训练集中的所有 response。
模型二:生成模型(Generator)
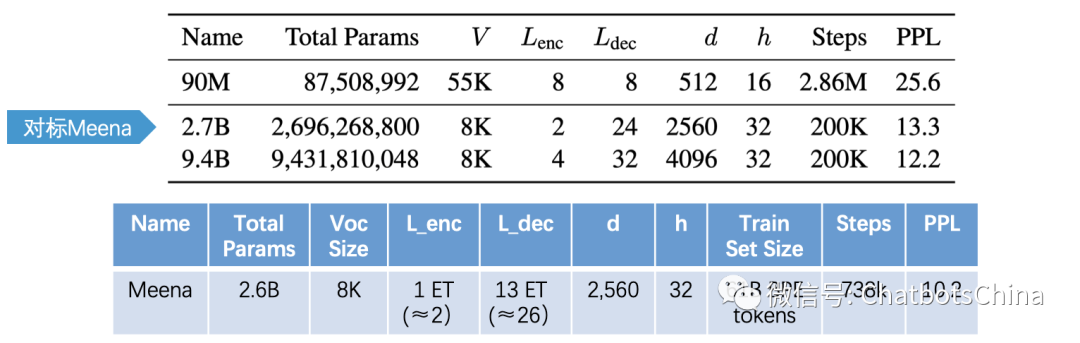
生成模型也是标准的 seq2seq 结构,只是用了标准的Transformer层,以及encoder层数少,decoder层数多的设计。下图列出了三个生成模型的尺寸,最大的模型包含了 9.4B 的参数量,快有 Meena 的 4 倍大了。
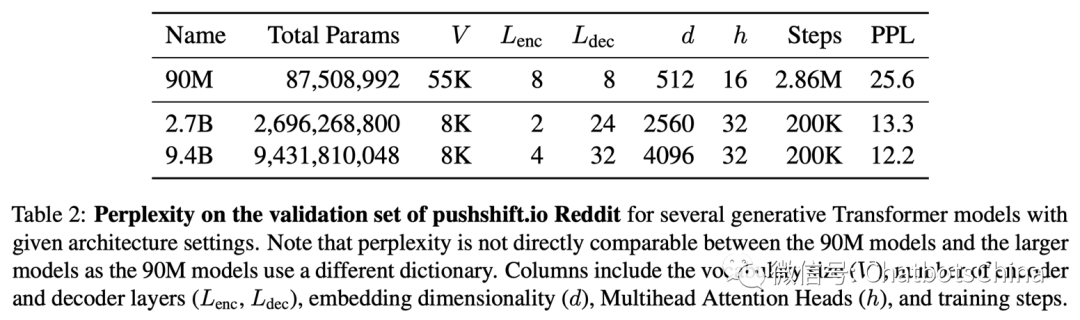
中间2.7B那个模型基本和Meena的大模型是对应的,参数量,模型层数都差不多。
Seq2seq模型标准的训练方法就是MLE,作者也尝试了他们之前在论文 “Neural Text Generation with Unlikelihood Training” 中提出的另一种损失,叫 Unlikelihood Loss (UL),即在提高正确token概率的同时,降低其他token的概率。
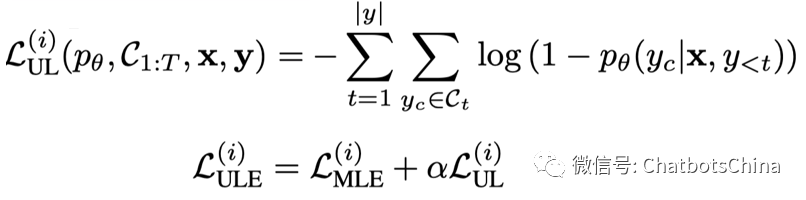
Unlikelihood loss 的关键是如何选取这些被打压的负token。作者选的是那些容易组合成常见n-grams的tokens。如果一个token组成的n-grams比真实答案中n-grams比例高,就会有更大概率被选取为负token。这么做的目的是期望降低生成无意义回复的比例。后续会有MLE与unlikelihood loss的效果对比。
前面说过,decoding阶段一般使用Beam Search或Sampling方法。Meena的结论是sampling效果比beam search方法好,所以用了sampling方法。Blender则表示模型够好时beam search用好了不比sampling差,所以Blender使用了受限的beam search。Blender在beam search加入了以下限制:
控制生成回复的最小长度。作者尝试了两种方法:
Minimum length:要求回复长度必须大于设定的值。长度不达标时,强制不产生结束token;
Predictive length:把长度分成四段,例如 < 10, < 20, < 30, 和 > 30 tokens,然后利用四分类模型预测当前回复应该落在哪个长度段。模型使用的依旧是 poly-encoder。
屏蔽重复的子序列(Subsequence Blocking):不允许产生当前句子和前面对话(context)中已经存在的 3-grams。
在beam search中加入各种限制方法以提升生成质量的做法非常多,Blender里用到的这些其实很多人也都用过。如果模型本身不够好,这些方法能起到的作用是很小的。
模型三:检索+生成(Retrieve and Refine)
Retrieve and Refine (RetNRef) 融合了检索和生成两种方法,是作者在2018年的论文 “Retrieve and Refine: Improved Sequence Generation Models For Dialogue” 中提出的。RetNRef 先利用检索模型检索出一个结果,然后把检索出的结果拼接到context后面,整体作为generator的输入。

