【CVPR2020】用多样性最大化克服单样本NAS中的多模型遗忘

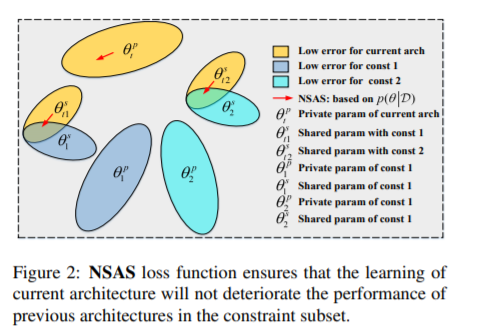
一次性神经架构搜索(NAS)通过权重共享显著提高了计算效率。然而,这种方法也在超网络训练(架构搜索阶段)中引入了多模型遗忘,在超网络训练中,当使用部分共享的权重顺序训练新架构时,之前架构的性能会下降。为了克服这种灾难性遗忘,最先进的方法假设共享权值在联合优化后验概率时是最优的。然而,这种严格的假设在实践中并不一定适用于一次性NAS。在本文中,我们将一次性NAS中的超网络训练描述为一个持续学习的约束优化问题,即当前架构的学习不应该降低以前架构的性能。提出了一种基于新搜索的结构选择损失函数,并证明了在最大化所选约束的多样性时,不需要严格的假设就可以计算后验概率。设计了一种贪心查新方法,寻找最具代表性的子集,对超网络训练进行正则化。我们将我们提出的方法应用于两个一次性的NAS基线,随机抽样NAS (RandomNAS)和基于梯度的抽样NAS (GDAS)。大量的实验证明,我们的方法提高了超级网络在一次NAS中的预测能力,并在CIFAR-10、CIFAR-100和PTB上取得了显著的效率。
https://shiruipan.github.io
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“GDAS” 可以获取《用多样性最大化克服单样本NAS中的多模型遗忘》专知下载链接索引



登录查看更多
相关内容

Arxiv
3+阅读 · 2019年2月28日
Arxiv
4+阅读 · 2017年10月26日



相关VIP内容
相关资讯
相关论文
Arxiv
3+阅读 · 2019年2月28日
Arxiv
4+阅读 · 2017年10月26日