这样做的目的是期望生成模型能学习到在合适的时候从检索结果中copy词或词组。
那么,检索出的结果具体是怎么得到的呢?作者建议了两种方法:
Dialogue Retrieval:直接从训练数据的数据中检索出得分最高的回复,作为结果;
Knowledge Retrieval:从外部的大知识库如 Wiki 中检索,作者之前的论文 “Wizard of Wikipedia: Knowledge-Powered Conversational agents” 给出的具体做法如下:
分别利用当前对话topic(对话topic会事先告知)和最后两轮对话,各自检索出 top-7 的文章;
把 21 篇文章各自分句,然后把各自文章的 title 追加到每个句子最前面,获得很多候选句子;

再利用 poly-encoder 结构的模型对候选句子排序,最终使用 top-1 的句子作为检索结果;
同时还会训练一个单独的分类器来判断是否需要从知识库中检索知识。回复某些对话 context 可以不需要额外知识,这时候就不用追加检索结果。
对于 Knowledge Retrieval,把检索出的结果直接追加到context后面,然后利用标准的 MLE 训练即可。但对于 Dialogue Retrieval,作者发现直接利用MLE训练会有问题。训练出来的模型很容易直接忽略掉追加的检索部分,因为检索部分可能与实际回复关联性不强。作者提出了名为 α-blending 的训练策略:训练时以 α% 的概率把检索结果替换为实际回复。这样模型就会被吸引去关注检索部分了。
数据集
什么叫会聊天?公认的几个标准是对话要:个性有趣、包含知识、富有同理心。作者之前的工作 “Can You Put it All Together: Evaluating Conversational Agents' Ability to Blend Skills” 发现在具有某些特性的数据上训练出的模型也会拥有这些特性。这是一个很重要的发现,以后我们就可以针对性地创建数据集来优化机器人的不同特性了。
Blender利用以下的数据集训练模型:
pushshift.io Reddit:整理自Reddit网站上的讨论;数据量大,可用于训练预训练模型(检索模型训练使用 MLM、生成模型训练使用 LM);
ConvAI2:带个性的对话数据,对话目标是了解对方,所以对话个性有趣;
Empathetic Dialogues (ED) :一个人发牢骚另一个人倾听,所以对话富有同理心;
Wizard of Wikipedia (WoW):基于wiki 选取的 topic 进行对话,所以对话包含知识;
Blended Skill Talk (BST):基于ConvAI2、ED和WoW构建,并融合它们各自的优势。
下图是 BST 数据集中的一个示例,它会同时提供对话人的背景、对话主题和对话历史。

有了上面的数据集,模型的训练流程如下图:

这样最终训练出的模型就倾向于产生个性有趣、包含知识、富有同理心的回复了。
作者发现在优质数据上训练模型,也能降低模型产生不好回复的概率,比如回复中出现污词的概率显著降低。
评估方法
和Meena一样,自动评估生成模型用的是 PPL,而检索打分模型看的是 Hits@1/K,即随机找 K-1 个其他回复,把它们和真的回复放一块用模型排序,看top-1真回复的命中率。
人工评估没有用 Meena 中的 SSA,而是用作者另一篇论文 “ACUTE-EVAL: Improved Dialogue Evaluation with Optimized Questions and Multi-turn Comparisons” 中提出的 ACUTE-Eval 和 Self-Chat ACUTE-Eval。这两个指标都是评估给定的两个speakers(如不同的聊天机器人)哪个更会聊天。
ACUTE-Eval 的做法是每次给两个对话session(每个session来自一个speaker与其他人的对话记录),然后让人来评判哪个 speaker 聊的更好(更想跟谁继续聊;谁更像人)。最后 ACUTE-Eval 可以给出两个 speaker 各自的胜率。下图是一个示例,左边是 speaker 1(浅蓝色)与其他人的对话记录,右边是 speaker 2(深蓝色)与其他人的对话记录。评委需要判断是左边的 speaker 1 聊得更好,还是右边的 speaker 2 聊得更好。
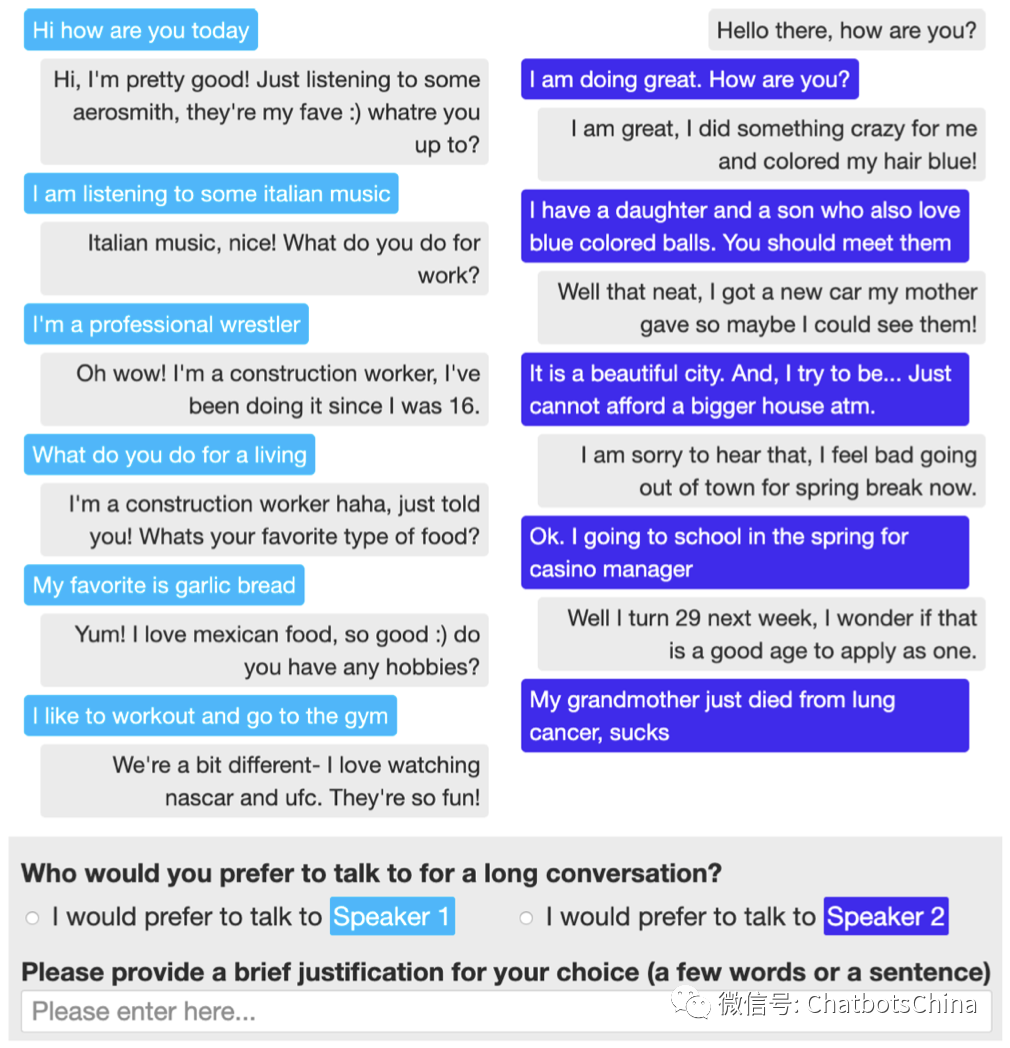
Self-Chat ACUTE-Eval 的做法类似,只是评估时用的是自己跟自己聊的session,也即 speaker 1 对话的对象是使用 speaker 1 相同模型构建的机器人,speaker 2 对话的对象是使用 speaker 2 相同模型构建的机器人。然后把 speaker 1 与speaker 2 自聊的很多 session 拿来两两对比,评估各自的胜率。
评估结果
PPL
论文首先对比了大小不同的三个生成模型的PPL,结论是模型越大PPL越低。最大的模型 9.4B ,PPL降到了 12.2。这个数字没法和Meena给出的PPL 10.2直接对比,因为使用的数据集不相同。
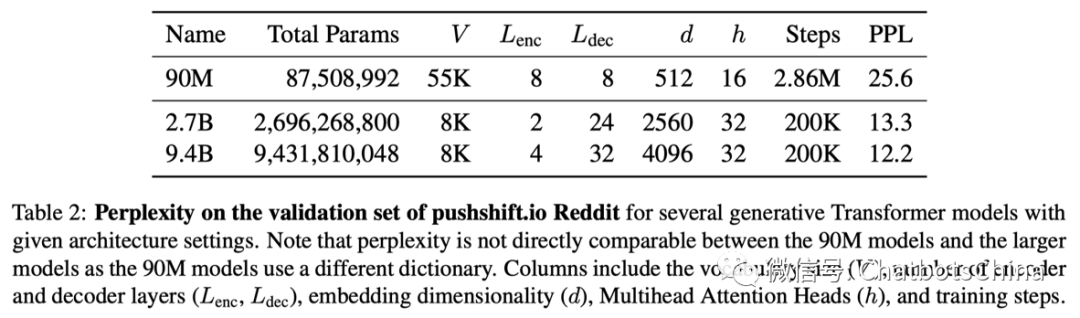
另一个结论是 RetNRef 相比于同等规模的生成模型,PPL会略有提升。
Self-Chat ACUTE-Eval
Retrieval vs. Generator vs. RetNRef
先来比较下三种模型的效果,它们都使用最小尺寸的模型。生成模型的参数量是90M,检索模型的参数量是256M,而 RetNRef 检索和生成部分的参数量分别是256M和90M。Generator和RetNRef模型都未使用最小长度约束。结果见下图。图中给出了不同模型 PK 时各自的输赢比率,下三角给出的是行模型对应的胜率。例如第三行第一列红框中的 60,表示 RetNRef 与Generative对战时,胜率为60%。

可见,从 Self-Chat ACUTE-Eval 指标看,最小尺寸的 Retrieval 和 RetNRef 都比 Generative 好;Retrieval 比 RetNRef 略好,但不显著。可见生成模型不加最小长度限制还是不太行啊。
Beam Search中加入限制
第一个结论是限制最小生成长度效果显著,最小长度限制设为20效果最好,其与不做限制时 PK 胜率达到了83%。

第二个结论是子序列屏蔽有点用,但不显著。

论文也对比了beam search与两种sampling方法的效果,结论是效果差不多。Beam search中的 beam 值取 10 效果比 1 或 30 都好。
预训练 vs. 精调
精调用的是BST数据。结论是精调后的模型效果好很多,与未精调模型 PK 胜率达到了61%。

MLE vs. Unlikelihood Loss
结论是 Unlikelihood Loss 比 MLE 效果好一点点,但不显著。

ACUTE-Eval
Retrieval vs. Generator vs. RetNRef
模型都还是用的最小模型,但 Generator 和 RetNRef 模型使用的 beam search 都加入了最小长度20的限制。结论反转了,Generator 和 RetNRef 显著优于 Retrieval。RetNRef 略优于 Generative,但不显著。(强烈怀疑 RetNRef 是作者夹带的私货,没有在此论文中存在的必要好不好!)

Blender vs. Meena
结论肯定是 Blender 显著优于 Meena 了,不论是比较对话的有趣性(engagingness),还是比较对话更像真人(humanness)方面。Blender 的胜率都达到了 70% 甚至更高。


Blender vs. Human
最后,Blender 到底跟人有多大差别呢?从 ACUTE-Eval 指标上看很接近了。Blender最好的模型(下图最后一行)和人 PK 的胜率已经到了 49%。和人的差距就剩 1% 了,已经是不显著的差距了。这个 1% 的差距留的实在太有深意了。新的工作几乎不可能用同样的评估方法 PK 掉 Blender 了。相信接下来很多工作会发明很多新评估方法与 Blender PK。

示例
下图贴出了论文的几个正向示例,个人感觉对话内容确实比 Meena 丰富,可能是因为生成结果变长了吧。论文提供了很多示例,有兴趣可以仔细看看论文:“Recipes for building an open-domain chatbot” 。

模型存在的问题
虽然 Blender 和人 PK 的胜率已经到了 49%,但作者没骄傲,依旧花了很多篇幅仔细剖析了模型存在的各种问题。
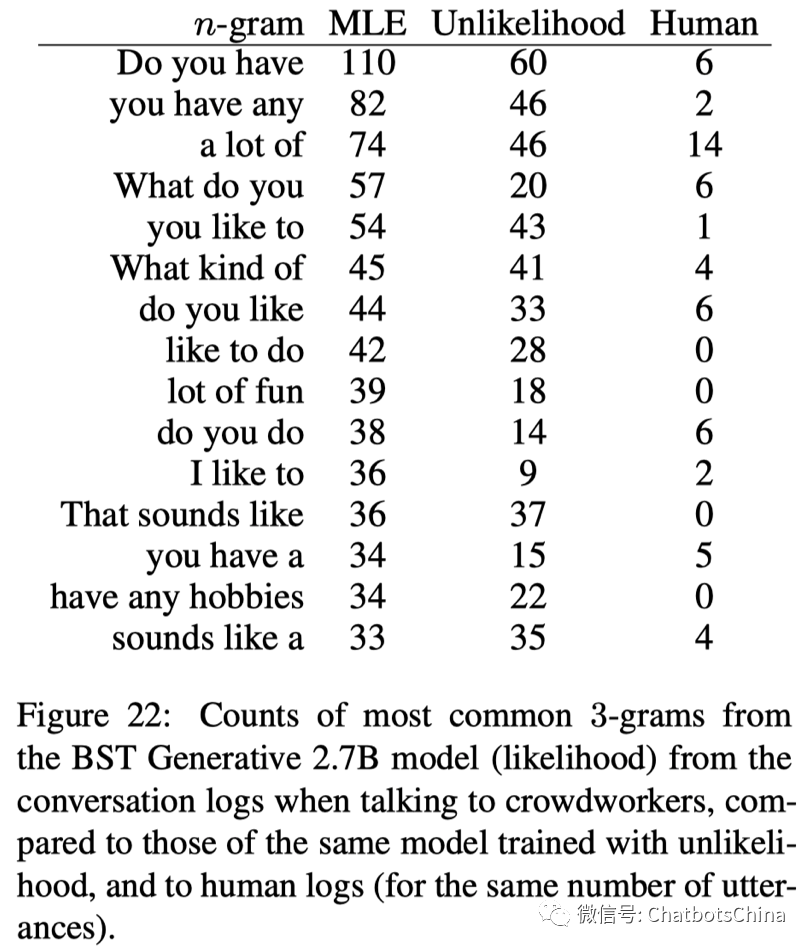
倾向于使用高频词
模型倾向于使用高频词,产生高频 n-grams,而很少使用低频词。虽然鼓励模型产生更长的回复会缓解这个问题,但无法杜绝。下图表明使用 unlikelihood loss 也可以缓解此问题。但使用unlikelihood loss 会降低 ACUTE-Evals 指标哦(作者很无奈,吹不了自己发明的 unlikelihood loss)。
倾向于生成重复信息
模型倾向于拷贝信息,产生各种重复。比如前面用户说了喜欢狗,模型会倾向于说自己也喜欢。虽然子序列屏蔽的方法可以屏蔽简单的n-grams重复,但复杂的重复很难避免。作者的其他论文在尝试使用 unlikelihood loss 训练模型,以便最小化 context 重复。另一种解决此方法是为机器人添加个性化的角色背景。
内容冲突和遗忘
模型生成的答复可能前后冲突。比如模型前面说喜欢狗,后面说不喜欢狗。用户已经说过喜欢狗,可机器人还问用户喜不喜欢狗。原因可能不是模型忘了,而是模型不会推理。作者也有其他工作在尝试解决这个问题。😅
论文中还分析了模型的一些其他问题:
无法针对某个话题做深度对话,不会倾向于使用更多知识进行深聊。
模型无法深度理解,无法通过对话真正教会模型理解某个概念。
当前的评测针对的是14轮长度的对话,分析更长的对话肯定会发现其他问题。
总之就是还有很多问题待解决(作者还有很多论文没发表呢)。
总结
对Blender这篇论文做个简单总结:
Larger Transformer and data is all you need;
训练数据的特性决定模型特性,BST 是个好数据集,赶紧用起来!(作者论文引用 +1);
评估方法使用 ACUTE-Eval、 Self-Chat ACUTE-Eval(作者论文引用 +1);
对decoding过程加入控制,比如控制生成句子长度,效果会更佳;
Blender在轮次少(<=28 轮)的情况下已经接近人类的水平(PK 人类胜率已达到 49%),但目前还有很多问题待解决;
新的工作几乎不可能在 ACUTE-Eval 指标下胜过 Blender。相信接下来很多工作会发明很多新评估方法与 Blender PK;
对于更多轮次的对话,模型还有很长的路要走,现在连低成本评测都还做不到呢。
Blender的代码和模型都已开源,大家可以去尝试跑跑。(小模型应该还是能跑得动的,大模型自己先掂量一下)。
离工业使用还差一点点
最后,写一点自己的感想。几年前我尝试了当时的生成式模型效果后就放弃生成式了,完全看不到生成模型可实用的希望啊。Meena 和 Blender 给我最大的震撼是端到端模型真的能打败复杂架构的对话系统!太了不起了!去年要是有人这么说我都完全不相信。没想到到了2020年大厂重燃了我对生成模型的信心。梦想还是要有的,万一别人替你实现了呢。
但目前端到端模型离工业界使用还是有些距离的。工业使用的一个前提是要结果足够可控。怎么让端到端的seq2seq模型结果可控?反正控制 seq2seq 模型本身现在基本是不行的,所以就尽量控制它的输入和输出吧。
输入可以尝试控制训练集、训练目标和优化方法。Blender已经发现在具有某些特性的数据上训练出的模型也会拥有这些特性,使用 unlikelihood loss 训练的模型会更少生成高频 n-grams。但这些控制都是间接、soft的,不是很有力度。
更直接的方法是控制decoding过程甚至decoding结果,比如Blender中使用的最小长度和子序列屏蔽控制方法。这种控制方法其实就相当于用 rule-based 的方式去解决一个又一个发现的问题。这种解法只能解决孤立的简单问题,无法解决更深更难的问题。而且,控制decoding过程往往会破坏模型的端到端特性。目前虽然有不少工作在尝试把decoding步骤也纳入到模型训练过程中,但我还没听说存在广泛有效的方法。
另外,现在Blender这种规模的模型工业使用也太太大了点,BERT线上用起来还费劲呢,再来一个大10倍的Blender,没干爹的公司谁扛得住啊。针对聊天机器人的模型压缩、蒸馏什么时候会来呢?
另另外,英文模型都出来两个月了,还没听到中文模型的任何下落呢。BAT加油啊。
不管怎样,能跟人类随便什么都能聊个十几二十轮的智能聊天机器人真的快出现了,估计最晚明后年就会有工业(试)部署了吧。到时候不知道又会有多少寂寞的心灵泛起波澜呢。
聊天机器人的teacher们(两年后可能就是student们了),一起加油吧。
推荐阅读
超赞!百度词法分析工具 LAC 全面升级,2.0 版在线极速体验
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,点个在看吧👇




